
scikit-image Python (Cómo Funciona: Una Guía para Desarrolladores)
Scikit-image es una colección de algoritmos diseñados para el procesamiento de imágenes en Python. Está disponible de forma gratuita y sin restricciones, con código de alta calidad y revisado por pares de una comunidad activa de voluntarios. El proyecto Scikit-image comenzó en Google en 2009 como parte del programa Google Summer Code bajo la tutela de Stefan van der Walt y otros colaboradores de Scikit-image. Tenía como objetivo crear una biblioteca de Python para el procesamiento de imágenes que fuera fácil de usar, eficiente y extensible para aplicaciones académicas e industriales. En este artículo, aprenderemos sobre la biblioteca de imágenes Scikit-image en Python y una biblioteca de generación de PDF de Iron Software llamada IronPDF.
Empezando
Para aprender sobre Scikit-image, visita el sitio web oficial. Además, Data Carpentry ofrece una excelente lección sobre procesamiento de imágenes en Python usando Scikit.
Instalación mediante pip
- Asegúrate de tener Python instalado (al menos la versión 3.10).
Abre tu terminal o símbolo del sistema.
- Actualiza pip:
python -m pip install -U pippython -m pip install -U pipSHELL- Instala scikit-image a través de pip:
python -m pip install -U scikit-imagepython -m pip install -U scikit-imageSHELL- Para acceder a conjuntos de datos de demostración, usa:
python -m pip install -U scikit-image[data]python -m pip install -U scikit-image[data]SHELL- Para obtener paquetes científicos adicionales, incluidas las capacidades de procesamiento paralelo:
python -m pip install -U scikit-image[optional]python -m pip install -U scikit-image[optional]SHELL
Ejemplo básico
import skimage.io
import matplotlib.pyplot as plt
# Load an image from file
image = skimage.io.imread(fname='land.jpg')
# Display the image
plt.imshow(image)
plt.show()import skimage.io
import matplotlib.pyplot as plt
# Load an image from file
image = skimage.io.imread(fname='land.jpg')
# Display the image
plt.imshow(image)
plt.show()Filtros
import skimage as ski
# Load a sample image from the scikit-image default collection
image = ski.data.coins()
# Apply a Sobel filter to detect edges
edges = ski.filters.sobel(image)
# Display the edges
ski.io.imshow(edges)
ski.io.show()import skimage as ski
# Load a sample image from the scikit-image default collection
image = ski.data.coins()
# Apply a Sobel filter to detect edges
edges = ski.filters.sobel(image)
# Display the edges
ski.io.imshow(edges)
ski.io.show()Scikit-image, a menudo abreviado como skimage, es una poderosa biblioteca de Python para tareas de procesamiento de imágenes. Está construida sobre matrices NumPy, SciPy y matplotlib, y proporciona varias funciones y algoritmos para manipular y analizar imágenes. El skimage.data.coins() se utiliza para obtener acceso a imágenes de muestra de la biblioteca. skimage.filters proporciona acceso a filtros integrados y funciones de utilidad.
