Test in a live environment
Test in production without watermarks.
Works wherever you need it to.
The Python PDF Library

In today's fast-paced business environment, efficient invoice data extraction is crucial for streamlining financial operations. One of the most common challenges faced by organizations is extracting valuable invoice data from PDF documents. In this article, we will explore how Python, a versatile and powerful programming language, can be harnessed to automate the extraction of essential information from invoices in PDF format, such as Invoice Date, Amount, and Invoice Number. By leveraging Python's robust libraries and tools, businesses can significantly reduce manual data extraction and entry, minimize errors, and enhance their overall productivity in managing invoices. Join us on this journey to discover how Python can revolutionize your invoice processing workflow.
In this article, we will discuss how you can extract text data from invoice PDF files using the IronPDF library for Python.
PdfDocument.FromFile method to open a PDF file.ExtractAllText method.print method to print all the extracted data from the invoice.IronPDF for Python is a robust library using Python that serves as a bridge between Python applications and PDF documents. This versatile tool provides developers with the means to effortlessly create, manipulate, and interact with PDF files within their Python projects. Here are some of the standout features that make IronPDF a valuable asset:
Setting up the environment for IronPDF in Python involves a few steps to ensure that you can start using the library effectively. Here's a step-by-step guide:
pip install ironpdf
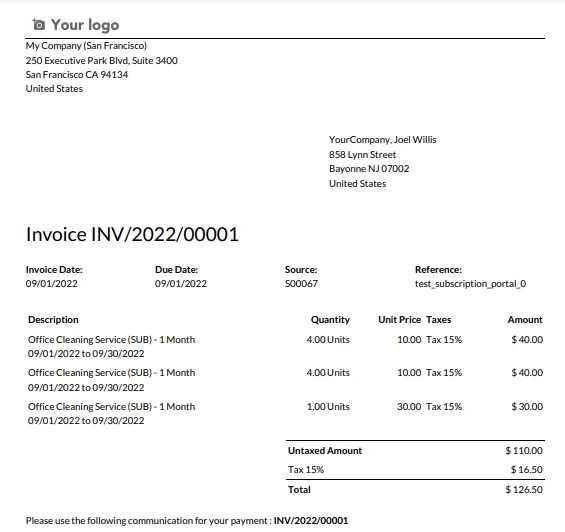
In this section of the article, we will see how to extract data from the invoice format and output format using the Python library IronPDF. The below code will extract all the data from the invoice and print it in the console.
from ironpdf import *
pdf = PdfDocument.FromFile("INV_2022_00001.pdf")
all_text = pdf.ExtractAllText()
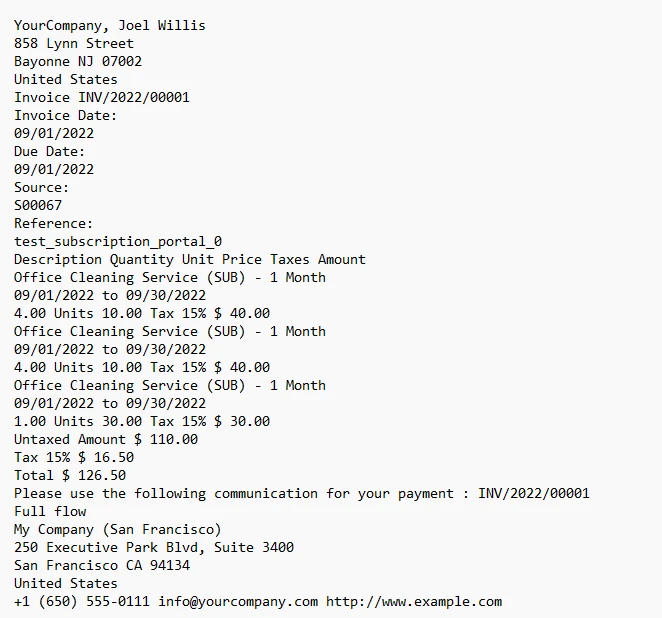
print(all_text)The above code loads a specific PDF file named "INV_2022_00001.pdf" using the PdfDocument.FromFile method. Subsequently, it extracts data on all the text content from the loaded PDF document and stores it in the variable all_text. Finally, the extracted text is printed to the console using the print function. Essentially, this code automates the process of extracting text structured data and unstructured data from a PDF file, making it accessible for further processing or analysis in a Python environment.
Using IronPDF invoice data extraction is quite an easy process, as we see in the above example. Extracting data such as Invoice Number and amount from the PDF invoice data can be a tricky process, but using IronPDF and help with the Python Open-Source library 're,' it can be achieved. The below code will extract data from PDF invoices and print them in the console.
from ironpdf import *
import re
invoice_number_pattern = r"Invoice\s+(INV/\d{4}/\d{5})"
amount_pattern = r"Total\s+\$\s*([\d,.]+(?:\.\d{2})?)"
pdf = PdfDocument.FromFile("INV_2022_00001.pdf")
all_text = pdf.ExtractAllText()
invoice_number_match = re.search(invoice_number_pattern, all_text)
amount_match = re.search(amount_pattern, all_text)
invoice_number = invoice_number_match.group(1) if invoice_number_match else "Not found"
amount = amount_match.group(1) if amount_match else "Not found"
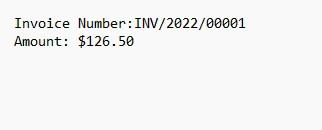
print('Invoice Number:' + invoice_number + '\n Amount:$' + amount)This code snippet utilizes Python and the IronPDF library to perform data extraction from a PDF document. It starts by importing the necessary libraries and defining regular expression patterns for identifying an invoice number and a total amount within the PDF's text content. The code then loads the target PDF, extracts all of its text, and proceeds to search for matches of the defined patterns.
If successful matches are found, it stores the corresponding values for the invoice number and amount; otherwise, it assigns "Not found." Finally, the script and output file print the extracted invoice number and amount output to the console, providing a streamlined way to automate the extraction of specific data from PDF documents, a task commonly encountered in various data processing and accounting applications.
In today's fast-paced business landscape, Python stands as a formidable ally for organizations seeking to streamline their financial operations by automating the extraction of crucial data from PDF invoices. Leveraging Python's capabilities and the IronPDF library, businesses can significantly reduce manual data entry, mitigate errors, save time, and enhance overall productivity in the accounting process of managing invoices. IronPDF, with its versatile features, such as PDF generation, HTML to PDF conversion, PDF editing, merging, splitting, form handling, digital signatures, and accurate data extraction, emerges as a powerful tool for these tasks.
By following simple setup procedures, Python developers can swiftly integrate IronPDF into their projects, revolutionizing their invoice processing workflows and making data extraction from invoices a seamless and efficient process. The code example of data extraction using IronPDF can be found here. The complete tutorial on data extraction using IronPDF Python is available on the following link, and for Invoice Extraction using C#, visit here.
30-day Trial Key instantly.
30-day Trial Key instantly.
Your trial key should be in the email.
If it is not, please contact
support@ironsoftware.com

