
HTTPX Python (Cómo Funciona: Una Guía para Desarrolladores)
HTTPX es un cliente HTTP moderno y completo for Python que presenta APIs síncronas y asíncronas. Esta biblioteca ofrece alta eficiencia en el manejo de HTTP requests. Varias características de esta biblioteca amplían las bibliotecas tradicionales como Requests; por lo tanto, es más poderosa porque soporta HTTP/2, agrupación de conexiones y manejo de cookies.
Integrado con IronPDF, una biblioteca .NET integral para crear y editar todos los documentos PDF, HTTPX puede obtener datos de APIs web o incluso sitios web y convertir esos datos obtenidos en largos y bien formateados reportes PDF. Uno puede producir documentos profesionales y bien presentados con la capacidad de IronPDF de generar un PDF desde HTML, imágenes y texto simple, e incluso soportar características avanzadas, como agregar encabezados, pies de página y marcas de agua. La integración es completa: desde la obtención de datos hasta la producción de informes, ofrece una manera eficiente de comunicar insights en forma pulida.
¿Qué es Httpx python?
HTTPX es un cliente HTTP de próxima generación y moderno for Python que toma algunas formas ingeniosas de usar la popular biblioteca Requests y las combina con soporte de API síncronas y asíncronas. Busca resolver tareas HTTP complejas con diferentes funcionalidades avanzadas como soporte HTTP/2, agrupación de conexiones o incluso manejo automático de cookies. HTTPX permite a los desarrolladores enviar múltiples solicitudes HTTP diferentes simultáneamente, acelerando el rendimiento de una aplicación en los casos donde las interacciones basadas en la web son las funcionalidades esperadas más importantes.
Ofrece una excelente interoperabilidad con la biblioteca Requests, proporcionando una vía de actualización fácil para los desarrolladores que desean mejorar su cliente HTTP y acceder a características más complejas. HTTPX es una herramienta flexible para el desarrollo Python moderno; se presta bien para tareas que van desde consultas HTTP simples hasta interacciones más complicadas y críticas en rendimiento web. HTTPX puede hacer solicitudes síncronas y asíncronas con soporte de conexión de proxy de socks.
Características de Httpx python
HTTPX en Python proporciona las características más valiosas que extienden y mejoran el manejo de solicitudes HTTP. Algunas características clave son:
APIs Síncronas y Asíncronas:
Soporta el manejo de solicitudes tanto síncronas como asíncronas. Un desarrollador puede aplicar cualquiera de las opciones disponibles en una aplicación según sus necesidades.
Soporte HTTP/2:
Este marco tiene soporte nativo para el protocolo HTTP/2, permitiendo una comunicación más rápida y eficiente con servidores que lo soportan.
Agrupación de Conexiones:
Conexión HTTP inteligente: Reutiliza las conexiones ya establecidas y las sesiones agrupadas de conexiones para reducir la latencia y aumentar la velocidad para muchas solicitudes.
Decodificación Automática de Contenido:
Automatiza la decodificación de una respuesta comprimida, usualmente codificada en gzip, lo que facilita mucho su manejo y reduce el ancho de banda.
Timeouts y Reintentos:
Define la configuración de solicitudes de timeout para garantizar solicitudes no bloqueantes que sobrepasen el timeout de la solicitud—mecanismos adicionales de reintento para tratar fallas transitorias.
Soporte WebSockets:
Soporta conexiones WebSocket, permitiendo la comunicación bidireccional entre el cliente y el servidor sobre una única conexión de larga duración.
Soporte de Proxy:
Tiene soporte incorporado para proxies HTTP. Esto permitirá solicitudes a través de servidores intermediarios para la privacidad o la gestión de red.
Manejo de Cookies:
La biblioteca manejará las cookies, manteniendo el estado de la sesión entre solicitudes.
Certificado de Cliente:
Se soportan certificados del lado del cliente para asegurar las comunicaciones con servidores que usan autenticación mutua TLS.
Middleware y Hooks:
Permite la personalización del manejo de solicitudes y respuestas con middleware y hooks. Esto proporciona una excelente extensibilidad para que los desarrolladores extiendan la funcionalidad de HTTPX de acuerdo a sus requerimientos. Compatibilidad con Requests: Está diseñado para usar la API de Requests, haciendo que sea muy fácil para los desarrolladores de Requests cambiar al proyecto HTTPX y obtener muchas nuevas características y mejoras excelentes.
