xml2js npm (Como funciona para desenvolvedores)
Os desenvolvedores podem incorporar facilmente recursos de análise de dados XML e criação de PDFs em seus aplicativos combinando XML2JS com IronPDF no Node.js O XML2JS, um pacote Node.js bastante popular, facilita a transformação de dados XML em objetos JavaScript , permitindo a manipulação programática e o uso de material XML. Por outro lado, o IronPDF se especializa na produção de documentos PDF de alta qualidade com tamanhos de página, margens e cabeçalhos ajustáveis a partir de HTML , incluindo material criado dinamicamente.
Agora, os desenvolvedores podem criar dinamicamente relatórios em PDF, faturas ou outros materiais imprimíveis diretamente de fontes de dados XML com a ajuda do XML2JS e do IronPDF. Para automatizar os processos de geração de documentos e garantir a correção e a flexibilidade no gerenciamento de dados baseados em XML para saídas em PDF em aplicações Node.js , esta integração aproveita os pontos fortes de ambas as bibliotecas.
O que é xml2js?
Um pacote Node.js chamado XML2JS facilita a análise e a criação de um conversor simples de XML (Extensible Markup Language) para objetos JavaScript . Ao oferecer maneiras de analisar arquivos ou textos XML e convertê-los em objetos JavaScript estruturados, facilita o processamento de documentos XML. Este procedimento oferece liberdade às aplicações na forma como interpretam e utilizam dados XML, fornecendo opções para gerenciar apenas atributos XML, conteúdo de texto, namespaces, atributos de mesclagem ou atributos de chaveamento, e outras características específicas do XML.
A biblioteca consegue lidar com documentos XML enormes ou situações em que é necessária uma análise não bloqueante, pois suporta operações de análise síncrona e assíncrona. Além disso, o XML2JS oferece mecanismos para validar e resolver erros durante a conversão de XML em objetos JavaScript , garantindo a estabilidade e a confiabilidade das operações de processamento de dados. Considerando todos os aspectos, as aplicações Node.js frequentemente utilizam XML2JS para integrar fontes de dados baseadas em XML, configurar software, alterar formatos de dados e agilizar procedimentos de teste automatizados.
XML2JS é uma ferramenta flexível e indispensável para trabalhar com dados XML em aplicações Node.js devido às seguintes características:
Análise XML
Com a ajuda do XML2JS, os desenvolvedores podem acessar e manipular dados XML mais rapidamente, utilizando a conhecida sintaxe JavaScript , simplificando o processamento de strings ou arquivos XML em objetos JavaScript .
Conversão de objetos JavaScript
Trabalhar com dados XML em aplicações JavaScript é simplificado pela conversão eficiente de dados XML em objetos JavaScript estruturados.
Opções configuráveis
O XML2JS oferece diversas opções de configuração que permitem alterar a forma como os dados XML são analisados e convertidos em objetos JavaScript . Isso abrange o gerenciamento de namespaces, conteúdo de texto, atributos e outros elementos.
Conversão bidirecional
As alterações de dados de ida e volta são possíveis graças às suas capacidades de conversão bidirecional, que permitem que objetos JavaScript sejam transformados novamente em strings XML simples.
Análise sintática assíncrona
Documentos XML grandes podem ser tratados de forma eficiente graças ao suporte da biblioteca para processos de análise assíncrona, que não interfere no loop de eventos da aplicação.
Tratamento de erros
Para lidar com problemas de validação e erros de análise que possam surgir durante o processo de análise e transformação de XML, o XML2JS oferece métodos robustos de tratamento de erros.
Integração com Promises
Funciona bem com Promises em JavaScript , tornando os padrões de código assíncrono para manipulação de dados XML mais claros e fáceis de usar.
Ganchos de análise personalizáveis
A flexibilidade dos processos de processamento de dados pode ser aumentada pelos desenvolvedores através da criação de ganchos de análise personalizados que lhes permitem opções especiais para interceptar e alterar o comportamento da análise XML.
Criar e configurar xml2js
A instalação da biblioteca e sua configuração de acordo com as suas necessidades são os passos iniciais para usar o XML2JS em uma aplicação Node.js Este é um guia detalhado sobre como configurar e criar XML2JS.
Instale o XML2JS via npm.
