
Cómo Convertir PDF A Imagen en Python
PDF (Portable Document Format) es el formato de archivo más popular para transferir datos a través de internet, ya que conserva el formato del contenido y ayuda a asegurar los datos con permisos de seguridad. Hay escenarios en los que necesitamos convertir archivos PDF a imágenes JPG u otro formato de imagen, como PNG, BMP, TIFF o GIF. Hay muchos recursos en línea disponibles para la conversión a JPG, pero ¿qué genial sería crear nuestra propia herramienta de conversión de PDF a Imagen en Python?
¿Qué es Python?
Python es un lenguaje de programación de alto nivel que se utiliza para crear aplicaciones de software, sitios web, automatizar tareas, realizar análisis de datos y llevar a cabo tareas de Inteligencia Artificial y Aprendizaje Automático. También es un lenguaje de scripts ya que es interpretado, lo que lo hace más potente en términos de desarrollo y pruebas rápidas.
Para crear un convertidor de PDF a imagen, necesitamos tener Python 3+ instalado en la computadora. Descarga e instala la última versión desde el sitio web oficial.
En este artículo, crearemos nuestra propia aplicación de conversión de imágenes utilizando las bibliotecas de Python para PDF a imagen. Para este propósito, utilizaremos dos de las bibliotecas más populares de Python: PDF2Image y PyMuPDF.
Cómo convertir archivos PDF en archivos de imagen en Python
- Instalar la biblioteca de Python para convertir PDF a imagen.
- Cargar un archivo PDF existente desde cualquier ubicación.
- Utilizar métodos de conversión.
- Iterar por las páginas del archivo.
- Guardar cada página como una imagen JPG o PNG utilizando el método save.
Crear un nuevo archivo Python
- Abre la aplicación IDLE de Python y presiona las teclas Ctrl + N. Se abrirá el editor de texto. Puedes usar el editor de texto de tu preferencia para esto.
- Guarda el archivo como pdf2image.py, en la misma ubicación que el archivo PDF que te gustaría convertir a imágenes.
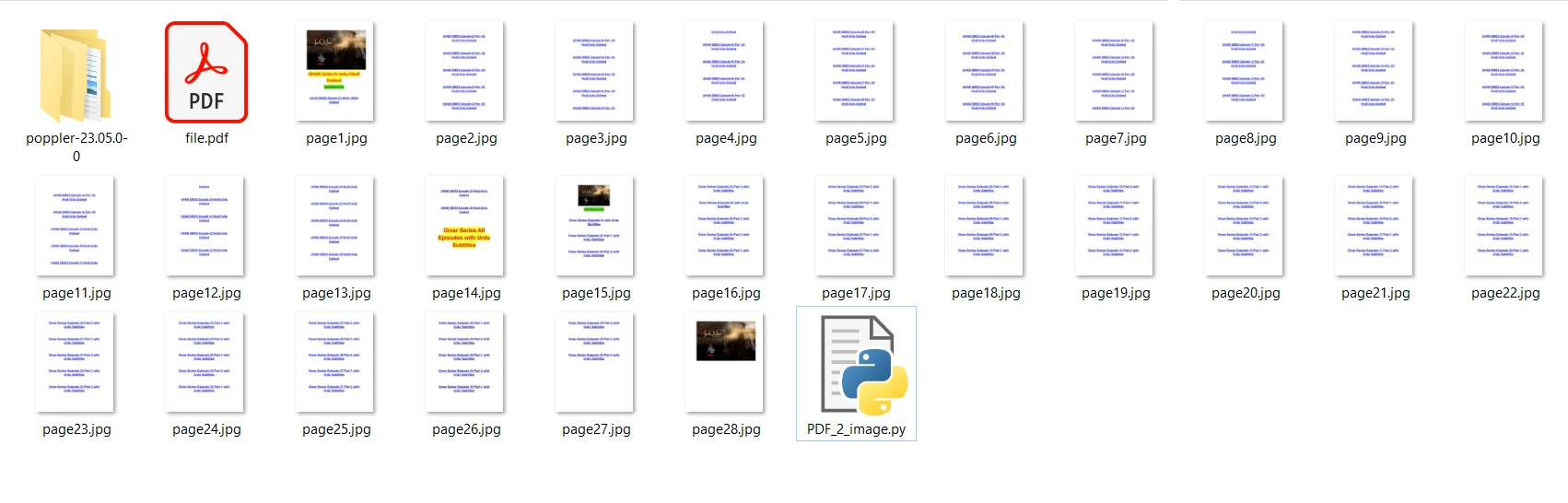
El archivo PDF de entrada que vamos a usar contiene 28 páginas y es el siguiente:

Convertir archivos PDF en archivos de imagen con la biblioteca PDF2Image
1. Instalar PDF2Image Python Library
PDF2Image es un módulo que envuelve pdftocairo y pdftoppm. Funciona en Python 3.7+ para convertir PDF a un objeto de imagen PIL. Su historial de versiones anteriores muestra que solo envuelve pdftoppm para convertir PDF a imágenes y solo funcionaba en Python 3+.
