
Dask Python (jak to działa dla programistów)
Python jest potężnym językiem do analizy danych i uczenia maszynowego, ale obsługa dużych zbiorów danych może stanowić wyzwanie dla analityków danych. W tym miejscu do akcji wkracza Dask. Dask to biblioteka open source, która zapewnia zaawansowaną paralelizację analiz, umożliwiając wydajne obliczenia na dużych zbiorach danych, które przekraczają pojemność pamięci pojedynczego komputera. W tym artykule przyjrzymy się podstawowemu zastosowaniu biblioteki Dask oraz innej bardzo interesującej bibliotece do generowania plików PDF o nazwie IronPDF firmy Iron Software, służącej do tworzenia dokumentów PDF.
Dlaczego warto korzystać z Dask?
Dask został zaprojektowany, aby umożliwić skalowanie kodu w języku Python z pojedynczego laptopa do dużego klastra. Integruje się płynnie z popularnymi bibliotekami Pythona, takimi jak NumPy, pandas i scikit-learn, umożliwiając równoległe wykonywanie bez znaczących zmian w kodzie.
Kluczowe funkcje Dask
- Obliczenia równoległe: Dask umożliwia jednoczesne wykonywanie wielu zadań, co znacznie przyspiesza obliczenia.
- Skalowalność: Potrafi obsługiwać zbiory danych większe niż pojemność pamięci, dzieląc je na mniejsze części i przetwarzając je równolegle.
- Kompatybilność: Działa dobrze z istniejącymi bibliotekami Python, co ułatwia integrację z obecnym przepływem pracy.
- Elastyczność: Zapewnia kolekcje wysokiego poziomu, takie jak Dask DataFrame, wykresy zadań, Dask Array, Dask Cluster i Dask Bag, które naśladują odpowiednio pandas, NumPy i listy.
Pierwsze kroki z Dask
Instalacja
Dask można zainstalować za pomocą pip:
pip install dask[complete]pip install dask[complete]Podstawowe zastosowanie
Oto prosty przykład pokazujący, w jaki sposób Dask może równolegle przetwarzać obliczenia:
import dask.array as da
# Create a large Dask array
x = da.random.random((10, 10), chunks=(10, 10))
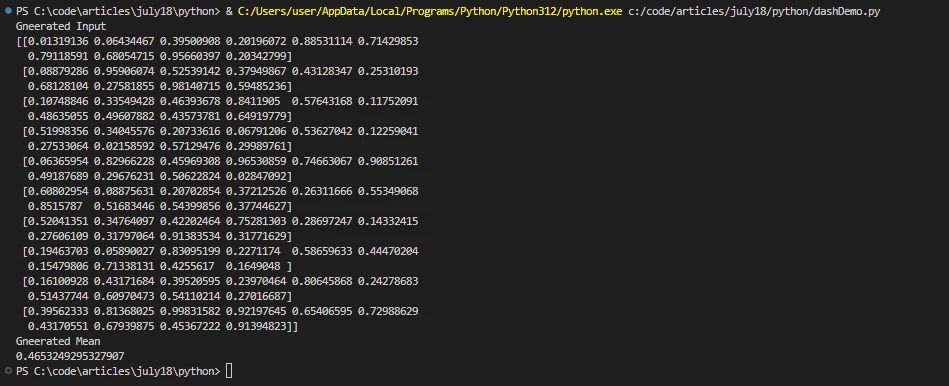
print('Generated Input')
print(x.compute())
# Perform a computation
result = x.mean().compute()
print('Generated Mean')
print(result)import dask.array as da
# Create a large Dask array
x = da.random.random((10, 10), chunks=(10, 10))
print('Generated Input')
print(x.compute())
# Perform a computation
result = x.mean().compute()
print('Generated Mean')
print(result)W tym przykładzie Dask tworzy dużą tablicę i dzieli ją na mniejsze fragmenty. Metoda compute() uruchamia obliczenia równoległe i zwraca wynik. Wykres zadań jest używany wewnętrznie do realizacji obliczeń równoległych w Python Dask.
