Python 中的 Scrapy(开发人员如何使用)
在网络数据抓取和文档生成领域,有效性和效率至关重要。 要从网站提取数据并将其转换为专业水准的文档,就需要将强大的工具和框架无缝集成。
接下来是 Scrapy,一个 Python 中的网络爬虫框架,以及 IronPDF,这两个强大的库协同工作,以优化在线数据的提取和动态PDF的创建。
借助 Python 中的 Scrapy(一款顶级的网络爬虫和抓取库),开发人员现在可以轻松浏览复杂的网络,并快速、精确地提取结构化数据。 凭借其强大的 XPath 和 CSS 选择器以及异步架构,它是抓取任何复杂程度任务的理想选择。
相反,IronPDF 是一个功能强大的 .NET 库,支持以编程方式创建、编辑和操作 PDF 文档。 IronPDF 为开发人员提供了一套完整的解决方案,通过其强大的 PDF 创建工具(包括 HTML 到 PDF 转换和 PDF 编辑功能),可以生成动态且美观的 PDF 文档。
本文将带您了解Scrapy Python与 IronPDF 的无缝集成,并向您展示这一动态组合如何改变网络抓取和文档创建的方式。 我们将展示这两个库如何协同工作,以简化复杂的任务并加快开发工作流程,从使用 Scrapy 从网络抓取数据到使用 IronPDF 动态生成 PDF 报告。
欢迎探索网络爬虫和文档生成的可能性,我们将使用 IronPDF 来充分利用 Scrapy。

异步架构
Scrapy 使用的异步架构能够同时处理多个请求。 这提高了效率,加快了网页抓取速度,尤其是在处理复杂的网站或大量数据时。
坚固的爬行管理
Scrapy 具有强大的爬虫过程管理功能,例如自动 URL 过滤、可配置的请求调度和集成的 robots.txt 指令处理。 开发者可以调整爬虫行为,以满足自身需求并保证遵守网站准则。
XPath 和 CSS 选择器
Scrapy 允许用户使用 XPath 和 CSS 选择器在 HTML 页面中导航和选择项目。 这种适应性使得数据提取更加精确可靠,因为开发人员可以精确地针对网页上的特定元素或模式。
物品管道
开发者可以使用 Scrapy 的项目管道,为抓取的数据指定可重用的组件,以便在导出或存储之前对其进行处理。通过执行清洗、验证、转换和去重等操作,开发者可以保证提取数据的准确性和一致性。
内置中间件
Scrapy 中预装的许多中间件组件提供了诸如自动 cookie 处理、请求限制、用户代理轮换和代理轮换等功能。 这些中间件元素易于配置和自定义,可以提高抓取效率并解决常见问题。
可扩展架构
通过创建自定义中间件、扩展和管道,开发人员可以借助 Scrapy 的模块化和可扩展架构,进一步个性化和扩展其功能。 由于其适应性强,开发人员可以轻松地将 Scrapy 集成到他们当前的流程中,并对其进行修改以满足他们独特的抓取需求。
使用 Python 创建和配置 Scrapy
安装 Scrapy
使用pip安装 Scrapy,运行以下命令:
pip install scrapypip install scrapy蜘蛛的定义
要定义您的爬虫,需在example.py)。 这里提供了一个从 URL 中提取信息的基本爬虫示例:
import scrapy
class QuotesSpider(scrapy.Spider):
# Name of the spider
name = 'quotes'
# Starting URL
start_urls = ['http://quotes.toscrape.com']
def parse(self, response):
# Iterate through each quote block in the response
for quote in response.css('div.quote'):
# Extract and yield quote details
yield {
'text': quote.css('span.text::text').get(),
'author': quote.css('span small.author::text').get(),
