
PDFtoText en Python: Un Tutorial Paso a Paso
Los archivos PDF se encuentran entre los formatos más populares de documentos digitales. Son preferidos por su compatibilidad en diferentes sistemas y su capacidad para preservar el formato de documentos complejos.
En la gestión de datos, convertir documentos PDF a formatos editables o extraer texto para análisis es invaluable. Este proceso de conversión permite a las empresas e individuos extraer y aprovechar datos que de otra manera estarían bloqueados dentro de documentos estáticos.
Python, con su extenso ecosistema de bibliotecas, ofrece una forma accesible y poderosa de manipular archivos PDF. Ya sea extrayendo datos, convirtiendo archivos PDF o automatizando la generación de informes, la simplicidad de Python y sus amplias herramientas lo convierten en un lenguaje de referencia para tareas de procesamiento de PDF.
¿Qué es IronPDF?
IronPDF es una biblioteca integral de renderizado de PDF para desarrolladores de Python que facilita la interacción con archivos PDF. Proporciona un robusto conjunto de herramientas que permite la creación, manipulación y conversión de documentos PDF dentro del entorno de programación de Python.
IronPDF une la facilidad de los scripts de Python y las capacidades de gestión de documentos necesarias para el procesamiento de PDF, permitiendo así a los desarrolladores incorporar funcionalidades PDF directamente en sus aplicaciones.
Requisitos del sistema y guía de instalación
Antes de instalar IronPDF, asegúrate de que tu sistema cumpla con los siguientes requisitos:
- Python 3.x instalado en tu sistema.
- Acceso a pip (instalador de paquetes de Python) para una fácil instalación.
- .NET framework si usas un sistema Windows, ya que IronPDF depende de .NET para funcionar.
Una vez que has confirmado que tu sistema cumple con estos requisitos, puedes instalar IronPDF usando pip. Abre tu línea de comandos o terminal y ejecuta el siguiente comando:
pip install ironpdf
Asegúrate de estar usando la última versión de la biblioteca IronPDF for Python. Este comando descargará e instalará la biblioteca IronPDF y todas las dependencias necesarias en tu entorno Python.
Convertir PDF en texto: Un tutorial paso a paso
Paso 1: Importar IronPDF
from ironpdf import *from ironpdf import *Este fragmento de código comienza con una declaración de importación que trae todos los componentes necesarios de la biblioteca IronPDF a tu script de Python. Es esencial para acceder a las clases y métodos proporcionados por IronPDF que te permiten trabajar con archivos PDF.
Paso 2: Configurar el registro
# Enable debugging for IronPDF
Logger.EnableDebugging = True
# Specify the log file path
Logger.LogFilePath = "Custom.log"
# Set logging mode to log all events
Logger.LoggingMode = Logger.LoggingModes.All# Enable debugging for IronPDF
Logger.EnableDebugging = True
# Specify the log file path
Logger.LogFilePath = "Custom.log"
# Set logging mode to log all events
Logger.LoggingMode = Logger.LoggingModes.AllLogger.EnableDebugging = True: habilita la función de depuración dentro de la biblioteca IronPDF para rastrear operaciones, lo cual es crucial para la resolución de problemas.
Logger.LogFilePath = "Custom.log": Especifica la ruta y el nombre del archivo de registro donde se escribirá la información de depuración. Asegúrate de que el directorio sea escribible.
- Logger.LoggingMode = Logger.LoggingModes.All: establece el modo de registro para registrar todos los eventos, incluidos registros de nivel de información, advertencias y errores. Este registro integral ayuda en la depuración.
Paso 3: Cargar el documento PDF
# Load an existing PDF document
pdf = PdfDocument.FromFile("content.pdf")# Load an existing PDF document
pdf = PdfDocument.FromFile("content.pdf")PdfDocument.FromFile("content.pdf"): carga el archivo PDF llamado "content.pdf" en el entorno creando un objeto PdfDocument .
- La variable pdf ahora contiene tu documento PDF y te permite realizar varias operaciones.
