


Convert HTML to PDF in Node.js
O recurso mais poderoso e popular do IronPDF é a capacidade de criar PDFs de alta qualidade a partir de HTML, CSS e JavaScript brutos. Este tutorial orienta os desenvolvedores Node.js em cada método prático para transformar conteúdo HTML em PDFs — desde uma conversão de string até a geração de documentos dinâmicos baseados em templates.
IronPDF é uma biblioteca de API de alto nível que ajuda os desenvolvedores a implementar rapidamente capacidades poderosas de processamento de PDF em aplicativos de software. O IronPDF está disponível em várias linguagens de programação . Para uma cobertura detalhada sobre a criação de PDFs em .NET, Java e Python, consulte as páginas oficiais de documentação. Este tutorial abrange seu uso em projetos Node.js.
Início Rápido: Converter HTML para PDF no Node.js
Como converter HTML para PDF em Node.js
- Instale a biblioteca IronPDF Node.js via NPM:
npm install @ironsoftware/ironpdf - Importe a classe PdfDocument do pacote
@ironsoftware/ironpdf. - Chame
PdfDocument.fromHtml,PdfDocument.fromUrlouPdfDocument.fromZipdependendo do seu recurso HTML. - Opcionalmente, configure opções de renderização: cabeçalhos, rodapés, tamanho da página, orientação e margens.
- Chame
PdfDocument.saveAspara salvar o PDF gerado no disco.
Índice
- Como você começa com o IronPDF for Node.js?
- Como você converte HTML em PDF no Node.js?
- Como você cria um PDF a partir de uma string HTML?
- Como você cria um PDF a partir de um arquivo HTML?
- Como você cria um PDF a partir de uma URL?
- Como você cria um PDF a partir de um arquivo ZIP?
- Quais opções avançadas de renderização o IronPDF suporta?
- Como você adiciona cabeçalhos e rodapés?
- Como você controla o tamanho da página, a orientação e as margens?
- Como você lida com páginas da web dinâmicas?
- Como você gera PDFs a partir de um template HTML?
- Quais são os próximos passos?
Como você começa com o IronPDF for Node.js? {#getting-started}
Comece a usar IronPDF no seu projeto hoje mesmo com um teste gratuito.
Instale a biblioteca IronPDF.
Instale o pacote IronPDF Node.js executando o comando NPM abaixo no projeto Node.js escolhido:
npm e @ironsoftware/ironpdf
Você também pode baixar e instalar o pacote IronPDF manualmente.
Como você instala o motor IronPDF?
IronPDF for Node.js requer um binário do motor IronPDF para funcionar.
@ironsoftware/ironpdf baixa e instala automaticamente o binário apropriado para o seu sistema operacional na primeira execução. A instalação explícita é recomendada em ambientes onde o acesso à internet é restrito ou indisponível.Instale o binário do motor IronPDF instalando o pacote apropriado para o seu sistema operacional.
Como Aplicar uma Chave de Licença?
Por padrão, o IronPDF marca todos os documentos que gera ou modifica com uma marca d'água. Para remover a marca d'água, defina a propriedade licenseKey no objeto global IronPdfGlobalConfig com uma chave de licença válida:
:path=/static-assets/ironpdf-nodejs/content-code-examples/tutorials/html-to-pdf/config.jsimport { IronPdfGlobalConfig } from "@ironsoftware/ironpdf";
// Retrieve the global configuration object
var config = IronPdfGlobalConfig.getConfig();
// Set a valid license key to remove watermarks
config.licenseKey = "{YOUR-LICENSE-KEY-HERE}";
Obtenha uma chave de licença de teste gratuita ou compre uma chave de licença na página de licenciamento.
Os exemplos de código restantes neste tutorial assumem que uma chave de licença foi aplicada em um arquivo config.js separado, que é importado no início de cada script:
:path=/static-assets/ironpdf-nodejs/content-code-examples/tutorials/html-to-pdf/config-import.jsimport { PdfDocument } from "@ironsoftware/ironpdf";
import './config.js'; // Import the configuration script
// ...
 Obtenha uma chave de licença em IronPDF para gerar documentos PDF sem marcas d'água.
Obtenha uma chave de licença em IronPDF para gerar documentos PDF sem marcas d'água.
Como você converte HTML em PDF no Node.js? {#convert-html-to-pdf}
A biblioteca IronPDF Node.js fornece quatro abordagens para criar arquivos PDF a partir de conteúdo HTML:
- A partir de uma string de código HTML
- A partir de um arquivo HTML local
- A partir de uma URL online
- A partir de um arquivo ZIP compactado
Cada abordagem usa a classe PdfDocument como base. Um PdfDocument representa um arquivo PDF produzido a partir de algum conteúdo de origem e impulsiona a maior parte dos recursos principais de criação e edição do IronPDF.
Como você cria um PDF a partir de uma string HTML? {#create-pdf-from-html-string}
PdfDocument.fromHtml gera PDFs a partir de strings de marcação HTML brutas. Essa abordagem oferece a maior flexibilidade dos quatro métodos, pois a string HTML pode ser obtida de praticamente qualquer lugar — arquivos de texto, fluxos de dados, um mecanismo de modelo HTML ou marcação construída dinamicamente.
:path=/static-assets/ironpdf-nodejs/content-code-examples/tutorials/html-to-pdf/html-string-to-pdf.jsimport { PdfDocument } from "@ironsoftware/ironpdf";
import './config.js'; // Import the configuration script
// Create a PDF from an HTML string
const pdf = await PdfDocument.fromHtml("<h1>Hello from IronPDF!</h1>");
// Save the PDF document to the file system
await pdf.saveAs("html-string-to-pdf.pdf");
PdfDocument.fromHtml retorna uma Promessa que resolve para uma instância da classe PdfDocument. Após obter a instância, chame saveAs com um caminho de arquivo de destino para gravar o PDF no disco. O arquivo PDF salvo renderiza o HTML exatamente como um navegador compatível com os padrões o exibiria.