Crear y configurar Httpx python.
Primero, debe instalar la biblioteca y configurar un entorno para configurar HTTPX en Python. El proyecto HTTPX depende de HTTP core y la autodetección de la biblioteca async como dependencias, pero deberían instalarse directamente al instalar el proyecto HTTPX. También hay una variación de HTTPX como soporte del cliente de línea de comandos que viene junto con un soporte rico para terminal; sin embargo, en este artículo estaríamos enfocados estrictamente en HTTPX python. La guía a continuación muestra un ejemplo de una simple solicitud HTTP GET. Para una referencia más completa del API, por favor visite la documentación de HTTPX aquí.
Instalar HTTPX
Primero, asegúrese de tener HTTPX instalado. Puede usar el cliente de línea de comandos para instalar:
pip install httpxpip install httpxImportar HTTPX y Hacer una Solicitud Básica
Cuando esté instalado, usted puede importar HTTPX y hacer una simple solicitud HTTP GET de la siguiente manera:
import httpx
# Example usage
url = 'https://jsonplaceholder.typicode.com/posts/1'
# Create a client instance to manage HTTP requests
response = httpx.get(url)
# Print response HTTP status codes and content
print(f"Status Code: {response.status_code}")
# Print Unicode Response Bodies
print(f"Response Content: {response.text}")import httpx
# Example usage
url = 'https://jsonplaceholder.typicode.com/posts/1'
# Create a client instance to manage HTTP requests
response = httpx.get(url)
# Print response HTTP status codes and content
print(f"Status Code: {response.status_code}")
# Print Unicode Response Bodies
print(f"Response Content: {response.text}")- Una función fetch_data, usando un administrador de contexto asincrónico interno para abrir un cliente HTTP, hace una solicitud GET a una URL dada.
- Almacena el objeto de respuesta HTTP devuelto por
httpx.get(url).
Configurando Características Avanzadas en HTTPX
Las características avanzadas de HTTPX soportan una amplia gama de otras configuraciones, como el manejo de proxies, cabezales y timeouts. Aquí esta cómo configurar HTTPX con más opciones:
import httpx
def fetch_data_with_config(url):
# Create a client with a timeout and custom headers
with httpx.Client(timeout=30, headers={"User-Agent": "MyApp/1.0"}) as client:
response = client.get(url)
return response
# Example usage
url = 'https://jsonplaceholder.typicode.com/posts/1'
response = fetch_data_with_config(url)
# Print response status code and content
print(f"Status Code: {response.status_code}")
print(f"Response Content: {response.json()}")import httpx
def fetch_data_with_config(url):
# Create a client with a timeout and custom headers
with httpx.Client(timeout=30, headers={"User-Agent": "MyApp/1.0"}) as client:
response = client.get(url)
return response
# Example usage
url = 'https://jsonplaceholder.typicode.com/posts/1'
response = fetch_data_with_config(url)
# Print response status code and content
print(f"Status Code: {response.status_code}")
print(f"Response Content: {response.json()}")- Tiempo de espera: establece el tiempo de espera para la solicitud HTTP en 30 segundos. Esto es para prevenir que la solicitud se bloquee indefinidamente.
- Agrega un encabezado
User-Agentpersonalizado a la solicitud{ "User-Agent": "MyApp/1.0" }, que identifica la aplicación cliente. - response.json() - Esto analiza el contenido de la respuesta como JSON, asumiendo que la respuesta incluye datos JSON.

Empezando
Para usar HTTPX con Python e IronPDF para generar PDFs. Primero, necesita configurar HTTPX para obtener datos de alguna fuente, y luego IronPDF creará un informe PDF a partir de los datos adquiridos. Aquí está cómo hacerlo en detalle:
¿Qué es IronPDF?
La poderosa y robusta biblioteca for Python, IronPDF, permite la producción, edición y lectura de PDFs. Permite a los programadores realizar muchas operaciones basadas en programación en PDFs, como editar PDFs ya existentes y convertir archivos HTML en archivos PDF. IronPDF hace que la generación de informes de alta calidad en formato PDF sea más sencilla y flexible. En consecuencia, esto lo hace práctico para aplicaciones que crean y procesan PDFs dinámicamente.
