
Pythonを使用してPDFページを追加または削除する方法
この記事では、PythonとIronPDF for PythonというPDFライブラリを使用して、PDFページを追加または削除する方法を示します。
1. IronPDF for Python
IronPDF は、市場をリードするPDF Pythonライブラリで、開発者がアプリケーション内でPDFドキュメントを簡単に生成、操作、および作業する能力を提供します。 IronPDFを使用すると、開発者はPDF機能をPythonプロジェクトにシームレスに統合できます。たとえば、動的なレポートの作成、請求書の生成、WebコンテンツをPDFファイルに変換するなど。 このライブラリは、PDF関連のタスクを効率的かつ使いやすく扱う方法を提供しており、PDFを簡単に作成および操作できます。
Webアプリ、デスクトップソフト、ドキュメントワークフローの自動化時に、IronPDFは必須のツールです。 この入門ガイドでは、IronPDF for Pythonの主な機能と能力を探ります。 IronPDFを使用することで、開発者は複数のPDFファイルを一つのドキュメントにマージする、特定のページからテキストを抽出する、ウォーターマークを追加する、ページの削除、空白ページの削除、ページの回転、ページの追加、PDFファイルの読み取りなどの操作を行うことができます。
2. IronPDFのインストール
IronPDFをインストールするには、PyCharmやその他 for Pythonコンパイラを開き、新しいPythonプロジェクトを作成するか、既存のプロジェクトを開きます。 プロジェクトを作成または開いたら、ターミナルを開きます。
IronPDF for Pythonは、ターミナルコマンドを使用して簡単にインストールできます。 ターミナルで次のコマンドを実行するだけで、IronPDFが1分以内にインストールされます。
pip install ironpdf
 IronPDFパッケージをインストールする
IronPDFパッケージをインストールする
インストールが完了したら、コードを使って遊ぶ準備が整ったことになります。
3. コード例
PDFドキュメントからPDFページを追加または削除する前に、HTMLを使用して4ページのシンプルなPDFファイルを作成しましょう。 以下のコードは、今後のコード例で使用する入力PDFドキュメントとしてPDFファイルを作成します。
from ironpdf import *
# HTML content to be converted to PDF
html = """
<p> Hello Iron</p>
<p> This is 1st Page </p>
<div style='page-break-after: always;'></div>
<p> This is 2nd Page</p>
<div style='page-break-after: always;'></div>
<p> This is 3rd Page</p>
<div style='page-break-after: always;'></div>