Certifique-se de que o npm e o Node.js estejam instalados primeiro. O XML2JS pode ser instalado com o npm:
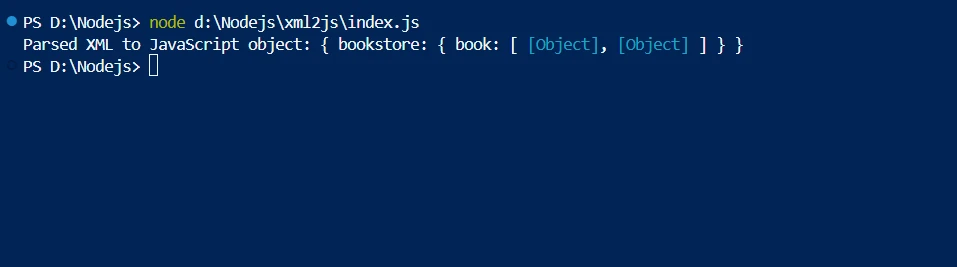
npm install xml2jsnpm install xml2jsUso básico do XML2JS
Esta é uma ilustração simples de como usar o XML2JS para analisar texto XML e convertê-lo em objetos JavaScript :
const xml2js = require('xml2js');
// Example XML content
const xmlContent = `
<bookstore>
<book category="fiction">
<title>Harry Potter</title>
<author>J.K. Rowling</author>
</book>
<book category="nonfiction">
<title>Thinking, Fast and Slow</title>
<author>Daniel Kahneman</author>
</book>
</bookstore>
`;
// Configure XML2JS parser
const parser = new xml2js.Parser();
// Parse XML content
parser.parseString(xmlContent, (err, result) => {
if (err) {
console.error('Error parsing XML:', err);
return;
}
console.log('Parsed XML to JavaScript object:', result);
});const xml2js = require('xml2js');
// Example XML content
const xmlContent = `
<bookstore>
<book category="fiction">
<title>Harry Potter</title>
<author>J.K. Rowling</author>
</book>
<book category="nonfiction">
<title>Thinking, Fast and Slow</title>
<author>Daniel Kahneman</author>
</book>
</bookstore>
`;
// Configure XML2JS parser
const parser = new xml2js.Parser();
// Parse XML content
parser.parseString(xmlContent, (err, result) => {
if (err) {
console.error('Error parsing XML:', err);
return;
}
console.log('Parsed XML to JavaScript object:', result);
});
Opções de configuração
O XML2JS oferece uma variedade de opções de configuração e configurações padrão que permitem alterar o comportamento da análise sintática. Aqui está uma ilustração de como definir as configurações de análise padrão para XML2JS:
const xml2js = require('xml2js');
// Example XML content
const xmlContent = `
<bookstore>
<book category="fiction">
<title>Harry Potter</title>
<author>J.K. Rowling</author>
</book>
<book category="nonfiction">
<title>Thinking, Fast and Slow</title>
<author>Daniel Kahneman</author>
</book>
</bookstore>
`;
// Configure XML2JS parser with options
const parser = new xml2js.Parser({
explicitArray: false, // Converts child elements to objects instead of arrays when there is only one child
trim: true // Trims leading/trailing whitespace from text nodes
});
// Parse XML content
parser.parseString(xmlContent, (err, result) => {
if (err) {
console.error('Error parsing XML:', err);
return;
}
console.log('Parsed XML to JavaScript object with options:', result);
});const xml2js = require('xml2js');
// Example XML content
const xmlContent = `
<bookstore>
<book category="fiction">
<title>Harry Potter</title>
<author>J.K. Rowling</author>
</book>
<book category="nonfiction">
<title>Thinking, Fast and Slow</title>
<author>Daniel Kahneman</author>
</book>
</bookstore>
`;
// Configure XML2JS parser with options
const parser = new xml2js.Parser({
explicitArray: false, // Converts child elements to objects instead of arrays when there is only one child
trim: true // Trims leading/trailing whitespace from text nodes
});
// Parse XML content
parser.parseString(xmlContent, (err, result) => {
if (err) {
console.error('Error parsing XML:', err);
return;
}
console.log('Parsed XML to JavaScript object with options:', result);
});Lidando com análise sintática assíncrona
A análise assíncrona é suportada pelo XML2JS, o que é útil para gerenciar grandes documentos XML sem interromper o loop de eventos. Aqui está uma ilustração de como usar a sintaxe async/await com XML2JS:
const xml2js = require('xml2js');
// Example XML content (assume it's loaded asynchronously, e.g., from a file)
const xmlContent = `
<bookstore>
<book category="fiction">
<title>Harry Potter</title>
<author>J.K. Rowling</author>
</book>
<book category="nonfiction">
<title>Thinking, Fast and Slow</title>
<author>Daniel Kahneman</author>
</book>
</bookstore>
`;
// Configure XML2JS parser
const parser = new xml2js.Parser();
// Async function to parse XML content
async function parseXml(xmlContent) {
try {
const result = await parser.parseStringPromise(xmlContent);
console.log('Parsed XML to JavaScript object (async):', result);
} catch (err) {
console.error('Error parsing XML (async):', err);
}
}
// Call async function to parse XML content
parseXml(xmlContent);const xml2js = require('xml2js');
// Example XML content (assume it's loaded asynchronously, e.g., from a file)
const xmlContent = `
<bookstore>
<book category="fiction">
<title>Harry Potter</title>
<author>J.K. Rowling</author>
</book>
<book category="nonfiction">
<title>Thinking, Fast and Slow</title>
<author>Daniel Kahneman</author>
</book>
</bookstore>
`;
// Configure XML2JS parser
const parser = new xml2js.Parser();
// Async function to parse XML content
async function parseXml(xmlContent) {
try {
const result = await parser.parseStringPromise(xmlContent);
console.log('Parsed XML to JavaScript object (async):', result);
} catch (err) {
console.error('Error parsing XML (async):', err);
}
}
// Call async function to parse XML content
parseXml(xmlContent);Começando
Para usar o IronPDF e o XML2JS em uma aplicação Node.js , primeiro você precisa ler os dados XML e depois criar um documento PDF a partir do conteúdo processado. Este é um guia detalhado que o ajudará a instalar e configurar essas bibliotecas.
