


La fonctionnalité la plus puissante et la plus populaire d'IronPDF est la capacité de créer des PDF haute-fidélité à partir de HTML brut, CSS et JavaScript. Ce tutoriel guide les développeurs Node.js à travers chaque méthode pratique pour convertir un contenu HTML en PDF - du simple convertisseur de chaînes à la génération de documents basés sur des modèles dynamiques.
IronPDF est une bibliothèque d'API de haut niveau qui aide les développeurs à implémenter rapidement des capacités puissantes de traitement de PDF dans les applications logicielles. IronPDF est disponible dans plusieurs langages de programmation. Pour une couverture détaillée de la création de PDF en .NET, Java, et Python, consultez les pages de documentation officielles. Ce tutoriel couvre son utilisation telle qu'elle s'applique aux projets Node.js.
Démarrage rapide : Convertir HTML en PDF dans Node.js
Comment convertir HTML en PDF dans Node.js
- Installez la bibliothèque IronPDF Node.js via NPM :
npm install @ironsoftware/ironpdf - Importez la classe PdfDocument du package
@ironsoftware/ironpdf. - Appelez
PdfDocument.fromHtml,PdfDocument.fromUrl, ouPdfDocument.fromZipselon votre source HTML. - Configurez éventuellement les options de rendu : entêtes, pieds de page, taille de page, orientation et marges.
- Appelez
PdfDocument.saveAspour sauvegarder le PDF généré sur le disque.
Table des matières
- Comment commencer avec IronPDF for Node.js ?
- Comment convertir du HTML en PDF dans Node.js ?
- Quelles options de rendu avancées IronPDF supporte-t-il ?
- Comment générer des PDF à partir d'un modèle HTML ?
- Quelles sont les prochaines étapes ?
Comment démarrer avec IronPDF for Node.js ? {#getting-started}
Commencez à utiliser IronPDF dans votre projet aujourd'hui avec un essai gratuit.
Installer la Bibliothèque IronPDF
Installez le package IronPDF Node.js en exécutant la commande NPM ci-dessous dans votre projet Node.js choisi :
//:path=/static-assets/ironpdf-nodejs/content-code-examples/tutorials/html-to-pdf/install.sh
npm install @ironsoftware/ironpdf//:path=/static-assets/ironpdf-nodejs/content-code-examples/tutorials/html-to-pdf/install.sh
npm install @ironsoftware/ironpdfVous pouvez également télécharger et installer le package IronPDF manuellement.
Comment installer le moteur IronPDF ?
IronPDF for Node.js nécessite un fichier binaire IronPDF Engine pour fonctionner.
@ironsoftware/ironpdf télécharge et installe automatiquement le binaire adapté à votre système d'exploitation lors de la première exécution. L'installation explicite est recommandée dans les environnements où l'accès à Internet est restreint ou indisponible.Installez le fichier binaire IronPDF Engine en installant le package approprié pour votre système d'exploitation.
Comment appliquer une clé de licence ?
Par défaut, IronPDF marque tous les documents qu'il génère ou modifie avec un filigrane. Pour supprimer le filigrane, définissez la propriété licenseKey sur l'objet global IronPdfGlobalConfig avec une clé de licence valide :
//:path=/static-assets/ironpdf-nodejs/content-code-examples/tutorials/html-to-pdf/config.js
import { IronPdfGlobalConfig } from "@ironsoftware/ironpdf";
// Retrieve the global configuration object
var config = IronPdfGlobalConfig.getConfig();
// Set a valid license key to remove watermarks
config.licenseKey = "{YOUR-LICENSE-KEY-HERE}";//:path=/static-assets/ironpdf-nodejs/content-code-examples/tutorials/html-to-pdf/config.js
import { IronPdfGlobalConfig } from "@ironsoftware/ironpdf";
// Retrieve the global configuration object
var config = IronPdfGlobalConfig.getConfig();
// Set a valid license key to remove watermarks
config.licenseKey = "{YOUR-LICENSE-KEY-HERE}";Obtenez une clé de licence d'essai gratuite ou achetez une clé de licence depuis la page de licences.
Les exemples de code restants de ce tutoriel partent du principe qu'une clé de licence a été appliquée dans un fichier config.js distinct, qui est importé en haut de chaque script :
//:path=/static-assets/ironpdf-nodejs/content-code-examples/tutorials/html-to-pdf/config-import.js
import { PdfDocument } from "@ironsoftware/ironpdf";
import './config.js'; // Import the configuration script
// ...//:path=/static-assets/ironpdf-nodejs/content-code-examples/tutorials/html-to-pdf/config-import.js
import { PdfDocument } from "@ironsoftware/ironpdf";
import './config.js'; // Import the configuration script
// ... Obtenez une clé de licence sur ironpdf.com/nodejs/licensing/ pour générer des documents PDF sans filigranes.
Obtenez une clé de licence sur ironpdf.com/nodejs/licensing/ pour générer des documents PDF sans filigranes.
Comment convertir du HTML en PDF dans Node.js ? {#convert-html-to-PDF}
La bibliothèque IronPDF Node.js propose quatre approches pour créer des fichiers PDF à partir de contenu HTML :
- À partir d'une chaîne de code HTML
- À partir d'un fichier HTML local
- À partir d'une URL en ligne
- À partir d'une archive ZIP compressée
Chaque approche utilise la classe PdfDocument comme base. Un PdfDocument représente un fichier PDF généré à partir d'un contenu source et pilote la plupart des fonctionnalités de création et d'édition principales d'IronPdf.
Comment créer un PDF à partir d'une chaîne HTML ? {#create-PDF-from-html-string}
PdfDocument.fromHtml génère des fichiers PDF à partir de chaînes de balisage HTML brut. Cette approche offre la plus grande flexibilité des quatre méthodes, car la chaîne HTML peut provenir de pratiquement n'importe où : fichiers texte, flux de données, moteur de modèles HTML ou balisage construit dynamiquement.
//:path=/static-assets/ironpdf-nodejs/content-code-examples/tutorials/html-to-pdf/html-string-to-pdf.js
import { PdfDocument } from "@ironsoftware/ironpdf";
import './config.js'; // Import the configuration script
// Create a PDF from an HTML string
const pdf = await PdfDocument.fromHtml("<h1>Hello from IronPDF!</h1>");
// Save the PDF document to the file system
await pdf.saveAs("html-string-to-pdf.pdf");//:path=/static-assets/ironpdf-nodejs/content-code-examples/tutorials/html-to-pdf/html-string-to-pdf.js
import { PdfDocument } from "@ironsoftware/ironpdf";
import './config.js'; // Import the configuration script
// Create a PDF from an HTML string
const pdf = await PdfDocument.fromHtml("<h1>Hello from IronPDF!</h1>");
// Save the PDF document to the file system
await pdf.saveAs("html-string-to-pdf.pdf");PdfDocument.fromHtml renvoie une Promise qui se résout en une instance de la classe PdfDocument. Après avoir obtenu l'instance, appelez saveAs avec un chemin d'accès au fichier de destination pour écrire le PDF sur le disque. Le fichier PDF enregistré rend le HTML exactement comme un navigateur conforme aux standards l'afficherait.