Para instalar el paquete pdf2image, abre tu símbolo del sistema de Windows o Windows PowerShell y usa el siguiente comando pip:
pip install pdf2imagepip install pdf2imagePip (Programador Preferido de Instalación) es el gestor de paquetes for Python. Descarga e instala paquetes de software de terceros que ofrecen características y funcionalidades no encontradas en la biblioteca estándar de Python.
Nota: Para ejecutar este comando desde cualquier parte de la línea de comandos, Python debe estar agregado al PATH. Para Python 3+, se recomienda usar pip3 ya que es la versión actualizada de pip.
2. Instalar Poppler
Poppler es una biblioteca gratuita de código abierto para trabajar con archivos PDF. Se utiliza para renderizar archivos PDF, leer contenido y modificar el contenido dentro de los archivos PDF. Es comúnmente usada por usuarios de Linux. Sin embargo, para Windows, necesitaremos descargar la última versión de Poppler.
Para Windows
Los usuarios de Windows pueden descargar la última versión de Poppler aquí: versión @oschwartz10612. Luego tendrás que agregar la carpeta bin/ al variable de entorno PATH.
Para Mac
Los usuarios de Mac también tendrán que instalar Poppler. Se puede instalar usando Brew:
brew install popplerbrew install popplerPara Linux
La mayoría de las distribuciones de Linux incluyen las utilidades de línea de comandos pdftoppm y pdftocairo. Si estas utilidades no están instaladas, puede utilizar el gestor de paquetes para instalar poppler-utils.
Para plataformas independientes (utilizando conda)
Instalar
poppler:conda install -c conda-forge popplerconda install -c conda-forge popplerSHELLInstalar pdf2image:
pip install pdf2imagepip install pdf2imageSHELL
Ahora todo está listo, comencemos con el código para convertir PDFs a imágenes.
3. Código para convertir archivos PDF en archivos de imagen
El siguiente código realizará la conversión de imagen del archivo PDF de entrada:
from pdf2image import convert_from_path
# Notify the user that the process is starting
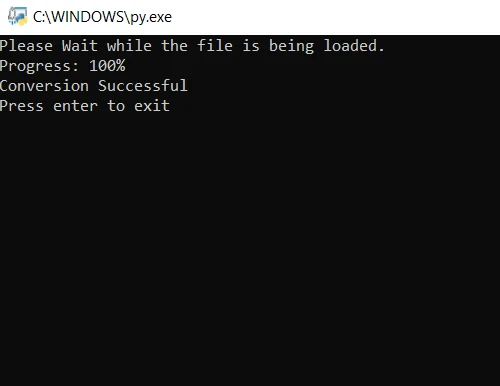
print("Please wait while the file is being loaded.")