<p> This is 4th Page</p>
"""
# Initialize the renderer
renderer = ChromePdfRenderer()
# Render the HTML as a PDF document
pdf = renderer.RenderHtmlAsPdf(html)
# Save the PDF to a file
pdf.SaveAs("Page1And4.pdf")from ironpdf import *
# HTML content to be converted to PDF
html = """
<p> Hello Iron</p>
<p> This is 1st Page </p>
<div style='page-break-after: always;'></div>
<p> This is 2nd Page</p>
<div style='page-break-after: always;'></div>
<p> This is 3rd Page</p>
<div style='page-break-after: always;'></div>
<p> This is 4th Page</p>
"""
# Initialize the renderer
renderer = ChromePdfRenderer()
# Render the HTML as a PDF document
pdf = renderer.RenderHtmlAsPdf(html)
# Save the PDF to a file
pdf.SaveAs("Page1And4.pdf")こ for Pythonコードは、IronPDFライブラリを使用して、HTMLコンテンツからPDFドキュメントを作成します。 HTMLコンテンツは、段落とページブレークを示す"page-break-after" divタグを含む文字列として定義されています。 それは4ページ構成です。 そのコードは、そのHTMLをPDFドキュメントに変換するためにChromePdfRendererを使用します。 最後に、結果のPDFを"Page1And4.pdf"として保存します。
本質的に、このコードは、HTML内の二つの連続する"ページブレーク" divタグ間のコンテンツに対応する複数ページのPDFを生成し、このHTMLコンテンツをPDFファイルに保存します。
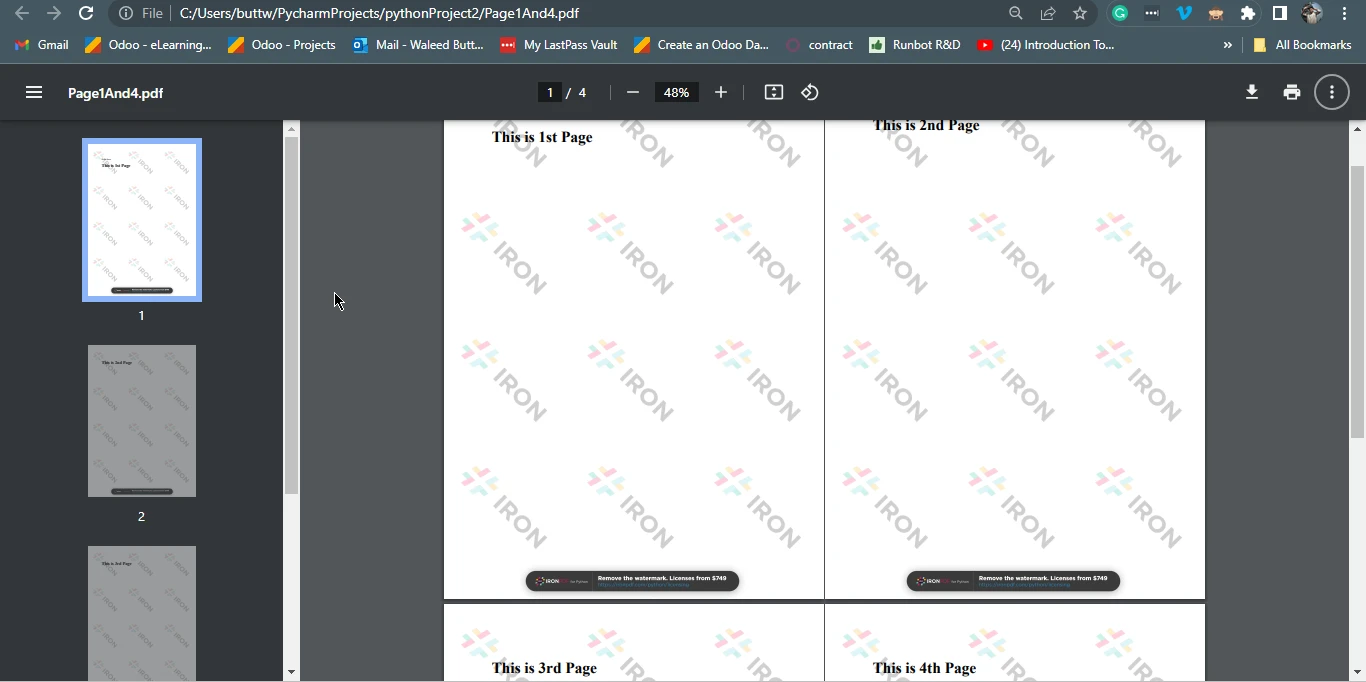 Page1And4.pdf
Page1And4.pdf
3.1. IronPDFを使用してPDFファイルから特定のページを削除
このセクションでは、先に作成したPDFからページを削除します。 以下のコードは、PDFファイルからページを削除します。
from ironpdf import *
# Load the existing PDF document
pdf = PdfDocument.FromFile("Page1And4.pdf")