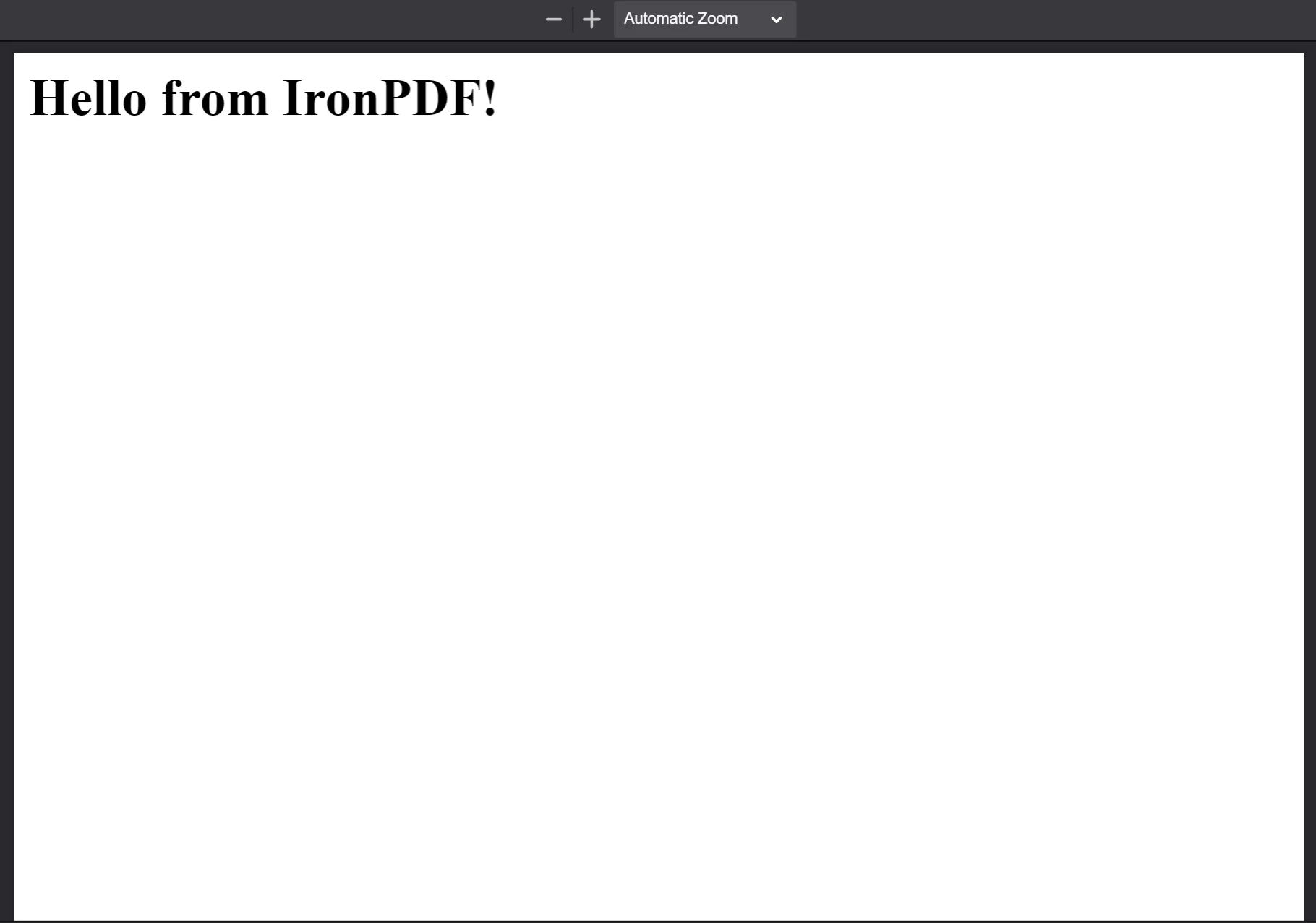 The PDF generated from the HTML string
The PDF generated from the HTML string <h1>Hello from IronPDF!</h1>. Les fichiers PDF générés par PdfDocument.fromHtml s'affichent exactement comme le ferait le contenu d'une page web.
Comment créer un PDF à partir d'un fichier HTML ? {#create-pdf-from-html-file}
PdfDocument.fromHtml accepte également un chemin d'accès à un document HTML local. Au lieu d'une chaîne de balisage, passez un chemin de fichier valide en tant que premier argument. C'est l'approche préférée lors de l'utilisation de pages Web enregistrées qui référencent des CSS, JavaScript, et des ressources d'image locales.
L'exemple suivant convertit une page Web échantillon en PDF :
//:path=/static-assets/ironpdf-nodejs/content-code-examples/tutorials/html-to-pdf/html-file-to-pdf.js
import { PdfDocument } from "@ironsoftware/ironpdf";
import './config.js'; // Import the configuration script
// Render a PDF from a local HTML file
const pdf = await PdfDocument.fromHtml("./sample2.html");
// Save the PDF document to the project directory
await pdf.saveAs("html-file-to-pdf-1.pdf");//:path=/static-assets/ironpdf-nodejs/content-code-examples/tutorials/html-to-pdf/html-file-to-pdf.js
import { PdfDocument } from "@ironsoftware/ironpdf";
import './config.js'; // Import the configuration script
// Render a PDF from a local HTML file
const pdf = await PdfDocument.fromHtml("./sample2.html");
// Save the PDF document to the project directory
await pdf.saveAs("html-file-to-pdf-1.pdf");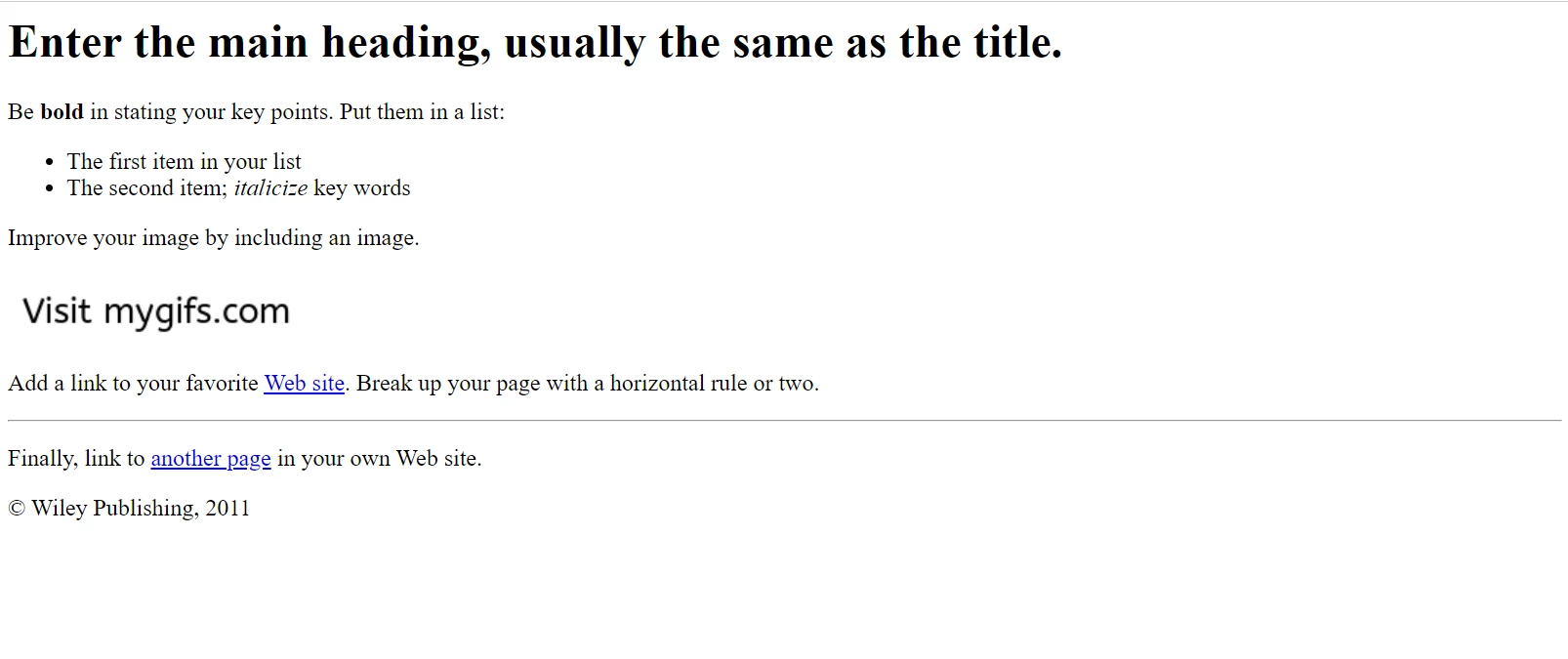 La page HTML échantillon telle qu'elle apparaît dans Google Chrome. Téléchargez cette page et des pages similaires depuis le site File Samples : https://filesamples.com/samples/code/html/sample2.html
La page HTML échantillon telle qu'elle apparaît dans Google Chrome. Téléchargez cette page et des pages similaires depuis le site File Samples : https://filesamples.com/samples/code/html/sample2.html
IronPDF préserve l'apparence du document HTML original et conserve la fonctionnalité des liens, des formulaires, et d'autres éléments interactifs. Cette fidélité s'étend aux pages complexes qui incluent des paragraphes, des listes, des images, des hyperliens, et du script côté client.