'tags': quote.css('div.tags a.tag::text').getall(),
}
# Identify and follow the next page link
next_page = response.css('li.next a::attr(href)').get()
if next_page is not None:
yield response.follow(next_page, self.parse)import scrapy
class QuotesSpider(scrapy.Spider):
# Name of the spider
name = 'quotes'
# Starting URL
start_urls = ['http://quotes.toscrape.com']
def parse(self, response):
# Iterate through each quote block in the response
for quote in response.css('div.quote'):
# Extract and yield quote details
yield {
'text': quote.css('span.text::text').get(),
'author': quote.css('span small.author::text').get(),
'tags': quote.css('div.tags a.tag::text').getall(),
}
# Identify and follow the next page link
next_page = response.css('li.next a::attr(href)').get()
if next_page is not None:
yield response.follow(next_page, self.parse)配置设置
要设置Scrapy项目参数,如用户代理、下载延迟和管道,编辑settings.py文件。以下是如何更改用户代理并使管道功能化的示例:
# Obey robots.txt rules
ROBOTSTXT_OBEY = True
# Set user-agent
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'
# Configure pipelines
ITEM_PIPELINES = {
'myproject.pipelines.MyPipeline': 300,
}# Obey robots.txt rules
ROBOTSTXT_OBEY = True
# Set user-agent
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'
# Configure pipelines
ITEM_PIPELINES = {
'myproject.pipelines.MyPipeline': 300,
}开始
使用 Scrapy 和 IronPDF 需要将 Scrapy 强大的网络抓取功能与 IronPDF 的动态 PDF 生成功能结合起来。 下面我将逐步指导您如何设置 Scrapy 项目,以便您可以从网站提取数据并使用 IronPDF 创建包含这些数据的 PDF 文档。
什么是 IronPDF?
IronPDF是一个功能强大的 .NET 库,用于以编程方式使用 C#、VB.NET 和其他 .NET 语言创建、编辑和更改 PDF 文档。 由于它为动态创建高质量PDF提供了广泛的功能集,因此是许多应用程序的热门选择。
IronPDF的功能
PDF 生成:使用 IronPDF,程序员可以创建新的 PDF 文档,或将现有的 HTML 元素(如标签、文本、图像和其他文件格式)转换为 PDF。 这一特性对于动态创建报告、发票、收据和其他文档非常有用。