O que é o IronPDF?
A biblioteca IronPDF é uma poderosa biblioteca Node.js para trabalhar com PDFs. O objetivo é converter conteúdo HTML em documentos PDF com qualidade excepcional. Simplifica o processo de conversão de arquivos HTML, CSS e outros arquivos JavaScript em PDFs formatados corretamente, sem comprometer o conteúdo original online. Esta é uma ferramenta muito útil para aplicações web que precisam gerar documentos dinâmicos e imprimíveis, como faturas, certificados e relatórios.
O IronPDF possui diversos recursos, incluindo configurações de página personalizáveis, cabeçalhos, rodapés e a possibilidade de inserir fontes e imagens. Ele oferece suporte a layouts e estilos complexos para garantir que todos os PDFs de saída dos testes sigam o design especificado. Além disso, o IronPDF controla a execução de JavaScript dentro do HTML, permitindo a renderização precisa de conteúdo dinâmico e interativo.
Funcionalidades do IronPDF
Geração de PDF a partir de HTML
Converter HTML, CSS e JavaScript para PDF. Suporta dois padrões modernos da web: media queries e design responsivo. Útil para usar HTML e CSS para decorar dinamicamente faturas, relatórios e documentos em PDF.
Edição de PDF
É possível adicionar texto, imagens e outros materiais a PDFs já existentes. Extrair texto e imagens de arquivos PDF. Una vários PDFs em um único arquivo. Divida arquivos PDF em vários documentos distintos. Adicione cabeçalhos, rodapés, anotações e marcas d'água.
Desempenho e confiabilidade
Em contextos industriais, alto desempenho e confiabilidade são atributos de projeto desejáveis. Lida facilmente com grandes conjuntos de documentos.
Instale o IronPDF
Para obter as ferramentas necessárias para trabalhar com PDFs em projetos Node.js , instale o pacote IronPDF .
npm e @ironsoftware/ironpdf
Analisar XML e gerar PDF
Para ilustrar, vamos gerar um arquivo XML básico chamado example.xml:
<bookstore>
<book category="fiction">
<title>Harry Potter</title>
<author>J.K. Rowling</author>
</book>
<book category="nonfiction">
<title>Thinking, Fast and Slow</title>
<author>Daniel Kahneman</author>
</book>
</bookstore>
<bookstore>
<book category="fiction">
<title>Harry Potter</title>
<author>J.K. Rowling</author>
</book>
<book category="nonfiction">
<title>Thinking, Fast and Slow</title>
<author>Daniel Kahneman</author>
</book>
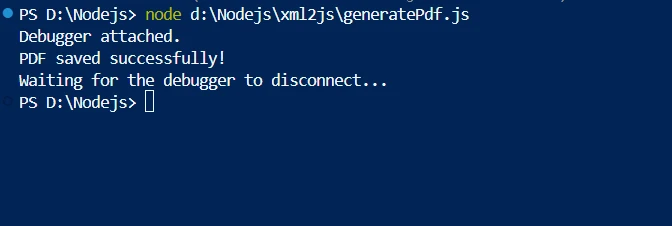
</bookstore>Crie o generatePdf.js script Node.js, que lê o arquivo XML, usa o XML2JS para convertê-lo em um objeto JavaScript e, em seguida, usa o IronPDF para criar um PDF a partir do objeto resultante dos dados analisados.
