
データサイエンスのため for PythonのPandasガイド
Pandasは、Pythonプログラミング言語で人気のデータ分析ツールで、使いやすさとタブデータの処理における多用途性で知られています。 このガイドは、実用的な例と効率的なデータ操作と分析の手法に焦点を当て、Pandasの基本を紹介します。
DataFrameの理解: Pandasの核心
1. Pandasでのデータアクセス
Pandasの主な構造は、データ解析と操作の強力なツールであるDataFrameです。 最初に、DataFrame内でのデータアクセス方法を探ります。
1.1 CSVファイルからデータを読み込む
たとえば、データを含むCSVファイルがある場合、それをDataFrameに読み込み操作を開始できます。 以下のコードはCSVファイルからデータを読み込む方法を示しています。
import pandas as pd
# Load data from a CSV file into a DataFrame
df = pd.read_csv('your_file.csv')import pandas as pd
# Load data from a CSV file into a DataFrame
df = pd.read_csv('your_file.csv')1.2 列データのアクセス
ロードした後、DataFrame内のデータにアクセスする方法はいくつかあります。 列の名前を使用して列データにアクセスできます。 例えば、以下のコードは'data'という名前の列からデータを取得します。
# Access data from a column named 'data'
column_data = df['data']# Access data from a column named 'data'
column_data = df['data']1.3 行データのアクセス
同様に、行インデックスや条件を使用して行データにアクセスすることも可能です。
# Accesses the first row of the DataFrame
row_data = df.loc[0]# Accesses the first row of the DataFrame
row_data = df.loc[0]2. DataFramesでのヌル値の処理
データ分析における一般的な問題は、Null値の取り扱いです。 Pandasは、これを処理するための強力なメソッドを提供します。 コードはNull値を指定された値で埋めるか、またはNullを含む行や列を削除することができます。 こちらはNull値を埋める方法のコード例です。
# Fill null values in the DataFrame with 0
df.fillna(0, inplace=True)# Fill null values in the DataFrame with 0
df.fillna(0, inplace=True)3. 列の作成と操作
DataFrameは新しい列の作成を可能にする多用途性を持っています。 新しい整数列であろうと既存データから導出された列であろうと、そのプロセスは簡単です。 こちらはDataFrameに新しい列を追加する例です。