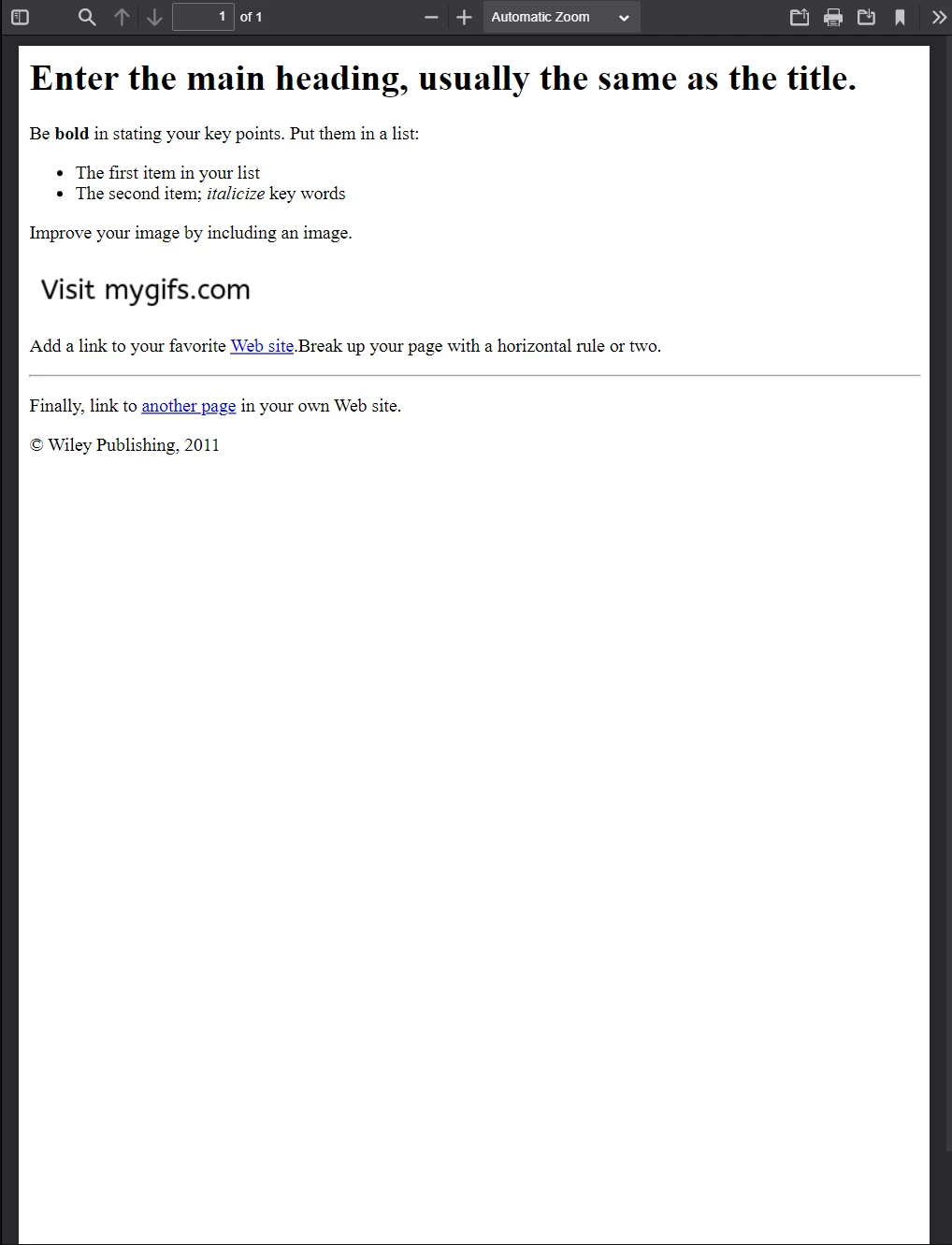 Ce PDF a été généré à partir de l'exemple de fichier HTML ci-dessus. Comparez son apparence avec l'image précédente - IronPDF préserve la mise en page avec une grande fidélité.
Ce PDF a été généré à partir de l'exemple de fichier HTML ci-dessus. Comparez son apparence avec l'image précédente - IronPDF préserve la mise en page avec une grande fidélité.
IronPDF gère des pages qui vont bien au-delà du simple balisage. L'exemple suivant convertit une page riche en fonctionnalités qui source de nombreux fichiers CSS externes, images, et ressources de script :
//:path=/static-assets/ironpdf-nodejs/content-code-examples/tutorials/html-to-pdf/html-complex-file-to-pdf.js
import { PdfDocument } from "@ironsoftware/ironpdf";
import './config.js'; // Import the configuration script
// Render a PDF from a complex HTML page with external assets
PdfDocument.fromHtml("./sample4.html").then(async (pdf) => {
return await pdf.saveAs("html-file-to-pdf-2.pdf");
});//:path=/static-assets/ironpdf-nodejs/content-code-examples/tutorials/html-to-pdf/html-complex-file-to-pdf.js
import { PdfDocument } from "@ironsoftware/ironpdf";
import './config.js'; // Import the configuration script
// Render a PDF from a complex HTML page with external assets
PdfDocument.fromHtml("./sample4.html").then(async (pdf) => {
return await pdf.saveAs("html-file-to-pdf-2.pdf");
}); Si cela a l'air bien dans Google Chrome, cela aura l'air bien une fois converti en PDF. Cela inclut les conceptions de page riches en CSS et rendues par JavaScript.
Si cela a l'air bien dans Google Chrome, cela aura l'air bien une fois converti en PDF. Cela inclut les conceptions de page riches en CSS et rendues par JavaScript.
Comment créer un PDF à partir d'une URL ? {#create-PDF-from-url}
PdfDocument.fromUrl récupère et affiche une page web en direct au format PDF. Passez n'importe quelle URL accessible au public en tant qu'argument. Le moteur de rendu Chrome d'IronPDF récupère la page, charge tous les actifs, et produit un PDF parfait au pixel près - aucun téléchargement manuel de HTML requis.
//:path=/static-assets/ironpdf-nodejs/content-code-examples/tutorials/html-to-pdf/url-to-pdf.js
import { PdfDocument } from "@ironsoftware/ironpdf";
import './config.js'; // Import the configuration script
// Convert a live web page to a PDF
const pdf = await PdfDocument.fromUrl("https://en.wikipedia.org/wiki/PDF");
// Save the document
await pdf.saveAs("url-to-pdf.pdf");//:path=/static-assets/ironpdf-nodejs/content-code-examples/tutorials/html-to-pdf/url-to-pdf.js
import { PdfDocument } from "@ironsoftware/ironpdf";
import './config.js'; // Import the configuration script
// Convert a live web page to a PDF
const pdf = await PdfDocument.fromUrl("https://en.wikipedia.org/wiki/PDF");
// Save the document
await pdf.saveAs("url-to-pdf.pdf");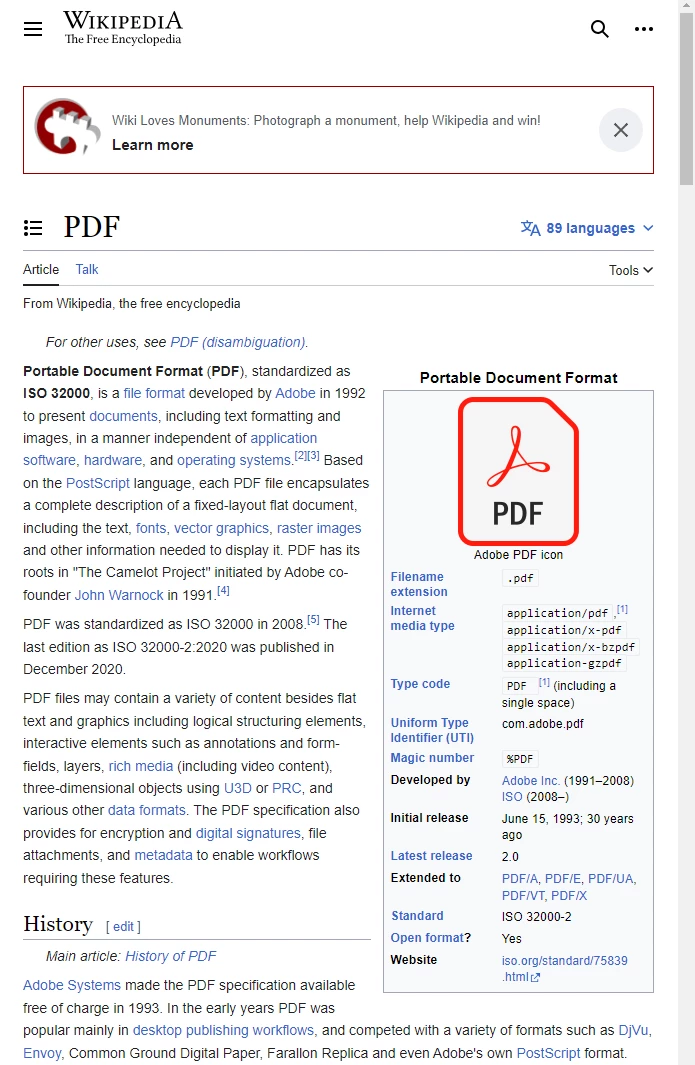 L'article Wikipedia sur le format PDF, tel qu'il apparaît dans un navigateur web conforme aux standards.
L'article Wikipedia sur le format PDF, tel qu'il apparaît dans un navigateur web conforme aux standards.
