xml2js npm (jak to działa dla programistów)
Programiści mogą z łatwością włączyć do swoich aplikacji funkcje analizowania danych XML i tworzenia plików PDF, łącząc XML2JS z IronPDF for Node.js. XML2JS, popularny pakiet Node.js, ułatwia przekształcanie danych XML w obiekty JavaScript, ułatwiając programową manipulację i wykorzystanie materiałów XML. Z kolei IronPDF specjalizuje się w tworzeniu wysokiej jakości dokumentów PDF z regulowanym rozmiarem stron, marginesami i nagłówkami na podstawie kodu HTML, w tym materiałów tworzonych dynamicznie.
Dzięki XML2JS i IronPDF programiści mogą teraz dynamicznie tworzyć raporty PDF, faktury lub inne materiały do druku bezpośrednio ze źródeł danych XML. Aby zautomatyzować procesy generowania dokumentów oraz zapewnić poprawność i elastyczność w zarządzaniu danymi opartymi na XML dla plików PDF w aplikacjach Node.js, integracja ta wykorzystuje zalety obu bibliotek.
Czym jest xml2js?
Pakiet Node.js o nazwie XML2JS ułatwia analizowanie i tworzenie prostego konwertera obiektów z języka XML (Extensible Markup Language) na JavaScript. Dzięki możliwości analizowania plików XML lub tekstów i konwertowania ich na uporządkowane obiekty JavaScript, ułatwia przetwarzanie dokumentów XML. Procedura ta zapewnia aplikacjom swobodę w interpretacji i wykorzystaniu danych XML poprzez udostępnienie opcji zarządzania wyłącznie atrybutami XML, treścią tekstową, przestrzeniami nazw, atrybutami scalającymi lub atrybutami kluczy oraz innymi cechami charakterystycznymi dla XML.
Biblioteka może obsługiwać ogromne dokumenty XML lub sytuacje, w których wymagane jest parsowanie nieblokujące, ponieważ obsługuje zarówno operacje parsowania synchronicznego, jak i asynchronicznego. Ponadto XML2JS oferuje mechanizmy do sprawdzania poprawności i rozwiązywania błędów podczas konwersji XML na obiekty JavaScript, gwarantując stabilność i niezawodność operacji przetwarzania danych. Biorąc wszystko pod uwagę, aplikacje Node.js często wykorzystują XML2JS do integracji źródeł danych opartych na XML, konfiguracji oprogramowania, zmiany formatów danych oraz usprawniania procedur automatycznego testowania.
XML2JS jest elastycznym i niezbędnym narzędziem do pracy z danymi XML w aplikacjach Node.js ze względu na następujące cechy:
Analiza XML
Dzięki XML2JS programiści mogą szybciej uzyskiwać dostęp do danych XML i obsługiwać je przy użyciu dobrze znanej składni JavaScript, usprawniając przetwarzanie ciągów znaków lub plików XML na obiekty JavaScript.
Konwersja obiektów JavaScript
Praca z danymi XML w aplikacjach JavaScript jest ułatwiona dzięki płynnej konwersji danych XML na ustrukturyzowane obiekty JavaScript.
Opcje konfiguracyjne
XML2JS oferuje szereg opcji konfiguracyjnych, które pozwalają modyfikować sposób analizowania danych XML i konwertowania ich na obiekty JavaScript. Obejmuje to zarządzanie przestrzeniami nazw, treścią tekstową, atrybutami i innymi elementami.
Konwersja dwukierunkowa
Dwukierunkowa konwersja umożliwia wprowadzanie zmian w danych w obie strony, co pozwala na przekształcanie obiektów JavaScript z powrotem w proste ciągi XML.
Parsowanie asynchroniczne
Duże dokumenty XML mogą być dobrze obsługiwane dzięki obsłudze przez bibliotekę asynchronicznych procesów parsowania, co nie zakłóca pętli zdarzeń aplikacji.
Obsługa błędów
W celu obsługi problemów z walidacją i błędów parsowania, które mogą pojawić się podczas procesu parsowania i transformacji XML, XML2JS oferuje zaawansowane metody obsługi błędów.