file = convert_from_path('file.pdf')
# Iterate over all pages in the PDF file
for i in range(len(file)):
# Update user on progress
print("Progress: " + str(round(i / len(file) * 100)) + "%")
# Save each page as a JPG image file
file[i].save('page' + str(i + 1) + '.jpg', 'JPEG')
# Notify the user that the conversion is successful
print("Conversion Successful")from pdf2image import convert_from_path
# Notify the user that the process is starting
print("Please wait while the file is being loaded.")
file = convert_from_path('file.pdf')
# Iterate over all pages in the PDF file
for i in range(len(file)):
# Update user on progress
print("Progress: " + str(round(i / len(file) * 100)) + "%")
# Save each page as a JPG image file
file[i].save('page' + str(i + 1) + '.jpg', 'JPEG')
# Notify the user that the conversion is successful
print("Conversion Successful")En el código anterior, primero abrimos el archivo utilizando el método convert_from_path. Este método abre el archivo ubicado en la ruta especificada. Luego, iteramos por cada página del archivo PDF para ser convertido a imágenes JPG. Por último, se utiliza el método save para guardar cada página convertida como un archivo de imagen JPG. Ahora, ejecute el programa y espere a que finalice la conversión. Los archivos de imagen de salida se guardan en la misma carpeta que el programa.
Convertir archivos PDF en imágenes con la biblioteca PyMuPDF
1. Instalar la librería Python PyMuPDF
PyMuPDF es un enlace extendido de Python a MuPDF, que es un visor, renderizador y herramienta de libro electrónico, PDF y XPS ligero. Puede ser utilizado para convertir PDF a otros formatos como JPG o PNG. PyMuPDF funciona en versiones de Python 3.7+.
Para instalar el paquete PyMuPDF, abre tu símbolo del sistema de Windows o Windows PowerShell y usa el siguiente comando pip:
pip install pymupdfpip install pymupdfTen en cuenta que PyMuPDF no requiere bibliotecas adicionales como el paquete PDF2Image.
2. Código para convertir archivos PDF en imágenes
El siguiente código importará el módulo fitz de PyMuPDF, para que podamos convertir el PDF en imágenes:
import fitz # PyMuPDF
# Open the PDF file
doc = fitz.open("file.pdf")
# Iterate over each page in the document
for x in range(len(doc)):
page = doc.load_page(x) # Load a specific page
pix = page.get_pixmap() # Render page to image
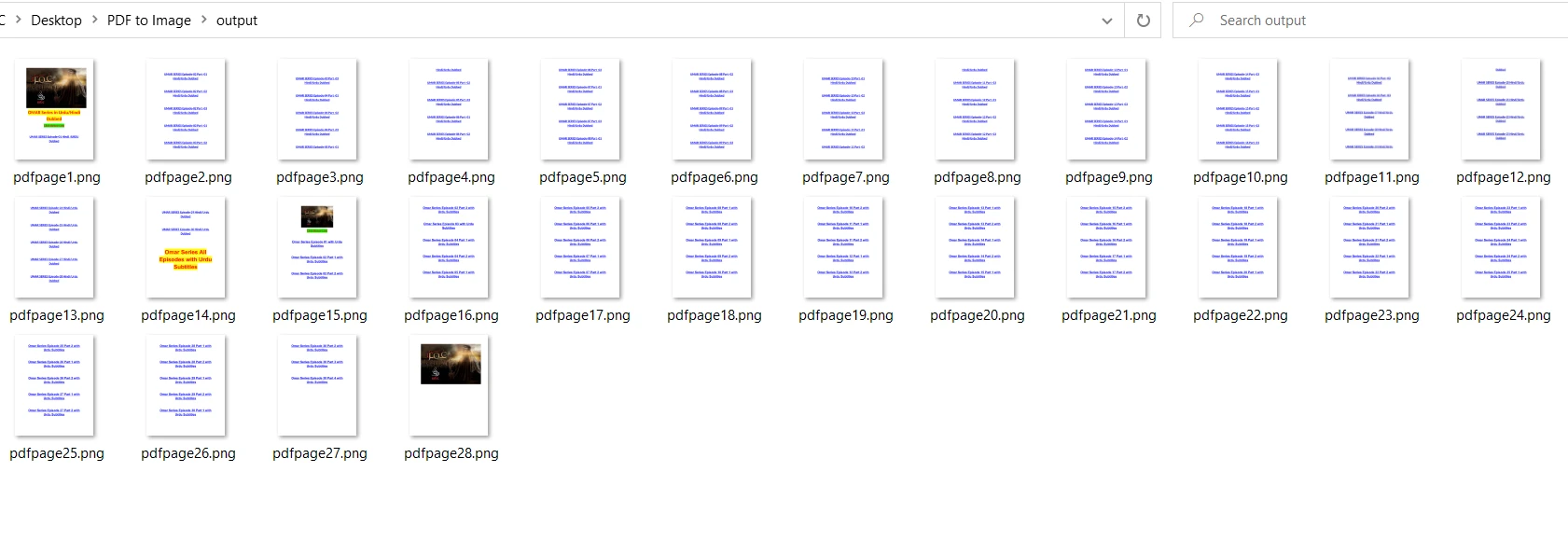
output = "output/pdfpage" + str(x + 1) + ".png" # Specify output path