# Remove the page at index 1 (second page)
pdf.RemovePage(1)
# Save the modified PDF to a new file
pdf.SaveAs("removed.pdf")from ironpdf import *
# Load the existing PDF document
pdf = PdfDocument.FromFile("Page1And4.pdf")
# Remove the page at index 1 (second page)
pdf.RemovePage(1)
# Save the modified PDF to a new file
pdf.SaveAs("removed.pdf")上記のコードは、PDFドキュメントを操作するためにIronPDFライブラリを利用します。 必要なコンポーネントをインポートしてから、FromFile()メソッドを使用して"Page1And4.pdf"という既存のPDFドキュメントを読み込みます。 PDFからインデックス"1"で識別されるページを削除し、その後SaveAsメソッドを呼び出します。 本質的に、このコードは元のPDFドキュメントから2ページ目を削除し、その結果のドキュメントを別ファイルとして保存するタスクを実行します。
3.1.1. 出力PDFファイル
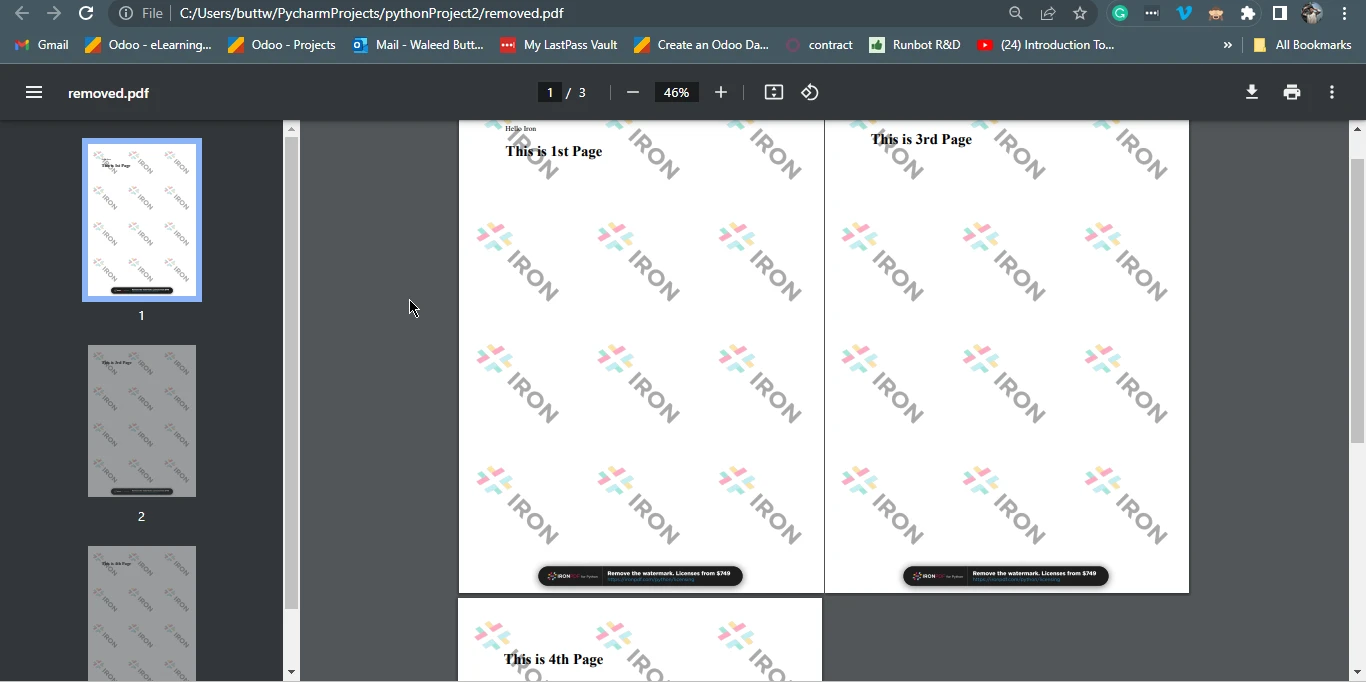 出力ファイル
出力ファイル
3.2. IronPDFを使用してPDFドキュメントにページを追加
このセクションでは、既存のPDFファイルに新しいページを追加する方法について説明します。 これには、新しいPDFファイルを作成し、ページ番号を使用してわずか数行のコードで以前に作成したPDFファイルに新しく作成したPDFを追加します。
以下は、元のドキュメントに新しいPDFページを追加するサンプルコードです。
from ironpdf import *
# HTML content to represent a new page
pdf_page = """
<h1> Cover Page</h1>
"""
# Initialize the renderer and render the new PDF page
renderer = ChromePdfRenderer()
pdfdoc_a = renderer.RenderHtmlAsPdf(pdf_page)
# Load the existing PDF file
pdf = PdfDocument.FromFile("removed.pdf")
# Prepend the new page to the beginning of the existing PDF
pdf.PrependPdf(pdfdoc_a)
# Save the combined PDF to a new file
pdf.SaveAs("addPage.pdf")from ironpdf import *
# HTML content to represent a new page
pdf_page = """