// generatePdf.js
const fs = require('fs');
const xml2js = require('xml2js');
const IronPdf = require('@ironsoftware/ironpdf');
// Configure IronPDF with license if necessary
var config = IronPdf.IronPdfGlobalConfig;
config.setConfig({ licenseKey: '' });
// Function to read and parse XML
const parseXml = async (filePath) => {
const parser = new xml2js.Parser();
const xmlContent = fs.readFileSync(filePath, 'utf8');
return await parser.parseStringPromise(xmlContent);
};
// Function to generate HTML content from the parsed object
function generateHtml(parsedXml) {
let htmlContent = `
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Bookstore</title>
<style>
body { font-family: Arial, sans-serif; }
.book { margin-bottom: 20px; }
</style>
</head>
<body>
<h1>Bookstore</h1>
`;
// Iterate over each book to append to the HTML content
parsedXml.bookstore.book.forEach(book => {
htmlContent += `
<div class="book">
<h2>${book.title}</h2>
<p><strong>Category:</strong> ${book.$.category}</p>
<p><strong>Author:</strong> ${book.author}</p>
</div>
`;
});
htmlContent += `
</body>
</html>
`;
return htmlContent;
}
// Main function to generate PDF
const generatePdf = async () => {
try {
const parser = await parseXml('./example.xml');
const htmlContent = generateHtml(parser);
// Convert HTML to PDF
IronPdf.PdfDocument.fromHtml(htmlContent).then((pdfres) => {
const filePath = `${Date.now()}.pdf`;
pdfres.saveAs(filePath).then(() => {
console.log('PDF saved successfully!');
}).catch((e) => {
console.log(e);
});
});
} catch (error) {
console.error('Error:', error);
}
};
// Run the main function
generatePdf();// generatePdf.js
const fs = require('fs');
const xml2js = require('xml2js');
const IronPdf = require('@ironsoftware/ironpdf');
// Configure IronPDF with license if necessary
var config = IronPdf.IronPdfGlobalConfig;
config.setConfig({ licenseKey: '' });
// Function to read and parse XML
const parseXml = async (filePath) => {
const parser = new xml2js.Parser();
const xmlContent = fs.readFileSync(filePath, 'utf8');
return await parser.parseStringPromise(xmlContent);
};
// Function to generate HTML content from the parsed object
function generateHtml(parsedXml) {
let htmlContent = `
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Bookstore</title>
<style>
body { font-family: Arial, sans-serif; }
.book { margin-bottom: 20px; }
</style>
</head>
<body>
<h1>Bookstore</h1>
`;
// Iterate over each book to append to the HTML content
parsedXml.bookstore.book.forEach(book => {
htmlContent += `
<div class="book">
<h2>${book.title}</h2>
<p><strong>Category:</strong> ${book.$.category}</p>
<p><strong>Author:</strong> ${book.author}</p>
</div>
`;
});
htmlContent += `
</body>
</html>
`;
return htmlContent;
}
// Main function to generate PDF
const generatePdf = async () => {
try {
const parser = await parseXml('./example.xml');
const htmlContent = generateHtml(parser);
// Convert HTML to PDF
IronPdf.PdfDocument.fromHtml(htmlContent).then((pdfres) => {
const filePath = `${Date.now()}.pdf`;
pdfres.saveAs(filePath).then(() => {
console.log('PDF saved successfully!');
}).catch((e) => {
console.log(e);
});
});
} catch (error) {
console.error('Error:', error);
}
};
// Run the main function
generatePdf();Uma maneira fácil de converter dados XML e analisar vários arquivos em documentos PDF é combinar IronPDF e XML2JS em uma aplicação Node.js Utilizando o XML2JS, o conteúdo XML de múltiplos arquivos é analisado e convertido em um objeto JavaScript assim que o arquivo XML é lido pela primeira vez usando o módulo fs do Node.js Em seguida, o texto HTML que forma a base do PDF é gerado dinamicamente usando esses dados processados.
