
Dask Python (Como funciona para desenvolvedores)
Python é uma linguagem poderosa para análise de dados e aprendizado de máquina, mas lidar com grandes conjuntos de dados pode ser um desafio para a análise de dados. É aí que Dask entra em cena. Dask é uma biblioteca de código aberto que oferece paralelização avançada para análises, permitindo computação eficiente em grandes conjuntos de dados que excedem a capacidade de memória de uma única máquina. Neste artigo, vamos explorar o uso básico da biblioteca Dask e de outra biblioteca muito interessante para geração de PDFs, chamada IronPDF, da Iron Software .
Por que usar o Dask?
O Dask foi projetado para dimensionar seu código Python, desde um único laptop até um grande cluster. Ele se integra perfeitamente com bibliotecas populares do Python, como NumPy, pandas e scikit-learn, para permitir a execução paralela sem alterações significativas no código.
Principais características do Dask
- Computação Paralela: O Dask permite executar várias tarefas simultaneamente, acelerando significativamente os cálculos.
- Escalabilidade: Ele consegue lidar com conjuntos de dados maiores que a memória disponível, dividindo-os em partes menores e processando-os em paralelo.
- Compatibilidade: Funciona bem com as bibliotecas Python existentes, facilitando a integração ao seu fluxo de trabalho atual.
- Flexibilidade: Oferece coleções de alto nível como Dask DataFrame, grafos de tarefas, Dask Array, Dask Cluster e Dask Bag, que imitam pandas, NumPy e listas, respectivamente.
Primeiros passos com o Dask
Instalação
Você pode instalar o Dask usando o pip:
pip install dask[complete]pip install dask[complete]Uso básico
Aqui está um exemplo simples para demonstrar como o Dask pode paralelizar computações:
import dask.array as da
# Create a large Dask array
x = da.random.random((10, 10), chunks=(10, 10))
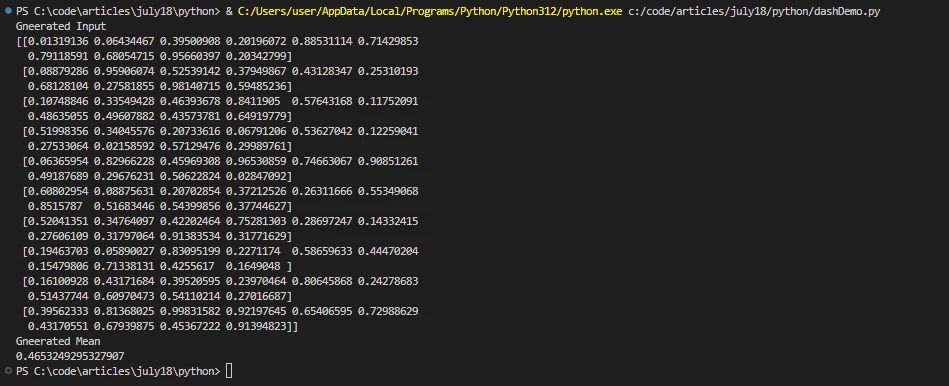
print('Generated Input')
print(x.compute())
# Perform a computation
result = x.mean().compute()
print('Generated Mean')
print(result)import dask.array as da
# Create a large Dask array
x = da.random.random((10, 10), chunks=(10, 10))
print('Generated Input')
print(x.compute())
# Perform a computation
result = x.mean().compute()
print('Generated Mean')
print(result)Neste exemplo, o Dask cria um array grande e o divide em partes menores. O método compute() aciona o cálculo paralelo e retorna o resultado. O grafo de tarefas é usado internamente para alcançar computação paralela no Python Dask.