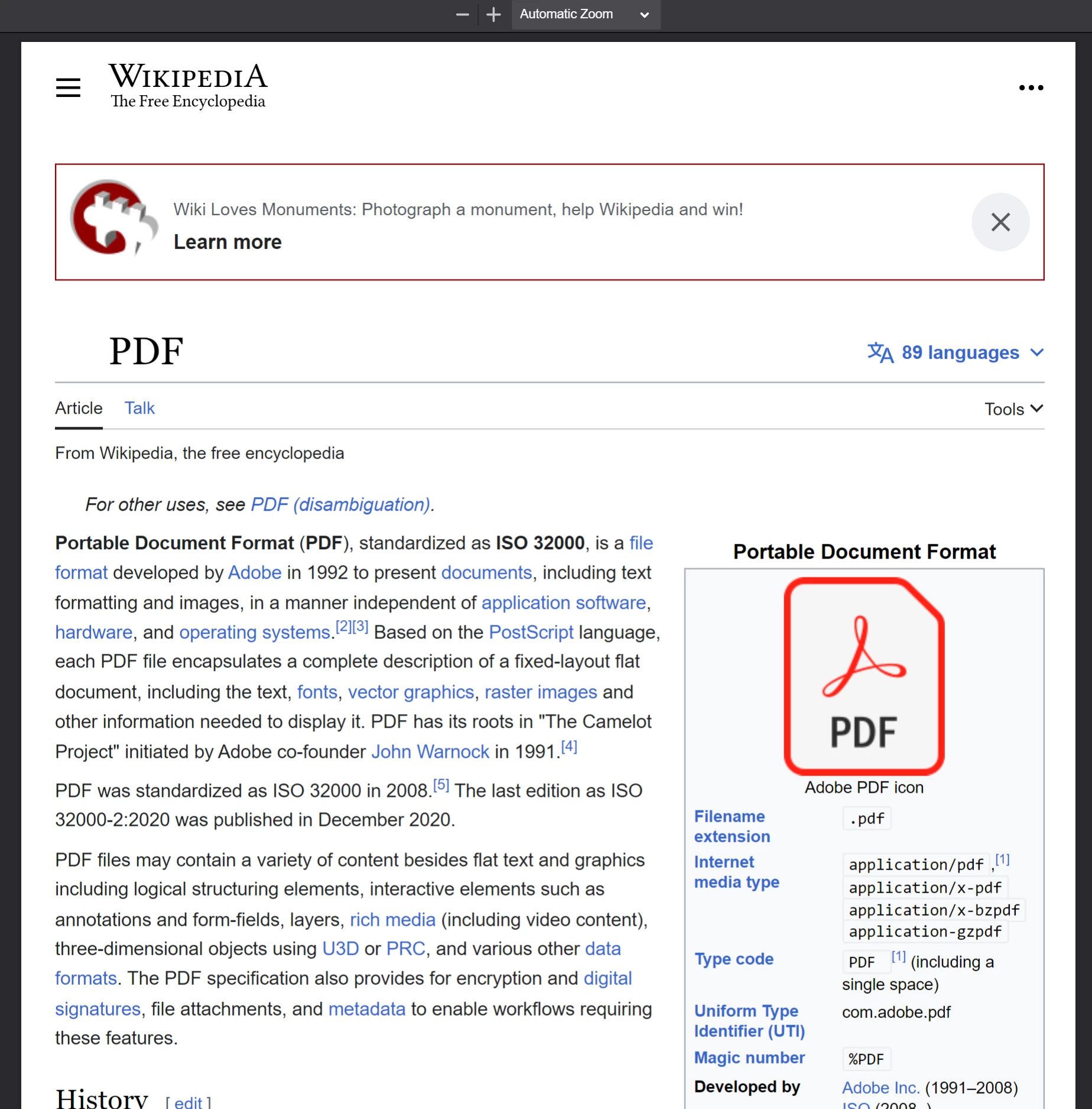 Le PDF généré à partir de l'appel de
Le PDF généré à partir de l'appel de PdfDocument.fromUrl sur un article Wikipédia. Notez sa grande ressemblance avec la page Web originale.
ChromePdfRenderOptions.Comment créer un PDF à partir d'une archive Zip ? {#create-pdf-from-zip}
PdfDocument.fromZip convertit un fichier HTML spécifique contenu dans une archive ZIP en PDF. C'est particulièrement utile lors de la distribution de projets HTML autonomes qui regroupent leur HTML, CSS, et ressources d'image ensemble.
Pour cet exemple, supposons que le répertoire du projet contient un fichier ZIP avec la structure suivante :
//:path=/static-assets/ironpdf-nodejs/content-code-examples/tutorials/html-to-pdf/zip-structure.txt
html-zip.zip
├─ index.html
├─ style.css
├─ logo.pngLe fichier index.html contient :
//:path=/static-assets/ironpdf-nodejs/content-code-examples/tutorials/html-to-pdf/index.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>Hello world!</title>
<link rel="stylesheet" href="style.css">
</head>
<body>
<h1>Hello from IronPDF!</h1>
<a href="https://ironpdf.com/nodejs/">
<img src="logo.png" alt="IronPDF for Node.js">
</a>
</body>
</html>//:path=/static-assets/ironpdf-nodejs/content-code-examples/tutorials/html-to-pdf/index.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>Hello world!</title>
<link rel="stylesheet" href="style.css">
</head>
<body>
<h1>Hello from IronPDF!</h1>
<a href="https://ironpdf.com/nodejs/">
<img src="logo.png" alt="IronPDF for Node.js">
</a>
</body>
</html>Et style.css définit la mise en page et les règles de police :
//:path=/static-assets/ironpdf-nodejs/content-code-examples/tutorials/html-to-pdf/style.css
@font-face {
font-family: 'Gotham-Black';
src: url('gotham-black-webfont.eot?') format('embedded-opentype'),
url('gotham-black-webfont.woff2') format('woff2'),
url('gotham-black-webfont.woff') format('woff'),
url('gotham-black-webfont.ttf') format('truetype'),
url('gotham-black-webfont.svg') format('svg');
font-weight: normal;
font-style: normal;
font-display: swap;
}
body {
display: flex;
flex-direction: column;
justify-content: center;
margin-left: auto;
margin-right: auto;
margin-top: 200px;
margin-bottom: auto;
color: white;
background-color: black;
text-align: center;
font-family: "Helvetica"
}
h1 {
font-family: "Gotham-Black";
margin-bottom: 70px;
font-size: 32pt;
}
img {
width: 400px;
height: auto;
}
p {
text-decoration: underline;
font-size: smaller;
} L'image d'échantillon à l'intérieur du fichier HTML ZIP hypothétique.
L'image d'échantillon à l'intérieur du fichier HTML ZIP hypothétique.
Lorsque vous appelez fromZip, spécifiez le chemin d'accès au fichier ZIP comme premier argument et un objet de configuration comme deuxième. Définissez la propriété mainHtmlFile sur le nom du fichier HTML contenu dans l'archive qui doit être converti :
//:path=/static-assets/ironpdf-nodejs/content-code-examples/tutorials/html-to-pdf/zip-to-pdf.js
import { PdfDocument } from "@ironsoftware/ironpdf";
import './config.js'; // Import the configuration script
// Convert an HTML file from a ZIP archive to PDF
PdfDocument.fromZip("./html-zip.zip", {
mainHtmlFile: "index.html"
}).then(async (pdf) => {
return await pdf.saveAs("html-zip-to-pdf.pdf");
});//:path=/static-assets/ironpdf-nodejs/content-code-examples/tutorials/html-to-pdf/zip-to-pdf.js
import { PdfDocument } from "@ironsoftware/ironpdf";
import './config.js'; // Import the configuration script
// Convert an HTML file from a ZIP archive to PDF
PdfDocument.fromZip("./html-zip.zip", {
mainHtmlFile: "index.html"
}).then(async (pdf) => {
return await pdf.saveAs("html-zip-to-pdf.pdf");
}); Création de PDF à l'aide de
Création de PDF à l'aide de PdfDocument.fromZip. La fonction rend avec succès le code HTML du fichier ZIP ainsi que ses ressources groupées.
Quelles options de rendu avancées IronPDF supporte-t-il ? {#advanced-rendering-options}
L'interface ChromePdfRenderOptions expose des propriétés permettant une personnalisation fine du comportement de rendu des PDF. Ces paramètres s'appliquent avant que le PDF ne soit généré et couvrent la mise en page, l'apparence visuelle et les cas particuliers pour le contenu dynamique.
IronPDF applique des paramètres de rendu par défaut à chaque conversion. Récupérez ces valeurs par défaut à l'aide de la fonction defaultChromePdfRenderOptions :
//:path=/static-assets/ironpdf-nodejs/content-code-examples/tutorials/html-to-pdf/default-options.js
import { defaultChromePdfRenderOptions } from "@ironsoftware/ironpdf";
// Retrieve a ChromePdfRenderOptions object with default settings
var options = defaultChromePdfRenderOptions();//:path=/static-assets/ironpdf-nodejs/content-code-examples/tutorials/html-to-pdf/default-options.js
import { defaultChromePdfRenderOptions } from "@ironsoftware/ironpdf";
// Retrieve a ChromePdfRenderOptions object with default settings
var options = defaultChromePdfRenderOptions();Modifiez les propriétés de l'objet renvoyé selon vos besoins et transmettez-le au paramètre renderOptions de n'importe quelle méthode de conversion.