Conversión de HTML a PDF
IronPDF permite la conversión de cualquier dato HTML en un documento PDF, independientemente de la edad. Esto permite la creación de publicaciones PDF impresionantes y artísticas a partir del contenido web que aprovecha plenamente las capacidades modernas de HTML5, CSS3 y JavaScript.
Crear y editar PDF
Es posible generar nuevos documentos PDF que contengan texto, imágenes, tablas y otros contenidos a través de un lenguaje de programación. IronPDF también puede abrir y modificar documentos PDF preexistentes para mayor personalización. Cualquier contenido incluido en un documento PDF puede ser añadido, cambiado o eliminado a voluntad.
Diseño y estilo complejos
Esto se consigue a través de la estilización de contenido PDF lograda por CSS, que puede manejar diseños intrincados con varias fuentes, colores y otros elementos de diseño. Además, el manejo de contenido dinámico dentro de PDFs está asegurado en lugar de JavaScript, lo que facilitará la representación de contenido HTML.
Instalar IronPDF
IronPDF puede ser instalado con pip. El comando para instalar es el siguiente:
pip install ironpdfpip install ironpdfCombina httpx con IronPDF for Python
Usar HTTPX para Obtener Datos de una API o Sitio Web. El siguiente ejemplo muestra cómo recuperar datos de una API falsa en formato JSON.
import httpx
from ironpdf import ChromePdfRenderer
# Set your IronPDF license key
License.LicenseKey = ""
def fetch_data_with_config(url):
# Create an HTTPX client with added configurations
with httpx.Client(timeout=30, headers={"User-Agent": "MyApp/1.0"}) as client:
response = client.get(url)
return response
# Example usage
url = 'https://jsonplaceholder.typicode.com/posts/1'
response = fetch_data_with_config(url)
# Create a PDF document renderer
iron_pdf = ChromePdfRenderer()
# Create HTML content from fetched data
html_content = f"""
<html>
<head><title>Data Report</title></head>
<body>
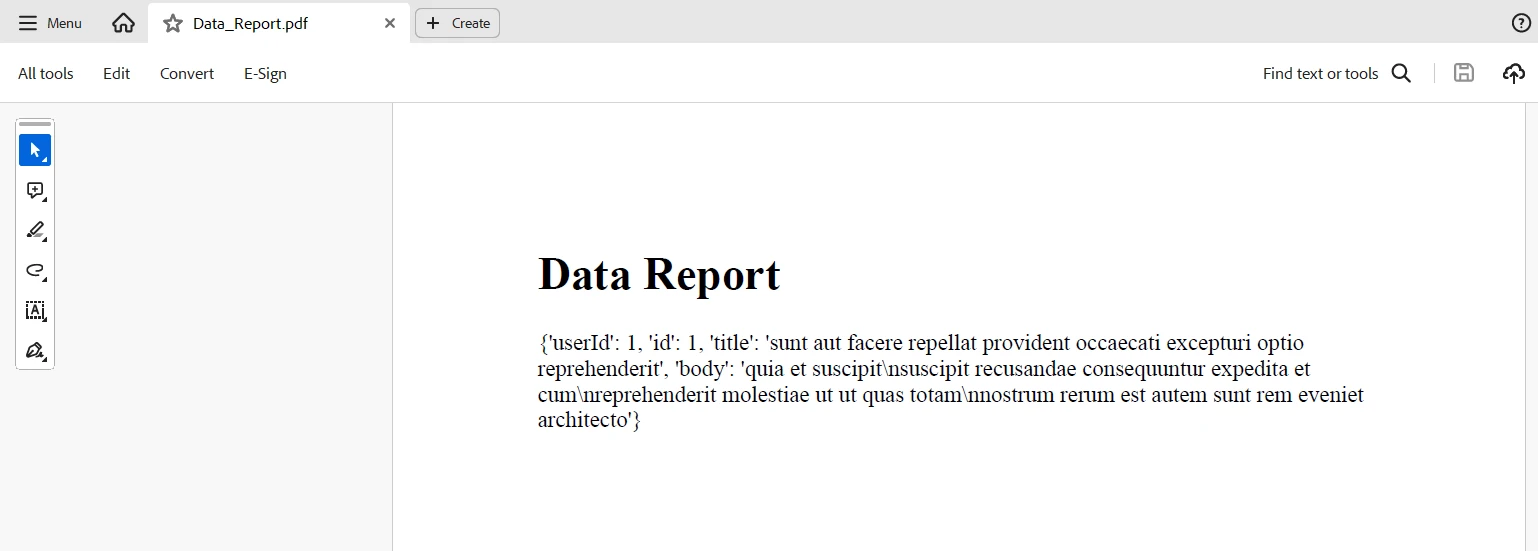
<h1>Data Report</h1>
<p>{response.json()}</p>
</body>
</html>"""
# Render the HTML content as a PDF
pdf = iron_pdf.RenderHtmlAsPdf(html_content)
# Save the PDF document
pdf.SaveAs("Data_Report.pdf")
print("PDF document generated successfully.")import httpx
from ironpdf import ChromePdfRenderer
# Set your IronPDF license key
License.LicenseKey = ""
def fetch_data_with_config(url):
# Create an HTTPX client with added configurations
with httpx.Client(timeout=30, headers={"User-Agent": "MyApp/1.0"}) as client:
response = client.get(url)
return response
# Example usage
url = 'https://jsonplaceholder.typicode.com/posts/1'
response = fetch_data_with_config(url)
# Create a PDF document renderer
iron_pdf = ChromePdfRenderer()
# Create HTML content from fetched data
html_content = f"""
<html>
<head><title>Data Report</title></head>
<body>
<h1>Data Report</h1>
<p>{response.json()}</p>
</body>
</html>"""