Integracja z Promises
Działa dobrze z obietnicami JavaScript, dzięki czemu asynchroniczne wzorce kodu do obsługi danych XML są bardziej przejrzyste i łatwiejsze w obsłudze.
Konfigurowalne haki parsujące
Programiści mogą zwiększyć elastyczność procesów przetwarzania danych, tworząc niestandardowe haki parsowania, które dają im specjalne opcje przechwytywania i zmiany zachowania parsowania XML.
Utwórz i skonfiguruj xml2js
Zainstalowanie biblioteki i skonfigurowanie jej zgodnie z własnymi potrzebami to pierwsze kroki w korzystaniu z XML2JS w aplikacji Node.js. Oto szczegółowa instrukcja konfiguracji i tworzenia XML2JS.
Zainstaluj XML2JS npm
Upewnij się, że npm i Node.js są już zainstalowane. XML2JS można zainstalować za pomocą npm:
npm install xml2jsnpm install xml2jsPodstawowe zastosowanie XML2JS
Oto prosta ilustracja pokazująca, jak używać XML2JS do analizowania tekstu XML na obiekty JavaScript:
const xml2js = require('xml2js');
// Example XML content
const xmlContent = `
<bookstore>
<book category="fiction">
<title>Harry Potter</title>
<author>J.K. Rowling</author>
</book>
<book category="nonfiction">
<title>Thinking, Fast and Slow</title>
<author>Daniel Kahneman</author>
</book>
</bookstore>
`;
// Configure XML2JS parser
const parser = new xml2js.Parser();
// Parse XML content
parser.parseString(xmlContent, (err, result) => {
if (err) {
console.error('Error parsing XML:', err);
return;
}
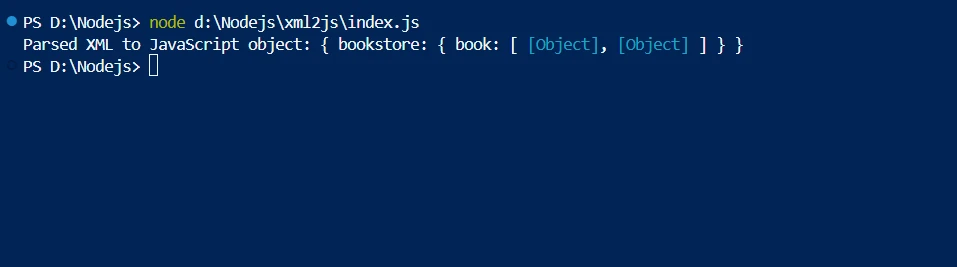
console.log('Parsed XML to JavaScript object:', result);
});const xml2js = require('xml2js');
// Example XML content
const xmlContent = `
<bookstore>
<book category="fiction">
<title>Harry Potter</title>
<author>J.K. Rowling</author>
</book>
<book category="nonfiction">
<title>Thinking, Fast and Slow</title>
<author>Daniel Kahneman</author>
</book>
</bookstore>
`;
// Configure XML2JS parser
const parser = new xml2js.Parser();
// Parse XML content
parser.parseString(xmlContent, (err, result) => {
if (err) {
console.error('Error parsing XML:', err);
return;
}
console.log('Parsed XML to JavaScript object:', result);
});
Opcje konfiguracji
XML2JS oferuje szereg opcji konfiguracyjnych i ustawień domyślnych, które pozwalają modyfikować sposób działania parsowania. Oto przykład tego, jak ustawić domyślne ustawienia parsowania dla XML2JS:
const xml2js = require('xml2js');
// Example XML content
const xmlContent = `
<bookstore>
<book category="fiction">
<title>Harry Potter</title>
<author>J.K. Rowling</author>
</book>
<book category="nonfiction">
<title>Thinking, Fast and Slow</title>
<author>Daniel Kahneman</author>
</book>
</bookstore>
`;
// Configure XML2JS parser with options
const parser = new xml2js.Parser({
explicitArray: false, // Converts child elements to objects instead of arrays when there is only one child
trim: true // Trims leading/trailing whitespace from text nodes
});
// Parse XML content
parser.parseString(xmlContent, (err, result) => {
if (err) {
console.error('Error parsing XML:', err);
return;
}
console.log('Parsed XML to JavaScript object with options:', result);
});const xml2js = require('xml2js');
// Example XML content
const xmlContent = `
<bookstore>
<book category="fiction">
<title>Harry Potter</title>
<author>J.K. Rowling</author>
</book>
<book category="nonfiction">
<title>Thinking, Fast and Slow</title>
<author>Daniel Kahneman</author>
</book>
</bookstore>
`;
