
Grakn Python (Jak działa: Przewodnik dla programistów)
W dzisiejszym świecie programowania bazy danych ewoluują, aby nadążać za wymaganiami nowych aplikacji. Chociaż tradycyjne relacyjne bazy danych są nadal w użyciu, obecnie dysponujemy zaawansowanymi rozwiązaniami, takimi jak mapowanie obiektowo-relacyjne (ORM), które pozwalają programistom na interakcję z bazami danych przy użyciu abstrakcji programistycznych wyższego poziomu, zamiast polegania wyłącznie na języku SQL. Takie podejście usprawnia zarządzanie danymi i sprzyja przejrzystej organizacji kodu. Ponadto bazy danych NoSQL stały się przydatnymi narzędziami do obsługi danych nieustrukturyzowanych, szczególnie w aplikacjach do obsługi dużych zbiorów danych i analiz w czasie rzeczywistym.
Znaczący wpływ mają również bazy danych natywne dla chmury, oferujące skalowalne, niezawodne i zarządzane usługi, które zmniejszają obciążenie związane z utrzymaniem infrastruktury bazowej. Ponadto bazy danych NewSQL i graficzne łączą zalety SQL i NoSQL, oferując niezawodność relacyjnych baz danych oraz elastyczność NoSQL. To połączenie sprawia, że nadają się one do wielu nowoczesnych zastosowań. Dzięki integracji tych różnych typów baz danych z innowacyjnymi paradygmatami programowania możemy tworzyć skalowalne i adaptacyjne rozwiązania, które odpowiadają dzisiejszym wymaganiom zorientowanym na dane. Grakn, znany obecnie jako TypeDB, stanowi przykład tego trendu, obsługując zarządzanie i wyszukiwanie w grafach wiedzy. W tym artykule przyjrzymy się Grakn (TypeDB) i jego integracji z IronPDF, kluczowym narzędziem do programowego generowania i edycji plików PDF.
Czym jest Grakn?
Grakn (obecnie TypeDB), stworzony przez Grakn Labs, to baza danych grafów wiedzy przeznaczona do zarządzania i analizowania złożonych sieci danych. Wyróżnia się w modelowaniu złożonych relacji w ramach istniejących zbiorów danych i zapewnia potężne możliwości wnioskowania na podstawie przechowywanych danych. Język zapytań Grakn, Graql, pozwala na precyzyjną manipulację danymi i wyszukiwanie, umożliwiając tworzenie inteligentnych systemów, które mogą wydobywać cenne informacje ze złożonych zbiorów danych. Wykorzystując podstawowe funkcje Grakn, organizacje mogą zarządzać strukturami danych dzięki solidnej i inteligentnej reprezentacji wiedzy.
Graql, język zapytań Grakn, został specjalnie zaprojektowany do efektywnej interakcji z modelem grafu wiedzy Grakn, umożliwiając szczegółowe i zróżnicowane przekształcanie danych. Ze względu na swoją skalowalność horyzontalną i zdolność do obsługi dużych zbiorów danych, TypeDB doskonale nadaje się do zastosowań w takich dziedzinach jak finanse, opieka zdrowotna, odkrywanie leków i cyberbezpieczeństwo, gdzie zrozumienie i zarządzanie złożonymi strukturami graficznymi ma kluczowe znaczenie.
Instalacja i konfiguracja Grakn w języku Python
Instalacja Grakn
Dla programistów Pythona zainteresowanych korzystaniem z Grakn (TypeDB) niezbędna jest instalacja biblioteki typedb-driver. Ten oficjalny klient ułatwia interakcję z TypeDB. Aby zainstalować tę bibliotekę, użyj następującego polecenia pip:
pip install typedb-driverpip install typedb-driverKonfiguracja serwera TypeDB
Przed napisaniem kodu upewnij się, że serwer TypeDB działa. Postępuj zgodnie z instrukcjami instalacji i konfiguracji podanymi na stronie TypeDB dla Twojego systemu operacyjnego. Po zainstalowaniu można użyć następującego polecenia, aby uruchomić serwer TypeDB:
./typedb server./typedb serverKorzystanie z Grakn w Pythonie
Kod w języku Python do interakcji z TypeDB
W tej sekcji pokazano nawiązywanie połączenia z serwerem TypeDB, konfigurowanie schematu bazy danych oraz wykonywanie podstawowych operacji, takich jak wstawianie i pobieranie danych.