Características principales de Scikit-image
1. Filtrado de imágenes y detección de bordes
from skimage import io, filters
# Load an image
image = io.imread('image.jpg')
# Apply Gaussian blur
blurred_image = filters.gaussian(image, sigma=1.0)
# Apply Sobel edge detection
edges = filters.sobel(image)
# Display the original image, blurred image, and edges
io.imshow_collection([image, blurred_image, edges])
io.show()from skimage import io, filters
# Load an image
image = io.imread('image.jpg')
# Apply Gaussian blur
blurred_image = filters.gaussian(image, sigma=1.0)
# Apply Sobel edge detection
edges = filters.sobel(image)
# Display the original image, blurred image, and edges
io.imshow_collection([image, blurred_image, edges])
io.show()Resultado
2. Extracción de características con HOG (histograma de gradientes orientados)
from skimage import io, color, feature
# Load an example image and convert to grayscale
image = io.imread('image.jpg')
gray_image = color.rgb2gray(image)
# Compute HOG features and visualize them
hog_features, hog_image = feature.hog(gray_image, visualize=True)
# Display the original image and the HOG image
io.imshow_collection([image, gray_image, hog_image])
io.show()from skimage import io, color, feature
# Load an example image and convert to grayscale
image = io.imread('image.jpg')
gray_image = color.rgb2gray(image)
# Compute HOG features and visualize them
hog_features, hog_image = feature.hog(gray_image, visualize=True)
# Display the original image and the HOG image
io.imshow_collection([image, gray_image, hog_image])
io.show()Resultado
3. Transformación geométrica - Cambio de tamaño y rotación
from skimage import io, transform
# Load an image
image = io.imread('image.jpg')
# Resize image by dividing its dimensions by 2
resized_image = transform.resize(image, (image.shape[0] // 2, image.shape[1] // 2))
# Rotate image by 45 degrees
rotated_image = transform.rotate(image, angle=45)
# Display the original image, resized image, and rotated image
io.imshow_collection([image, resized_image, rotated_image])
io.show()from skimage import io, transform
# Load an image
image = io.imread('image.jpg')
# Resize image by dividing its dimensions by 2
resized_image = transform.resize(image, (image.shape[0] // 2, image.shape[1] // 2))
# Rotate image by 45 degrees
rotated_image = transform.rotate(image, angle=45)
# Display the original image, resized image, and rotated image
io.imshow_collection([image, resized_image, rotated_image])
io.show()Resultado
4. Desnaturalización de imágenes con filtro de variación total
from skimage import io, restoration
# Load a noisy image
image = io.imread('image.jpg')
# Apply total variation denoising
denoised_image = restoration.denoise_tv_chambolle(image, weight=0.1)
# Display the noisy image and the denoised image
io.imshow_collection([image, denoised_image])
io.show()from skimage import io, restoration
# Load a noisy image
image = io.imread('image.jpg')
# Apply total variation denoising
denoised_image = restoration.denoise_tv_chambolle(image, weight=0.1)
# Display the noisy image and the denoised image
io.imshow_collection([image, denoised_image])
io.show()Salida
Puedes encontrar más sobre procesamiento de imágenes y matrices NumPy en la página oficial.
Presentamos IronPDF
IronPDF es una robusta biblioteca de Python diseñada para manejar la creación, edición y firma de documentos PDF utilizando HTML, CSS, imágenes y JavaScript. Prioriza la eficiencia del rendimiento y opera con un uso mínimo de memoria. Las características clave son:
Conversión de HTML a PDF: Convierte archivos HTML, cadenas HTML y URLs en documentos PDF, aprovechando capacidades como la renderización de páginas web usando el motor de renderizado de PDF de Chrome.
Soporte Multiplataforma: Compatible con Python 3+ en Windows, Mac, Linux y varias plataformas en la nube. IronPDF también está disponible para entornos .NET, Java, Python y Node.js.
Edición y Firma: Personaliza las propiedades de PDF, aplica medidas de seguridad como contraseñas y permisos, y aplica firmas digitales sin problemas.
Plantillas y Configuraciones de Página: Crea diseños de PDF con características como encabezados, pies de página, números de página, márgenes ajustables, tamaños de papel personalizados y diseños responsivos.
- Cumplimiento de Estándares: Se adhiere estrictamente a los estándares de PDF como PDF/A y PDF/UA, garantiza la compatibilidad con codificación de caracteres UTF-8, y maneja hábilmente activos como imágenes, hojas de estilo CSS y fuentes.
Instalación
pip install ironpdf
pip install scikit-imagepip install ironpdf
pip install scikit-imageGenerar documentos PDF con IronPDF y Scikit Image
Prerrequisitos
- Asegúrate de que Visual Studio Code esté instalado como editor de código
- La versión 3 de Python esté instalada
Para empezar, crearemos un archivo Python para añadir nuestros guiones.
Abra Visual Studio Code y cree un archivo, scikitDemo.py.
Instale las bibliotecas necesarias:
pip install scikit-image
pip install ironpdfpip install scikit-image
pip install ironpdfLuego añade el siguiente código en Python para demostrar el uso de los paquetes IronPDF y scikit-image en Python.