# Add a new column 'new_column' by multiplying an existing column by 10
df['new_column'] = df['existing_column'] * 10# Add a new column 'new_column' by multiplying an existing column by 10
df['new_column'] = df['existing_column'] * 10条件に基づいてデータをフィルターすることもできます。 例えば、'column_named_data'という名前の列から特定の値以上のデータを持つ新しい列を作成したい場合など。
# Create a new column 'filtered_data' based on the condition
df['filtered_data'] = df[df['column_named_data'] > value]# Create a new column 'filtered_data' based on the condition
df['filtered_data'] = df[df['column_named_data'] > value]高度なデータ操作手法
1. データのグループ化と集計
Pandasはデータのグループ化と集計が得意です。 以下のコードはgroupbyメソッドを使用し、指定した列でデータをグループ化して平均や合計などの集計関数を計算します。
# Group data by 'column_name' and calculate the mean
grouped_data = df.groupby('column_name').mean()# Group data by 'column_name' and calculate the mean
grouped_data = df.groupby('column_name').mean()2. 日付と時間データ
日付と時間の処理は多くのデータセットで重要です。 DataFrameに日付列がある場合、Pandasは日付でのフィルタリングや月単位または年単位での集計などのタスクを簡単にします。こちらは基本的な例です。
# Convert 'date_column' to datetime format
df['date_column'] = pd.to_datetime(df['date_column'])# Convert 'date_column' to datetime format
df['date_column'] = pd.to_datetime(df['date_column'])3. カスタムデータ操作
より複雑なデータ操作ニーズに対して、Pandasはカスタム関数を書いてDataFrameに適用することを可能にします。 特に、言語統合クエリアプローチを要求するシナリオに有用です。
def custom_function(row):
# Perform custom manipulation on each row
return modified_row
# Apply custom function to each row in the DataFrame
df = df.apply(custom_function, axis=1)def custom_function(row):