# Render the HTML content as a PDF
pdf = iron_pdf.RenderHtmlAsPdf(html_content)
# Save the PDF document
pdf.SaveAs("Data_Report.pdf")
print("PDF document generated successfully.")- Esto está diseñado para obtener datos de APIs web o sitios web de forma sincrónica utilizando HTTPX. Es una biblioteca práctica porque está preparada para operaciones tanto síncronas como asíncronas, procesando diferentes solicitudes HTTP simultáneamente. Un ejemplo sería golpear un endpoint de API simulada que retorna datos JSON.
- IronPDF es utilizado a través de Python; un motor .NET contratado para producir informes PDF con los datos anteriormente mencionados. IronPDF puede generar PDFs a partir de contenido HTML y convertir estos datos en documentos estructurados.
- Integración de IronPDF: Python permite interactuar con IronPDF. Esto dará como resultado el desarrollo de un documento PDF (
pdf) basado en contenido HTML generado dinámicamente (html_content). Los datos son obtenidos a través de HTTPX. Este contenido HTML se basará en datos obtenidos de manera dinámica; por lo tanto, se pueden obtener informes personalizados en tiempo real.
Conclusión
Esta integración de HTTPX con IronPDF combina dos potencias en tu Python: la obtención de datos y la generación de PDFs de calidad profesional. Esto significa que HTTPX será perfecto para obtener datos sobre APIs web o sitios web ya que soporta tanto estilos asincrónicos como sincrónicos para el manejo de solicitudes HTTP. Por otro lado, IronPDF facilita la generación de informes PDF pulidos y de calidad profesional a partir de datos obtenidos a través de la interoperabilidad con Python .NET, adornando así esta visualización y transmisión de análisis de datos.
Mitiga todo, desde la obtención de datos más simple hasta la escritura de informes, brindando flexibilidad al tratar con muchas fuentes y formatos de datos discretos. Capacita al desarrollador para generar PDFs detallados para presentación o documentación o incluso archivar todos los hallazgos del análisis de datos. Todas estas utilidades y aplicaciones Python convertirán datos brutos en informes profesionalmente formateados, asegurando la productividad y la toma de decisiones en cualquier dominio elegido.
Integra IronPDF y productos de Iron Software para proporcionar soluciones de software ricas y de alto nivel a sus clientes y sus usuarios. Esto racionalizará las operaciones y procedimientos del proyecto.
Además de todas las características básicas, IronPDF tiene completa documentación, una comunidad activa y actualizaciones frecuentes. En base a esta información, Iron Software es un socio confiable para proyectos de desarrollo de software modernos. Los desarrolladores pueden probar IronPDF para una prueba gratuita para revisar todas sus características. Posteriormente la licencia comienza en $799 y en adelante.
















