
Cómo Extraer Texto De Un PDF en Python
Este artículo demostrará cómo extraer todo el texto de archivos PDF usando IronPDF en Python, proporcionándole el conocimiento y fragmentos de código de Python para realizar esta tarea de manera eficiente.
Cómo Extraer Texto De Un PDF en Python
- Descargue un módulo Python para extraer texto de PDF
- Utilice el método
FromFilepara importar el archivo PDF - Extraer texto del PDF importado con el método
ExtractText - Extraer texto de páginas específicas con el método
ExtractTextFromPage - Genera el texto extraído en la consola o un archivo de texto
IronPDF - Biblioteca Python
IronPDF for Python es una poderosa biblioteca de PDF for Python que permite a los desarrolladores extraer texto de documentos PDF. Con IronPDF, puede automatizar la parte de extracción de datos del contenido textual de archivos PDF, facilitando el procesamiento y análisis de la información contenida en los documentos PDF.
IronPDF proporciona a los programadores de Python la capacidad de manipular, extraer datos e interactuar con archivos PDF utilizando Python, facilitando la automatización de diversas tareas relacionadas con PDF. Ya sea que necesite generar PDFs, modificar PDFs existentes, extraer datos del contenido o realizar otras operaciones con PDF, IronPDF simplifica el proceso con su API intuitiva y potentes capacidades.
Características clave
Algunas características de la biblioteca IronPDF for Python incluyen:
- Crear un nuevo archivo PDF desde cero
- Editar archivos PDF existentes
- Extraer texto, metadatos e imágenes de archivos PDF
- Convertir archivos PDF a otros formatos
- Proteger archivos PDF con contraseñas y restricciones
- Dividir y fusionar PDFs
Requisitos previos
Antes de proceder con la extracción de texto usando IronPDF, asegúrese de tener los siguientes requisitos previos:
- Instalación de Python: asegúrese de tener Python instalado en su sistema. IronPDF es compatible con versiones de Python 3.x, así que asegúrese de tener una instalación de Python compatible.
Biblioteca IronPDF: Instale la biblioteca IronPDF utilizando
pip, el gestor de paquetes de Python. Abra su interfaz de línea de comandos y ejecute el siguiente comando:pip install ironpdfpip install ironpdfSHELLNota: Python debe estar añadido a la variable de entorno PATH para usar los comandos pip.
- Entorno de desarrollo integrado (IDE): si bien no es estrictamente necesario, el uso de un IDE puede mejorar enormemente su experiencia de desarrollo. Proporciona características como autocompletar código, depuración y un flujo de trabajo más eficiente. Un IDE popular para el desarrollo en Python es PyCharm. Puede descargar e instalar PyCharm desde el sitio web de JetBrains https://www.jetbrains.com/pycharm/.
- Editor de texto: como alternativa, si prefiere trabajar con un editor de texto liviano, puede usar cualquier editor de texto de su elección, como Visual Studio Code, Sublime Text o Atom. Estos editores proporcionan resaltado de sintaxis y otras características útiles para el desarrollo en Python. También puede usar la aplicación IDLE de Python.
Creación de un proyecto de Python con PyCharm
Después de instalar el IDE PyCharm, cree un proyecto Python en PyCharm siguiendo los pasos a continuación:
- Lanzar PyCharm: Abra PyCharm desde el lanzador de aplicaciones de su sistema o el acceso directo del escritorio.
Crear un Nuevo Proyecto: Haga clic en "Crear Nuevo Proyecto" o abra un proyecto Python existente.
 PyCharm IDE
PyCharm IDEConfigurar Configuración del Proyecto: Proporcione un nombre para su proyecto y elija la ubicación para crear el directorio del proyecto. Seleccione el intérprete de Python para su proyecto. Luego haga clic en "Crear".
 Crear un nuevo proyecto Python en PyCharm
Crear un nuevo proyecto Python en PyCharm- Crear Archivos Fuente: PyCharm creará la estructura del proyecto, incluyendo un archivo Python principal y un directorio para archivos fuente adicionales. Comience a escribir el código y haga clic en el botón de ejecución o presione Shift+F10 para ejecutar el script.
Extracción de texto de PDF en Python con IronPDF
Ahora vamos a adentrarnos en los pasos involucrados en extraer texto plano de archivos PDF usando IronPDF en el lenguaje de programación Python.