// Configure XML2JS parser with options
const parser = new xml2js.Parser({
explicitArray: false, // Converts child elements to objects instead of arrays when there is only one child
trim: true // Trims leading/trailing whitespace from text nodes
});
// Parse XML content
parser.parseString(xmlContent, (err, result) => {
if (err) {
console.error('Error parsing XML:', err);
return;
}
console.log('Parsed XML to JavaScript object with options:', result);
});Obsługa parsowania asynchronicznego
Parsowanie asynchroniczne jest obsługiwane przez XML2JS, co jest przydatne do zarządzania dużymi dokumentami XML bez zatrzymywania pętli zdarzeń. Oto ilustracja pokazująca, jak używać składni async/await z XML2JS:
const xml2js = require('xml2js');
// Example XML content (assume it's loaded asynchronously, e.g., from a file)
const xmlContent = `
<bookstore>
<book category="fiction">
<title>Harry Potter</title>
<author>J.K. Rowling</author>
</book>
<book category="nonfiction">
<title>Thinking, Fast and Slow</title>
<author>Daniel Kahneman</author>
</book>
</bookstore>
`;
// Configure XML2JS parser
const parser = new xml2js.Parser();
// Async function to parse XML content
async function parseXml(xmlContent) {
try {
const result = await parser.parseStringPromise(xmlContent);
console.log('Parsed XML to JavaScript object (async):', result);
} catch (err) {
console.error('Error parsing XML (async):', err);
}
}
// Call async function to parse XML content
parseXml(xmlContent);const xml2js = require('xml2js');
// Example XML content (assume it's loaded asynchronously, e.g., from a file)
const xmlContent = `
<bookstore>
<book category="fiction">
<title>Harry Potter</title>
<author>J.K. Rowling</author>
</book>
<book category="nonfiction">
<title>Thinking, Fast and Slow</title>
<author>Daniel Kahneman</author>
</book>
</bookstore>
`;
// Configure XML2JS parser
const parser = new xml2js.Parser();
// Async function to parse XML content
async function parseXml(xmlContent) {
try {
const result = await parser.parseStringPromise(xmlContent);
console.log('Parsed XML to JavaScript object (async):', result);
} catch (err) {
console.error('Error parsing XML (async):', err);
}
}
// Call async function to parse XML content
parseXml(xmlContent);Pierwsze kroki
Aby używać IronPDF i XML2JS w aplikacji Node.js, należy najpierw odczytać dane XML, a następnie utworzyć dokument PDF na podstawie przetworzonej treści. Jest to szczegółowy poradnik, który pomoże Ci w instalacji i konfiguracji tych bibliotek.
Czym jest IronPDF?
Biblioteka IronPDF for Node.js to potężna biblioteka do pracy z plikami PDF. Celem jest konwersja treści HTML na dokumenty PDF o wyjątkowej jakości. Usprawnia proces przekształcania plików HTML, CSS i innych plików JavaScript w poprawnie sformatowane pliki PDF bez utraty jakości oryginalnej treści internetowej. Jest to bardzo przydatne narzędzie dla aplikacji internetowych, które muszą generować dynamiczne, nadające się do druku dokumenty, takie jak faktury, certyfikaty i raporty.
IronPDF posiada kilka funkcji, w tym konfigurowalne ustawienia stron, nagłówki, stopki oraz możliwość wstawiania czcionek i obrazów. Obsługuje złożone układy i style, aby zapewnić, że wszystkie testowe pliki PDF są zgodne z określonym projektem. Ponadto IronPDF kontroluje wykonywanie kodu JavaScript w HTML, umożliwiając dokładne renderowanie treści dynamicznych i interaktywnych.