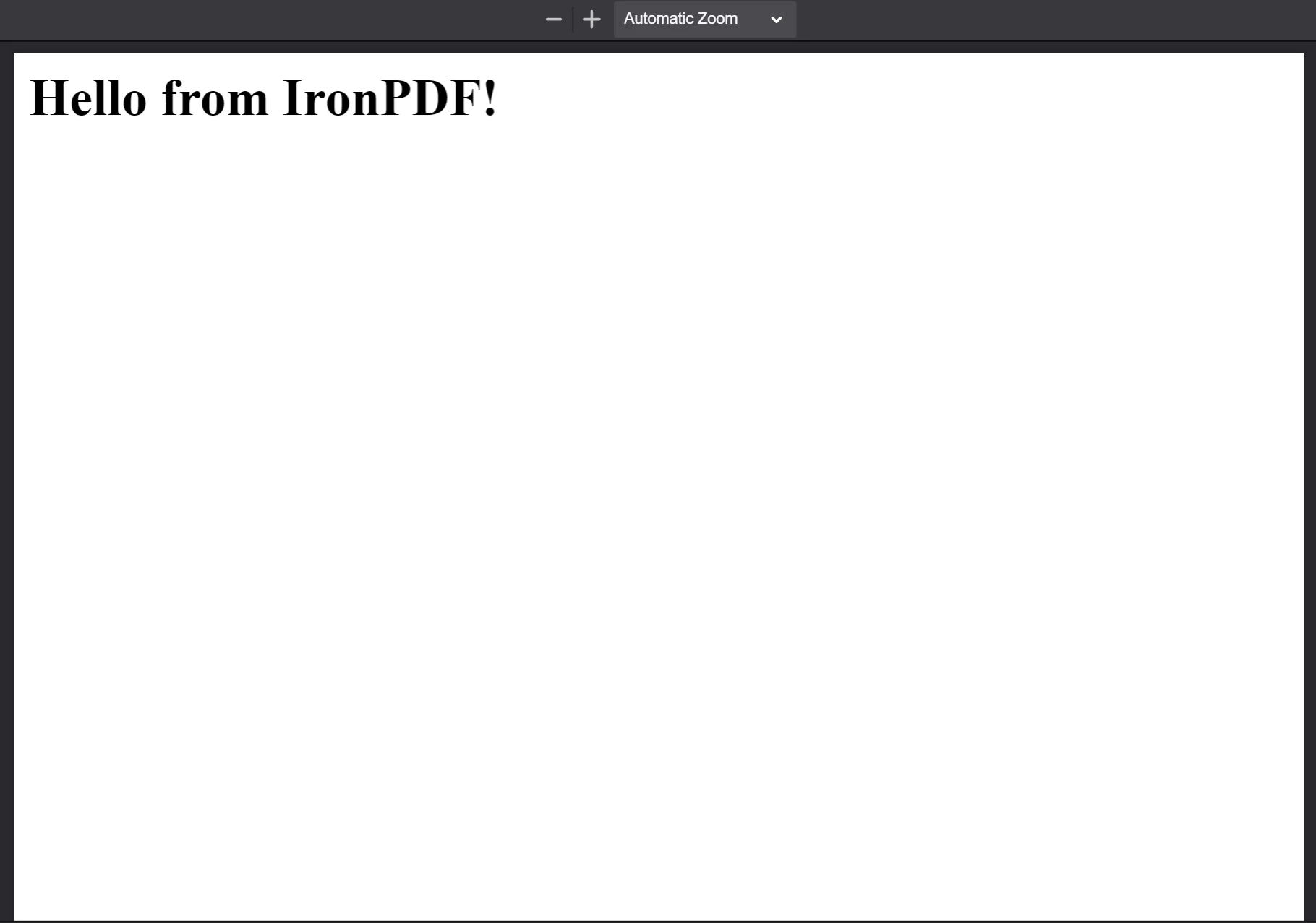 The PDF generated from the HTML string
The PDF generated from the HTML string <h1>Hello from IronPDF!</h1>. Os arquivos PDF que PdfDocument.fromHtml gera aparecem exatamente como o conteúdo da página web apareceria.
Como você cria um PDF a partir de um arquivo HTML? {#create-pdf-from-html-file}
PdfDocument.fromHtml também aceita um caminho para um documento HTML local. Em vez de uma string de marcação, passe um caminho de arquivo válido como o primeiro argumento. Esta é a abordagem preferida ao trabalhar com páginas da web salvas que fazem referência a ativos locais de CSS, JavaScript e imagem.
O exemplo a seguir converte uma página da web de exemplo em um PDF:
:path=/static-assets/ironpdf-nodejs/content-code-examples/tutorials/html-to-pdf/html-file-to-pdf.jsimport { PdfDocument } from "@ironsoftware/ironpdf";
import './config.js'; // Import the configuration script
// Render a PDF from a local HTML file
const pdf = await PdfDocument.fromHtml("./sample2.html");
// Save the PDF document to the project directory
await pdf.saveAs("html-file-to-pdf-1.pdf");
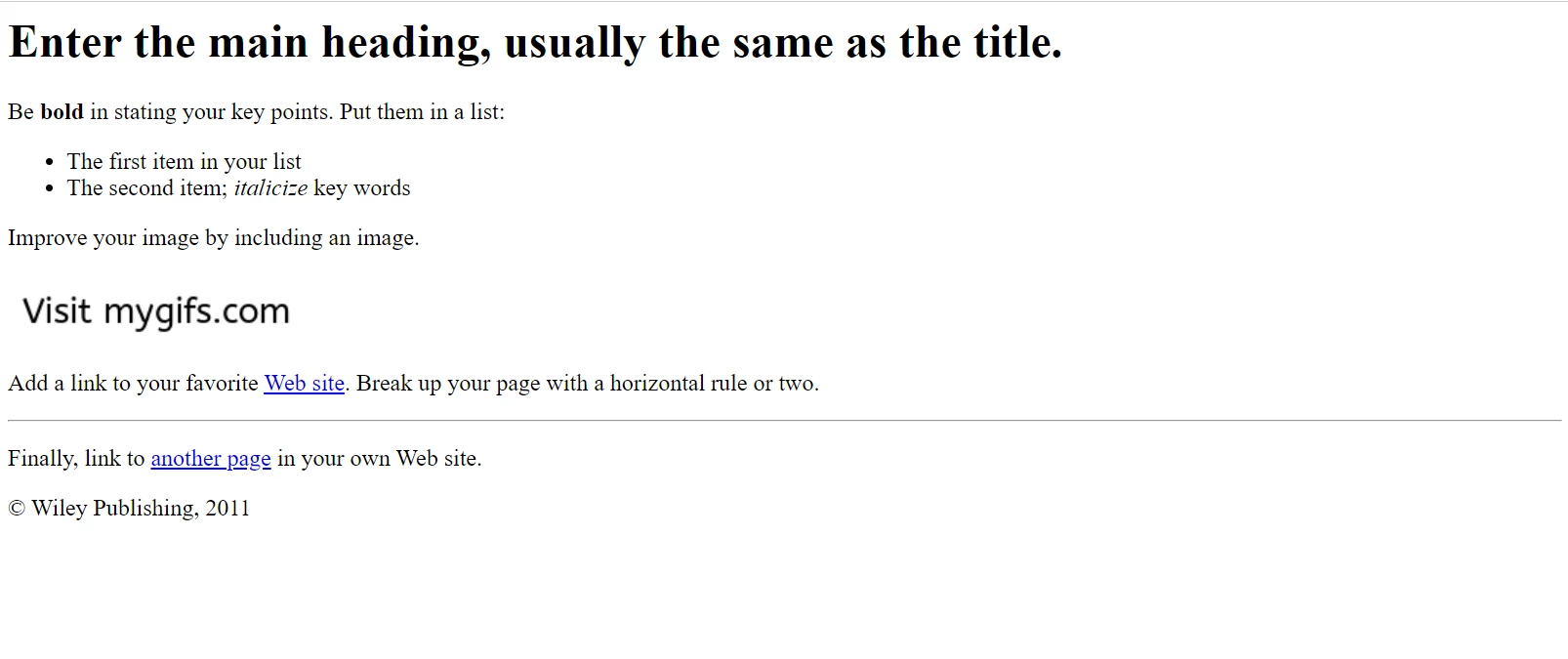 A página HTML de exemplo como aparece no Google Chrome. Baixe esta e outras páginas similares no site File Samples: https://filesamples.com/samples/code/html/sample2.html
A página HTML de exemplo como aparece no Google Chrome. Baixe esta e outras páginas similares no site File Samples: https://filesamples.com/samples/code/html/sample2.html
IronPDF preserva a aparência do documento HTML original e mantém a funcionalidade de links, formulários e outros elementos interativos. Essa fidelidade se estende a páginas complexas que incluem parágrafos, listas, imagens, hyperlinks e scripts no lado do cliente.