Comment ajouter des en-têtes et des pieds de page ? {#add-headers-footers}
Les propriétés textHeader et textFooter ajoutent du contenu textuel personnalisé à chaque page d'un PDF nouvellement généré. L'exemple suivant crée un PDF à partir de la page d'accueil de la recherche Google avec un en-tête et un pied de page personnalisés, chacun utilisant une police différente :
//:path=/static-assets/ironpdf-nodejs/content-code-examples/tutorials/html-to-pdf/custom-headers-footers.js
import { PdfDocument, defaultChromePdfRenderOptions, AffixFonts } from "@ironsoftware/ironpdf";
import './config.js'; // Import the configuration script
// Start from default render options
var options = defaultChromePdfRenderOptions();
// Configure a text-based header
options.textHeader = {
centerText: "https://www.adobe.com",
dividerLine: true,
font: AffixFonts.CourierNew,
fontSize: 12,
leftText: "URL to PDF"
};
// Configure a text-based footer
options.textFooter = {
centerText: "IronPDF for Node.js",
dividerLine: true,
fontSize: 14,
font: AffixFonts.Helvetica,
rightText: "HTML to PDF in Node.js"
};
// Render the page with custom headers and footers applied
PdfDocument.fromUrl("https://www.google.com/", { renderOptions: options }).then(async (pdf) => {
return await pdf.saveAs("add-custom-headers-footers-1.pdf");
});//:path=/static-assets/ironpdf-nodejs/content-code-examples/tutorials/html-to-pdf/custom-headers-footers.js
import { PdfDocument, defaultChromePdfRenderOptions, AffixFonts } from "@ironsoftware/ironpdf";
import './config.js'; // Import the configuration script
// Start from default render options
var options = defaultChromePdfRenderOptions();
// Configure a text-based header
options.textHeader = {
centerText: "https://www.adobe.com",
dividerLine: true,
font: AffixFonts.CourierNew,
fontSize: 12,
leftText: "URL to PDF"
};
// Configure a text-based footer
options.textFooter = {
centerText: "IronPDF for Node.js",
dividerLine: true,
fontSize: 14,
font: AffixFonts.Helvetica,
rightText: "HTML to PDF in Node.js"
};
// Render the page with custom headers and footers applied
PdfDocument.fromUrl("https://www.google.com/", { renderOptions: options }).then(async (pdf) => {
return await pdf.saveAs("add-custom-headers-footers-1.pdf");
});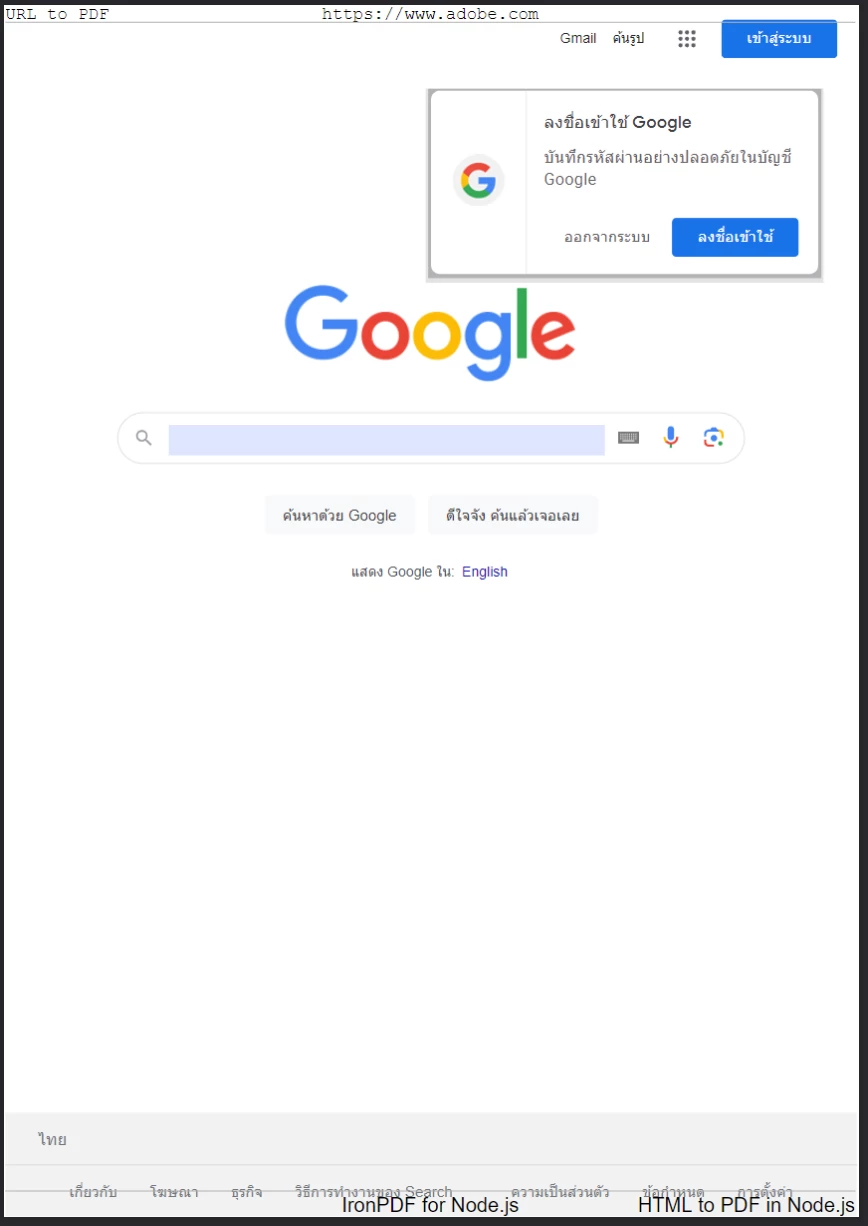 Un PDF généré à partir de la page d'accueil de Google avec un en-tête et un pied de page personnalisés appliqués à l'aide de
Un PDF généré à partir de la page d'accueil de Google avec un en-tête et un pied de page personnalisés appliqués à l'aide de textHeader et textFooter.