Funkcje IronPDF
Generowanie plików PDF z HTML
Konwertuj HTML, CSS i JavaScript do formatu PDF. Obsługuje dwa nowoczesne standardy internetowe: zapytania o media i projekt responsywny. Przydatne do dynamicznego formatowania faktur, raportów i dokumentów PDF przy użyciu HTML i CSS.
Edycja plików PDF
Możliwe jest dodawanie tekstu, obrazów i innych materiałów do już istniejących plików PDF. Wyodrębnij tekst i obrazy z plików PDF. Połącz wiele plików PDF w jeden plik. Podziel pliki PDF na kilka oddzielnych dokumentów. Dodaj nagłówki, stopki, adnotacje i znaki wodne.
Wydajność i niezawodność
W kontekście przemysłowym pożądanymi cechami projektowymi są wysoka wydajność i niezawodność. Z łatwością obsługuje duże zbiory dokumentów.
Zainstaluj IronPDF
Aby uzyskać narzędzia potrzebne do pracy z plikami PDF w projektach Node.js, zainstaluj pakiet IronPDF.
npm install @ironsoftware/ironpdfnpm install @ironsoftware/ironpdfAnaliza XML i generowanie plików PDF
Aby to zilustrować, wygenerujmy podstawowy plik XML o nazwie example.xml:
<bookstore>
<book category="fiction">
<title>Harry Potter</title>
<author>J.K. Rowling</author>
</book>
<book category="nonfiction">
<title>Thinking, Fast and Slow</title>
<author>Daniel Kahneman</author>
</book>
</bookstore>
<bookstore>
<book category="fiction">
<title>Harry Potter</title>
<author>J.K. Rowling</author>
</book>
<book category="nonfiction">
<title>Thinking, Fast and Slow</title>
<author>Daniel Kahneman</author>
</book>
</bookstore>Utwórz skrypt Node.js generatePdf.js, który odczytuje plik XML, wykorzystuje XML2JS do przeanalizowania go na obiekt JavaScript, a następnie używa IronPDF do utworzenia pliku PDF na podstawie wynikowego obiektu przeanalizowanych danych.
// generatePdf.js
const fs = require('fs');
const xml2js = require('xml2js');
const IronPdf = require('@ironsoftware/ironpdf');
// Configure IronPDF with license if necessary
var config = IronPdf.IronPdfGlobalConfig;
config.setConfig({ licenseKey: '' });
// Function to read and parse XML
const parseXml = async (filePath) => {
const parser = new xml2js.Parser();
const xmlContent = fs.readFileSync(filePath, 'utf8');
return await parser.parseStringPromise(xmlContent);
};
// Function to generate HTML content from the parsed object
function generateHtml(parsedXml) {
let htmlContent = `
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Bookstore</title>
<style>
body { font-family: Arial, sans-serif; }
.book { margin-bottom: 20px; }
</style>
</head>
<body>
<h1>Bookstore</h1>
`;
// Iterate over each book to append to the HTML content
parsedXml.bookstore.book.forEach(book => {
htmlContent += `
<div class="book">
<h2>${book.title}</h2>
<p><strong>Category:</strong> ${book.$.category}</p>
<p><strong>Author:</strong> ${book.author}</p>
</div>
`;
});
htmlContent += `
</body>
</html>
`;
return htmlContent;
}
// Main function to generate PDF
const generatePdf = async () => {
try {
const parser = await parseXml('./example.xml');
const htmlContent = generateHtml(parser);
// Convert HTML to PDF
IronPdf.PdfDocument.fromHtml(htmlContent).then((pdfres) => {
const filePath = `${Date.now()}.pdf`;
pdfres.saveAs(filePath).then(() => {