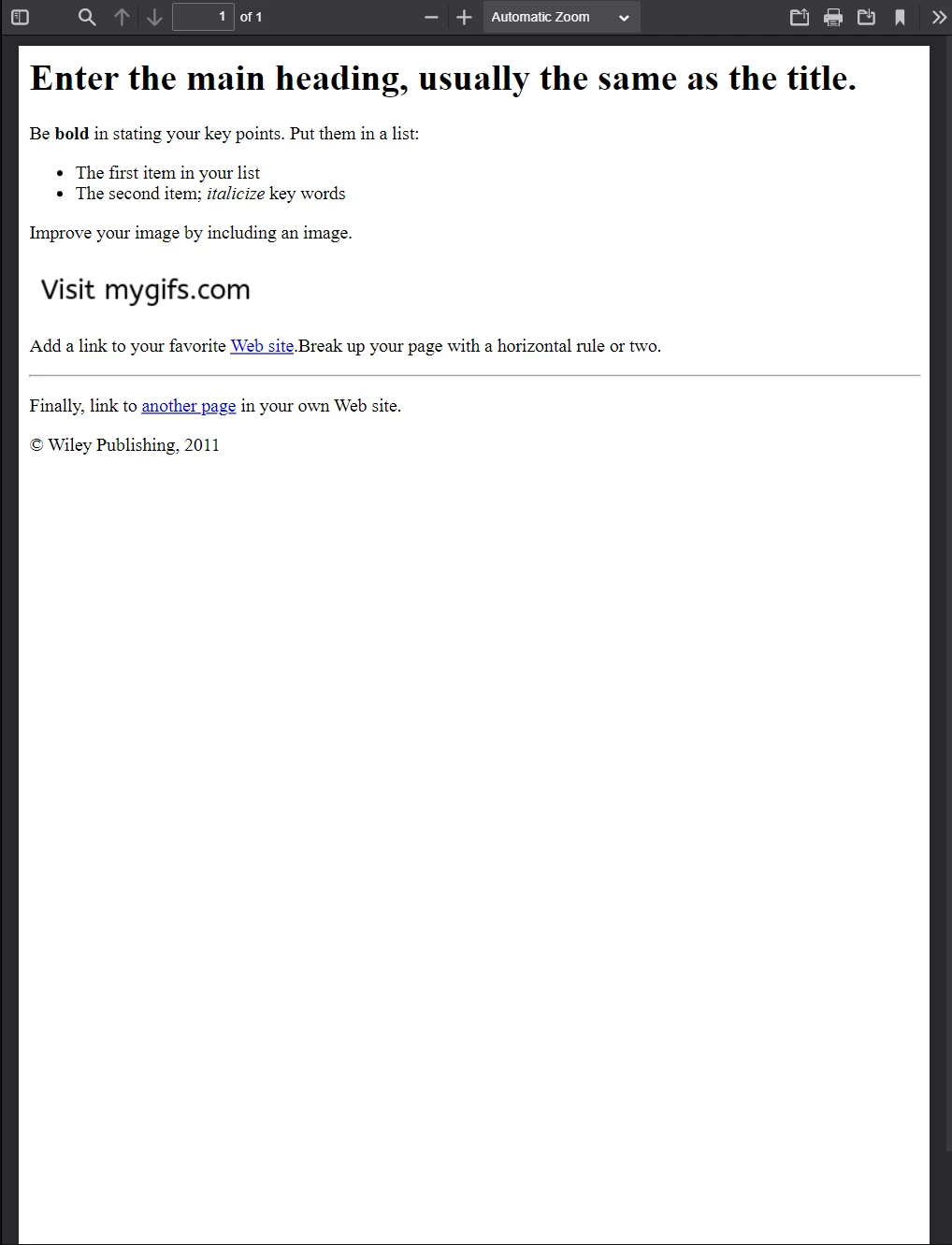 Este PDF foi gerado a partir do exemplo de arquivo HTML acima. Compare sua aparência com a imagem anterior — IronPDF preserva o layout com alta fidelidade.
Este PDF foi gerado a partir do exemplo de arquivo HTML acima. Compare sua aparência com a imagem anterior — IronPDF preserva o layout com alta fidelidade.
IronPDF lida com páginas que vão muito além da marcação simples. O exemplo a seguir converte uma página rica em recursos que obtém numerosos arquivos CSS externos, imagens e ativos de script:
:path=/static-assets/ironpdf-nodejs/content-code-examples/tutorials/html-to-pdf/html-complex-file-to-pdf.jsimport { PdfDocument } from "@ironsoftware/ironpdf";
import './config.js'; // Import the configuration script
// Render a PDF from a complex HTML page with external assets
PdfDocument.fromHtml("./sample4.html").then(async (pdf) => {
return await pdf.saveAs("html-file-to-pdf-2.pdf");
});
 Se parecer bom no Google Chrome, parecerá bom quando convertido para PDF. Isso inclui designs de página fortemente baseados em CSS e renderizados por JavaScript.
Se parecer bom no Google Chrome, parecerá bom quando convertido para PDF. Isso inclui designs de página fortemente baseados em CSS e renderizados por JavaScript.
Como você cria um PDF a partir de uma URL? {#create-pdf-from-url}
PdfDocument.fromUrl busca e renderiza uma página da web ao vivo como um PDF. Passe qualquer URL publicamente acessível como argumento. O mecanismo de renderização Chrome do IronPDF recupera a página, carrega todos os recursos e produz um PDF perfeito — sem necessidade de download manual do HTML.
:path=/static-assets/ironpdf-nodejs/content-code-examples/tutorials/html-to-pdf/url-to-pdf.jsimport { PdfDocument } from "@ironsoftware/ironpdf";
import './config.js'; // Import the configuration script
// Convert a live web page to a PDF
const pdf = await PdfDocument.fromUrl("https://en.wikipedia.org/wiki/PDF");
// Save the document
await pdf.saveAs("url-to-pdf.pdf");
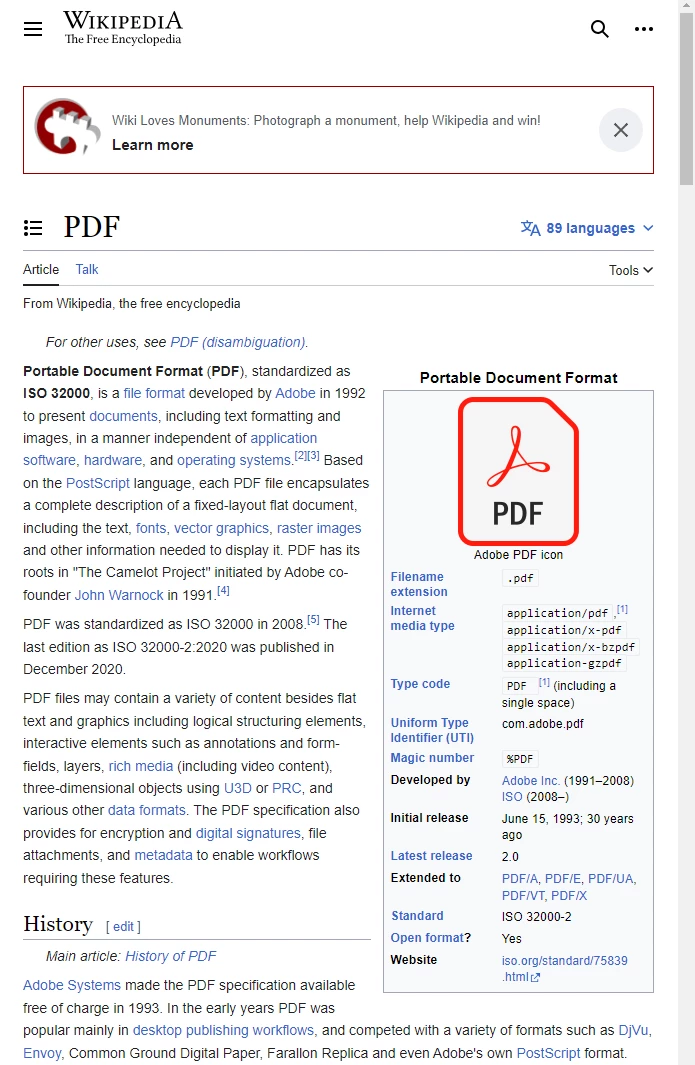 O artigo da Wikipédia sobre o formato PDF, tal como aparece num navegador web compatível com as normas.
O artigo da Wikipédia sobre o formato PDF, tal como aparece num navegador web compatível com as normas.