Pour des mises en page d'en-tête et de pied de page plus riches, utilisez plutôt les propriétés htmlHeader et htmlFooter. Celles-ci acceptent des fragments HTML bruts, offrant un contrôle total sur la typographie, les images et l'alignement. L'exemple ci-dessous centre l'URL de la page en gras dans l'en-tête et intègre une image de logo dans le pied de page :
//:path=/static-assets/ironpdf-nodejs/content-code-examples/tutorials/html-to-pdf/html-headers-footers.js
import { PdfDocument, defaultChromePdfRenderOptions } from "@ironsoftware/ironpdf";
import './config.js'; // Import the configuration script
// Start from default render options
var options = defaultChromePdfRenderOptions();
// Define a rich HTML header
options.htmlHeader = {
htmlFragment: "<strong>https://www.google.com/</strong>",
dividerLine: true,
dividerLineColor: "blue",
loadStylesAndCSSFromMainHtmlDocument: true,
};
// Define a rich HTML footer with a logo
options.htmlFooter = {
htmlFragment: "<img src='logo.png' alt='IronPDF for Node.js' style='display: block; width: 150px; height: auto; margin-left: auto; margin-right: auto;'>",
dividerLine: true,
loadStylesAndCSSFromMainHtmlDocument: true
};
// Apply custom HTML headers and footers during rendering
await PdfDocument.fromUrl("https://www.google.com/", { renderOptions: options }).then(async (pdf) => {
return await pdf.saveAs("add-html-headers-footers.pdf");
});//:path=/static-assets/ironpdf-nodejs/content-code-examples/tutorials/html-to-pdf/html-headers-footers.js
import { PdfDocument, defaultChromePdfRenderOptions } from "@ironsoftware/ironpdf";
import './config.js'; // Import the configuration script
// Start from default render options
var options = defaultChromePdfRenderOptions();
// Define a rich HTML header
options.htmlHeader = {
htmlFragment: "<strong>https://www.google.com/</strong>",
dividerLine: true,
dividerLineColor: "blue",
loadStylesAndCSSFromMainHtmlDocument: true,
};
// Define a rich HTML footer with a logo
options.htmlFooter = {
htmlFragment: "<img src='logo.png' alt='IronPDF for Node.js' style='display: block; width: 150px; height: auto; margin-left: auto; margin-right: auto;'>",
dividerLine: true,
loadStylesAndCSSFromMainHtmlDocument: true
};
// Apply custom HTML headers and footers during rendering
await PdfDocument.fromUrl("https://www.google.com/", { renderOptions: options }).then(async (pdf) => {
return await pdf.saveAs("add-html-headers-footers.pdf");
});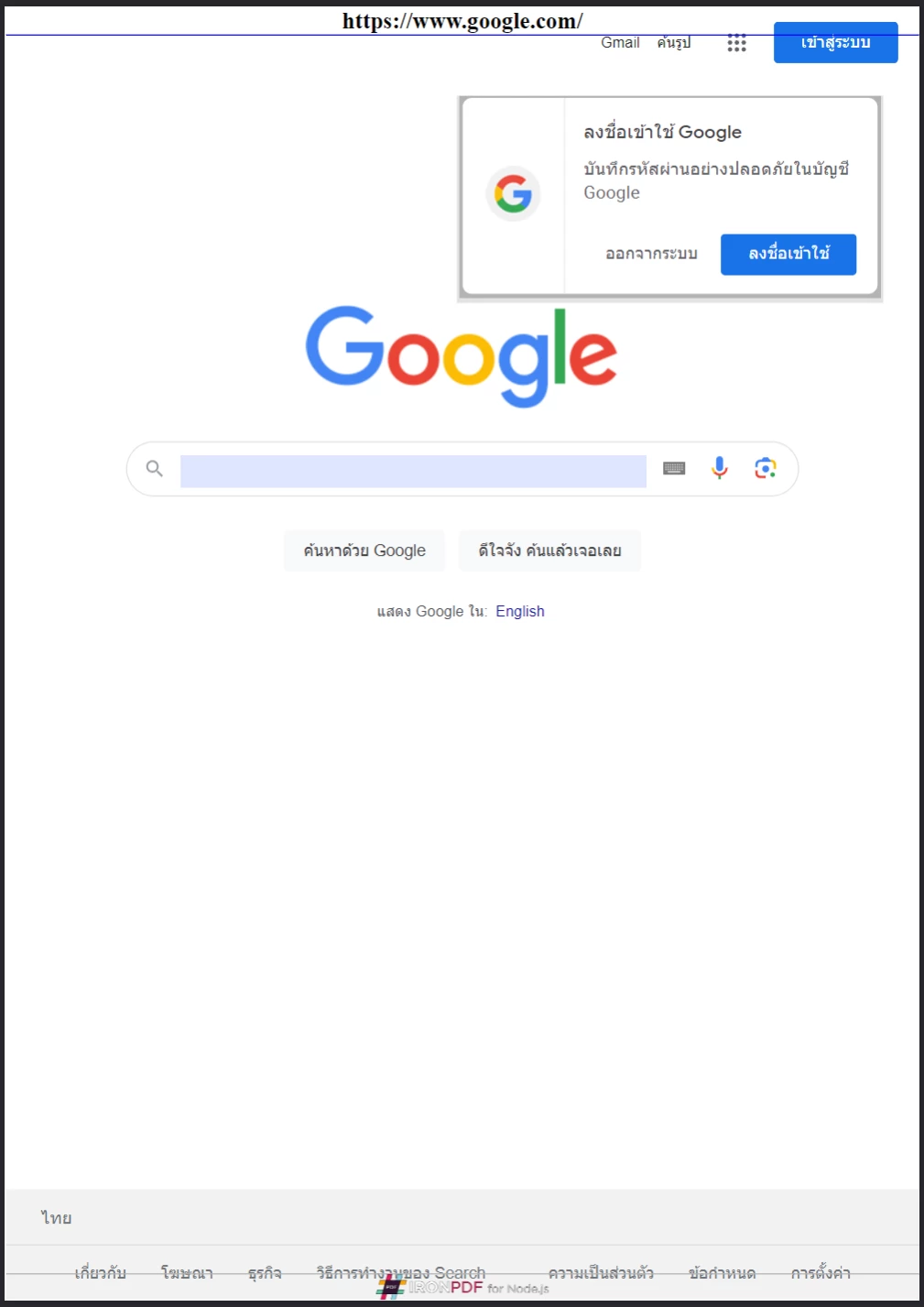 IronPDF prend en charge les en-têtes et pieds de page basés sur HTML, offrant un contrôle total sur l'image de marque et la mise en page de chaque page.
IronPDF prend en charge les en-têtes et pieds de page basés sur HTML, offrant un contrôle total sur l'image de marque et la mise en page de chaque page.
Comment contrôlez-vous la taille de la page, l'orientation et les marges ? {#page-size-orientation-margins}
Les propriétés margin, paperSize, fitToPaperMode, paperOrientation et grayScale sur ChromePdfRenderOptions contrôlent la mise en page physique de chaque page affichée. L'exemple suivant convertit la page d'accueil de Google avec des marges personnalisées, une orientation paysage A5 et une sortie en niveaux de gris :
//:path=/static-assets/ironpdf-nodejs/content-code-examples/tutorials/html-to-pdf/page-size-orientation.js
import { PdfDocument, defaultChromePdfRenderOptions, PaperSize, FitToPaperModes, PdfPaperOrientation } from "@ironsoftware/ironpdf";
import './config.js'; // Import the configuration script
// Start from default render options
var options = defaultChromePdfRenderOptions();
// Set page margins in millimeters
options.margin = {
top: 50,
bottom: 50,
left: 60,
right: 60
};
// Configure paper size, fit mode, orientation, and color mode
options.paperSize = PaperSize.A5;
options.fitToPaperMode = FitToPaperModes.FitToPage;
options.paperOrientation = PdfPaperOrientation.Landscape;
options.grayScale = true;
// Render with the customized layout settings
PdfDocument.fromUrl("https://www.google.com/", { renderOptions: options }).then(async (pdf) => {
return await pdf.saveAs("set-margins-and-page-size.pdf");
});//:path=/static-assets/ironpdf-nodejs/content-code-examples/tutorials/html-to-pdf/page-size-orientation.js
import { PdfDocument, defaultChromePdfRenderOptions, PaperSize, FitToPaperModes, PdfPaperOrientation } from "@ironsoftware/ironpdf";
import './config.js'; // Import the configuration script
// Start from default render options
var options = defaultChromePdfRenderOptions();
// Set page margins in millimeters
options.margin = {
top: 50,
bottom: 50,
left: 60,
right: 60
};
// Configure paper size, fit mode, orientation, and color mode
options.paperSize = PaperSize.A5;
options.fitToPaperMode = FitToPaperModes.FitToPage;
options.paperOrientation = PdfPaperOrientation.Landscape;
options.grayScale = true;
// Render with the customized layout settings
PdfDocument.fromUrl("https://www.google.com/", { renderOptions: options }).then(async (pdf) => {
return await pdf.saveAs("set-margins-and-page-size.pdf");
});L'énumération PaperSize comprend des formats de papier standard tels que A4, A5, Letter et Legal. L'énumération PdfPaperOrientation prend en charge Portrait et Landscape. Ces paramètres offrent un contrôle précis des dimensions de sortie pour les documents prêts à imprimer.
Comment gérer les pages Web dynamiques ? {#dynamic-web-pages}
Les pages qui chargent du contenu de manière asynchrone — via des minuteries JavaScript, un chargement différé ou des appels d'API — peuvent ne pas être entièrement rendues au moment où le moteur de IronPDF les capture. Le mécanisme WaitFor, configuré via la propriété waitFor sur ChromePdfRenderOptions, indique au moteur de rendu Chrome de mettre en pause jusqu'à ce que les conditions spécifiées soient remplies avant de capturer la page.