<h1> Cover Page</h1>
"""
# Initialize the renderer and render the new PDF page
renderer = ChromePdfRenderer()
pdfdoc_a = renderer.RenderHtmlAsPdf(pdf_page)
# Load the existing PDF file
pdf = PdfDocument.FromFile("removed.pdf")
# Prepend the new page to the beginning of the existing PDF
pdf.PrependPdf(pdfdoc_a)
# Save the combined PDF to a new file
pdf.SaveAs("addPage.pdf")こ for Pythonコードスニペットは、PDFドキュメントを操作するためにIronPDFライブラリを利用しています。 最初に、タイトルを持つ表紙ページを表すHTMLコンテンツスニペットを定義します。 次に、このHTMLをPDFドキュメントに変換し、それをChromePdfRenderer()メソッドを使用します。
次に、PdfDocument.FromFile("removed.pdf")を使用して既存のPDFドキュメント"removed.pdf"を読み込みます。 コードは、pdfdoc_aのコンテンツをこの既存のPDFに前置します。 本質的に、このコードは表紙PDFを"removed.pdf"と組み合わせ、元のPDFの先頭に表紙を追加する新しいPDFドキュメント"addPage.pdf"を作成します。
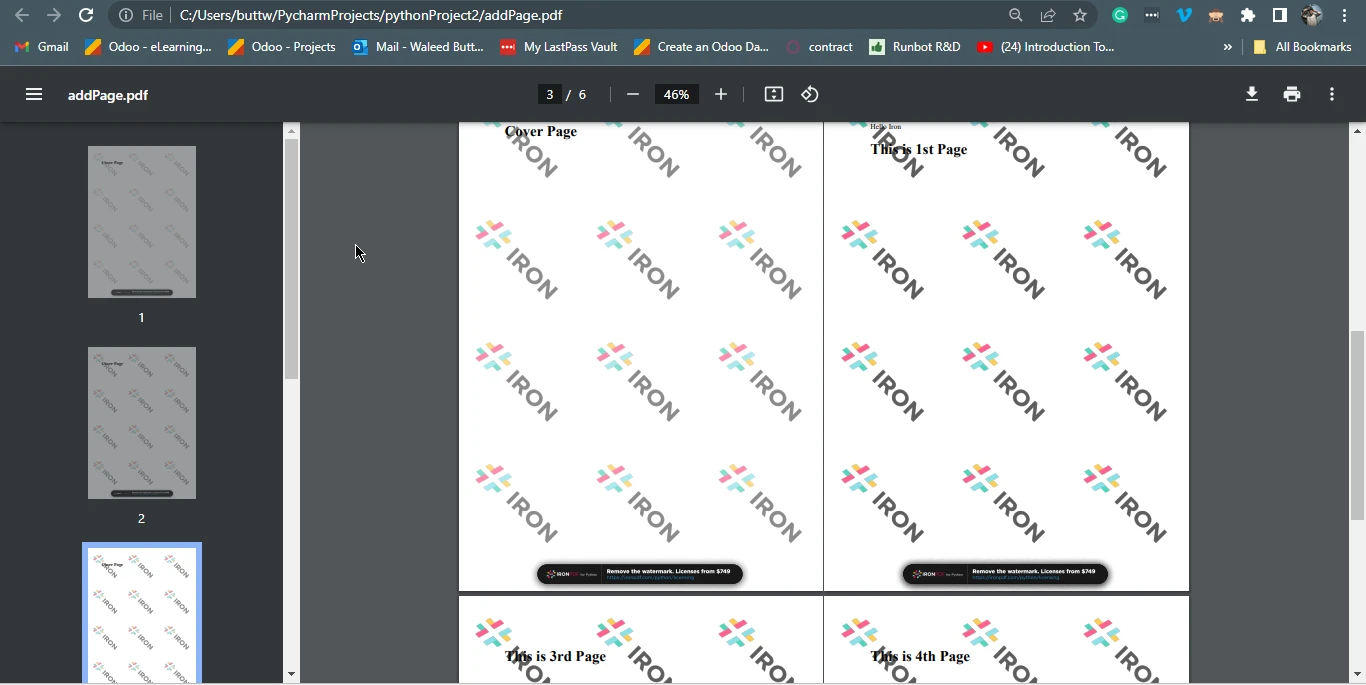 出力ファイル
出力ファイル
4. 結論
この記事では、Pythonを使用してPDF操作の世界を探求し、IronPDFライブラリに焦点を当てました。 PDFドキュメントからページを追加または削除する能力は、今日のデジタル環境において貴重なスキルであり、Pythonはこれらのタスクを達成するためのアクセス可能で強力な方法を提供します。 この記事では、IronPDFのインストールに必要な手順を解説し、PDF内のページの作成、削除、追加のプロセスを説明するためのコード例を提供しました。
IronPDFを使用すると、Python開発者はレポートの生成、コンテンツのカスタマイズ、ドキュメントワークフローの改善などについて、効率的にPDFドキュメントを操作できます。 デジタルの世界がさまざまな目的でPDFに依存し続ける中、これらの技術をマスターすることで、開発者は幅広いニーズに対応できるようになり、PythonとIronPDFはPDF操作におけるダイナミックな組み合わせになります。
PDFページを削除するコード例は、次のサンプルコードで見つけることができます。 PDFページを追加するコード例は、もう一つのPythonコード例で見つけることができます。 また、HTMLからPDFへの変換がどのように機能するかに興味がある場合は、このチュートリアルページをご覧ください。