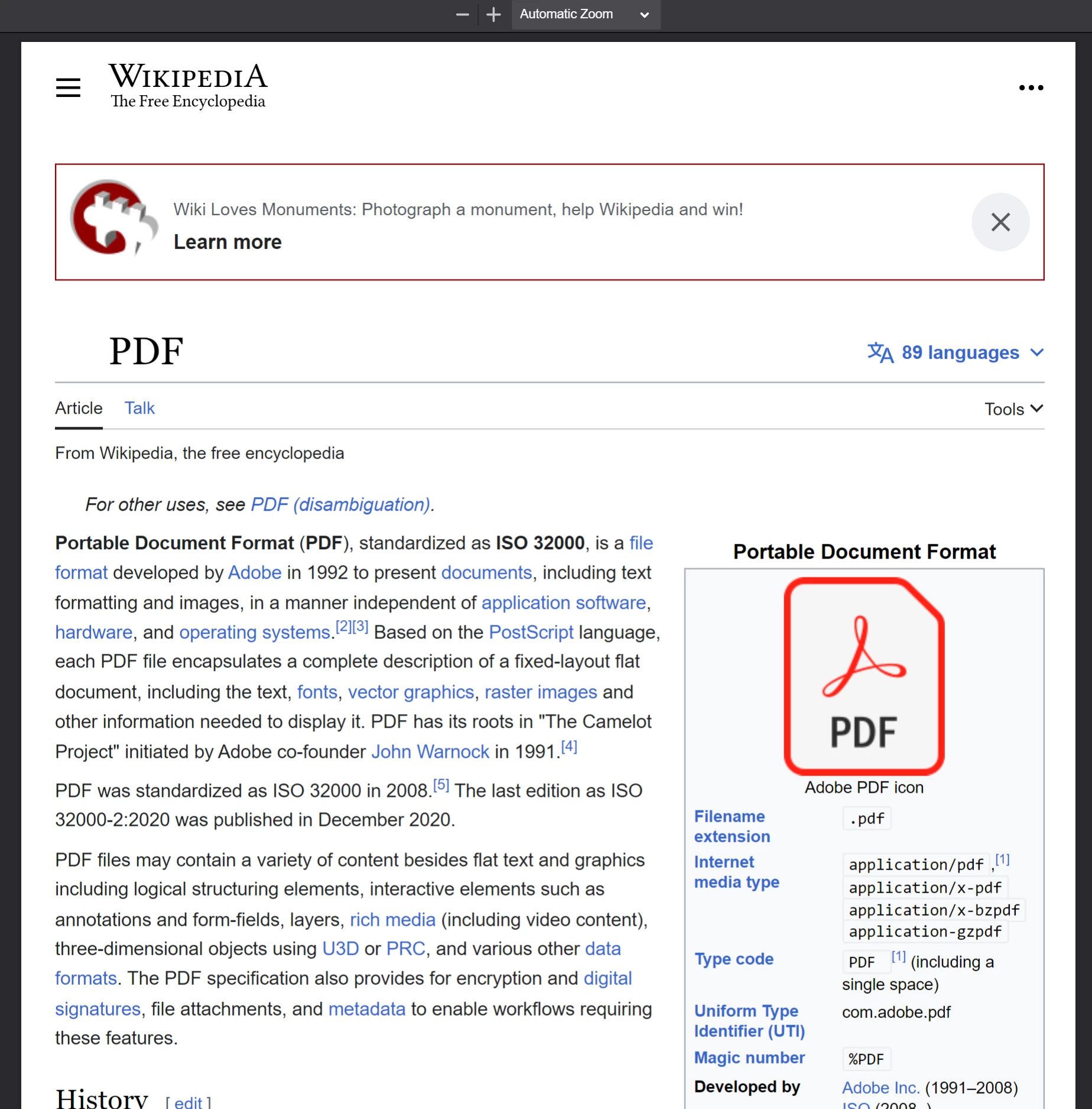 O PDF gerado ao chamar
O PDF gerado ao chamar PdfDocument.fromUrl em um artigo da Wikipedia. Note sua semelhança próxima com a página da web original.
ChromePdfRenderOptions.Como você cria um PDF a partir de um arquivo ZIP? {#create-pdf-from-zip}
PdfDocument.fromZip converte um arquivo HTML específico contido em um arquivo ZIP em um PDF. Isso é particularmente útil ao distribuir projetos HTML autossuficientes que agrupam seus ativos HTML, CSS e imagem juntos.
Para este exemplo, assuma que o diretório do projeto contém um arquivo ZIP com a seguinte estrutura:
//:path=/static-assets/ironpdf-nodejs/content-code-examples/tutorials/html-to-pdf/zip-structure.txt
html-zip.zip
├─ index.html
├─ style.css
├─ logo.pngO arquivo index.html contém:
//:path=/static-assets/ironpdf-nodejs/content-code-examples/tutorials/html-to-pdf/index.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>Hello world!</title>
<link rel="stylesheet" href="style.css">
</head>
<body>
<h1>Hello from IronPDF!</h1>
<a href="https://ironpdf.com/nodejs/">
<img src="logo.png" alt="IronPDF para Node.js">
</a>
</body>
</html>//:path=/static-assets/ironpdf-nodejs/content-code-examples/tutorials/html-to-pdf/index.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>Hello world!</title>
<link rel="stylesheet" href="style.css">
</head>
<body>
<h1>Hello from IronPDF!</h1>
<a href="https://ironpdf.com/nodejs/">
<img src="logo.png" alt="IronPDF para Node.js">
</a>
</body>
</html>E style.css declara as regras de layout da página e fonte:
//:path=/static-assets/ironpdf-nodejs/content-code-examples/tutorials/html-to-pdf/style.css
@font-face {
font-family: 'Gotham-Black';
src: url('gotham-black-webfont.eot?') format('embedded-opentype'),
url('gotham-black-webfont.woff2') format('woff2'),
url('gotham-black-webfont.woff') format('woff'),
url('gotham-black-webfont.ttf') format('truetype'),
url('gotham-black-webfont.svg') format('svg');
font-weight: normal;
font-style: normal;
font-display: swap;
}
body {
display: flex;
flex-direction: column;
justify-content: center;
margin-left: auto;
margin-right: auto;
margin-top: 200px;
margin-bottom: auto;
color: white;
background-color: black;
text-align: center;
font-family: "Helvetica"
}
h1 {
font-family: "Gotham-Black";
margin-bottom: 70px;
font-size: 32pt;
}
img {
width: 400px;
height: auto;
}
p {
text-decoration: underline;
font-size: smaller;
} A imagem de exemplo dentro do arquivo ZIP HTML hipotético.
A imagem de exemplo dentro do arquivo ZIP HTML hipotético.
Ao chamar fromZip, especifique o caminho para o arquivo ZIP como o primeiro argumento e um objeto de configuração como o segundo. Defina a propriedade mainHtmlFile para o nome do arquivo HTML dentro do arquivo que deve ser convertido:
:path=/static-assets/ironpdf-nodejs/content-code-examples/tutorials/html-to-pdf/zip-to-pdf.jsimport { PdfDocument } from "@ironsoftware/ironpdf";
import './config.js'; // Import the configuration script
// Convert an HTML file from a ZIP archive to PDF
PdfDocument.fromZip("./html-zip.zip", {
mainHtmlFile: "index.html"
}).then(async (pdf) => {
return await pdf.saveAs("html-zip-to-pdf.pdf");
});
 Criação de PDF usando
Criação de PDF usando PdfDocument.fromZip. A função renderiza com sucesso o código HTML do arquivo ZIP juntamente com seus ativos agrupados.
Minha biblioteca favorita desse tipo é o IronPDF. Ele permite a manipulação rápida e eficiente de arquivos PDF. Além disso, possui muitos recursos valiosos, como a exportação para o formato PDF/A e a assinatura digital de documentos PDF.