from skimage import io, filters
from ironpdf import *
# Apply your license key
License.LicenseKey = "YOUR_LICENSE_KEY"
# Load an image
image = io.imread('image.jpg')
# Apply Gaussian blur
blurred_image = filters.gaussian(image, sigma=1.0)
# Apply Sobel edge detection
edges = filters.sobel(image)
# Save the results to a file
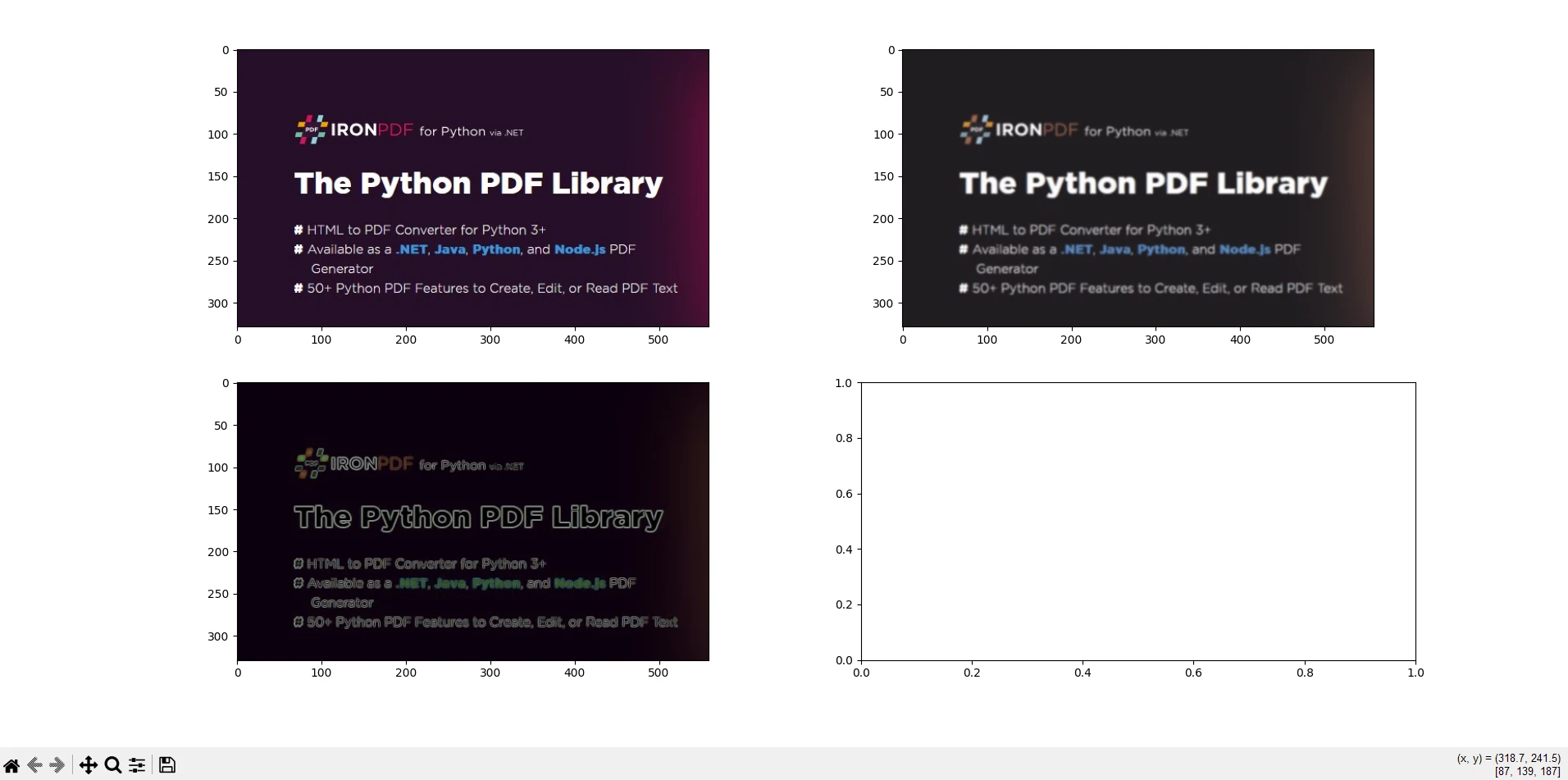
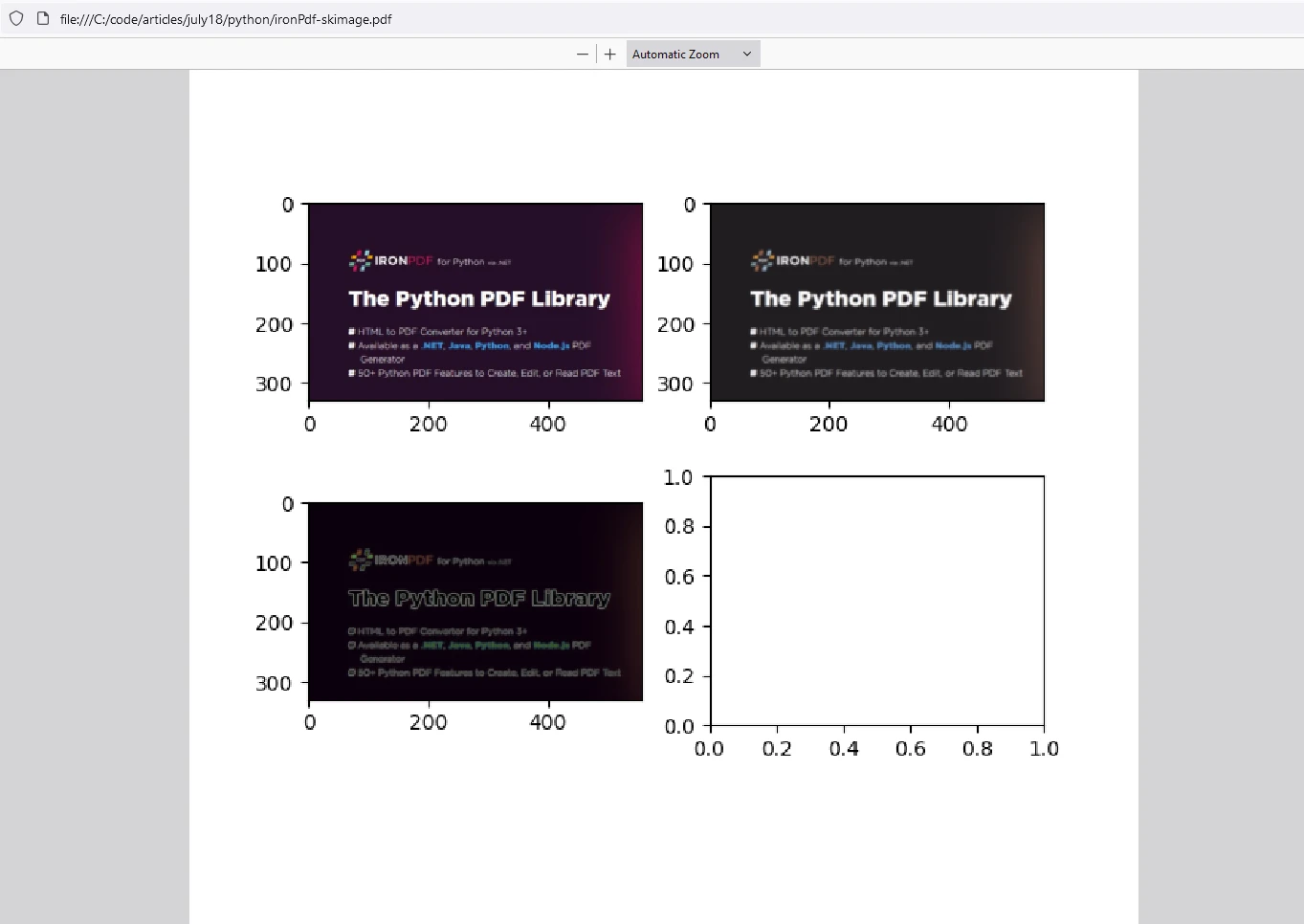
io.imshow_collection([image, blurred_image, edges]).savefig('ironPdf-skimage.png')
# Convert the saved image to a PDF document
ImageToPdfConverter.ImageToPdf("ironPdf-skimage.png").SaveAs("ironPdf-skimage.pdf")
# Display the images
io.show()from skimage import io, filters
from ironpdf import *
# Apply your license key
License.LicenseKey = "YOUR_LICENSE_KEY"
# Load an image
image = io.imread('image.jpg')
# Apply Gaussian blur
blurred_image = filters.gaussian(image, sigma=1.0)
# Apply Sobel edge detection
edges = filters.sobel(image)
# Save the results to a file
io.imshow_collection([image, blurred_image, edges]).savefig('ironPdf-skimage.png')
# Convert the saved image to a PDF document
ImageToPdfConverter.ImageToPdf("ironPdf-skimage.png").SaveAs("ironPdf-skimage.pdf")
# Display the images
io.show()Explicación del código
Este fragmento de código demuestra cómo utilizar scikit-image (skimage) e IronPDF juntos para procesar una imagen y convertir los resultados en un documento PDF. Aquí hay una explicación de cada parte:
Declaraciones de Importación: Importa funciones necesarias de scikit-image para carga de imágenes y filtrado de imágenes, e importa funcionalidad de IronPDF.