console.log('PDF saved successfully!');
}).catch((e) => {
console.log(e);
});
});
} catch (error) {
console.error('Error:', error);
}
};
// Run the main function
generatePdf();// generatePdf.js
const fs = require('fs');
const xml2js = require('xml2js');
const IronPdf = require('@ironsoftware/ironpdf');
// Configure IronPDF with license if necessary
var config = IronPdf.IronPdfGlobalConfig;
config.setConfig({ licenseKey: '' });
// Function to read and parse XML
const parseXml = async (filePath) => {
const parser = new xml2js.Parser();
const xmlContent = fs.readFileSync(filePath, 'utf8');
return await parser.parseStringPromise(xmlContent);
};
// Function to generate HTML content from the parsed object
function generateHtml(parsedXml) {
let htmlContent = `
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Bookstore</title>
<style>
body { font-family: Arial, sans-serif; }
.book { margin-bottom: 20px; }
</style>
</head>
<body>
<h1>Bookstore</h1>
`;
// Iterate over each book to append to the HTML content
parsedXml.bookstore.book.forEach(book => {
htmlContent += `
<div class="book">
<h2>${book.title}</h2>
<p><strong>Category:</strong> ${book.$.category}</p>
<p><strong>Author:</strong> ${book.author}</p>
</div>
`;
});
htmlContent += `
</body>
</html>
`;
return htmlContent;
}
// Main function to generate PDF
const generatePdf = async () => {
try {
const parser = await parseXml('./example.xml');
const htmlContent = generateHtml(parser);
// Convert HTML to PDF
IronPdf.PdfDocument.fromHtml(htmlContent).then((pdfres) => {
const filePath = `${Date.now()}.pdf`;
pdfres.saveAs(filePath).then(() => {
console.log('PDF saved successfully!');
}).catch((e) => {
console.log(e);
});
});
} catch (error) {
console.error('Error:', error);
}
};
// Run the main function
generatePdf();Prostym sposobem na konwersję danych XML i parsowanie wielu plików do dokumentów PDF jest połączenie IronPDF i XML2JS w aplikacji Node.js. Za pomocą XML2JS zawartość XML wielu plików jest analizowana do obiektu JavaScript po pierwszym odczytaniu pliku XML przy użyciu modułu fs biblioteki Node.js. Następnie tekst HTML, który stanowi podstawę pliku PDF, jest generowany dynamicznie przy użyciu tych przetworzonych danych.
Skrypt rozpoczyna się od odczytania tekstu XML z pliku i użycia xml2js do przeanalizowania go na obiekt JavaScript. Na podstawie przeanalizowanego obiektu danych funkcja niestandardowa tworzy treść HTML, strukturyzując ją za pomocą wymaganych elementów — na przykład autorów i tytułów w przypadku księgarni. Ten kod HTML jest następnie renderowany do bufora PDF przy użyciu IronPDF. Wygenerowany plik PDF jest następnie zapisywany w systemie plików.
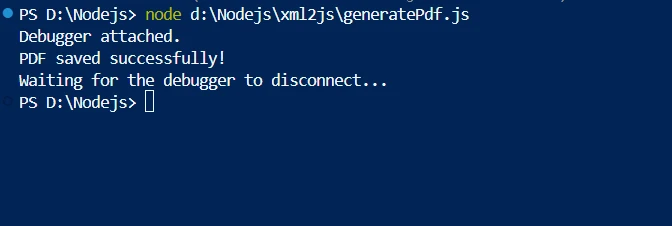
Wykorzystując skuteczną konwersję HTML do PDF oferowaną przez IronPDF oraz solidne możliwości parsowania XML w XML2JS, ta metoda zapewnia uproszczony sposób tworzenia plików PDF z danych XML w aplikacjach Node.js. Połączenie to umożliwia przekształcanie dynamicznych danych XML w dokumenty PDF, które można wydrukować i które mają odpowiedni format. Dzięki temu idealnie nadaje się do aplikacji wymagających automatycznego generowania dokumentów ze źródeł XML.