Com o IronOCR, podemos economizar US$ 40.000 por ano em processamento manual, ao mesmo tempo que aumentamos a produtividade e liberamos recursos para tarefas de alto impacto. Eu o recomendo fortemente.
O IronSuite desempenha um papel crucial nas nossas operações. Estas são ferramentas que aumentam a eficiência no negócio, incluindo a criação de plantas baixas e melhoria na gestão de inventário.
Quais opções avançadas de renderização o IronPDF suporta? {#advanced-rendering-options}
A interface ChromePdfRenderOptions expõe propriedades para personalização granular do comportamento de renderização do PDF. Essas configurações se aplicam antes que o PDF seja gerado e abrangem layout, aparência visual e casos de borda para conteúdo dinâmico.
IronPDF aplica configurações de renderização padrão a cada conversão. Recupere esses valores padrão com a função defaultChromePdfRenderOptions:
:path=/static-assets/ironpdf-nodejs/content-code-examples/tutorials/html-to-pdf/default-options.jsimport { defaultChromePdfRenderOptions } from "@ironsoftware/ironpdf";
// Retrieve a ChromePdfRenderOptions object with default settings
var options = defaultChromePdfRenderOptions();
Modifique as propriedades do objeto retornado conforme necessário e passe-o para o parâmetro renderOptions de qualquer método de conversão.
Como adicionar cabeçalhos e rodapés? {#add-headers-footers}
As propriedades textHeader e textFooter afixam conteúdo baseado em texto personalizado em todas as páginas de um PDF recém-renderizado. O seguinte exemplo cria um PDF da página inicial do Google com um cabeçalho e rodapé personalizados, cada um usando uma fonte diferente:
:path=/static-assets/ironpdf-nodejs/content-code-examples/tutorials/html-to-pdf/custom-headers-footers.jsimport { PdfDocument, defaultChromePdfRenderOptions, AffixFonts } from "@ironsoftware/ironpdf";
import './config.js'; // Import the configuration script
// Start from default render options
var options = defaultChromePdfRenderOptions();
// Configure a text-based header
options.textHeader = {
centerText: "https://www.adobe.com",
dividerLine: true,
font: AffixFonts.CourierNew,
fontSize: 12,
leftText: "URL to PDF"
};
// Configure a text-based footer
options.textFooter = {
centerText: "IronPDF for Node.js",
dividerLine: true,
fontSize: 14,
font: AffixFonts.Helvetica,
rightText: "HTML to PDF in Node.js"
};
// Render the page with custom headers and footers applied
PdfDocument.fromUrl("https://www.google.com/", { renderOptions: options }).then(async (pdf) => {
return await pdf.saveAs("add-custom-headers-footers-1.pdf");
});
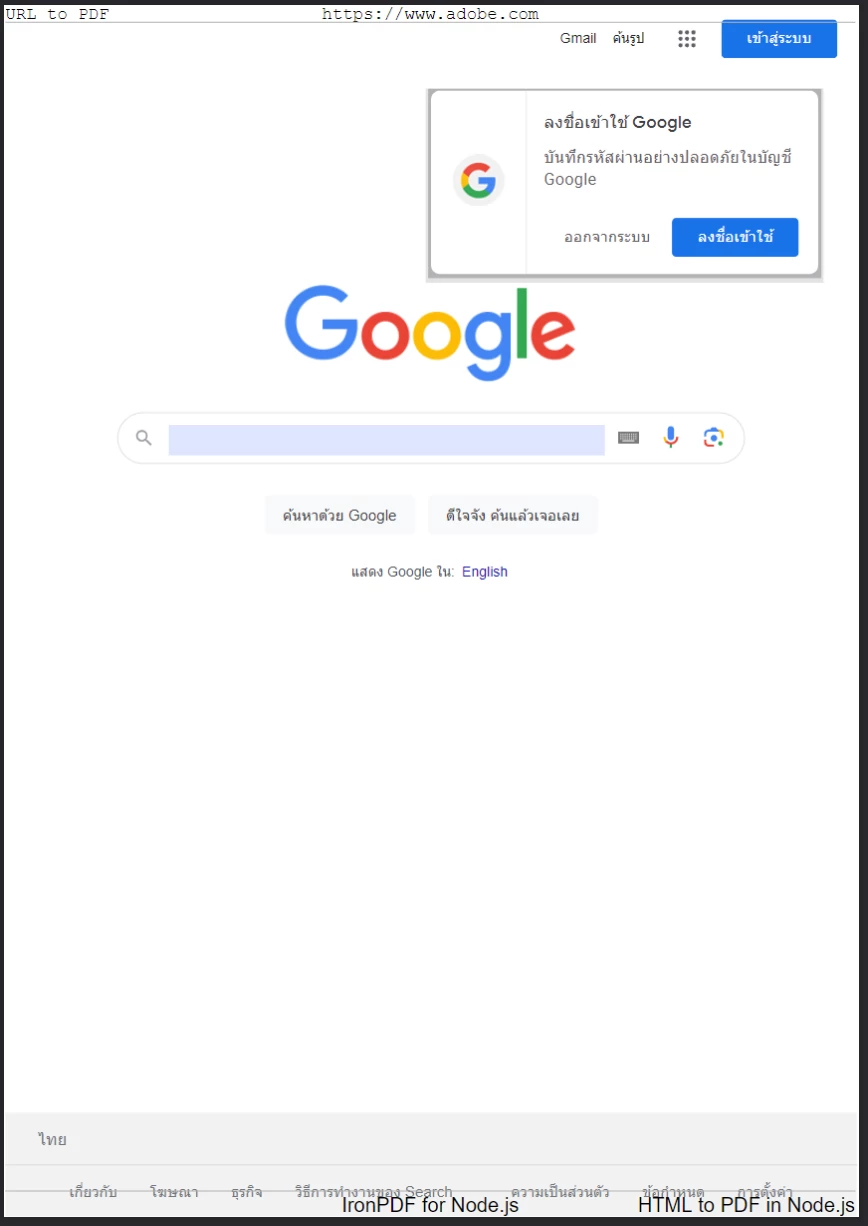 Um PDF gerado a partir da página inicial do Google com um cabeçalho de texto personalizado e rodapé aplicados usando
Um PDF gerado a partir da página inicial do Google com um cabeçalho de texto personalizado e rodapé aplicados usando textHeader e textFooter.