Wynik
Dask DataFrames
Ramki danych Dask są podobne do ramek danych pandas, ale zostały zaprojektowane do obsługi zbiorów danych większych niż pojemność pamięci. Oto przykład:
import dask
# Generate a synthetic timeseries DataFrame
df = dask.datasets.timeseries()
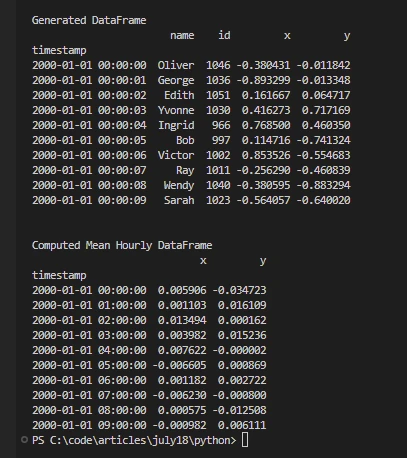
print('\nGenerated DataFrame')
print(df.head(10))
# Compute mean hourly resampled DataFrame
print('\nComputed Mean Hourly DataFrame')
print(df[["x", "y"]].resample("1h").mean().head(10))import dask
# Generate a synthetic timeseries DataFrame
df = dask.datasets.timeseries()
print('\nGenerated DataFrame')
print(df.head(10))
# Compute mean hourly resampled DataFrame
print('\nComputed Mean Hourly DataFrame')
print(df[["x", "y"]].resample("1h").mean().head(10))Kod pokazuje zdolność Dask do obsługi danych szeregów czasowych, generowania syntetycznych zbiorów danych oraz wydajnego obliczania agregacji, takich jak średnie godzinowe, poprzez wykorzystanie możliwości przetwarzania równoległego przy użyciu wielu procesów Python, rozproszonego harmonogramu oraz zasobów obliczeniowych wielu rdzeni.
Wynik
Najlepsze praktyki
- Zacznij od małych zbiorów danych, aby zrozumieć, jak działa Dask, zanim przejdziesz do większych projektów.
- Korzystanie z pulpitu nawigacyjnego: Dask udostępnia pulpit nawigacyjny do monitorowania postępów i wydajności obliczeń.
- Optymalizacja rozmiarów fragmentów: Wybierz odpowiednie rozmiary fragmentów, aby zrównoważyć zużycie pamięci i szybkość obliczeniową.
Przedstawiamy IronPDF
IronPDF to solidna biblioteka w języku Python przeznaczona do tworzenia, edycji i podpisywania dokumentów PDF przy użyciu HTML, CSS, obrazów i JavaScript. Podkreśla wydajność przy minimalnym zużyciu pamięci. Najważniejsze cechy to:
- Konwersja HTML do PDF: Łatwo konwertuj pliki HTML, ciągi znaków i adresy URL na dokumenty PDF, wykorzystując możliwości renderowania PDF w przeglądarce Chrome.
- Obsługa wielu platform: Działa płynnie w środowisku Python 3+ na systemach Windows, Mac, Linux oraz różnych platformach chmurowych. Jest również kompatybilny ze środowiskami .NET, Java, Python i Node.js.
- Edycja i podpisywanie: Dostosuj właściwości plików PDF, zastosuj zabezpieczenia, takie jak hasła i uprawnienia, oraz płynnie dodawaj podpisy cyfrowe.
- Szablony stron i ustawienia: Dostosuj układy plików PDF za pomocą nagłówków, stopek, numerów stron, regulowanych marginesów, niestandardowych rozmiarów papieru i responsywnych projektów.
- Zgodność ze standardami: Ścisłe przestrzeganie standardów PDF, takich jak PDF/A i PDF/UA, zapewniające zgodność z kodowaniem znaków UTF-8. Obsługiwane jest również wydajne zarządzanie zasobami, takimi jak obrazy, arkusze stylów CSS i czcionki.
Instalacja
pip install ironpdf
pip install daskpip install ironpdf
pip install daskGenerowanie dokumentów PDF przy użyciu IronPDF i Dask.
Wymagania wstępne
- Upewnij się, że masz zainstalowany Visual Studio Code.
- Zainstalowano Python w wersji 3.
Na początek utwórzmy plik w języku Python, aby dodać nasze skrypty.
Otwórz Visual Studio Code i utwórz plik daskDemo.py.