Tworzenie schematu bazy danych
W poniższym bloku kodu definiujemy strukturę bazy danych, tworząc typ o nazwie person z dwoma atrybutami: name i age. Otwieramy sesję w trybie SCHEMA, umożliwiającym modyfikacje strukturalne. Oto jak definiuje się i zatwierdza schemat:
from typedb.driver import TypeDB, SessionType, TransactionType
# Connect to TypeDB server
client = TypeDB.core_driver("localhost:1729")
# Create a database (if not already created)
database_name = "example_db"
if not client.databases().contains(database_name):
client.databases().create(database_name)
with client.session(database_name, SessionType.SCHEMA) as session:
with session.transaction(TransactionType.WRITE) as transaction:
transaction.query().define("""
define
person sub entity, owns name, owns age;
name sub attribute, value string;
age sub attribute, value long;
""")
transaction.commit()from typedb.driver import TypeDB, SessionType, TransactionType
# Connect to TypeDB server
client = TypeDB.core_driver("localhost:1729")
# Create a database (if not already created)
database_name = "example_db"
if not client.databases().contains(database_name):
client.databases().create(database_name)
with client.session(database_name, SessionType.SCHEMA) as session:
with session.transaction(TransactionType.WRITE) as transaction:
transaction.query().define("""
define
person sub entity, owns name, owns age;
name sub attribute, value string;
age sub attribute, value long;
""")
transaction.commit()Wstawianie danych
Po ustaleniu schematu skrypt wstawia dane do bazy danych. Otwieramy sesję w trybie DATA, odpowiednim do operacji na danych, i wykonujemy zapytanie insert, aby dodać nową encję person o imieniu "Alice" i wieku 30 lat:
# Insert data into the database
with client.session(database_name, SessionType.DATA) as session:
with session.transaction(TransactionType.WRITE) as transaction:
# Create a person entity
transaction.query().insert("""
insert $p isa person, has name "Alice", has age 30;
""")
transaction.commit()# Insert data into the database
with client.session(database_name, SessionType.DATA) as session:
with session.transaction(TransactionType.WRITE) as transaction:
# Create a person entity
transaction.query().insert("""
insert $p isa person, has name "Alice", has age 30;
""")
transaction.commit()Wyszukiwanie danych
Na koniec pobieramy informacje z bazy danych, wyszukując encje o nazwie "Alice". Otwieramy nową sesję w trybie DATA i inicjujemy transakcję odczytu za pomocą TransactionType.READ. Wyniki są przetwarzane w celu wyodrębnienia i wyświetlenia imienia oraz wieku:
# Query the data from the database
with client.session(database_name, SessionType.DATA) as session:
with session.transaction(TransactionType.READ) as transaction:
# Query entities where the person has the name 'Alice'
results = transaction.query().match("""
match
$p isa person, has name "Alice";
$p has name $n, has age $a;
get;
""")
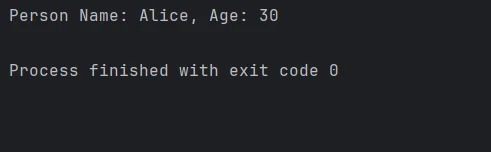
for result in results:
person_name = result.get("n").get_value()
person_age = result.get("a").get_value()
print(f"Person Name: {person_name}, Age: {person_age}")# Query the data from the database
with client.session(database_name, SessionType.DATA) as session:
with session.transaction(TransactionType.READ) as transaction:
# Query entities where the person has the name 'Alice'
results = transaction.query().match("""
match
$p isa person, has name "Alice";
$p has name $n, has age $a;
get;
""")
for result in results:
person_name = result.get("n").get_value()
person_age = result.get("a").get_value()
print(f"Person Name: {person_name}, Age: {person_age}")Wynik
Zamykanie połączenia z klientem
Aby poprawnie zwolnić zasoby i zapobiec dalszym interakcjom z serwerem TypeDB, zamknij połączenie klienta za pomocą client.close():
# Close the client connection
client.close()# Close the client connection
client.close()Przedstawiamy IronPDF
IronPDF for Python to potężna biblioteka służąca do programowego tworzenia i edycji plików PDF. Zapewnia kompleksową funkcjonalność do tworzenia plików PDF z HTML, łączenia plików PDF oraz dodawania adnotacji do istniejących dokumentów PDF. IronPDF umożliwia również konwersję treści HTML lub internetowych na wysokiej jakości pliki PDF, co czyni go idealnym wyborem do generowania raportów, faktur i innych dokumentów o stałym układzie.
Biblioteka oferuje zaawansowane funkcje, takie jak ekstrakcja treści, szyfrowanie dokumentów i dostosowywanie układu strony. Dzięki integracji IronPDF z aplikacjami w języku Python programiści mogą zautomatyzować procesy tworzenia dokumentów i zwiększyć ogólne możliwości obsługi plików PDF.
