
PDFtoText in Python:ステップバイステップのチュートリアル
PDF ファイルは、デジタル ドキュメントの最も一般的な形式の 1 つです。 さまざまなシステム間での互換性があり、複雑なドキュメントの書式を保持できるため、好まれています。
データ管理では、PDF ドキュメントを編集可能な形式に変換したり、分析のためにテキストを抽出したりすることが非常に重要です。 この変換プロセスにより、企業や個人は、静的なドキュメント内に閉じ込められていたデータをマイニングして活用できるようになります。
Python は、広範なライブラリ エコシステムを備えており、PDF ファイルを操作するためのアクセスしやすく強力な方法を提供します。 データの抽出、PDF ファイルの変換、レポート生成の自動化など、Python のシンプルさと豊富なツールにより、PDF 処理タスクに最適な言語となっています。
IronPDFとは何ですか?
IronPDFは、Python 開発者が PDF ファイルとのやり取りを容易にするための包括的な PDF レンダリング ライブラリです。 Python プログラミング環境内で PDF ドキュメントの作成、操作、変換を可能にする強力なツール セットを提供します。
IronPDF は、Python スクリプトの容易さと PDF 処理に必要なドキュメント管理機能を結び付け、開発者が PDF 機能をアプリケーションに直接組み込むことを可能にします。
システム要件とインストールガイド
IronPDF をインストールする前に、システムが次の要件を満たしていることを確認してください。
- システムに Python 3.x がインストールされていること。
- 簡単にインストールできるように、pip (Python パッケージ インストーラー) にアクセスできます。
- Windows システムで実行している場合は、IronPDF が機能するために .NET に依存しているため、.NET Frameworkが必要です。
システムがこれらの要件を満たしていることを確認したら、pipを使ってIronPDFをインストールできます。コマンドラインまたはターミナルを開き、以下のコマンドを実行してください。
pip install ironpdf
Python 用 IronPDF ライブラリの最新バージョンを使用していることを確認してください。 このコマンドは、IronPDF ライブラリと必要なすべての依存関係を Python 環境にダウンロードしてインストールします。
PDFをテキストに変換する:ステップバイステップのチュートリアル
ステップ1:IronPDFのインポート
from ironpdf import *from ironpdf import *このコード スニペットは、IronPDF ライブラリから必要なすべてのコンポーネントを Python スクリプトに取り込む import ステートメントで始まります。 これは、PDF ファイルの操作を可能にする IronPDF によって提供されるクラスとメソッドにアクセスするために不可欠です。
ステップ2: ログの設定
# Enable debugging for IronPDF
Logger.EnableDebugging = True
# Specify the log file path
Logger.LogFilePath = "Custom.log"
# Set logging mode to log all events
Logger.LoggingMode = Logger.LoggingModes.All# Enable debugging for IronPDF
Logger.EnableDebugging = True
# Specify the log file path
Logger.LogFilePath = "Custom.log"
# Set logging mode to log all events
Logger.LoggingMode = Logger.LoggingModes.AllLogger.EnableDebugging = True:トラブルシューティングに不可欠な操作を追跡するために、 IronPDFライブラリ内のデバッグ機能を有効にします。
Logger.LogFilePath = "Custom.log":デバッグ情報が書き込まれるログ ファイルのパスと名前を指定します。 ディレクトリが書き込み可能であることを確認してください。
- Logger.LoggingMode = Logger.LoggingModes.All:情報レベルのログ、警告、エラーを含むすべてのイベントを記録するようにログ モードを設定します。 この包括的なログ記録はデバッグに役立ちます。
ステップ3: PDFドキュメントの読み込み
# Load an existing PDF document
pdf = PdfDocument.FromFile("content.pdf")# Load an existing PDF document
pdf = PdfDocument.FromFile("content.pdf")PdfDocument.FromFile("content.pdf"): PdfDocumentオブジェクトを作成して、"content.pdf" という名前の PDF ファイルを環境に読み込みます。
- pdf変数は PDF ドキュメントを保持し、さまざまな操作を実行できるようになりました。
ステップ4: 文書全体からテキストを抽出する