Aplicación de Clave de Licencia: Establece la clave de licencia para IronPDF. Este paso es necesario para usar las funcionalidades de IronPDF.
Carga y procesamiento de una imagen: carga una imagen llamada
'image.jpg'usando la funciónio.imreadde scikit-image. Luego aplica desenfoque gaussiano a la imagen cargada usandofilters.gaussiancon un valor sigma de 1.0, y aplica detección de bordes Sobel a la imagen cargada usandofilters.sobel.Visualización y guardado de resultados:
io.imshow_collection([image, blurred_image, edges]).savefig('ironPdf-skimage.png'): guarda una colección de imágenes (original, borrosa y bordes) como'ironPdf-skimage.png'.Conversión de imagen a PDF:
ImageToPdfConverter.ImageToPdf("ironPdf-skimage.png").SaveAs("ironPdf-skimage.pdf"): Convierte la imagen PNG guardada en un documento PDF utilizando la funcionalidad de IronPDF.- Visualización de las imágenes:
io.show(): Muestra las imágenes en una ventana gráfica.
Este fragmento de código combina las capacidades de scikit-image para el procesamiento de imágenes y IronPDF para convertir imágenes procesadas en documentos PDF. Demuestra cómo cargar una imagen, aplicar desenfoque Gaussiano y detección de bordes Sobel, guardarlas como un archivo PNG, convertir el PNG a PDF usando IronPDF y mostrar las imágenes procesadas. Esta integración es útil para tareas donde las imágenes necesitan ser procesadas, analizadas y documentadas en un formato PDF, como en investigación científica, informes de análisis de imágenes, o flujos de trabajo automatizados de generación de documentos.
Resultado
Licencia de IronPDF
IronPDF funciona con una clave de licencia for Python. IronPDF for Python ofrece una licencia de prueba gratuita para permitir a los usuarios verificar sus amplias funciones antes de la compra.
Coloca la clave de licencia al inicio del guión antes de usar el paquete IronPDF:
from ironpdf import *
# Apply your license key
License.LicenseKey = "YOUR_LICENSE_KEY"from ironpdf import *
# Apply your license key
License.LicenseKey = "YOUR_LICENSE_KEY"Conclusión
scikit-image empodera a los desarrolladores de Python para abordar eficientemente tareas relacionadas con imágenes. Ya sea que estés trabajando en visión por computadora, imágenes médicas o proyectos artísticos, este paquete te tiene cubierto. scikit-image es una biblioteca versátil y poderosa para el procesamiento de imágenes en Python, ofreciendo una amplia gama de funciones y algoritmos para tareas como filtrado, segmentación, extracción de características, y transformaciones geométricas. Su integración perfecta con otras bibliotecas científicas la convierte en una opción preferida para investigadores, desarrolladores e ingenieros que trabajan con análisis de imágenes y aplicaciones de visión por computadora.
IronPDF es una biblioteca de Python que facilita la creación, edición y manipulación de documentos PDF dentro de aplicaciones de Python. Ofrece características como generar archivos PDF desde diversas fuentes como HTML, imágenes o PDFs existentes. Además, IronPDF soporta tareas como fusionar o dividir documentos PDF, añadir anotaciones, marcas de agua o firmas digitales, extraer texto o imágenes de PDFs, y gestionar propiedades de documentos como metadatos y configuraciones de seguridad. Esta biblioteca proporciona una manera eficiente de manejar tareas relacionadas con PDF programáticamente, lo que la hace adecuada para aplicaciones que requieren generación de documentos, creación de informes, o funcionalidades de gestión documental.
Junto con ambas bibliotecas, los usuarios pueden trabajar con imágenes, procesarlas eficientemente y almacenar los resultados en documentos PDF para propósitos de archivo.
