Para layouts de cabeçalho e rodapés mais ricos, use as propriedades htmlHeader e htmlFooter em vez disso. Essas aceitam fragmentos de HTML bruto, dando total controle sobre tipografia, imagens e alinhamento. O exemplo abaixo centraliza a URL da página em negrito no cabeçalho e insere uma imagem de logotipo no rodapé:
:path=/static-assets/ironpdf-nodejs/content-code-examples/tutorials/html-to-pdf/html-headers-footers.jsimport { PdfDocument, defaultChromePdfRenderOptions } from "@ironsoftware/ironpdf";
import './config.js'; // Import the configuration script
// Start from default render options
var options = defaultChromePdfRenderOptions();
// Define a rich HTML header
options.htmlHeader = {
htmlFragment: "<strong>https://www.google.com/</strong>",
dividerLine: true,
dividerLineColor: "blue",
loadStylesAndCSSFromMainHtmlDocument: true,
};
// Define a rich HTML footer with a logo
options.htmlFooter = {
htmlFragment: "<img src='logo.png' alt='IronPDF for Node.js' style='display: block; width: 150px; height: auto; margin-left: auto; margin-right: auto;'>",
dividerLine: true,
loadStylesAndCSSFromMainHtmlDocument: true
};
// Apply custom HTML headers and footers during rendering
await PdfDocument.fromUrl("https://www.google.com/", { renderOptions: options }).then(async (pdf) => {
return await pdf.saveAs("add-html-headers-footers.pdf");
});
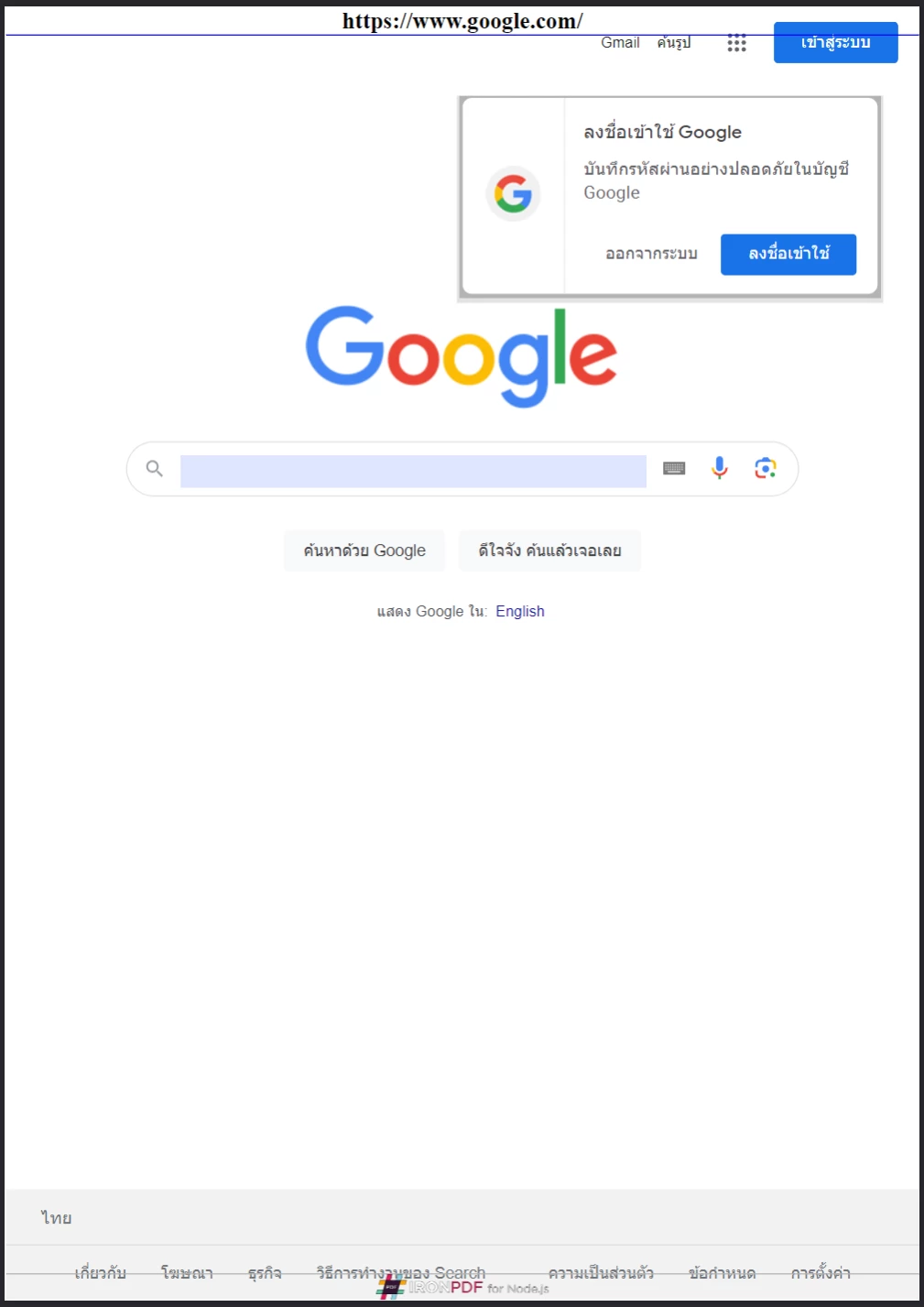 IronPDF suporta cabeçalhos e rodapés baseados em HTML, dando total controle sobre branding e layout em cada página.
IronPDF suporta cabeçalhos e rodapés baseados em HTML, dando total controle sobre branding e layout em cada página.
Como você controla o tamanho da página, a orientação e as margens? {#page-size-orientation-margins}
As propriedades margin, paperSize, fitToPaperMode, paperOrientation e grayScale em ChromePdfRenderOptions controlam o layout físico de cada página renderizada. O exemplo a seguir converte a página inicial do Google com margens personalizadas, orientação paisagem A5 e saída em escala de cinza:
:path=/static-assets/ironpdf-nodejs/content-code-examples/tutorials/html-to-pdf/page-size-orientation.jsimport { PdfDocument, defaultChromePdfRenderOptions, PaperSize, FitToPaperModes, PdfPaperOrientation } from "@ironsoftware/ironpdf";
import './config.js'; // Import the configuration script
// Start from default render options
var options = defaultChromePdfRenderOptions();
// Set page margins in millimeters
options.margin = {
top: 50,
bottom: 50,
left: 60,
right: 60
};
// Configure paper size, fit mode, orientation, and color mode
options.paperSize = PaperSize.A5;
options.fitToPaperMode = FitToPaperModes.FitToPage;
options.paperOrientation = PdfPaperOrientation.Landscape;
options.grayScale = true;
// Render with the customized layout settings
PdfDocument.fromUrl("https://www.google.com/", { renderOptions: options }).then(async (pdf) => {
return await pdf.saveAs("set-margins-and-page-size.pdf");
});
A enumeração PaperSize inclui tamanhos de papel padrão, como A4, A5, Letter e Legal. A enumeração PdfPaperOrientation suporta Portrait e Landscape. Essas configurações dão controle preciso sobre as dimensões de saída para documentos prontos para impressão.
Como você lida com páginas da web dinâmicas? {#dynamic-web-pages}
Páginas que carregam conteúdo de forma assíncrona — através de timers do JavaScript, lazy loading ou chamadas de API — podem não estar totalmente renderizadas no momento em que o mecanismo do IronPDF as captura. O mecanismo WaitFor, configurado através da propriedade waitFor em ChromePdfRenderOptions, instrui o renderizador do Chrome a pausar até que as condições especificadas sejam atendidas antes de capturar a página.
O bloco de código a seguir define o IronPDF para aguardar 20 segundos antes de capturar o conteúdo da página:
:path=/static-assets/ironpdf-nodejs/content-code-examples/tutorials/html-to-pdf/waitfor-delay.jsimport { PdfDocument, defaultChromePdfRenderOptions, WaitForType } from "@ironsoftware/ironpdf";
import './config.js'; // Import the configuration script
// Configure the renderer to wait 20 seconds before capturing
var options = defaultChromePdfRenderOptions();
options.waitFor = {
type: WaitForType.RenderDelay,
delay: 20000
};
PdfDocument.fromUrl("https://ironpdf.com/nodejs/", { renderOptions: options }).then(async (pdf) => {
return await pdf.saveAs("waitfor-renderdelay.pdf");
});
Alternativamente, configure o IronPDF para aguardar até que um elemento DOM específico apareça antes de renderizar. Isso é útil para páginas onde o conteúdo é injetado após um framework JavaScript concluir a montagem:
:path=/static-assets/ironpdf-nodejs/content-code-examples/tutorials/html-to-pdf/waitfor-element.jsimport { PdfDocument, defaultChromePdfRenderOptions, WaitForType } from "@ironsoftware/ironpdf";
import './config.js'; // Import the configuration script
// Configure the renderer to wait for a specific DOM element (up to 20 seconds)
var options = defaultChromePdfRenderOptions();
options.waitFor = {
type: WaitForType.HtmlElement,
htmlQueryStr: "div.ProseMirror",
maxWaitTime: 20000,
};
PdfDocument.fromUrl("https://app.surferseo.com/drafts/s/V7VkcdfgFz-dpkldsfHDGFFYf4jjSvvjsdf", { renderOptions: options }).then(async (pdf) => {
return await pdf.saveAs("waitfor-htmlelement.pdf");
});
A estratégia WaitForType.HtmlElement usa um seletor de consulta CSS padrão. O renderizador verifica pela presença do elemento até que maxWaitTime milissegundos se passem ou o elemento seja encontrado — o que ocorrer primeiro.