IronPDF for Pythonライブラリの多様な機能を探求し、無料トライアルを選んで体験してみてください。
よくある質問
PythonでPDFに新しいカバーページを追加するにはどうしたらいいですか?
PythonでPDFドキュメントに新しいカバーページを追加するには、IronPDFのChromePdfRendererを使用してHTMLコンテンツから新しいページを作成します。その後、PrependPdfメソッドを使用してこの新しいページを既存のPDFドキュメントの前に追加します。
IronPDFを使用してPDFからページを削除するにはどのような手順が含まれていますか?
IronPDFを使用してPDFからページを削除するには、最初にPdfDocument.FromFileを使用してPDFを読み込みます。削除したいページをそのインデックスで特定し、RemovePageメソッドを使用して削除します。
PythonのPDFライブラリを使用して複数のPDFファイルをマージできますか?
はい、IronPDF for Pythonを使用すると、MergePdfのようなメソッドを使用して、複数のPDFファイルをシームレスに一つのドキュメントにマージできます。
IronPDFはPythonでPDFを編集するためにどのような機能を提供していますか?
IronPDFは、ページの追加と削除、ドキュメントのマージ、テキストの抽出、透かしの追加、ページの回転など、多くのPDF編集機能を提供し、PDF操作の包括的なツールとなります。
IronPDFを使用してHTMLコンテンツをPDFドキュメントに変換する方法は?
IronPDFを使用してHTMLコンテンツをPDFドキュメントに変換するには、RenderHtmlAsPdfメソッドを活用します。これはHTML文字列を処理し、PDFファイルとして出力します。
IronPDFライブラリにはトライアル版がありますか?
はい、IronPDFの無料トライアルがあり、Pythonアプリケーション内でPDFドキュメントを操作する際のライブラリの機能と能力を探ることができます。
IronPDFを使用したPDF操作からどのような種類のアプリケーションが利益を得られますか?
ウェブプラットフォームからデスクトップソフトウェアまで、IronPDFを使用したPDF操作から利益を得ることができます。レポートの生成、ドキュメントワークフローの自動化、PDFコンテンツのカスタマイズなどのタスクをサポートします。
PDFページを追加または削除するPythonコード例はどこで見つけられますか?
IronPDFを使用してPDFページを追加または削除するコード例は、IronPDFウェブサイトの記事で見つけられます。これにはこれらの操作に対する実践的なPythonコードスニペットが含まれています。
デジタルワークフローでPDFページを管理することが重要な理由は何ですか?
PDFページ管理は、ドキュメントレイアウトのカスタマイズ、不要なコンテンツの削除、自動レポート生成に重要です。
