Zainstaluj niezbędne biblioteki:
pip install dask
pip install ironpdfpip install dask
pip install ironpdfNastępnie dodaj poniższy kod w języku Python, aby zademonstrować użycie pakietów IronPDF i Dask Python:
import dask
from ironpdf import *
# Apply your license key
License.LicenseKey = "key"
# Generate a synthetic timeseries DataFrame
df = dask.datasets.timeseries()
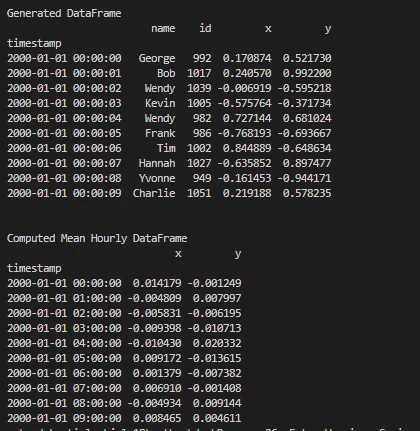
print('\nGenerated DataFrame')
print(df.head(10))
# Compute the mean hourly DataFrame
dfmean = df[["x", "y"]].resample("1h").mean().head(10)
print('\nComputed Mean Hourly DataFrame')
print(dfmean)
# Initialize the PDF renderer
renderer = ChromePdfRenderer()
# Create HTML content for the PDF
content = "<h1>Awesome Iron PDF with Dask</h1>"
# Add generated DataFrame to the content
content += "<h2>Generated DataFrame (First 10)</h2>"
rows = df.head(10)
for i in range(10):
row = rows.iloc[i]
content += f"<p>{str(row[0])}, {str(row[2])}, {str(row[3])}</p>"
# Add computed mean DataFrame to the content
content += "<h2>Computed Mean Hourly DataFrame (First 10)</h2>"
for i in range(10):
row = dfmean.iloc[i]
content += f"<p>{str(row[0])}</p>"
# Render the HTML content as PDF
pdf = renderer.RenderHtmlAsPdf(content)
# Save the PDF to a file
pdf.SaveAs("DemoIronPDF-Dask.pdf")import dask
from ironpdf import *
# Apply your license key
License.LicenseKey = "key"
# Generate a synthetic timeseries DataFrame
df = dask.datasets.timeseries()
print('\nGenerated DataFrame')
print(df.head(10))
# Compute the mean hourly DataFrame
dfmean = df[["x", "y"]].resample("1h").mean().head(10)
print('\nComputed Mean Hourly DataFrame')
print(dfmean)
# Initialize the PDF renderer
renderer = ChromePdfRenderer()
# Create HTML content for the PDF
content = "<h1>Awesome Iron PDF with Dask</h1>"
# Add generated DataFrame to the content
content += "<h2>Generated DataFrame (First 10)</h2>"
rows = df.head(10)
for i in range(10):
row = rows.iloc[i]
content += f"<p>{str(row[0])}, {str(row[2])}, {str(row[3])}</p>"
# Add computed mean DataFrame to the content
content += "<h2>Computed Mean Hourly DataFrame (First 10)</h2>"
for i in range(10):
row = dfmean.iloc[i]
content += f"<p>{str(row[0])}</p>"
# Render the HTML content as PDF
pdf = renderer.RenderHtmlAsPdf(content)
# Save the PDF to a file
pdf.SaveAs("DemoIronPDF-Dask.pdf")Wyjaśnienie kodu
Ten fragment kodu integruje Dask do obsługi danych oraz IronPDF do generowania plików PDF. Pokazuje to:
- Integracja z Dask: Wykorzystuje
dask.datasets.timeseries()do generowania syntetycznego DataFrame'a szeregów czasowych (df). PRINTuje pierwsze 10 wierszy (df.head(10)) i oblicza średnią godzinową DataFrame (dfmean) na podstawie kolumn "x" i "y". - Użycie IronPDF: Ustawia klucz licencyjny IronPDF za pomocą
License.LicenseKey. Tworzy ciąg HTML (content) zawierający nagłówki i dane z wygenerowanych i obliczonych ram danych (DataFrames), a następnie renderuje tę zawartość HTML do pliku PDF (pdf) przy użyciuChromePdfRenderer(), a na koniec zapisuje plik PDF jako "DemoIronPDF-Dask.pdf".
Ten kod łączy możliwości Dask w zakresie przetwarzania danych na dużą skalę z funkcjonalnością IronPDF do konwersji treści HTML na dokument PDF.
Wynik

Licencja IronPDF
Klucz licencyjny IronPDF pozwala użytkownikom zapoznać się z jego rozbudowanymi funkcjami przed zakupem.
Umieść klucz licencyjny na początku skryptu przed użyciem pakietu IronPDF:
from ironpdf import *
# Apply your license key
License.LicenseKey = "key"from ironpdf import *
# Apply your license key
License.LicenseKey = "key"Wnioski
Dask to wszechstronne narzędzie, które może znacznie zwiększyć możliwości przetwarzania danych w języku Python. Dzięki obsłudze obliczeń równoległych i rozproszonych umożliwia wydajną pracę z dużymi zbiorami danych i płynnie integruje się z istniejącym ekosystemem Pythona. IronPDF to potężna biblioteka w języku Python służąca do tworzenia i edycji dokumentów PDF przy użyciu HTML, CSS, obrazów i JavaScript. Oferuje takie funkcje, jak konwersja HTML do PDF, edycja plików PDF, podpisywanie cyfrowe oraz obsługa wielu platform, dzięki czemu nadaje się do różnych zadań związanych z generowaniem i zarządzaniem dokumentami w aplikacjach napisanych w języku Python.
Obie biblioteki razem pozwalają analitykom danych na przeprowadzanie zaawansowanych operacji analitycznych i naukowych, a następnie zapisywanie wyników w standardowym formacie PDF przy użyciu IronPDF.
















