
Dask Python (개발자를 위한 작동 방식)
Python은 데이터 분석 및 머신 러닝에 강력한 언어이지만, 대규모 데이터 세트를 처리하는 것은 데이터 분석에 어려움을 줄 수 있습니다. 바로 이 부분에서 Dask가 등장합니다. Dask는 분석을 위한 고급 병렬화 기능을 제공하는 오픈 소스 라이브러리로, 단일 컴퓨터의 메모리 용량을 초과하는 대규모 데이터 세트에 대한 효율적인 계산을 가능하게 합니다. 이 글에서는 Dask 라이브러리의 기본 사용법과 Iron Software 에서 개발한 IronPDF 라는 또 다른 흥미로운 PDF 생성 라이브러리를 사용하여 PDF 문서를 생성하는 방법을 살펴보겠습니다.
Dask를 사용하는 이유는 무엇일까요?
Dask 는 단일 노트북에서 대규모 클러스터에 이르기까지 Python 코드를 확장할 수 있도록 설계되었습니다. 이 라이브러리는 NumPy, pandas, scikit-learn과 같은 인기 있는 Python 라이브러리와 완벽하게 통합되어 코드 변경 없이 병렬 실행을 가능하게 합니다.
Dask의 주요 기능
- 병렬 컴퓨팅: Dask를 사용하면 여러 작업을 동시에 실행할 수 있어 계산 속도를 크게 향상시킬 수 있습니다.
- 확장성: 메모리보다 큰 데이터셋도 작은 덩어리로 나누어 병렬로 처리함으로써 확장성을 확보할 수 있습니다.
- 호환성: 기존 Python 라이브러리와 호환성이 뛰어나 현재 워크플로에 쉽게 통합할 수 있습니다.
- 유연성: Dask DataFrame, 작업 그래프, Dask Array, Dask Cluster, Dask Bag과 같은 고급 컬렉션을 제공하며, 이는 각각 pandas, NumPy, 리스트를 모방합니다.
Dask 시작하기
설치
pip를 사용하여 Dask를 설치할 수 있습니다.
pip install dask[complete]pip install dask[complete]기본 사용법
Dask를 사용하여 연산을 병렬화하는 방법을 보여주는 간단한 예입니다.
import dask.array as da
# Create a large Dask array
x = da.random.random((10, 10), chunks=(10, 10))
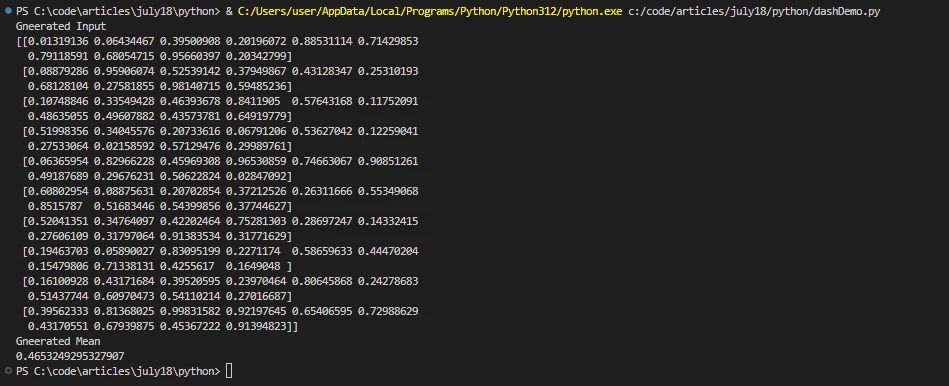
print('Generated Input')
print(x.compute())
# Perform a computation
result = x.mean().compute()
print('Generated Mean')
print(result)import dask.array as da
# Create a large Dask array
x = da.random.random((10, 10), chunks=(10, 10))
print('Generated Input')
print(x.compute())
# Perform a computation
result = x.mean().compute()
print('Generated Mean')
print(result)이 예제에서 Dask는 큰 배열을 생성한 다음 이를 더 작은 덩어리로 나눕니다. compute() 메서드는 병렬 연산을 트리거하고 결과를 반환합니다. 태스크 그래프는 Python Dask에서 병렬 컴퓨팅을 구현하기 위한 내부적인 도구입니다.