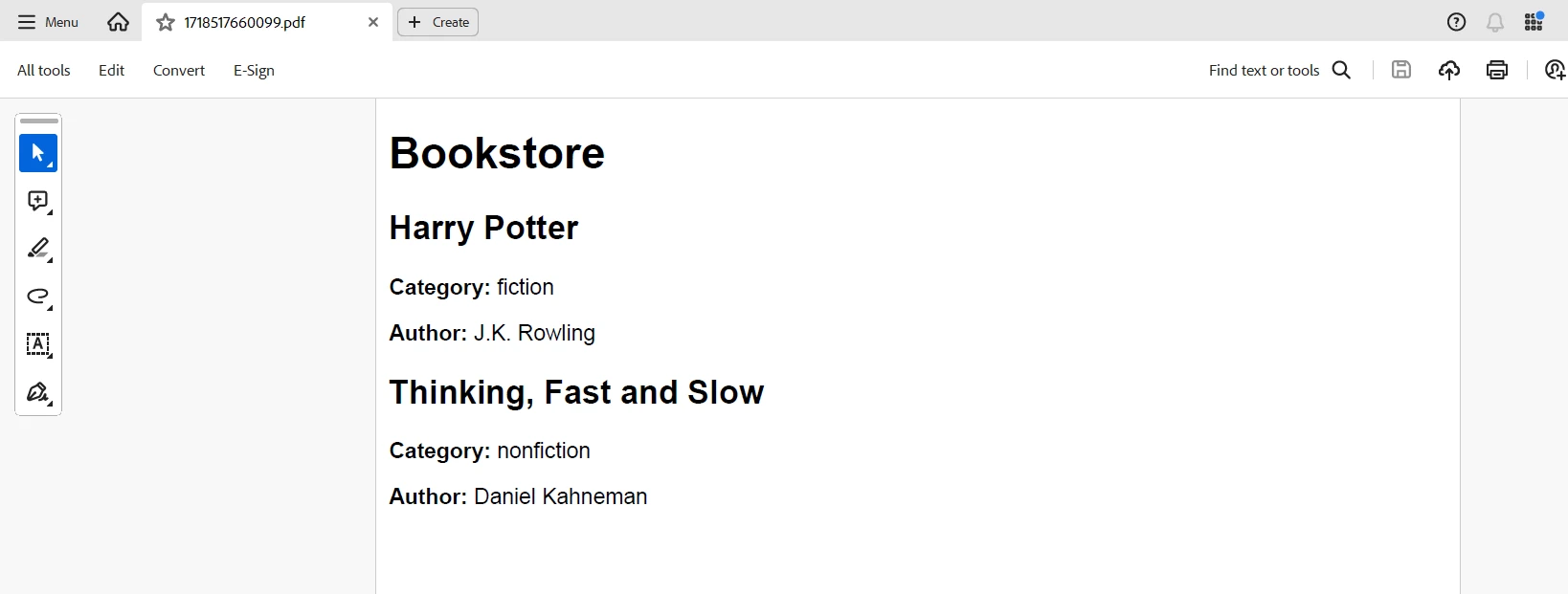
Wnioski
Podsumowując, połączenie XML2JS i IronPDF w aplikacji Node.js zapewnia solidny i elastyczny sposób przekształcania danych XML w wysokiej jakości dokumenty PDF. Skuteczne parsowanie XML do obiektów JavaScript przy użyciu XML2JS ułatwia pozyskiwanie i przetwarzanie danych. Po przeanalizowaniu danych można je dynamicznie przekształcić w tekst HTML, który IronPDF może następnie łatwo przekonwertować na poprawnie ustrukturyzowane pliki PDF.
To połączenie może okazać się szczególnie pomocne w aplikacjach wymagających automatycznego tworzenia dokumentów, takich jak raporty, faktury i certyfikaty, na podstawie danych XML. Programiści mogą zapewnić dokładne i estetyczne pliki PDF, usprawnić przepływ pracy oraz poprawić zdolność aplikacji Node.js do obsługi zadań związanych z generowaniem dokumentów, wykorzystując zalety obu bibliotek.
IronPDF oferuje programistom więcej możliwości oraz bardziej wydajne tworzenie oprogramowania, a wszystko to przy wykorzystaniu wysoce elastycznych systemów i Suite Iron Software.
Programistom łatwiej jest wybrać najlepszy model, gdy opcje licencji są jasno określone i dostosowane do projektu. Funkcje te pozwalają programistom rozwiązywać różnorodne problemy w łatwy w użyciu, wydajny i spójny sposób.