HTML 转 PDF 转换: IronPDF 使开发人员能够轻松地将 HTML 文档(包括 JavaScript 和 CSS 中的样式)转换为 PDF 文件。 这使得可以从网页、动态生成的内容和 HTML 模板创建 PDF 文件成为可能。
PDF 文档的修改和编辑: IronPDF 提供了一套全面的功能,用于修改和更改预先存在的 PDF 文档。 开发人员可以合并多个 PDF 文件,将它们拆分成单独的文档,删除页面,并添加书签、注释和水印等功能,以根据自己的需求自定义 PDF。
如何安装 IronPDF
确认计算机上已安装 Python 后,使用 pip 安装 IronPDF。
pip install ironpdf
使用 IronPDF 的 Scrapy 项目
要定义您的爬虫,需在Scrapy项目(example.py)。 以下是一个从 URL 中提取引用的基本爬虫代码示例:
import scrapy
from IronPdf import *
class QuotesSpider(scrapy.Spider):
name = 'quotes'
# Web page link
start_urls = ['http://quotes.toscrape.com']
def parse(self, response):
quotes = []
for quote in response.css('div.quote'):
title = quote.css('span.text::text').get()
content = quote.css('span small.author::text').get()
quotes.append((title, content)) # Append quote to list
# Generate PDF document using IronPDF
renderer = ChromePdfRenderer()
pdf = renderer.RenderHtmlAsPdf(self.get_pdf_content(quotes))
pdf.SaveAs("quotes.pdf")
def get_pdf_content(self, quotes):
# Generate HTML content for PDF using extracted quotes
html_content = "<html><head><title>Quotes</title></head><body>"
for title, content in quotes:
html_content += f"<h2>{title}</h2><p>Author: {content}</p>"
html_content += "</body></html>"
return html_contentimport scrapy
from IronPdf import *
class QuotesSpider(scrapy.Spider):
name = 'quotes'
# Web page link
start_urls = ['http://quotes.toscrape.com']
def parse(self, response):
quotes = []
for quote in response.css('div.quote'):
title = quote.css('span.text::text').get()
content = quote.css('span small.author::text').get()
quotes.append((title, content)) # Append quote to list
# Generate PDF document using IronPDF
renderer = ChromePdfRenderer()
pdf = renderer.RenderHtmlAsPdf(self.get_pdf_content(quotes))
pdf.SaveAs("quotes.pdf")
def get_pdf_content(self, quotes):