Paso 4: Extracción de texto de todo el documento
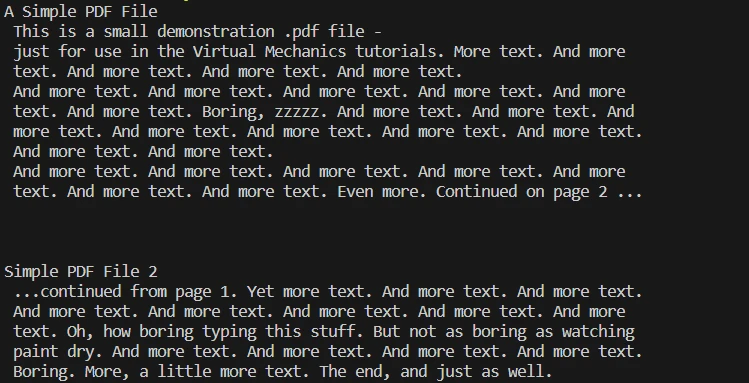
# Extract all text from the PDF document
all_text = pdf.ExtractAllText()
# Print the extracted text
print(all_text)# Extract all text from the PDF document
all_text = pdf.ExtractAllText()
# Print the extracted text
print(all_text)pdf.ExtractAllText(): extrae todo el contenido textual del documento. El texto se almacena luego en la variable all_text.
- print(all_text): imprime el texto extraído en la consola, verificando el proceso de extracción de texto.
Paso 5: Extracción de texto de una página específica
# Load an existing PDF document (already loaded, but shown for clarity)
pdf = PdfDocument.FromFile("content.pdf")
# Extract text from a specific page in the document
page_text = pdf.ExtractTextFromPage(1)
# Print the extracted text from the specific page
print(page_text)# Load an existing PDF document (already loaded, but shown for clarity)
pdf = PdfDocument.FromFile("content.pdf")
# Extract text from a specific page in the document
page_text = pdf.ExtractTextFromPage(1)
# Print the extracted text from the specific page
print(page_text)PdfDocument.FromFile("content.pdf"): demuestra la necesidad de un objeto de archivo PDF (el objeto PdfDocument ) para extraer texto. Esta línea no es necesaria si el documento ya ha sido cargado en un script continuo.
pdf.ExtractTextFromPage(1): extrae texto de la segunda página (índice 1) del PDF.
- El ejemplo asume que imprimirías el texto extraído para verificar la operación: print(page_text).
Este tutorial ofrece una vía clara para que los desarrolladores conviertan el contenido de archivos PDF en texto, ya sea que necesites procesar el documento completo o solo páginas individuales, usando la biblioteca IronPDF en Python.
Raspado de código completo
Aquí está el código completo que puedes usar:
from ironpdf import *
# Add your License key here
License.LicenseKey = "License-Code"
# Enable debugging for IronPDF
Logger.EnableDebugging = True
# Specify the log file path
Logger.LogFilePath = "Custom.log"
# Set logging mode to log all events
Logger.LoggingMode = Logger.LoggingModes.All
# Load an existing PDF document
pdf = PdfDocument.FromFile("sample.pdf")
# Extract all text from the PDF document
all_text = pdf.ExtractAllText()
# Print the extracted text
print(all_text)from ironpdf import *
# Add your License key here
License.LicenseKey = "License-Code"
# Enable debugging for IronPDF
Logger.EnableDebugging = True
# Specify the log file path
Logger.LogFilePath = "Custom.log"
# Set logging mode to log all events
Logger.LoggingMode = Logger.LoggingModes.All
# Load an existing PDF document
pdf = PdfDocument.FromFile("sample.pdf")
# Extract all text from the PDF document
all_text = pdf.ExtractAllText()
# Print the extracted text
print(all_text)Funciones avanzadas para archivos PDF
Convertir archivos PDF a otros formatos
IronPDF no solo se encarga de la extracción de texto. Una de sus características clave es la capacidad de convertir archivos PDF a otros formatos, lo cual puede ser particularmente útil para compartir y presentar información en diferentes medios.
Imprimir y gestionar documentos PDF
Gestionar un trabajo de impresión de un archivo PDF directamente desde Python es inestimable en cuanto a documentación física. IronPDF proporciona esta capacidad, agilizando el proceso de digital a físico con solo unos pocos comandos.
Manejo de archivos PDF escaneados
Para archivos PDF escaneados, IronPDF ofrece métodos especializados para extraer texto, lo cual puede ser una tarea desafiante debido a la naturaleza del contenido que es una imagen en lugar de texto seleccionable. Esto extiende la utilidad de la biblioteca a tareas más amplias de gestión de documentos.