Como você gera PDFs a partir de um template HTML? {#html-template-to-pdf}
Um padrão comum de automação no mundo real é gerar um lote de PDFs a partir de um template HTML compartilhado, substituindo valores de espaço reservado por dados de um banco de dados, API ou planilha. O método replaceText do IronPDF em PdfDocument lida com isso diretamente.
O modelo de fatura abaixo (adaptado de um modelo de fatura do CodePen acessível publicamente) usa espaços reservados de chaves, como {COMPANY-NAME}, {FULL-NAME} e {INVOICE-NUMBER} para conteúdo substituível:
 Um modelo de invoice de exemplo com etiquetas de espaço reservado. Código JavaScript substituirá cada etiqueta com dados reais antes de o documento ser salvo como PDF.
Um modelo de invoice de exemplo com etiquetas de espaço reservado. Código JavaScript substituirá cada etiqueta com dados reais antes de o documento ser salvo como PDF.
O código a seguir carrega o template, substitui cada espaço reservado com dados de teste e salva o resultado como um PDF:
//:path=/static-assets/ironpdf-nodejs/content-code-examples/tutorials/html-to-pdf/html-template-to-pdf.js
import { PdfDocument } from "@ironsoftware/ironpdf";
import './config.js'; // Import the configuration script
/**
* Loads an HTML template from the file system as a PdfDocument.
*/
async function getTemplateHtml(fileLocation) {
return PdfDocument.fromHtml(fileLocation);
}
/**
* Saves a PdfDocument to the specified file path.
*/
async function generatePdf(pdf, location) {
return pdf.saveAs(location);
}
/**
* Replaces a named placeholder in the PdfDocument with a data value.
*/
async function addTemplateData(pdf, key, value) {
return pdf.replaceText(key, value);
}
// Path to the HTML invoice template
const template = "./sample-invoice.html";
// Load the template, fill in all placeholder values, then save the PDF
getTemplateHtml(template).then(async (doc) => {
await addTemplateData(doc, "{FULL-NAME}", "Lizbeth Presland");
await addTemplateData(doc, "{ADDRESS}", "678 Manitowish Alley, Portland, OG");
await addTemplateData(doc, "{PHONE-NUMBER}", "(763) 894-4345");
await addTemplateData(doc, "{INVOICE-NUMBER}", "787");
await addTemplateData(doc, "{INVOICE-DATE}", "August 28, 2023");
await addTemplateData(doc, "{AMOUNT-DUE}", "13,760.13");
await addTemplateData(doc, "{RECIPIENT}", "Celestyna Farmar");
await addTemplateData(doc, "{COMPANY-NAME}", "BrainBook");
await addTemplateData(doc, "{TOTAL}", "13,760.13");
await addTemplateData(doc, "{AMOUNT-PAID}", "0.00");
await addTemplateData(doc, "{BALANCE-DUE}", "13,760.13");
await addTemplateData(doc, "{ITEM}", "Training Sessions");
await addTemplateData(doc, "{DESCRIPTION}", "60 Minute instruction");
await addTemplateData(doc, "{RATE}", "3,440.03");
await addTemplateData(doc, "{QUANTITY}", "4");
await addTemplateData(doc, "{PRICE}", "13,760.13");
return doc;
}).then(async (doc) => await generatePdf(doc, "html-template-to-pdf.pdf"));//:path=/static-assets/ironpdf-nodejs/content-code-examples/tutorials/html-to-pdf/html-template-to-pdf.js
import { PdfDocument } from "@ironsoftware/ironpdf";
import './config.js'; // Import the configuration script
/**
* Loads an HTML template from the file system as a PdfDocument.
*/
async function getTemplateHtml(fileLocation) {
return PdfDocument.fromHtml(fileLocation);
}
/**
* Saves a PdfDocument to the specified file path.
*/
async function generatePdf(pdf, location) {
return pdf.saveAs(location);
}
/**
* Replaces a named placeholder in the PdfDocument with a data value.
*/
async function addTemplateData(pdf, key, value) {
return pdf.replaceText(key, value);
}
// Path to the HTML invoice template
const template = "./sample-invoice.html";
// Load the template, fill in all placeholder values, then save the PDF
getTemplateHtml(template).then(async (doc) => {
await addTemplateData(doc, "{FULL-NAME}", "Lizbeth Presland");
await addTemplateData(doc, "{ADDRESS}", "678 Manitowish Alley, Portland, OG");
await addTemplateData(doc, "{PHONE-NUMBER}", "(763) 894-4345");
await addTemplateData(doc, "{INVOICE-NUMBER}", "787");
await addTemplateData(doc, "{INVOICE-DATE}", "August 28, 2023");
await addTemplateData(doc, "{AMOUNT-DUE}", "13,760.13");
await addTemplateData(doc, "{RECIPIENT}", "Celestyna Farmar");
await addTemplateData(doc, "{COMPANY-NAME}", "BrainBook");
await addTemplateData(doc, "{TOTAL}", "13,760.13");
await addTemplateData(doc, "{AMOUNT-PAID}", "0.00");
await addTemplateData(doc, "{BALANCE-DUE}", "13,760.13");
await addTemplateData(doc, "{ITEM}", "Training Sessions");
await addTemplateData(doc, "{DESCRIPTION}", "60 Minute instruction");
await addTemplateData(doc, "{RATE}", "3,440.03");
await addTemplateData(doc, "{QUANTITY}", "4");
await addTemplateData(doc, "{PRICE}", "13,760.13");
return doc;
}).then(async (doc) => await generatePdf(doc, "html-template-to-pdf.pdf"));O código acima define três funções auxiliares assíncronas:
getTemplateHtml: Carrega um arquivo HTML em um objetoPdfDocumentusandoPdfDocument.fromHtml.addTemplateData: ChamaPdfDocument.replaceTextpara substituir uma chave de espaço reservado por seu valor de dados real.generatePdf: Grava oPdfDocumentcompleto em um caminho de arquivo de destino.
Cada chamada replaceText opera diretamente na representação do PDF na memória, portanto, várias substituições podem ser encadeadas sem recarregar o documento do disco. O PDF resultante mantém todos os estilos CSS, fontes e layout do modelo original.