# Generate HTML content for PDF using extracted quotes
html_content = "<html><head><title>Quotes</title></head><body>"
for title, content in quotes:
html_content += f"<h2>{title}</h2><p>Author: {content}</p>"
html_content += "</body></html>"
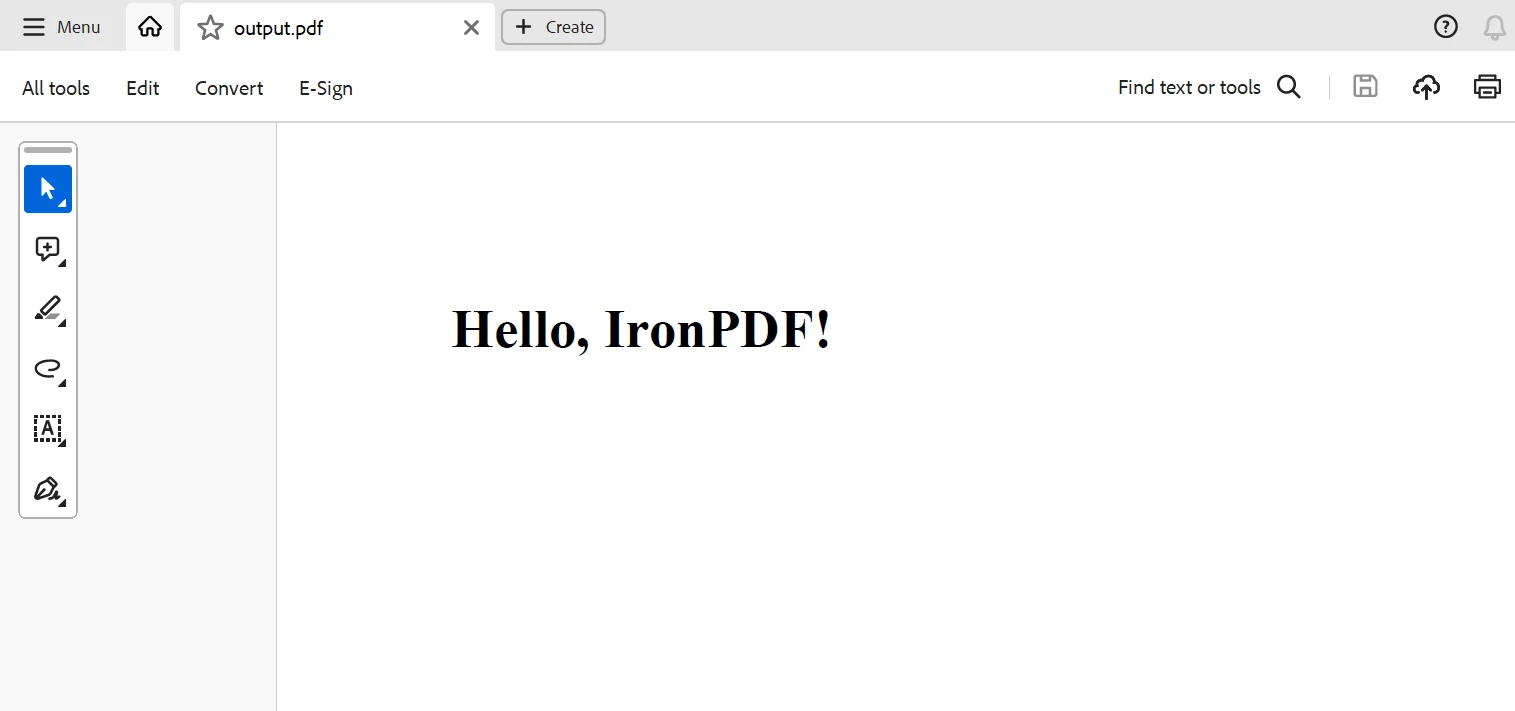
return html_content在上面使用 IronPDF 的 Scrapy 项目代码示例中,IronPDF 正在使用 Scrapy 提取的数据创建PDF 文档。
在这里,爬虫的quotes.pdf。
结论
总而言之,Scrapy 和 IronPDF 的结合为开发人员提供了一个强大的选择,可以自动执行网络抓取活动并即时生成 PDF 文档。 IronPDF 灵活的 PDF 生成功能与 Scrapy 强大的网络爬虫和抓取功能相结合,可轻松从任何网页收集结构化数据,并将提取的数据转换为专业质量的 PDF 报告、发票或文档。
通过使用 Scrapy Spider Python,开发人员可以有效地驾驭互联网的复杂性,从多个来源检索信息,并以系统的方式进行整理。 Scrapy 的灵活框架、异步架构以及对 XPath 和 CSS 选择器的支持,使其具备管理各种网络抓取活动所需的灵活性和可扩展性。
IronPDF随附的终身许可证,当以套装购买时价格合理。 该软件包提供了极高的性价比,仅需$799(一次性购买,可用于多个系统)。 持有许可证的人可24/7访问在线技术支持。 有关费用的更多详情,请访问网站。 访问此页面了解更多关于Iron Software产品的信息。
常见问题解答
如何将 Scrapy 与 PDF 生成工具集成?
您可以通过首先使用 Scrapy 从网站提取结构化数据,然后使用 IronPDF 将其转换为动态 PDF 文档来将 Scrapy 与像 IronPDF 这样的 PDF 生成工具集成在一起。
抓取数据并将其转换为 PDF 的最佳方法是什么?
抓取数据并将其转换为 PDF 的最佳方法是使用 Scrapy 高效提取数据,使用 IronPDF 从提取的内容生成高质量的 PDF。
如何在Python中将HTML转换为PDF?
虽然 IronPDF 是一个 .NET 库,但可以通过像 Python.NET 这样的互操作性解决方案将其用于 Python,以使用 IronPDF 的转换方法将 HTML 转换为 PDF。
使用 Scrapy 进行网页抓取的优势是什么?
Scrapy 提供的优势包括异步处理、强大的 XPath 和 CSS 选择器以及可自定义的中间件,这些都简化了从复杂网站提取数据的过程。
我可以自动从网络数据创建 PDF 吗?
是的,您可以通过集成 Scrapy 进行数据提取和 IronPDF 生成 PDF,实现从抓取到文档创建的无缝工作流程,从而自动化从网络数据创建 PDF。
中间件在 Scrapy 中的作用是什么?
Scrapy 中的中间件允许您控制和自定义请求和响应的处理,启用自动 URL 过滤和用户代理轮换等功能,以提高抓取效率。
您如何在 Scrapy 中定义一个蜘蛛?
要在 Scrapy 中定义一个蜘蛛,在项目的 spiders 目录中创建一个新 Python 文件,并实现一个扩展 scrapy.Spider 的类,其中包含 parse 等方法来处理数据提取。
是什么让 IronPDF 成为 PDF 生成的合适选择?
IronPDF 是 PDF 生成的合适选择,因为它提供了全面的 HTML 到 PDF 转换、动态 PDF 创建、编辑和操作功能,使其适用于各种文档生成需求。
我如何增强网页数据提取和 PDF 创建?
增强网页数据提取和 PDF 创建的方法是使用 Scrapy 高效抓取数据,并使用 IronPDF 将提取的数据转换为专业格式的 PDF 文档。