pip install ironpdf-2024.5-py37-none-win_amd64.whiWant to deploy IronPDF to a live project for FREE?
Your trial key should be in the email.![]()
The trial form was submitted
successfully.
If it is not, please contact
support@ironsoftware.com
Want to deploy IronPDF to a live project for FREE?
Your trial key should be in the email.![]()
The trial form was submitted
successfully.
If it is not, please contact
support@ironsoftware.com
Want to deploy IronPDF to a live project for FREE?
Your trial key should be in the email.![]()
The trial form was submitted
successfully.
If it is not, please contact
support@ironsoftware.com
Want to deploy IronPDF to a live project for FREE?
Your trial key should be in the email.![]()
The trial form was submitted
successfully.
If it is not, please contact
support@ironsoftware.com

Get started for FREE
No credit card required
Test in production without watermarks.
Works wherever you need it to.
Get 30 days of fully functional product.
Have it up and running in minutes.
Full access to our support engineering team during your product trial
![]() No credit card or account creation required
No credit card or account creation required
Your trial key should be in the email.
If it is not, please contact
support@ironsoftware.com
Get started for FREE
No credit card required
Test in production without watermarks.
Works wherever you need it to.
Get 30 days of fully functional product.
Have it up and running in minutes.
Full access to our support engineering team during your product trial
![]() No credit card or account creation required
No credit card or account creation required
Your trial key should be in the email.
If it is not, please contact
support@ironsoftware.com
Get started for FREE
No credit card required
Test in production without watermarks.
Works wherever you need it to.
Get 30 days of fully functional product.
Have it up and running in minutes.
Full access to our support engineering team during your product trial
Licenses from $749. Have a question? Get in touch.
9 .NET API products for your office documents
Thank you!
Your license key has been delivered to the email provided. Contact us

24-Hour Upgrade Offer:
Save 50% on a
Professional Upgrade
Go Professional to cover 10 developers
and unlimited projects.
hours
:
minutes
:
seconds

Professional
$600 USD
$299 USD
5 .NET Products for the Price of 2
Total Suite Value:
$7,192 USD