Le bloc de code suivant configure IronPDF pour attendre 20 secondes avant de capturer le contenu de la page :
//:path=/static-assets/ironpdf-nodejs/content-code-examples/tutorials/html-to-pdf/waitfor-delay.js
import { PdfDocument, defaultChromePdfRenderOptions, WaitForType } from "@ironsoftware/ironpdf";
import './config.js'; // Import the configuration script
// Configure the renderer to wait 20 seconds before capturing
var options = defaultChromePdfRenderOptions();
options.waitFor = {
type: WaitForType.RenderDelay,
delay: 20000
};
PdfDocument.fromUrl("https://ironpdf.com/nodejs/", { renderOptions: options }).then(async (pdf) => {
return await pdf.saveAs("waitfor-renderdelay.pdf");
});//:path=/static-assets/ironpdf-nodejs/content-code-examples/tutorials/html-to-pdf/waitfor-delay.js
import { PdfDocument, defaultChromePdfRenderOptions, WaitForType } from "@ironsoftware/ironpdf";
import './config.js'; // Import the configuration script
// Configure the renderer to wait 20 seconds before capturing
var options = defaultChromePdfRenderOptions();
options.waitFor = {
type: WaitForType.RenderDelay,
delay: 20000
};
PdfDocument.fromUrl("https://ironpdf.com/nodejs/", { renderOptions: options }).then(async (pdf) => {
return await pdf.saveAs("waitfor-renderdelay.pdf");
});Alternativement, configurez IronPDF pour attendre qu'un élément DOM spécifique apparaisse avant de rendre. C'est utile pour les pages où le contenu est injecté après qu'un framework JavaScript ait terminé son montage :
//:path=/static-assets/ironpdf-nodejs/content-code-examples/tutorials/html-to-pdf/waitfor-element.js
import { PdfDocument, defaultChromePdfRenderOptions, WaitForType } from "@ironsoftware/ironpdf";
import './config.js'; // Import the configuration script
// Configure the renderer to wait for a specific DOM element (up to 20 seconds)
var options = defaultChromePdfRenderOptions();
options.waitFor = {
type: WaitForType.HtmlElement,
htmlQueryStr: "div.ProseMirror",
maxWaitTime: 20000,
};
PdfDocument.fromUrl("https://app.surferseo.com/drafts/s/V7VkcdfgFz-dpkldsfHDGFFYf4jjSvvjsdf", { renderOptions: options }).then(async (pdf) => {
return await pdf.saveAs("waitfor-htmlelement.pdf");
});//:path=/static-assets/ironpdf-nodejs/content-code-examples/tutorials/html-to-pdf/waitfor-element.js
import { PdfDocument, defaultChromePdfRenderOptions, WaitForType } from "@ironsoftware/ironpdf";
import './config.js'; // Import the configuration script
// Configure the renderer to wait for a specific DOM element (up to 20 seconds)
var options = defaultChromePdfRenderOptions();
options.waitFor = {
type: WaitForType.HtmlElement,
htmlQueryStr: "div.ProseMirror",
maxWaitTime: 20000,
};
PdfDocument.fromUrl("https://app.surferseo.com/drafts/s/V7VkcdfgFz-dpkldsfHDGFFYf4jjSvvjsdf", { renderOptions: options }).then(async (pdf) => {
return await pdf.saveAs("waitfor-htmlelement.pdf");
});La stratégie WaitForType.HtmlElement utilise un sélecteur de requête CSS standard. Le moteur de rendu vérifie la présence de l'élément jusqu'à ce que maxWaitTime millisecondes se soient écoulées ou que l'élément soit trouvé — selon la première éventualité.
Comment générez-vous des PDFs à partir d'un modèle HTML ? {#html-template-to-PDF}
Un modèle courant d'automatisation réelle est de générer un lot de PDFs à partir d'un modèle HTML partagé, en substituant des valeurs de remplacement par des données provenant d'une base de données, d'une API ou d'une feuille de calcul. La méthode replaceText d'IronPDF sur PdfDocument gère cela directement.
Le modèle de facture ci-dessous (adapté d'un modèle de facture CodePen accessible au public) utilise des espaces réservés entre accolades tels que {COMPANY-NAME}, {FULL-NAME} et {INVOICE-NUMBER} pour le contenu remplaçable :
 Un modèle de facture exemple avec des balises de remplacement. Le code JavaScript remplacera chaque balise par des données réelles avant que le document soit enregistré en tant que PDF.
Un modèle de facture exemple avec des balises de remplacement. Le code JavaScript remplacera chaque balise par des données réelles avant que le document soit enregistré en tant que PDF.
Le code suivant charge le modèle, remplace chaque remplacement par des données de test, et enregistre le résultat sous forme de PDF :
//:path=/static-assets/ironpdf-nodejs/content-code-examples/tutorials/html-to-pdf/html-template-to-pdf.js
import { PdfDocument } from "@ironsoftware/ironpdf";
import './config.js'; // Import the configuration script
/**
* Loads an HTML template from the file system as a PdfDocument.
*/
async function getTemplateHtml(fileLocation) {
return PdfDocument.fromHtml(fileLocation);
}
/**
* Saves a PdfDocument to the specified file path.
*/
async function generatePdf(pdf, location) {
return pdf.saveAs(location);
}
/**
* Replaces a named placeholder in the PdfDocument with a data value.
*/
async function addTemplateData(pdf, key, value) {
return pdf.replaceText(key, value);
}
// Path to the HTML invoice template
const template = "./sample-invoice.html";
// Load the template, fill in all placeholder values, then save the PDF
getTemplateHtml(template).then(async (doc) => {
await addTemplateData(doc, "{FULL-NAME}", "Lizbeth Presland");
await addTemplateData(doc, "{ADDRESS}", "678 Manitowish Alley, Portland, OG");
await addTemplateData(doc, "{PHONE-NUMBER}", "(763) 894-4345");
await addTemplateData(doc, "{INVOICE-NUMBER}", "787");
await addTemplateData(doc, "{INVOICE-DATE}", "August 28, 2023");
await addTemplateData(doc, "{AMOUNT-DUE}", "13,760.13");
await addTemplateData(doc, "{RECIPIENT}", "Celestyna Farmar");
await addTemplateData(doc, "{COMPANY-NAME}", "BrainBook");
await addTemplateData(doc, "{TOTAL}", "13,760.13");
await addTemplateData(doc, "{AMOUNT-PAID}", "0.00");
await addTemplateData(doc, "{BALANCE-DUE}", "13,760.13");
await addTemplateData(doc, "{ITEM}", "Training Sessions");
await addTemplateData(doc, "{DESCRIPTION}", "60 Minute instruction");
await addTemplateData(doc, "{RATE}", "3,440.03");
await addTemplateData(doc, "{QUANTITY}", "4");
await addTemplateData(doc, "{PRICE}", "13,760.13");
return doc;
}).then(async (doc) => await generatePdf(doc, "html-template-to-pdf.pdf"));//:path=/static-assets/ironpdf-nodejs/content-code-examples/tutorials/html-to-pdf/html-template-to-pdf.js
import { PdfDocument } from "@ironsoftware/ironpdf";
import './config.js'; // Import the configuration script
/**
* Loads an HTML template from the file system as a PdfDocument.
*/
async function getTemplateHtml(fileLocation) {
return PdfDocument.fromHtml(fileLocation);
}
/**
* Saves a PdfDocument to the specified file path.
*/
async function generatePdf(pdf, location) {
return pdf.saveAs(location);
}
/**
* Replaces a named placeholder in the PdfDocument with a data value.
*/
async function addTemplateData(pdf, key, value) {
return pdf.replaceText(key, value);
}
// Path to the HTML invoice template
const template = "./sample-invoice.html";
// Load the template, fill in all placeholder values, then save the PDF
getTemplateHtml(template).then(async (doc) => {
await addTemplateData(doc, "{FULL-NAME}", "Lizbeth Presland");
await addTemplateData(doc, "{ADDRESS}", "678 Manitowish Alley, Portland, OG");
await addTemplateData(doc, "{PHONE-NUMBER}", "(763) 894-4345");
await addTemplateData(doc, "{INVOICE-NUMBER}", "787");
await addTemplateData(doc, "{INVOICE-DATE}", "August 28, 2023");
await addTemplateData(doc, "{AMOUNT-DUE}", "13,760.13");
await addTemplateData(doc, "{RECIPIENT}", "Celestyna Farmar");
await addTemplateData(doc, "{COMPANY-NAME}", "BrainBook");
await addTemplateData(doc, "{TOTAL}", "13,760.13");
await addTemplateData(doc, "{AMOUNT-PAID}", "0.00");
await addTemplateData(doc, "{BALANCE-DUE}", "13,760.13");
await addTemplateData(doc, "{ITEM}", "Training Sessions");
await addTemplateData(doc, "{DESCRIPTION}", "60 Minute instruction");
await addTemplateData(doc, "{RATE}", "3,440.03");
await addTemplateData(doc, "{QUANTITY}", "4");
await addTemplateData(doc, "{PRICE}", "13,760.13");
return doc;
}).then(async (doc) => await generatePdf(doc, "html-template-to-pdf.pdf"));Le code ci-dessus définit trois fonctions d'assistance asynchrones :
getTemplateHtml: Charge un fichier HTML dans un objetPdfDocumentà l'aide dePdfDocument.fromHtml.addTemplateData: AppellePdfDocument.replaceTextpour remplacer une clé de remplacement par sa valeur réelle.generatePdf: Écrit lePdfDocumentterminé dans un chemin de fichier cible.
Chaque appel replaceText opère directement sur la représentation PDF en mémoire, ce qui permet d'enchaîner plusieurs remplacements sans recharger le document depuis le disque. Le PDF résultant conserve tous les styles CSS, polices et mise en page du modèle original.
