
PythonでPDFから表を抽出する方法
この記事では、強力な PDF 処理ライブラリである IronPDF を使用して、あらゆる PDF ファイル内の複雑なテーブルからデータを簡単に抽出する方法を説明します。
IronPDF
Python は、他の言語と比較してプログラマーに非常に高い柔軟性を提供し、開発者がグラフィカル ユーザー インターフェイスを簡単かつ効率的に設計できるようにします。 したがって、IronPDF ライブラリを Python に組み込むのは簡単なプロセスです。 完全に機能する GUI を迅速かつ安全に作成するために、PyQt、wxWidgets、Kivy、その他のさまざまなパッケージやライブラリを含む、プリインストールされたさまざまなツールを利用できます。
IronPDF は Python による Web デザインと開発を簡素化します。 これは主に、Django、Flask、Pyramid などの Python Web 開発フレームワークが豊富に利用できることに起因します。 これらのフレームワークを採用している有名な Web サイトやオンライン サービスとしては、Reddit、Mozilla、Spotify などがあります。
- PDFから表を抽出するPythonモジュールをダウンロードする。
- PDFファイルをインポートするには、`FromFile`メソッドを使用します。
- `ExtractAllText`メソッドでテーブルからテキストを抽出します。
- 抽出されたテキストを繰り返し処理して行を分割する
- 抽出したテキストをコンソールまたはテキストファイルに出力する
IronPDFの特長
以下はIronPDFのいくつかの機能です:
- PDF ファイルは、HTML、HTML5、ASP、PHP などのさまざまなソースから作成できます。 さらに、HTML ファイルだけでなく画像ファイルも PDF に変換できます。
- IronPDF を使用すると、インタラクティブな PDF ドキュメントを作成できます。 PDF ファイルの分割と結合、PDF ファイルからのテキストと画像の抽出、 PDF ページの画像へのラスタライズ、PDF から HTML への変換、PDF ファイルの印刷、インタラクティブ フォームへの入力と送信、PDF ファイルの分割と結合などの機能を提供します。
- IronPDF では URL からドキュメントを生成することが可能です。 また、HTML ログイン フォーム、プロキシ、Cookie、HTTP ヘッダー、特殊なネットワーク ログイン資格情報、フォーム変数、およびユーザー エージェントを使用してログインするユーザー エージェントもサポートします。
- IronPDF プログラムを使用すると、PDF ファイルの検査と注釈付けが可能になります。
- IronPDF を使用すると、ドキュメントから画像を抽出できます。
- IronPDF は、ドキュメントにヘッダー、フッター、テキスト、写真、ブックマーク、透かしなどを追加する機能をユーザーに提供します。
- IronPDF を使用すると、新規または既存のドキュメントのページを分割したり結合したりできます。
- Acrobat ビューアがなくても、ドキュメントを PDF オブジェクトに変換できます。
- IronPDF を使用すると、CSS ファイルから PDF ドキュメントを作成できます。
- IronPDF では、メディア タイプ定義を含む CSS ファイルを使用してドキュメントを作成できます。