Saída
DataFrames Dask
Os DataFrames do Dask são semelhantes aos DataFrames do pandas, mas foram projetados para lidar com conjuntos de dados maiores do que a memória disponível. Eis um exemplo:
import dask
# Generate a synthetic timeseries DataFrame
df = dask.datasets.timeseries()
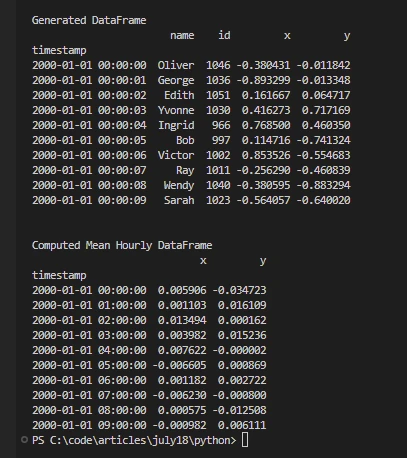
print('\nGenerated DataFrame')
print(df.head(10))
# Compute mean hourly resampled DataFrame
print('\nComputed Mean Hourly DataFrame')
print(df[["x", "y"]].resample("1h").mean().head(10))import dask
# Generate a synthetic timeseries DataFrame
df = dask.datasets.timeseries()
print('\nGenerated DataFrame')
print(df.head(10))
# Compute mean hourly resampled DataFrame
print('\nComputed Mean Hourly DataFrame')
print(df[["x", "y"]].resample("1h").mean().head(10))O código demonstra a capacidade do Dask de lidar com dados de séries temporais, gerar conjuntos de dados sintéticos e calcular agregações como médias horárias de forma eficiente, aproveitando seus recursos de processamento paralelo por meio de múltiplos processos Python, um agendador distribuído e recursos computacionais de múltiplos núcleos.
Saída
Melhores práticas
- Comece pequeno: Comece com conjuntos de dados pequenos para entender como o Dask funciona antes de aumentar a escala.
- Utilize o Painel de Controle: O Dask fornece um painel de controle para monitorar o progresso e o desempenho de seus cálculos.
- Otimize o tamanho dos blocos: escolha tamanhos de bloco adequados para equilibrar o uso de memória e a velocidade de computação.
Apresentando o IronPDF
IronPDF é uma biblioteca Python robusta projetada para criar, editar e assinar documentos PDF usando HTML, CSS, imagens e JavaScript. Prioriza a eficiência de desempenho com o mínimo uso de memória. As principais características incluem:
- Conversão de HTML para PDF: Converta facilmente arquivos HTML, strings e URLs em documentos PDF, aproveitando os recursos de renderização de PDF do Chrome.
- Suporte multiplataforma: Funciona perfeitamente com Python 3+ no Windows, Mac, Linux e em diversas plataformas de nuvem. Também é compatível com ambientes .NET, Java, Python e Node.js
- Edição e assinatura: personalize as propriedades do PDF, aplique medidas de segurança como senhas e permissões e adicione assinaturas digitais com facilidade.
- Modelos e configurações de página: personalize layouts de PDF com cabeçalhos, rodapés, números de página, margens ajustáveis, tamanhos de papel personalizados e designs responsivos.
- Conformidade com os padrões: Rigorosa observância dos padrões PDF, como PDF/A e PDF/UA, garantindo a compatibilidade com a codificação de caracteres UTF-8. O sistema também oferece suporte ao gerenciamento eficiente de recursos como imagens, folhas de estilo CSS e fontes.
Instalação
pip install ironpdf dask
Gere documentos PDF usando IronPDF e Dask.
Pré-requisitos
- Certifique-se de que o Visual Studio Code esteja instalado.
- A versão 3 do Python está instalada.
Para começar, vamos criar um arquivo Python para adicionar nossos scripts.
Abra o Visual Studio Code e crie um arquivo, daskDemo.py.