Importe las bibliotecas necesarias
Para comenzar, importe las bibliotecas necesarias en su script de Python. En este caso, la muestra de código necesita importar la biblioteca IronPDF, que proporciona la funcionalidad para trabajar con archivos PDF.
import ironpdfimport ironpdfConfigurar la clave de licencia
Para extraer todo el texto de un archivo PDF usando IronPDF, necesita tener IronPDF licenciado. Aplique la licencia o clave de prueba utilizando el siguiente comando:
# Apply your license key
License.LicenseKey = "YOUR-LICENSE-KEY-HERE"# Apply your license key
License.LicenseKey = "YOUR-LICENSE-KEY-HERE"Nota: Sin una clave de licencia, la extracción de datos con IronPDF se restringe solo a unos pocos caracteres del archivo PDF. Obtenga una clave de licencia comprando IronPDF o inscribiéndose en una prueba gratuita.
Cargar el documento PDF
A continuación, carga el archivo PDF utilizando el método PdfDocument.FromFile() de IronPDF. Proporcione la ruta al archivo PDF como argumento para este método. Esto cargará el archivo PDF en un objeto PdfDocument.
pdf = ironpdf.PdfDocument.FromFile("path/to/your/pdf_file.pdf")pdf = ironpdf.PdfDocument.FromFile("path/to/your/pdf_file.pdf")Archivo de entrada
Para extraer texto del archivo PDF de entrada e imprimirlo en la pantalla, se utiliza el siguiente documento:
 El archivo de entrada
El archivo de entrada
Extraer texto de archivos PDF
Una vez cargado el documento PDF, puede extraer el contenido de texto utilizando el método ExtractText. Este método devuelve el texto extraído como una cadena.
text = pdf.ExtractText()text = pdf.ExtractText()Procesar y utilizar el texto extraído
Ahora que ha extraído el texto del PDF, puede procesarlo y utilizarlo según sus requerimientos. Puede realizar tareas como analizar el texto, almacenarlo en una base de datos o usarlo para un procesamiento de datos adicional.
# Process and utilize the extracted text
print(text)
# Perform other operations with the extracted text# Process and utilize the extracted text
print(text)
# Perform other operations with the extracted textResultado
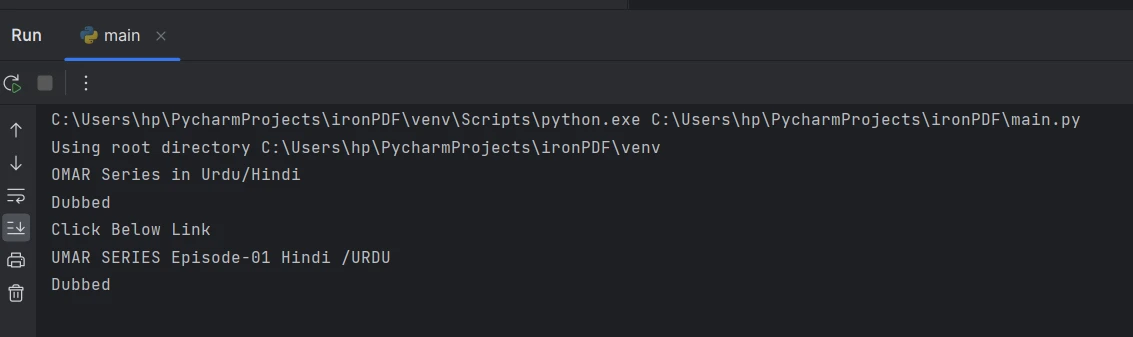 El texto extraído de la consola
El texto extraído de la consola
Extraer texto de una página específica de un archivo PDF
IronPDF también ofrece un método práctico para extraer texto de páginas específicas dentro de un archivo PDF. En esta sección se explorará cómo extraer texto de una página específica utilizando el método ExtractTextFromPage proporcionado por IronPDF.
El siguiente código demuestra cómo extraer texto de una página específica:
# Extract text from a specific page in the document
page_2_text = pdf.ExtractTextFromPage(1)# Extract text from a specific page in the document
page_2_text = pdf.ExtractTextFromPage(1)En el código de ejemplo anterior, pdf representa el objeto PdfDocument obtenido tras cargar el documento PDF. El método ExtractTextFromPage() se utiliza para extraer texto de una página específica, indicada por el índice de página pasado como argumento. En este caso, el texto se extrae de la segunda página o página número 2, que corresponde al índice de página 1.