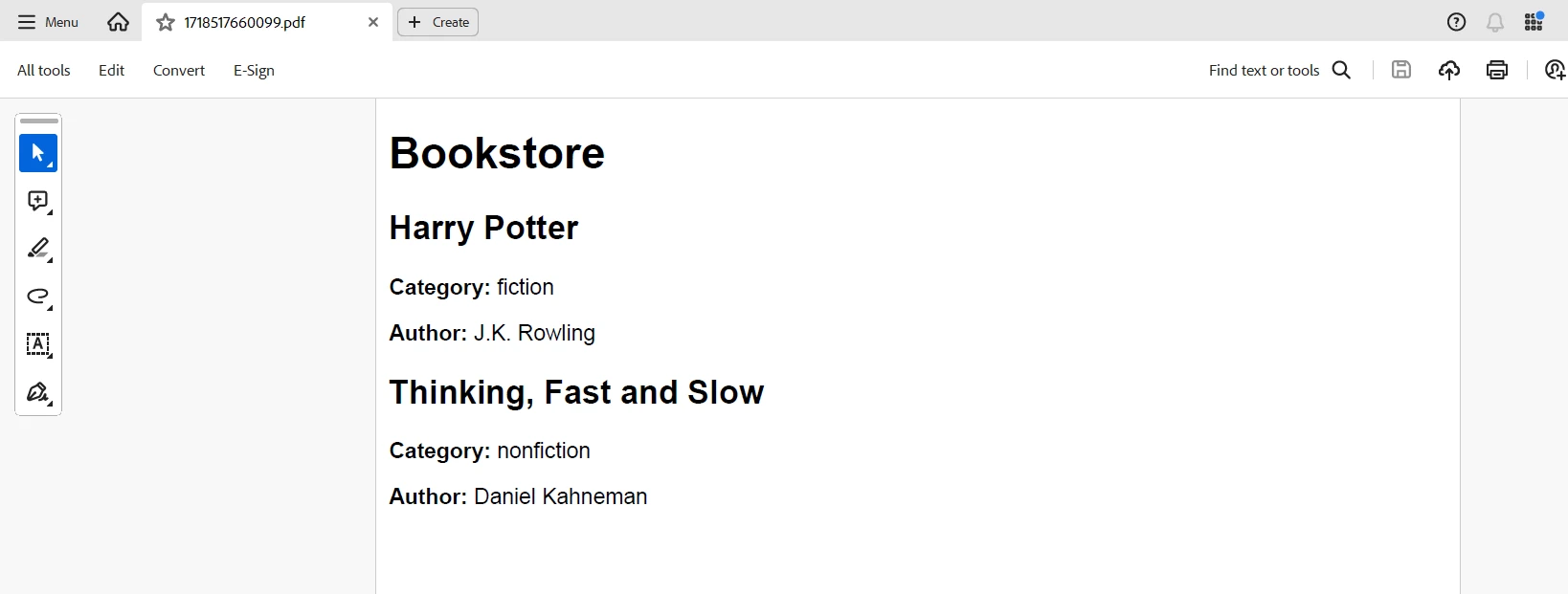
O script começa lendo um texto XML de um arquivo e usando o xml2js para analisá-lo e convertê-lo em um objeto JavaScript . A partir do objeto de dados analisado, uma função personalizada cria conteúdo HTML, estruturando-o com os elementos necessários — por exemplo, autores e títulos para uma livraria. Posteriormente, esse HTML é renderizado em um buffer PDF usando o IronPDF. O PDF gerado é então salvo no sistema de arquivos.
Utilizando a eficiente conversão de HTML para PDF do IronPDF e os robustos recursos de análise XML do XML2JS, este método oferece uma maneira simplificada de criar PDFs a partir de dados XML em aplicações Node.js Essa conexão possibilita transformar dados XML dinâmicos em documentos PDF imprimíveis e bem formatados. Isso o torna perfeito para aplicações que exigem geração automatizada de documentos a partir de fontes XML.
Conclusão
Em resumo, o XML2JS e o IronPDF, juntos em uma aplicação Node.js, oferecem uma maneira robusta e adaptável de converter dados XML em documentos PDF de alta qualidade. A análise eficiente de XML para objetos JavaScript usando XML2JS simplifica a extração e manipulação de dados. Após a análise dos dados, eles podem ser convertidos dinamicamente em texto HTML, que o IronPDF pode então converter facilmente em arquivos PDF devidamente estruturados.
Aplicações que exigem a criação automatizada de documentos como relatórios, faturas e certificados a partir de fontes de dados XML podem achar essa combinação particularmente útil. Os desenvolvedores podem garantir saídas em PDF precisas e esteticamente agradáveis, otimizar fluxos de trabalho e aprimorar a capacidade dos aplicativos Node.js de lidar com tarefas de geração de documentos, aproveitando os benefícios de ambas as bibliotecas.
O IronPDF oferece aos desenvolvedores mais recursos e um desenvolvimento mais eficiente, tudo isso utilizando os sistemas e o conjunto de ferramentas altamente flexíveis da Iron Software.
Para os desenvolvedores, é mais fácil escolher o melhor modelo quando as opções de licenciamento são explícitas e específicas para o projeto. Esses recursos permitem que os desenvolvedores resolvam uma variedade de problemas de maneira fácil, eficiente e coesa.