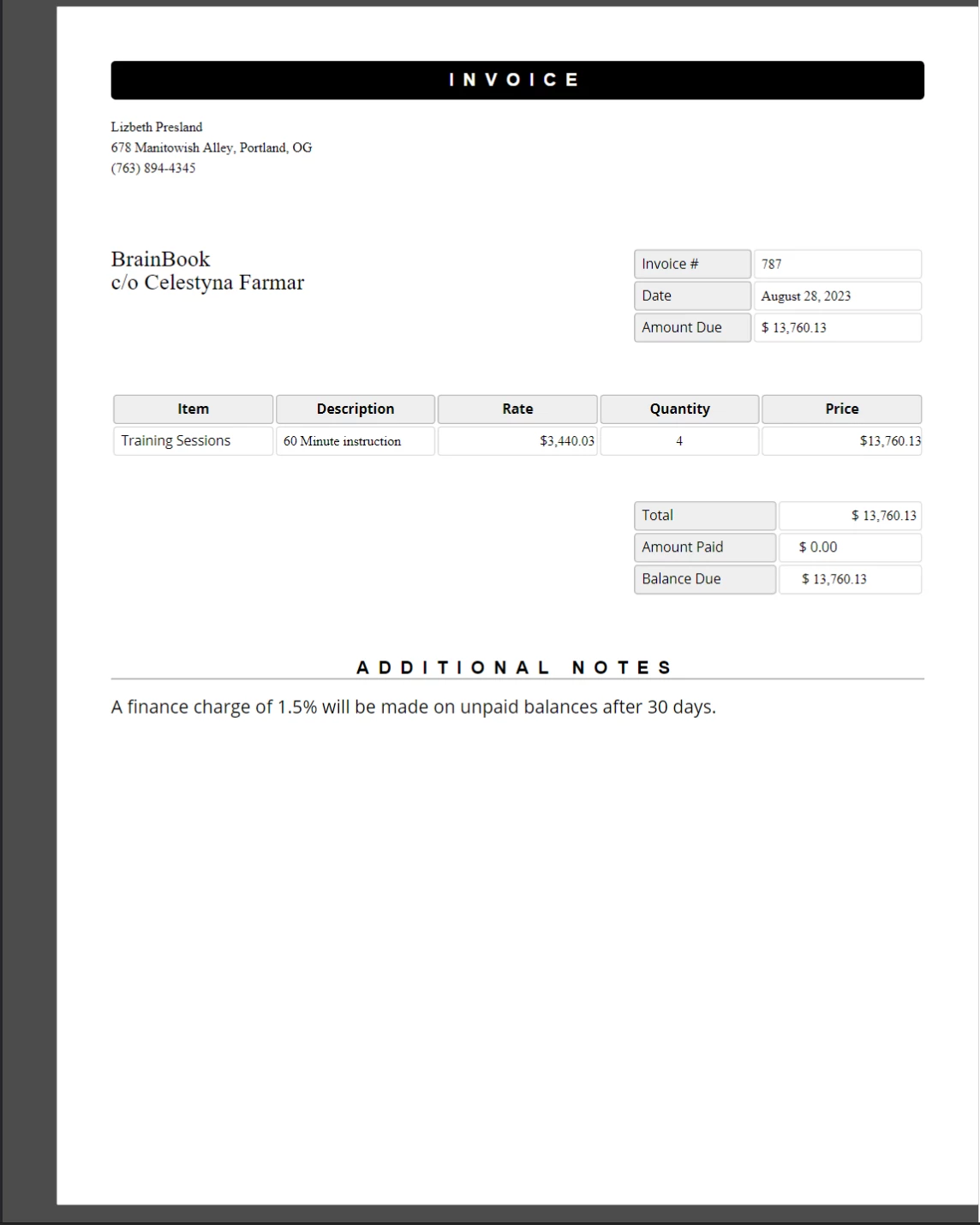 La facture PDF complétée avec des valeurs de remplacement remplacées par des données réelles. Les styles CSS et la mise en page du modèle d'origine sont conservés exactement.
La facture PDF complétée avec des valeurs de remplacement remplacées par des données réelles. Les styles CSS et la mise en page du modèle d'origine sont conservés exactement.
Cette approche est bien adaptée pour la génération de documents en lots. Appelez getTemplateHtml une fois par enregistrement pour créer un nouveau PdfDocument pour chaque fichier de sortie, puis enchaînez les appels addTemplateData pour les données de cet enregistrement avant d'appeler generatePdf.
Quelles sont les prochaines étapes? {#next-steps}
Ce tutoriel couvre les méthodes de conversion HTML en PDF de base et les options de rendu les plus fréquemment utilisées dans IronPDF for Node.js. Les sujets ci-dessous prolongent ce que vous avez appris ici dans des domaines plus spécialisés.
- Modifier et tamponner des PDFs dans Node.js — Appliquez des tampons, annotations et éditions de texte aux documents PDF existants de manière programmatique.
- Fusionner et diviser des PDFs dans Node.js — Combinez plusieurs PDFs en un seul document ou divisez un PDF en pages séparées.
- Ajouter des filigranes à des PDFs dans Node.js — Appliquez des filigranes texte ou image sur chaque page d'un PDF avec un contrôle précis de positionnement.
- Référence de l'API IronPDF for Node.js — Parcourez l'API complète pour
PdfDocument,ChromePdfRenderOptions,WaitFor,AffixFontset toutes les autres classes et interfaces exportées. - Obtenez une clé de licence d'essai gratuite — Générez des PDFs de qualité production sans filigranes en activant une licence d'essai gratuite de 30 jours.
Questions Fréquemment Posées
Comment convertissez-vous HTML en PDF dans Node.js ?
Utilisez la bibliothèque IronPDF. Installez-la avec npm install @ironsoftware/ironpdf, puis appelez PdfDocument.fromHtml avec une chaîne HTML ou un chemin de fichier, ou PdfDocument.fromUrl avec une adresse web. Enregistrez le résultat avec PdfDocument.saveAs.
Comment convertissez-vous une chaîne HTML en PDF dans Node.js ?
Appelez PdfDocument.fromHtml avec la chaîne HTML en argument. La méthode renvoie une Promise qui se résout en une instance de PdfDocument. Enchaînez saveAs sur le résultat pour écrire le PDF sur disque.
Comment convertissez-vous un fichier HTML local en PDF dans Node.js ?
Passez un chemin de système de fichiers valide à PdfDocument.fromHtml au lieu d'une chaîne HTML. IronPDF résout les chemins CSS, d'image et de script relatifs de la même manière qu'un navigateur lorsqu'il charge le fichier.
Comment convertissez-vous une URL en PDF dans Node.js ?
Appelez PdfDocument.fromUrl avec l'URL cible. IronPDF récupère la page en utilisant son moteur de rendu Chrome et produit un PDF au pixel près. L'URL cible doit être publiquement accessible à partir de l'hôte exécutant IronPDF.
Comment ajoutez-vous des en-têtes et des pieds de page à un PDF dans Node.js ?
Définissez les propriétés textHeader et textFooter sur un objet ChromePdfRenderOptions pour des en-têtes et pieds de page en texte simple. Pour des mises en page plus riches, utilisez htmlHeader et htmlFooter avec des fragments HTML bruts. Passez l'objet options au paramètre renderOptions de toute méthode de conversion.
Comment changez-vous la taille de la page et l'orientation dans IronPDF for Node.js ?
Définissez options.paperSize sur une valeur de l'enum PaperSize (comme PaperSize.A4 ou PaperSize.Letter) et définissez options.paperOrientation sur PdfPaperOrientation.Portrait ou PdfPaperOrientation.Landscape. Passez les options configurées à la méthode de conversion.
Comment gérez-vous le contenu JavaScript dynamique lors de la conversion en PDF ?
Utilisez la propriété waitFor sur ChromePdfRenderOptions. Définissez type sur WaitForType.RenderDelay et fournissez un délai en millisecondes, ou définissez type sur WaitForType.HtmlElement et fournissez un sélecteur de requête CSS. IronPDF suspendra le rendu jusqu'à ce que la condition soit satisfaite.
Comment convertissez-vous un fichier HTML à l'intérieur d'une archive ZIP en PDF ?
Appelez PdfDocument.fromZip avec le chemin vers le fichier ZIP en tant que premier argument et un objet d'options en tant que second. Définissez la propriété mainHtmlFile sur le nom du fichier HTML à l'intérieur de l'archive qui doit être converti.
Comment supprimer le filigrane IronPDF des PDF générés ?
Appliquez une clé de licence valide à la configuration globale avant d'appeler toute méthode de conversion. Récupérez l'objet config avec IronPdfGlobalConfig.getConfig() et définissez config.licenseKey sur votre clé. Une licence d'essai gratuite est disponible sur ironpdf.com.
Comment générez-vous des PDF à partir d'un modèle HTML dans Node.js ?
Chargez le modèle avec PdfDocument.fromHtml, puis appelez PdfDocument.replaceText pour chaque espace réservé dans le modèle, en passant la chaîne d'espace réservé et sa valeur de remplacement. Une fois toutes les substitutions terminées, appelez saveAs pour écrire le PDF final.


Vous faites encore défiler ?
Vous voulez une preuve rapidement ?
exécuter un échantillon Regardez votre code HTML se transformer en PDF.