Python環境の設定
Pythonのセットアップ
コンピュータに Python がインストールされていることを確認してください。 ご使用のオペレーティング システム用の最新バージョンの Python をダウンロードしてセットアップするには、公式 Python Web サイトにアクセスしてください。 Python をインストールしたら、仮想環境を作成してプロジェクトの要件を分離します。 venv モジュールを利用することで、仮想環境を作成および管理し、変換プロジェクトに整理されたワークスペースを提供できます。
PyCharm の新しいプロジェクト
このチュートリアルでは、Python 開発用の IDE である PyCharm をお勧めします。
PyCharm IDE を起動したら、下の図のようにメニューから"新規プロジェクト"を選択します。
 PyCharm IDE
PyCharm IDE
下の図に示すように、"新しいプロジェクト"を選択すると新しいウィンドウが表示され、プロジェクトの場所と Python 環境を定義できるようになります。
 PyCharmで新しいプロジェクトを作成する
PyCharmで新しいプロジェクトを作成する
プロジェクトの場所と環境を選択したら、 "作成"ボタンをクリックしてプロジェクトを開始します。 新しく起動したウィンドウで Python ファイルを開き、コードを入力できます。 このガイドでは Python 3.9 を使用します。
 メイン for Pythonファイル
メイン for Pythonファイル
IronPDFライブラリの要件
IronPDF for Python は、コア テクノロジーとして .NET 6.0 を採用しています。 したがって、IronPDF for Python を使用するには、コンピューターに .NET 6.0 ランタイムがインストールされている必要があります。 Linux および Mac ユーザーは、この Python モジュールを利用する前に .NET をインストールする必要がある場合があります。 必要なランタイム環境を Microsoft からダウンロードします。
IronPDFライブラリのセットアップ
.pdf拡張子のファイルを作成、編集、および開くためにはironpdfパッケージをインストールする必要があります。 PyCharm にパッケージをインストールするには、ターミナル ウィンドウを開いて次のコマンドを入力します。
pip install ironpdf
以下のスクリーンショットはironpdfパッケージのインストールプロセスを示しています。
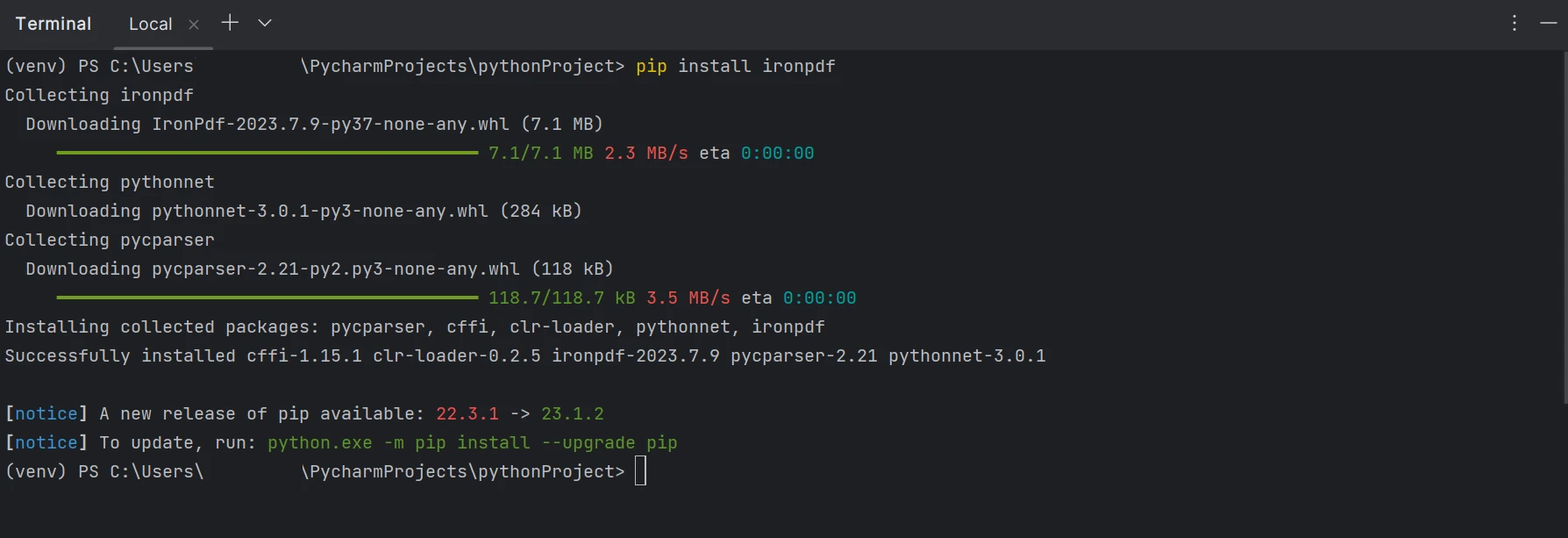 IronPDFパッケージをインストールする
IronPDFパッケージをインストールする
PDFファイルから表データを抽出する
IronPDF for Python ライブラリを使用すると、PDF ファイルから簡単にデータを抽出できます。 IronPDF は、テキスト データの分析と PDF ファイルからの表の抽出を容易にします。 以下は、提供された画像を参照として使用して、PDF テーブルからデータを抽出する方法を示すサンプル コードです。
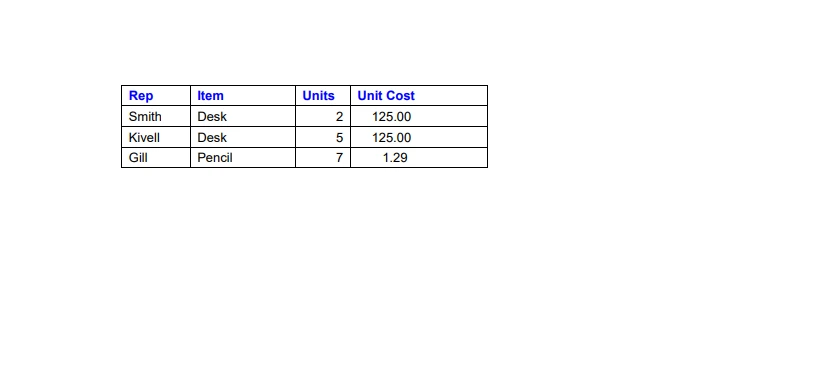 PDFファイルからのサンプルデータ
PDFファイルからのサンプルデータ
from ironpdf import PdfDocument