La evolución de las tecnologías de procesamiento de PDF
Las tecnologías de procesamiento de PDF han evolucionado rápidamente, desde la simple extracción de texto hasta el manejo de datos complejos y la manipulación de documentos más interactivos. El enfoque se está desplazando hacia la automatización, la inteligencia artificial y los servicios basados en la nube, permitiendo soluciones de procesamiento de documentos más dinámicas e inteligentes.
Es probable que IronPDF evolucione en paralelo, incorporando estas tecnologías de vanguardia para mantenerse relevante y robusto.
Conclusión: Agilice su flujo de trabajo con IronPDF
IronPDF simplifica la conversión de PDF a texto y optimiza los flujos de trabajo, convirtiéndolo en un activo valioso para desarrolladores y empresas.
IronPDF se destaca por su capacidad de integrarse sin problemas en entornos Python, su robusta extracción de texto tanto de PDFs estándar como escaneados, y su alta fidelidad para mantener el formato original del documento.
Las capacidades de registro y depuración de la biblioteca también ayudan en el desarrollo de aplicaciones confiables para la manipulación de PDF.
Después de convertir un PDF a texto, los pasos siguientes implican aprovechar los datos extraídos. Esto podría significar integrar el texto en bases de datos, realizar análisis de datos, alimentarlo en herramientas de informes o usarlo para el aprendizaje automático.
Con los datos textuales en un formato más accesible, las posibilidades para procesar y usar esta información se expanden significativamente, abriendo puertas a nuevas ideas y eficiencias operativas.
IronPDF ofrece una prueba gratuita de 30 días, permitiéndote explorar y evaluar todas sus funcionalidades antes de comprometerte. Este período de prueba es una excelente oportunidad para que los desarrolladores experimenten de primera mano cómo IronPDF puede optimizar sus flujos de trabajo con PDF.
Preguntas Frecuentes
¿Cómo puedo extraer texto de un PDF en Python?
Puedes usar IronPDF para extraer texto de un PDF en Python. Carga el documento PDF usando PdfDocument.FromFile('filename.pdf') y extrae el texto usando pdf.ExtractAllText().
¿Cuáles son las ventajas de usar IronPDF para el procesamiento de PDF en Python?
IronPDF ofrece herramientas robustas para la extracción de texto, manipulación de documentos y conversión, integrándose perfectamente en entornos Python. Sus características avanzadas incluyen el manejo de PDFs escaneados y la conversión de PDFs a otros formatos.
¿Cómo instalo IronPDF en Python?
Para instalar IronPDF, asegúrate de tener Python 3.x y pip instalados. Ejecuta el comando pip install ironpdf en tu línea de comandos o terminal.
¿Puede IronPDF manejar archivos PDF escaneados?
Sí, IronPDF tiene métodos especializados para extraer texto de archivos PDF escaneados, lo que te permite trabajar con documentos donde el contenido está en forma de imagen.
¿Cuáles son los requisitos del sistema para usar IronPDF en Python?
Para usar IronPDF, necesitas Python 3.x, pip (instalador de paquetes de Python) y, si estás en un sistema Windows, el marco .NET.
¿Cómo puedo convertir un PDF a otros formatos usando IronPDF?
IronPDF te permite convertir PDFs a varios formatos utilizando sus métodos de conversión, mejorando la flexibilidad de la gestión de documentos en aplicaciones Python.
¿Hay una prueba gratuita disponible para IronPDF?
Sí, IronPDF ofrece una prueba gratuita de 30 días, lo que permite a los desarrolladores explorar y evaluar sus funcionalidades antes de realizar una compra.
¿Por qué es importante el registro al usar IronPDF?
El registro en IronPDF es crucial ya que ayuda a rastrear operaciones, solucionar problemas y registrar todos los eventos incluidos los registros de nivel de información, advertencias y errores, ayudando en la depuración.
¿Cómo mejora IronPDF la automatización del flujo de trabajo en Python?
IronPDF mejora la automatización del flujo de trabajo simplificando la conversión de PDF a texto y permitiendo una integración sin problemas en proyectos Python, mejorando así la productividad y la eficiencia operativa.
