산출
Dask 데이터 프레임
Dask DataFrame은 pandas DataFrame과 유사하지만 메모리 용량보다 큰 데이터 세트를 처리하도록 설계되었습니다. 다음은 예시입니다.
import dask
# Generate a synthetic timeseries DataFrame
df = dask.datasets.timeseries()
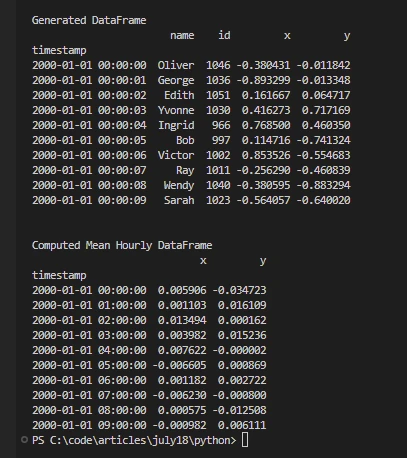
print('\nGenerated DataFrame')
print(df.head(10))
# Compute mean hourly resampled DataFrame
print('\nComputed Mean Hourly DataFrame')
print(df[["x", "y"]].resample("1h").mean().head(10))import dask
# Generate a synthetic timeseries DataFrame
df = dask.datasets.timeseries()
print('\nGenerated DataFrame')
print(df.head(10))
# Compute mean hourly resampled DataFrame
print('\nComputed Mean Hourly DataFrame')
print(df[["x", "y"]].resample("1h").mean().head(10))이 코드는 Dask가 여러 Python 프로세스, 분산 스케줄러 및 멀티 코어 컴퓨팅 리소스를 활용한 병렬 처리 기능을 통해 시계열 데이터를 처리하고, 합성 데이터 세트를 생성하고, 시간별 평균과 같은 집계를 효율적으로 계산할 수 있는 능력을 보여줍니다.
산출
모범 사례
- 소규모로 시작하세요: 규모를 확장하기 전에 Dask의 작동 방식을 이해하기 위해 소규모 데이터 세트로 시작하십시오.
- 대시보드 사용: Dask는 계산 진행 상황과 성능을 모니터링할 수 있는 대시보드를 제공합니다.
- 청크 크기 최적화: 메모리 사용량과 계산 속도의 균형을 맞추기 위해 적절한 청크 크기를 선택하십시오.
IronPDF 소개합니다
IronPDF 는 HTML, CSS, 이미지 및 JavaScript 사용하여 PDF 문서를 생성, 편집 및 서명하도록 설계된 강력한 Python 라이브러리입니다. 이 소프트웨어는 최소한의 메모리 사용량으로 성능 효율성을 강조합니다. 주요 특징은 다음과 같습니다.
- HTML을 PDF로 변환: Chrome의 PDF 렌더링 기능을 활용하여 HTML 파일, 문자열 및 URL을 PDF 문서로 간편하게 변환할 수 있습니다.
- 크로스 플랫폼 지원: Windows, Mac, Linux 및 다양한 클라우드 플랫폼에서 Python 3 이상 버전과 원활하게 작동합니다. 또한 .NET, Java, Python 및 Node.js 환경과 호환됩니다.
- 편집 및 서명: PDF 속성을 사용자 지정하고, 암호 및 권한과 같은 보안 조치를 적용하고, 디지털 서명을 간편하게 추가할 수 있습니다.
- 페이지 템플릿 및 설정: 머리글, 바닥글, 페이지 번호, 조정 가능한 여백, 사용자 지정 용지 크기 및 반응형 디자인을 사용하여 PDF 레이아웃을 맞춤 설정할 수 있습니다.
- 표준 준수: PDF/A 및 PDF/UA와 같은 PDF 표준을 엄격히 준수하여 UTF-8 문자 인코딩 호환성을 보장합니다. 이미지, CSS 스타일시트, 글꼴과 같은 자산의 효율적인 관리도 지원됩니다.
설치
pip install ironpdf dask
IronPDF 와 Dask를 사용하여 PDF 문서를 생성합니다.
필수 조건
- Visual Studio Code가 설치되어 있는지 확인하십시오.
- Python 버전 3이 설치되어 있습니다.
우선 스크립트를 추가할 Python 파일을 만들어 보겠습니다.
Visual Studio Code를 열고 파일을 생성합니다, daskDemo.py.
필요한 라이브러리를 설치하세요:
pip install dask ironpdf
다음으로 아래 Python 코드를 추가하여 IronPDF 및 Dask Python 패키지의 사용법을 보여주세요.