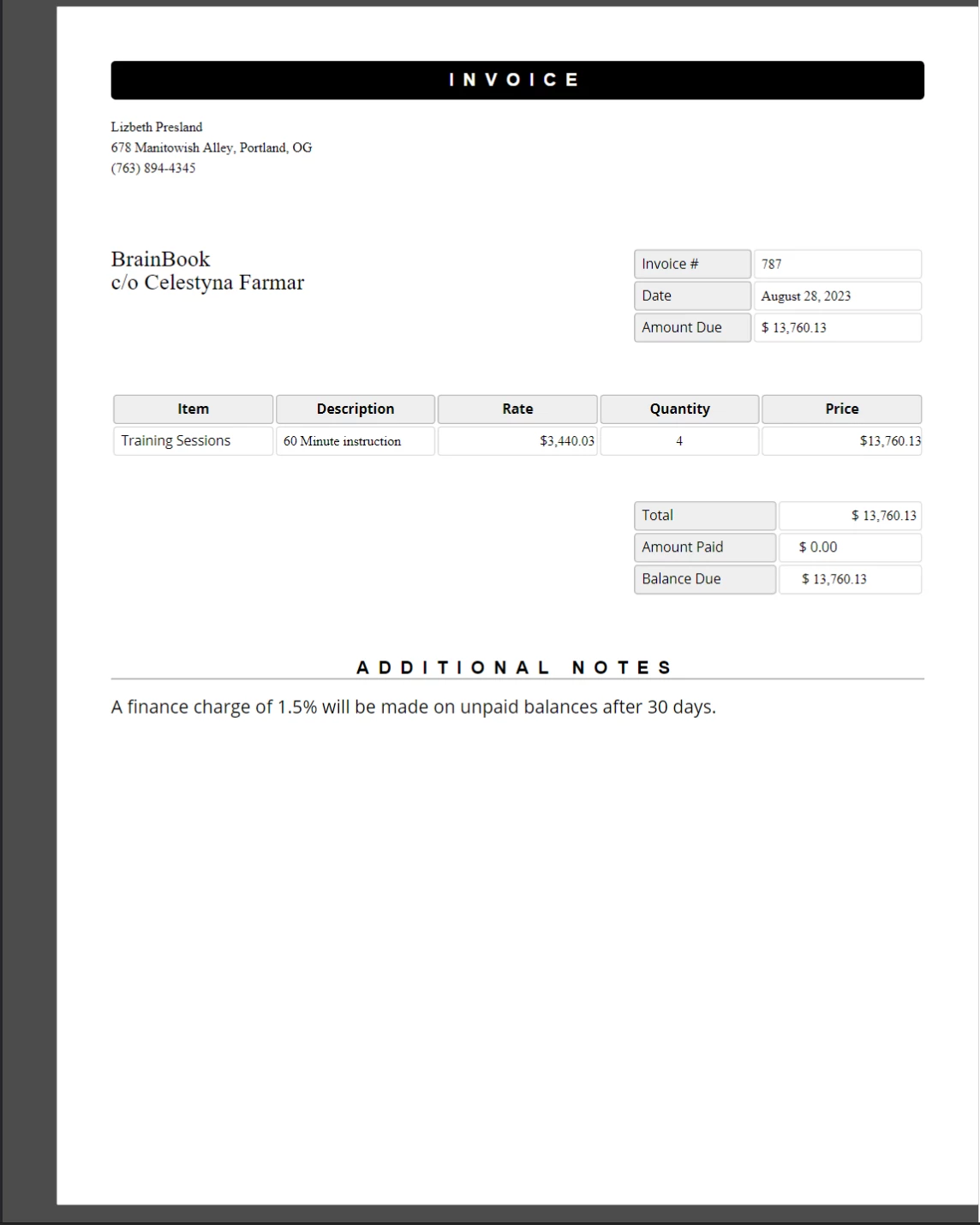 A fatura PDF concluída com valores de espaço reservado substituídos por dados reais. Os estilos CSS e o layout do modelo original são preservados exatamente.
A fatura PDF concluída com valores de espaço reservado substituídos por dados reais. Os estilos CSS e o layout do modelo original são preservados exatamente.
Essa abordagem escala bem para geração em lote de documentos. Chame getTemplateHtml uma vez por registro para criar um novo PdfDocument para cada arquivo de saída, então encadeie as chamadas addTemplateData para os dados desse registro antes de chamar generatePdf.
Quais são os próximos passos? {#next-steps}
Este tutorial cobre os métodos principais de conversão de HTML para PDF e as opções de renderização mais frequentemente usadas no IronPDF for Node.js. Os tópicos abaixo ampliam o que você aprendeu aqui para áreas mais especializadas.
- Editar e Carimbar PDFs no Node.js — Aplique carimbos, anotações e edições de texto a documentos PDF existentes programaticamente.
- Mesclar e Dividir PDFs no Node.js — Combine vários PDFs em um único documento ou divida um PDF em páginas separadas.
- Adicionar Marcas d'água a PDFs no Node.js — Aplique marcas d'água de texto ou imagem em todas as páginas de um PDF com controle de posicionamento preciso.
- Referência de API do IronPDF Node.js — Navegue por toda a API para
PdfDocument,ChromePdfRenderOptions,WaitFor,AffixFontse todas as outras classes e interfaces exportadas. - Obtenha uma Chave de Licença de Avaliação Gratuita — Gere PDFs de qualidade de produção sem marcas d'água ativando uma licença de avaliação gratuita de 30 dias.
Perguntas frequentes
Como você converte HTML para PDF no Node.js?
Use a biblioteca IronPDF. Instale-a com npm install @ironsoftware/ironpdf e, em seguida, chame PdfDocument.fromHtml com uma string HTML ou caminho de arquivo, ou PdfDocument.fromUrl com um endereço da Web. Salve o resultado com PdfDocument.saveAs.
Como você converte uma string HTML em PDF no Node.js?
Chame PdfDocument.fromHtml com a string HTML como argumento. O método retorna uma Promise que resolve em uma instância de PdfDocument. Encadeie saveAs no resultado para gravar o PDF no disco.
Como você converte um arquivo HTML local em PDF no Node.js?
Passe um caminho de sistema de arquivos válido para PdfDocument.fromHtml em vez de uma string HTML. O IronPDF resolve caminhos relativos de CSS, imagem e script da mesma maneira que um navegador ao carregar o arquivo.
Como você converte uma URL em PDF no Node.js?
Chame PdfDocument.fromUrl com a URL de destino. O IronPDF busca a página usando seu motor de renderização Chrome e produz um PDF com precisão de pixels. A URL de destino deve ser publicamente acessível a partir do host que executa o IronPDF.
Como você adiciona cabeçalhos e rodapés a um PDF no Node.js?
Defina as propriedades textHeader e textFooter em um objeto ChromePdfRenderOptions para cabeçalhos e rodapés de texto simples. Para layouts mais ricos, use htmlHeader e htmlFooter com fragmentos HTML brutos. Passe o objeto de opções para o parâmetro renderOptions de qualquer método de conversão.
Como você muda o tamanho e a orientação da página no IronPDF for Node.js?
Defina options.paperSize para um valor do enum PaperSize (como PaperSize.A4 ou PaperSize.Letter) e defina options.paperOrientation para PdfPaperOrientation.Portrait ou PdfPaperOrientation.Landscape. Passe as opções configuradas para o método de conversão.
Como você lida com conteúdo dinâmico de JavaScript ao converter para PDF?
Use a propriedade waitFor em ChromePdfRenderOptions. Defina type para WaitForType.RenderDelay e forneça um atraso em milissegundos, ou defina type para WaitForType.HtmlElement e forneça um seletor de consulta CSS. O IronPDF pausará a renderização até que a condição esteja satisfeita.
Como você converte um arquivo HTML dentro de um arquivo ZIP para PDF?
Chame PdfDocument.fromZip com o caminho para o arquivo ZIP como primeiro argumento e um objeto de opções como segundo. Defina a propriedade mainHtmlFile para o nome do arquivo HTML dentro do arquivo que deve ser convertido.
Como você remove a marca d'água do IronPDF dos PDFs gerados?
Aplique uma chave de licença válida à configuração global antes de chamar qualquer método de conversão. Recupere o objeto de configuração com IronPdfGlobalConfig.getConfig() e defina config.licenseKey com sua chave. Uma licença de avaliação gratuita está disponível em ironpdf.com.
Como você gera PDFs a partir de um template HTML no Node.js?
Carregue o template com PdfDocument.fromHtml, em seguida, chame PdfDocument.replaceText para cada espaço reservado no template, passando a string de espaço reservado e seu valor de substituição. Após todas as substituições serem concluídas, chame saveAs para gravar o PDF final.


Ainda está rolando a tela?
Quer provas rápidas?
executar um exemplo Veja seu HTML se transformar em um PDF.