# Perform custom manipulation on each row
return modified_row
# Apply custom function to each row in the DataFrame
df = df.apply(custom_function, axis=1)データの視覚化と表示
Pandasはデータ視覚化のためのMatplotlibやSeabornのようなライブラリとよく統合されます。 視覚フォーマットでデータを表示するのは以下のソースコードで示されるように簡単です。
import matplotlib.pyplot as plt
# Plot a bar chart for data visualization
df.plot(kind='bar')
plt.show()import matplotlib.pyplot as plt
# Plot a bar chart for data visualization
df.plot(kind='bar')
plt.show()PandasとのIronPDF統合によるPythonでのデータ分析の強化
前述の通り、PandasはPythonでのデータ操作と分析の強力なツールです。 その機能を補完するIron Softwareが開発したライブラリ、IronPDFは、特にPDFコンテンツを扱うときにデータ分析ワークフローを改善する追加機能を提供します。
IronPDFの概要
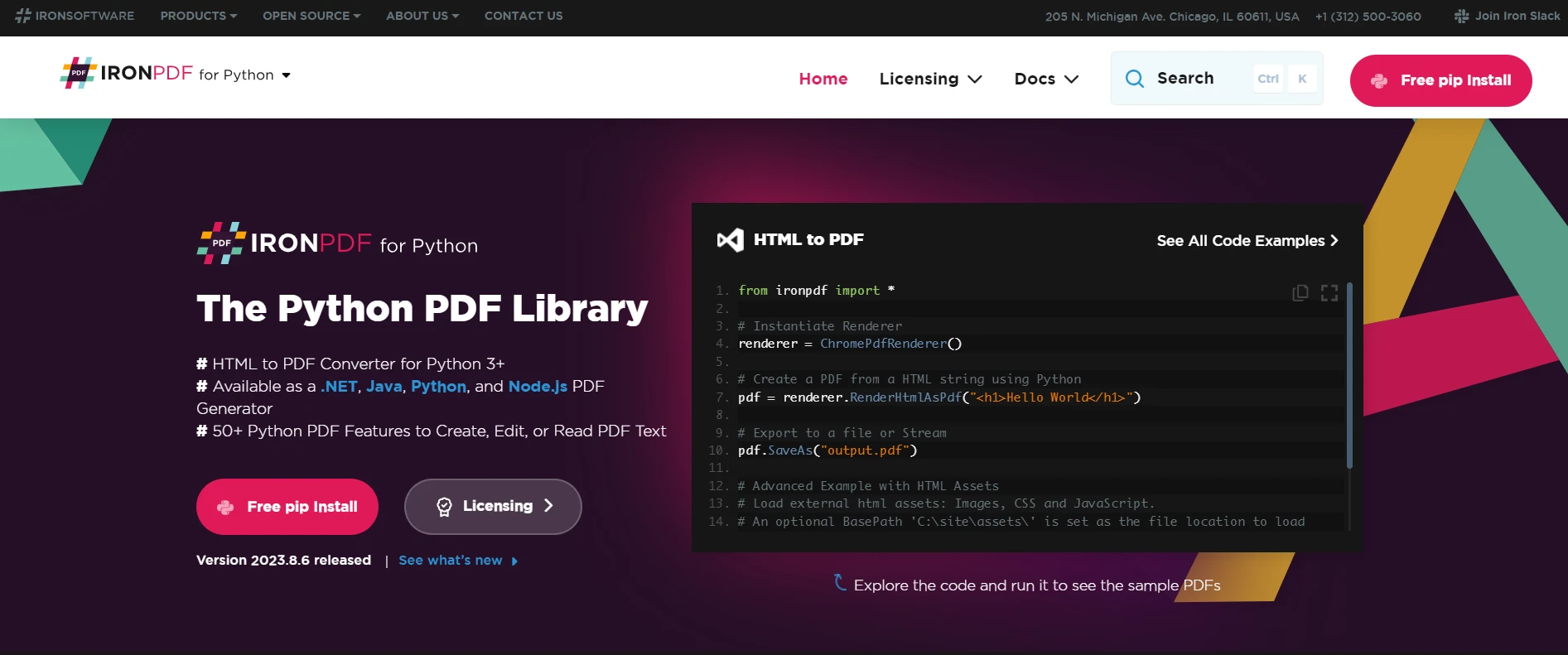
IronPDFは、Pythonプロジェクト内でPDFコンテンツの作成、編集、抽出を行うための多用途なPython PDFライブラリです。 Windows、Mac、Linux、クラウド環境など、さまざまなプラットフォーム上で動作するように設計されており、多様なPythonプロジェクトに適した選択肢となっています。 このライブラリは、PDFファイルの処理に強力で、PDFデータを扱う開発者にとって重要なシームレスな経験と効率的な処理を提供します。
Pandasとのシナジー
IronPDFをPandasと統合することで、より高度なデータ処理とレポートの可能性が広がります。 Pandasを使ってデータの操作と分析を行い、その結果とビジュアル化をIronPDFを用いてプロフェッショナルにフォーマットされたPDFレポートにシームレスに変換する分析ワークフローを想像してみてください。 この統合は、データ分析結果の共有と提示のプロセスを大幅に効率化することができます。
結論
結論として、Pandasがデータ分析の基盤を提供する一方で、IronPDFの統合により、Pythonでのデータ分析ワークフローに新たな次元が追加されます。 この組み合わせは、データ操作と分析プロセスの効率を高めるだけでなく、データの提示と共有の方法も大幅に改善し、Pythonベースのデータアナリストと科学者にとって非常に価値のある資産になります。
IronPDFは購入前にその機能を探ることに関心のあるユーザーに提供されます。
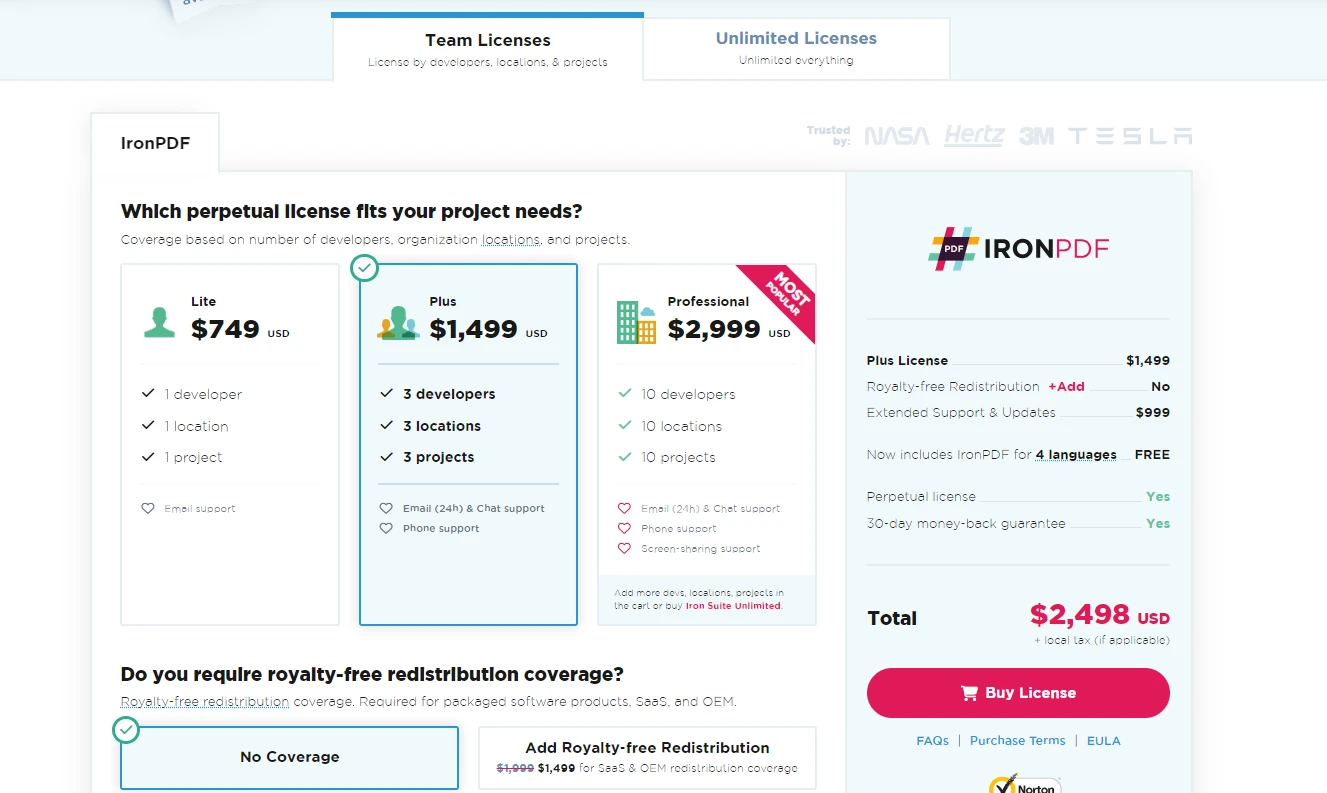
フルライセンスの取得を検討している方には、IronPDF で、プロジェクトのニーズと予算に最も適したプランを選択することができます。
