import dask
from ironpdf import *
# Apply your license key
License.LicenseKey = "key"
# Generate a synthetic timeseries DataFrame
df = dask.datasets.timeseries()
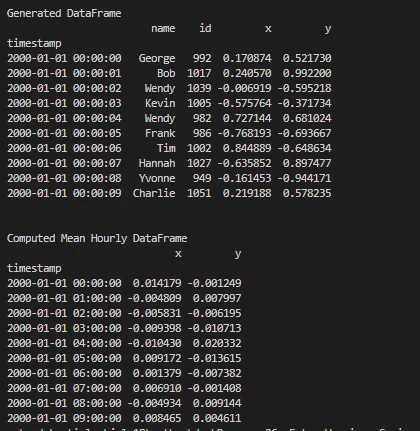
print('\nGenerated DataFrame')
print(df.head(10))
# Compute the mean hourly DataFrame
dfmean = df[["x", "y"]].resample("1h").mean().head(10)
print('\nComputed Mean Hourly DataFrame')
print(dfmean)
# Initialize the PDF renderer
renderer = ChromePdfRenderer()
# Create HTML content for the PDF
content = "<h1>Awesome Iron PDF with Dask</h1>"
# Add generated DataFrame to the content
content += "<h2>Generated DataFrame (First 10)</h2>"
rows = df.head(10)
for i in range(10):
row = rows.iloc[i]
content += f"<p>{str(row[0])}, {str(row[2])}, {str(row[3])}</p>"
# Add computed mean DataFrame to the content
content += "<h2>Computed Mean Hourly DataFrame (First 10)</h2>"
for i in range(10):
row = dfmean.iloc[i]
content += f"<p>{str(row[0])}</p>"
# Render the HTML content as PDF
pdf = renderer.RenderHtmlAsPdf(content)
# Save the PDF to a file
pdf.SaveAs("DemoIronPDF-Dask.pdf")import dask
from ironpdf import *
# Apply your license key
License.LicenseKey = "key"
# Generate a synthetic timeseries DataFrame
df = dask.datasets.timeseries()
print('\nGenerated DataFrame')
print(df.head(10))
# Compute the mean hourly DataFrame
dfmean = df[["x", "y"]].resample("1h").mean().head(10)
print('\nComputed Mean Hourly DataFrame')
print(dfmean)
# Initialize the PDF renderer
renderer = ChromePdfRenderer()
# Create HTML content for the PDF
content = "<h1>Awesome Iron PDF with Dask</h1>"
# Add generated DataFrame to the content
content += "<h2>Generated DataFrame (First 10)</h2>"
rows = df.head(10)
for i in range(10):
row = rows.iloc[i]
content += f"<p>{str(row[0])}, {str(row[2])}, {str(row[3])}</p>"
# Add computed mean DataFrame to the content
content += "<h2>Computed Mean Hourly DataFrame (First 10)</h2>"
for i in range(10):
row = dfmean.iloc[i]
content += f"<p>{str(row[0])}</p>"
# Render the HTML content as PDF
pdf = renderer.RenderHtmlAsPdf(content)
# Save the PDF to a file
pdf.SaveAs("DemoIronPDF-Dask.pdf")코드 설명
이 코드 조각은 데이터 처리를 위해 Dask를, PDF 생성을 위해 IronPDF 통합합니다. 이는 다음을 보여줍니다:
- Dask 통합:
dask.datasets.timeseries()을 사용하여 합성 시계열 DataFrame (df)을 생성합니다. 첫 10개 행 (df.head(10))을 출력하고, "x" 및 "y" 열을 기반으로 평균 시간별 DataFrame (dfmean)을 계산합니다. - IronPDF 사용:
License.LicenseKey을 사용하여 IronPDF 라이선스 키를 설정합니다. 생성 및 계산된 DataFrames의 헤더와 데이터를 포함한 HTML 문자열 (content)을 생성한 후,ChromePdfRenderer()을 사용하여 이 HTML 내용을 PDF (pdf)로 렌더링하고, 마지막으로 "DemoIronPDF-Dask.pdf"로 저장합니다.
이 코드는 대규모 데이터 처리를 위한 Dask의 기능과 HTML 콘텐츠를 PDF 문서로 변환하는 IronPDF의 기능을 결합합니다.
산출

IronPDF 라이선스
IronPDF 라이선스 키를 사용하면 구매 전에 다양한 기능을 미리 확인할 수 있습니다.
IronPDF 패키지를 사용하기 전에 스크립트 시작 부분에 라이선스 키를 배치하십시오.
from ironpdf import *
# Apply your license key
License.LicenseKey = "key"from ironpdf import *
# Apply your license key
License.LicenseKey = "key"결론
Dask 는 Python에서 데이터 처리 기능을 크게 향상시킬 수 있는 다재다능한 도구입니다. 병렬 및 분산 컴퓨팅을 지원함으로써 대규모 데이터 세트를 효율적으로 처리할 수 있으며 기존 Python 생태계와 원활하게 통합됩니다. IronPDF 는 HTML, CSS, 이미지 및 JavaScript 사용하여 PDF 문서를 생성하고 조작할 수 있는 강력한 Python 라이브러리입니다. 이 라이브러리는 HTML을 PDF로 변환, PDF 편집, 디지털 서명, 크로스 플랫폼 지원 등의 기능을 제공하여 Python 애플리케이션에서 다양한 문서 생성 및 관리 작업에 적합합니다.
두 라이브러리를 함께 사용하면 데이터 과학자는 고급 데이터 분석 및 과학 작업을 수행한 다음 IronPDF 사용하여 출력 결과를 표준 PDF 형식으로 저장할 수 있습니다.
