# Load the PDF document
pdf = PdfDocument.FromFile("sampleData.pdf")
# Extract all text from the PDF document
all_text = pdf.ExtractAllText()
# Split the extracted text into rows and print each row
for row in all_text.split("\n"):
print(row)from ironpdf import PdfDocument
# Load the PDF document
pdf = PdfDocument.FromFile("sampleData.pdf")
# Extract all text from the PDF document
all_text = pdf.ExtractAllText()
# Split the extracted text into rows and print each row
for row in all_text.split("\n"):
print(row)提供されているコードは、わずか数行の Python コードを使用して IronPDF を使用して PDF ファイルから表を抽出する方法を示しています。 最初に、IronPDF ライブラリをインポートしてその機能にアクセスし、IronPDF のすべての機能にアクセスします。 次に、PdfDocumentクラスの助けを借りて、既存のPDFファイルを処理し、様々な操作を行うことができます。
FromFile関数を使用する際は、入力PDFファイルをロードするための引数が利用できます。 その後、ExtractAllText関数がPDFファイル内のすべてのページからテーブルデータを抽出します。 次に、抽出されたテーブルデータを複数の行に分割し、コンソール画面に表示するためにsplit関数を使用します。
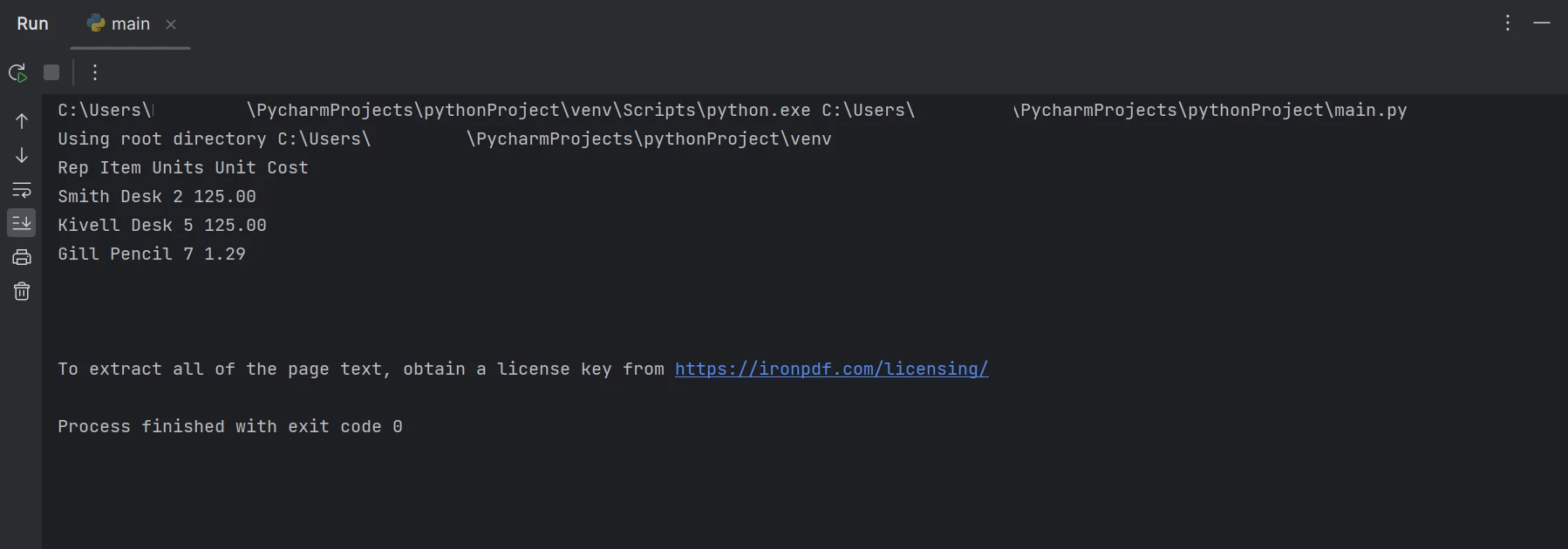 抽出されたデータ
抽出されたデータ
上記の出力では、データが行ごとに表示され、テーブルデータを抽出する方法を示しています。 製品ドキュメントをよく読んで、IronPDF について詳しく学んでください。
結論
IronPDF ライブラリは、潜在的なリスクを最小限に抑え、データのセキュリティを確保するための強力なセキュリティ対策を提供します。 すべての一般的なブラウザと互換性があり、特定のブラウザに限定されません。 IronPDF を使用すると、プログラマーはわずか数行のコードを使用して PDF ファイルを効率的に作成および読み取ることができます。 開発者の多様なニーズに応えるために、IronPDF ライブラリでは、無料の開発者ライセンスや購入可能な追加の開発ライセンスなど、さまざまなライセンス オプションを提供しています。
Liteバンドルは、$799で販売されており、永続ライセンス、30日間の返金保証、1年間のソフトウェアメンテナンス、およびアップグレードの可能性が含まれます。 初回購入後は追加料金は発生せず、これらのライセンスは運用環境、ステージング環境、開発環境で使用できます。 IronPDF は、時間と再配布の制限がある無料ライセンスも提供しています。 ユーザーは、透かしが入らない無料試用期間を利用して、実際の環境で製品をテストできます。 IronPDF の試用版の料金とライセンスに関する詳細については、次のライセンス ページをクリックしてください。