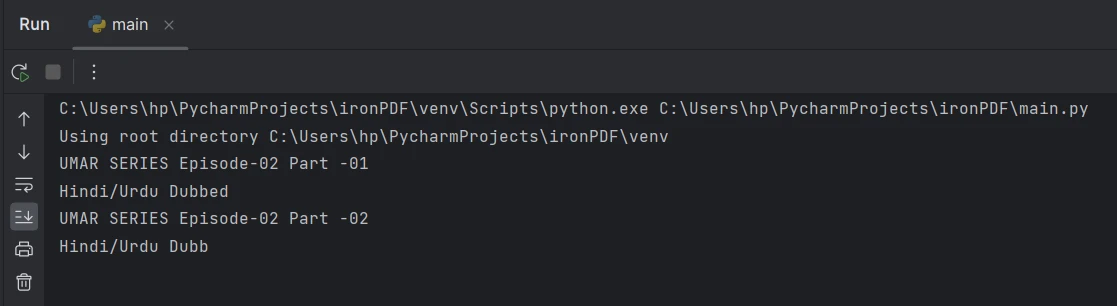 Extraer texto de la página 2
Extraer texto de la página 2
Conclusión
Este artículo exploró cómo extraer texto de archivos PDF usando IronPDF en Python. Cubrió los pasos necesarios, incluyendo la importación de la biblioteca requerida, carga del documento PDF, extracción del contenido de texto y procesamiento del texto extraído.
Con las potentes capacidades de extracción de texto de IronPDF, puede automatizar la extracción y el procesamiento adicional del texto de los PDFs, permitiéndole procesar y analizar fácilmente la información textual dentro de los documentos PDF. Su API intuitiva y sus extensas capacidades lo hacen una opción ideal para una amplia gama de tareas relacionadas con PDF en el desarrollo de Python.
IronPDF es gratuito para propósitos de desarrollo, pero necesita ser licenciado para uso comercial. Para usarlo en modo de producción para prueba, obtenga una prueba gratuita. Descargue e instale la última versión de IronPDF for Python y pruébelo.
Preguntas Frecuentes
¿Cómo puedo extraer texto de un documento PDF completo utilizando Python?
Se puede extraer texto de un documento PDF completo utilizando el método de IronPDF PdfDocument.FromFile() para cargar el PDF y, a continuación, llamando al ExtractText() método para recuperar el contenido de texto.
¿Cuál es el proceso para extraer texto de páginas específicas de un PDF en Python?
Para extraer texto de páginas específicas de un PDF, utilice el método ExtractTextFromPage() , que le permite especificar el índice de página para recuperar el texto de esa página en concreto.
¿Cómo instalo la biblioteca IronPDF for Python?
Instala la biblioteca IronPDF for Python utilizando el gestor de paquetes pip ejecutando el comando: pip install ironpdf.
¿Cuáles son los requisitos previos para extraer texto de archivos PDF en Python?
Los requisitos previos incluyen tener Python instalado en el sistema, instalar IronPDF a través de pip y utilizar un IDE como PyCharm para el desarrollo.
¿Existe una versión gratuita de la biblioteca IronPDF disponible for Python?
IronPDF es gratuito para fines de desarrollo, pero se necesita una licencia para uso comercial. Hay disponible una versión de prueba gratuita para probar la biblioteca en modo de producción.
¿Necesito una licencia para extraer el texto completo de archivos PDF utilizando IronPDF?
Sí, se requiere una clave de licencia para extraer texto de archivos PDF de forma completa utilizando IronPDF. Sin una licencia, la extracción se limita a unos pocos caracteres.
¿Cuáles son algunas de las características clave de IronPDF for Python?
Las características principales de IronPDF for Python incluyen la creación y edición de archivos PDF, la extracción de texto, metadatos e imágenes, la conversión de archivos PDF a otros formatos y la incorporación de funciones de seguridad, como contraseñas.
¿Puede IronPDF for Python ayudar a automatizar la extracción de datos de PDF?
Sí, IronPDF ofrece métodos como FromFile y ExtractText que facilitan la automatización de la extracción de datos de PDF, lo que ayuda en el análisis y la manipulación de datos.
¿Qué IDE se recomienda para utilizar IronPDF en Python?
Se recomienda PyCharm para el desarrollo en Python con IronPDF debido a sus características, como la finalización de código, las herramientas de depuración y un flujo de trabajo optimizado.
¿Cómo mejora IronPDF mi flujo de trabajo en el procesamiento de documentos PDF?
IronPDF mejora el flujo de trabajo al proporcionar una API intuitiva para la extracción de texto, la creación y edición de PDF, la conversión de formatos y la configuración de seguridad, lo que agiliza diversas tareas relacionadas con los PDF.
