Instale as bibliotecas necessárias:
pip install dask ironpdf
Em seguida, adicione o código Python abaixo para demonstrar o uso dos pacotes IronPDF e Dask do Python:
import dask
from ironpdf import *
# Apply your license key
License.LicenseKey = "key"
# Generate a synthetic timeseries DataFrame
df = dask.datasets.timeseries()
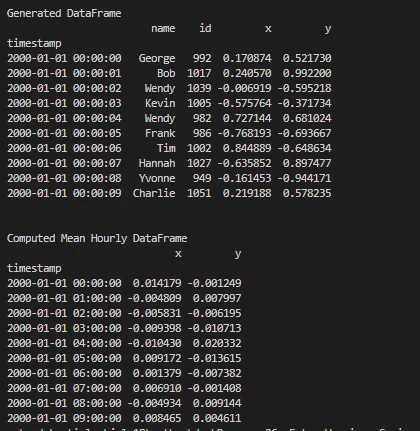
print('\nGenerated DataFrame')
print(df.head(10))
# Compute the mean hourly DataFrame
dfmean = df[["x", "y"]].resample("1h").mean().head(10)
print('\nComputed Mean Hourly DataFrame')
print(dfmean)
# Initialize the PDF renderer
renderer = ChromePdfRenderer()
# Create HTML content for the PDF
content = "<h1>Awesome Iron PDF with Dask</h1>"
# Add generated DataFrame to the content
content += "<h2>Generated DataFrame (First 10)</h2>"
rows = df.head(10)
for i in range(10):
row = rows.iloc[i]
content += f"<p>{str(row[0])}, {str(row[2])}, {str(row[3])}</p>"
# Add computed mean DataFrame to the content
content += "<h2>Computed Mean Hourly DataFrame (First 10)</h2>"
for i in range(10):
row = dfmean.iloc[i]
content += f"<p>{str(row[0])}</p>"
# Render the HTML content as PDF
pdf = renderer.RenderHtmlAsPdf(content)
# Save the PDF to a file
pdf.SaveAs("Demo IronPDF-Dask.pdf")import dask
from ironpdf import *
# Apply your license key
License.LicenseKey = "key"
# Generate a synthetic timeseries DataFrame
df = dask.datasets.timeseries()
print('\nGenerated DataFrame')
print(df.head(10))
# Compute the mean hourly DataFrame
dfmean = df[["x", "y"]].resample("1h").mean().head(10)
print('\nComputed Mean Hourly DataFrame')
print(dfmean)
# Initialize the PDF renderer
renderer = ChromePdfRenderer()
# Create HTML content for the PDF
content = "<h1>Awesome Iron PDF with Dask</h1>"
# Add generated DataFrame to the content
content += "<h2>Generated DataFrame (First 10)</h2>"
rows = df.head(10)
for i in range(10):
row = rows.iloc[i]
content += f"<p>{str(row[0])}, {str(row[2])}, {str(row[3])}</p>"
# Add computed mean DataFrame to the content
content += "<h2>Computed Mean Hourly DataFrame (First 10)</h2>"
for i in range(10):
row = dfmean.iloc[i]
content += f"<p>{str(row[0])}</p>"
# Render the HTML content as PDF
pdf = renderer.RenderHtmlAsPdf(content)
# Save the PDF to a file
pdf.SaveAs("Demo IronPDF-Dask.pdf")Explicação do código
Este trecho de código integra o Dask para manipulação de dados e o IronPDF para geração de PDFs. Isso demonstra:
- Integração Dask: Usa
dask.datasets.timeseries()para gerar um DataFrame de série temporal sintético (df). Imprime as primeiras 10 linhas (df.head(10)) e calcula a média horária do DataFrame (dfmean) com base nas colunas "x" e "y". - Uso do IronPDF: Define a chave de licença IronPDF usando
License.LicenseKey. Cria uma string HTML (content) contendo cabeçalhos e dados dos DataFrames gerados e calculados, depois renderiza este conteúdo HTML em um PDF (pdf) usandoChromePdfRenderer(), e finalmente salva o PDF como "Demo IronPDF-Dask.pdf".
Este código combina os recursos do Dask para manipulação de dados em larga escala com a funcionalidade do IronPDF para converter conteúdo HTML em um documento PDF.
Saída

Licença IronPDF
A chave de licença do IronPDF permite que os usuários experimentem seus diversos recursos antes da compra.
Insira a chave de licença no início do script antes de usar o pacote IronPDF :
from ironpdf import *
# Apply your license key
License.LicenseKey = "key"from ironpdf import *
# Apply your license key
License.LicenseKey = "key"Conclusão
Dask é uma ferramenta versátil que pode aprimorar significativamente suas capacidades de processamento de dados em Python. Ao permitir computação paralela e distribuída, possibilita trabalhar com grandes conjuntos de dados de forma eficiente e se integra perfeitamente ao seu ecossistema Python existente. IronPDF é uma poderosa biblioteca Python para criar e manipular documentos PDF usando HTML, CSS, imagens e JavaScript. Oferece funcionalidades como conversão de HTML para PDF, edição de PDF, assinatura digital e suporte multiplataforma, tornando-o adequado para diversas tarefas de geração e gerenciamento de documentos em aplicações Python.
Juntas, ambas as bibliotecas permitem que cientistas de dados realizem análises de dados avançadas e operações científicas, armazenando os resultados em formato PDF padrão usando o IronPDF.
