よくある質問
PythonでPDFからテーブルを抽出するにはどうすればいいですか?
PythonでIronPDFを使用してPDFからテーブルを抽出するには、PdfDocument.FromFile()メソッドを使用してPDFを読み込み、ExtractAllText()を使用してテキストを抽出します。その後、テキストを処理して行に分割し、テーブルデータを取得することができます。
IronPDFを使用するため for Python環境を設定する手順は何ですか?
IronPDFを使用するため for Python環境をセットアップするには、Pythonがインストールされていることを確認し、仮想環境を作成し、.NET 6.0ランタイムをインストールします。その後、コマンドpip install ironpdfを使用してIronPDFをインストールできます。
PythonにおけるIronPDFのPDF操作機能にはどのようなものがありますか?
IronPDFは、HTMLや画像などからPDFを作成する機能、テキストや画像の抽出、注釈やヘッド、フッター、透かしを含むインタラクティブなPDFの作成機能を含む、Pythonにおける幅広いPDF操作機能を提供します。
PythonでIronPDFを使用してHTMLをPDFに変換することは可能ですか?
はい、IronPDFを使用するとPythonでHTMLをPDFに変換することができます。IronPDFのメソッドを使用して、HTML文字列やファイルをPDFとしてレンダリングし、ウェブコンテンツからPDFドキュメントを作成することができます。
PythonにおけるIronPDFのライセンスオプションにはどのようなものがありますか?
IronPDFは、テスト用の無料の開発者ライセンス、永続ライセンスを含むLiteバンドル、および購入可能な追加のライセンスパッケージ、さらに30日間の返金保証をサポートしています。
IronPDFを使用してPDFからテーブルを抽出する際の一般的な問題のトラブルシューティング方法を教えてください。
IronPDFの抽出問題をトラブルシューティングするには、必要なインストールがすべて完了している正しいPython環境を確認してください。PDFファイルがアクセス可能であることを確認し、PdfDocument.FromFile()とExtractAllText()メソッドを使用するコードの構文を確認してください。さらに指導が必要な場合は、IronPDFのドキュメントを参照してください。
IronPDFはPDF処理においてどのようなセキュリティ機能を提供しますか?
IronPDFは、処理と配信中にドキュメントを保護するパスワード保護および暗号化などの強力なセキュリティ機能をPDF処理に統合しています。
PythonでIronPDFを使ってPDFから画像を抽出することはできますか?
はい、IronPDFはPythonでPDFから画像を抽出することをサポートしており、PDFドキュメントから画像を分離して保存し、データ処理機能の一部として利用できます。
PythonでのIronPDF開発に推奨されるIDEは何ですか?
IronPDFで for Python開発には、コーディング、デバッグ、およびPythonプロジェクトの効果的な管理のための高度な機能を備えた包括的なIDEであるPyCharmが推奨されます。
