pix.save(output) # Save the image to the output path
# Close the document
doc.close()import fitz # PyMuPDF
# Open the PDF file
doc = fitz.open("file.pdf")
# Iterate over each page in the document
for x in range(len(doc)):
page = doc.load_page(x) # Load a specific page
pix = page.get_pixmap() # Render page to image
output = "output/pdfpage" + str(x + 1) + ".png" # Specify output path
pix.save(output) # Save the image to the output path
# Close the document
doc.close()En el código anterior, el nombre del archivo se pasa como argumento al método fitz.open para abrir el archivo. A continuación, recorro todo el documento y cargo cada página por separado. El método get_pixmap se utiliza para convertir cada página del documento en píxeles de imagen, y la imagen resultante se guarda en la carpeta de salida mediante el método save. Finalmente, el documento abierto se cierra para liberar memoria.
En comparación con PDF2Image, PyMuPDF es más rápido al convertir PDF a PNG. PDF2Image puede ser lento para el formato PNG debido a su relación de compresión. La salida es la misma que la de PDF2Image:
Rendering PDF to Image Conversions in C
Biblioteca IronPDF
IronPDF es una biblioteca utilizada para generar, leer y manipular archivos PDF. Su especialidad radica en renderizar HTML a PDF con la ayuda del motor de Chromium. Esta característica la hace popular entre los desarrolladores que necesitan convertir archivos HTML o URL a documentos PDF. Además, proporciona conversión de varios formatos a archivos PDF.
También puedes rasterizar un archivo PDF a imágenes usando solo dos líneas de código. El siguiente código demuestra cómo convertir PDFs a diferentes formatos de imagen:
using IronPdf;
var Renderer = new IronPdf.ChromePdfRenderer();
var PDF = Renderer.RenderUrlAsPdf("https://example.com");
PDF.SaveAs("html.pdf");
// Rasterize the PDF
List<string> Images = PDF.RasterizeToImageFiles(ImageType.Png);using IronPdf;
var Renderer = new IronPdf.ChromePdfRenderer();
var PDF = Renderer.RenderUrlAsPdf("https://example.com");
PDF.SaveAs("html.pdf");
// Rasterize the PDF
List<string> Images = PDF.RasterizeToImageFiles(ImageType.Png);Imports IronPdf
Private Renderer = New IronPdf.ChromePdfRenderer()
Private PDF = Renderer.RenderUrlAsPdf("https://example.com")
PDF.SaveAs("html.pdf")
' Rasterize the PDF
Dim Images As List(Of String) = PDF.RasterizeToImageFiles(ImageType.Png)