# Extract all text from the PDF document
all_text = pdf.ExtractAllText()
# Print the extracted text
print(all_text)# Extract all text from the PDF document
all_text = pdf.ExtractAllText()
# Print the extracted text
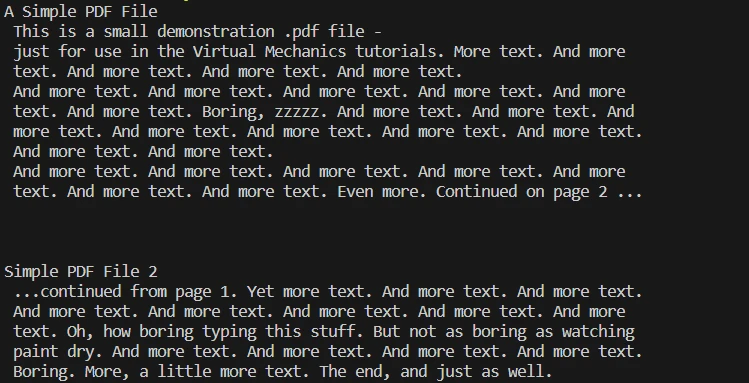
print(all_text)pdf.ExtractAllText():ドキュメントからすべてのテキスト コンテンツを抽出します。 テキストは変数all_textに保存されます。
- print(all_text):抽出されたテキストをコンソールに出力し、テキスト抽出プロセスを確認します。
ステップ5: 特定のページからテキストを抽出する
# Load an existing PDF document (already loaded, but shown for clarity)
pdf = PdfDocument.FromFile("content.pdf")
# Extract text from a specific page in the document
page_text = pdf.ExtractTextFromPage(1)
# Print the extracted text from the specific page
print(page_text)# Load an existing PDF document (already loaded, but shown for clarity)
pdf = PdfDocument.FromFile("content.pdf")
# Extract text from a specific page in the document
page_text = pdf.ExtractTextFromPage(1)
# Print the extracted text from the specific page
print(page_text)PdfDocument.FromFile("content.pdf"):テキストを抽出するために PDF ファイル オブジェクト ( PdfDocumentオブジェクト) が必要であることを示します。 ドキュメントが連続スクリプトですでに読み込まれている場合、この行は必要ありません。
pdf.ExtractTextFromPage(1): PDFの2ページ目(インデックス1)からテキストを抽出します。
- この例では、操作を確認するために抽出されたテキストを印刷することを想定しています: print(page_text) 。
このチュートリアルでは、ドキュメント全体を処理する必要がある場合でも、個々のページのみを処理する必要がある場合でも、Python の IronPDF ライブラリを使用して、開発者が PDF ファイルの内容をテキストに変換するための明確な方法を説明します。
完全なコードスニペット
使用できる完全なコードは次のとおりです。
from ironpdf import *
# Add your License key here
License.LicenseKey = "License-Code"
# Enable debugging for IronPDF
Logger.EnableDebugging = True
# Specify the log file path
Logger.LogFilePath = "Custom.log"
# Set logging mode to log all events
Logger.LoggingMode = Logger.LoggingModes.All
# Load an existing PDF document
pdf = PdfDocument.FromFile("sample.pdf")
# Extract all text from the PDF document
all_text = pdf.ExtractAllText()
# Print the extracted text
print(all_text)from ironpdf import *
# Add your License key here
License.LicenseKey = "License-Code"
# Enable debugging for IronPDF
Logger.EnableDebugging = True
# Specify the log file path
Logger.LogFilePath = "Custom.log"
# Set logging mode to log all events
Logger.LoggingMode = Logger.LoggingModes.All
# Load an existing PDF document
pdf = PdfDocument.FromFile("sample.pdf")
# Extract all text from the PDF document
all_text = pdf.ExtractAllText()
# Print the extracted text
print(all_text)PDFファイルの高度な機能
PDFファイルを他の形式に変換する
IronPDF はテキスト抽出だけを処理するのではありません。 その主な機能の 1 つは、PDF ファイルを他の形式に変換する機能です。これは、さまざまな媒体で情報を共有したり提示したりする場合、特に便利です。
PDFドキュメントの印刷と管理
PDF ファイルの印刷ジョブを Python から直接管理することは、物理的なドキュメント作成に非常に役立ちます。 IronPDF はこの機能を提供し、わずか数個のコマンドでデジタルから物理へのプロセスを合理化します。
スキャンしたPDFファイルの取り扱い
スキャンされた PDF ファイルの場合、IronPDF はテキストを抽出するための特殊な方法を提供しますが、コンテンツが選択可能なテキストではなく画像であるという性質上、これは難しい作業になる場合があります。 これにより、ライブラリのユーティリティがより広範なドキュメント管理タスクに拡張されます。
PDF処理技術の進化
PDF 処理テクノロジーは、単純なテキスト抽出から複雑なデータ処理、よりインタラクティブなドキュメント操作まで、急速に進化してきました。 焦点は自動化、人工知能、クラウドベースのサービスへと移行しており、より動的でインテリジェントなドキュメント処理ソリューションが可能になります。
IronPDF は、これらの最先端技術を取り入れて、関連性と堅牢性を維持しながら、連動して進化していくと思われます。
結論: IronPDFでワークフローを効率化する
IronPDF は PDF からテキストへの変換を簡素化し、ワークフローを合理化するため、開発者や企業にとって貴重な資産となります。
IronPDF は、Python 環境にシームレスに統合できる機能、標準 PDF とスキャンされた PDF の両方から強力なテキスト抽出を実行できる機能、元のドキュメントの形式を忠実に維持できる機能など、その優れた点が際立っています。
ライブラリのログ記録およびデバッグ機能は、PDF 操作用の信頼性の高いアプリケーションの開発にさらに役立ちます。
PDF をテキストに変換した後、抽出されたデータを活用するための手順は以下になります。 これは、テキストをデータベースに統合したり、データ分析を実行したり、レポートツールに入力したり、機械学習に利用したりすることを意味します。
テキストデータがよりアクセスしやすい形式になることで、この情報の処理と使用の可能性が大幅に広がり、新たな洞察と運用効率の向上につながります。
IronPDF は30 日間の無料トライアルを提供しており、購入前に全機能を試して評価することができます。 この試用期間は、開発者にとって、IronPDF が PDF ワークフローを効率化できる様子を直接体験できる絶好の機会です。
よくある質問
Python で PDF からテキストを抽出するにはどうすればよいですか?
Python で PDF からテキストを抽出するには IronPDF を使用できます。PdfDocument.FromFile('filename.pdf')を使用して PDF ドキュメントを読み込み、pdf.ExtractAllText()を使用してテキストを抽出します。
Python で PDF を処理するために IronPDF を使用する利点は何ですか?
IronPDF は Python 環境へのシームレスな統合を実現するテキスト抽出、ドキュメント操作、変換の強力なツールを提供します。その高度な機能には、スキャンされた PDF の処理や PDF を他の形式に変換することが含まれます。
Python で IronPDF をインストールするにはどうすればよいですか?
IronPDF をインストールするには、Python 3.x と pip がインストールされていることを確認してください。コマンドラインまたはターミナルで pip install ironpdf コマンドを実行します。
IronPDF はスキャンされた PDF ファイルを処理できますか?
はい、IronPDF には画像形式のコンテンツを含むドキュメントで作業できるように、スキャンされた PDF ファイルからテキストを抽出するための専門的なメソッドがあります。
Python で IronPDF を使用するためのシステム要件は何ですか?
IronPDF を使用するには Python 3.x、pip (Python パッケージインストーラー) が必要で、Windows システムのユーザーには .NET Frameworkが必要です。
IronPDF を使用して PDF を他の形式に変換するにはどうすればよいですか?
IronPDF による変換メソッドを活用して、PDF をさまざまな形式に変換し、Python アプリケーションでのドキュメント管理の柔軟性を高めます。
IronPDFの無料試用版はありますか?
はい、IronPDF は 30 日間の無料トライアルを提供しており、開発者が購入前にその機能を探索して評価することができます。
IronPDF を使用する際にログが重要な理由は何ですか?
IronPDF のロギングは、操作を追跡し、問題をトラブルシューティングし、情報レベルのログ、警告、エラーを含むすべてのイベントを記録するために不可欠であり、デバッグに役立ちます。
IronPDF は Python でのワークフローの自動化をどのように強化しますか?
IronPDF は PDF からテキストへの変換を簡素化し、Python プロジェクトへのシームレスな統合を可能にすることでワークフローの自動化を強化し、生産性と運用効率を向上させます。
