Instalacja biblioteki IronPDF
Aby włączyć funkcjonalność IronPDF w Pythonie, zainstaluj bibliotekę za pomocą pip:
pip install ironpdfpip install ironpdfIntegracja Grakn TypeDB z IronPDF
Łącząc TypeDB i IronPDF w środowisku Python, programiści mogą efektywnie generować i zarządzać dokumentacją PDF w oparciu o złożone dane strukturalne w bazie danych Grakn (TypeDB). Oto przykład integracji:
from typedb.driver import TypeDB, SessionType, TransactionType
from ironpdf import *
import warnings
# Suppress potential warnings
warnings.filterwarnings('ignore')
# Replace with your own license key
License.LicenseKey = "YOUR LICENSE KEY GOES HERE"
# Initialize data list
data = []
# Connect to TypeDB server
client = TypeDB.core_driver("localhost:1729")
# Query the data from the database
with client.session(database_name, SessionType.DATA) as session:
with session.transaction(TransactionType.READ) as transaction:
# Fetch details of persons named 'Alice'
results = transaction.query().match("""
match
$p isa person, has name "Alice";
$p has name $n, has age $a;
get;
""")
for result in results:
person_name = result.get("n").get_value()
person_age = result.get("a").get_value()
data.append({"name": person_name, "age": person_age})
# Close the client connection
client.close()
# Create a PDF from HTML content
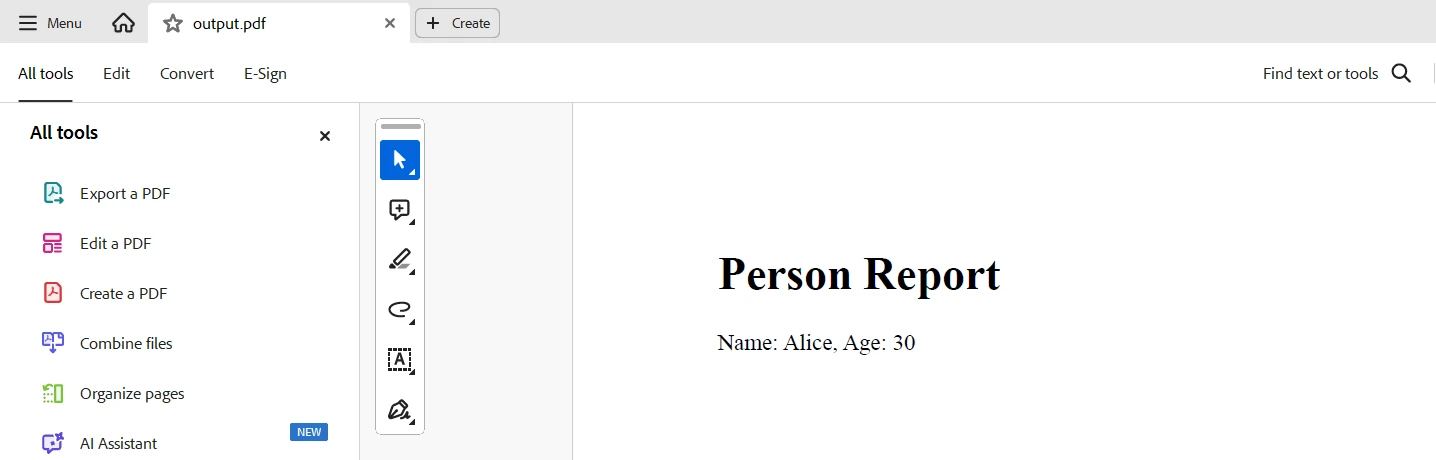
html_to_pdf = ChromePdfRenderer()
content = "<h1>Person Report</h1>"
for item in data:
content += f"<p>Name: {item['name']}, Age: {item['age']}</p>"
# Render the HTML content as a PDF
pdf_document = html_to_pdf.RenderHtmlAsPdf(content)
# Save the PDF to a file
pdf_document.SaveAs("output.pdf")from typedb.driver import TypeDB, SessionType, TransactionType
from ironpdf import *
import warnings
# Suppress potential warnings
warnings.filterwarnings('ignore')
# Replace with your own license key
License.LicenseKey = "YOUR LICENSE KEY GOES HERE"
# Initialize data list
data = []
# Connect to TypeDB server
client = TypeDB.core_driver("localhost:1729")
# Query the data from the database
with client.session(database_name, SessionType.DATA) as session:
with session.transaction(TransactionType.READ) as transaction:
# Fetch details of persons named 'Alice'
results = transaction.query().match("""
match
$p isa person, has name "Alice";
$p has name $n, has age $a;
get;
""")
for result in results:
person_name = result.get("n").get_value()
person_age = result.get("a").get_value()
data.append({"name": person_name, "age": person_age})
# Close the client connection
client.close()
# Create a PDF from HTML content
html_to_pdf = ChromePdfRenderer()
content = "<h1>Person Report</h1>"
for item in data:
content += f"<p>Name: {item['name']}, Age: {item['age']}</p>"
# Render the HTML content as a PDF
pdf_document = html_to_pdf.RenderHtmlAsPdf(content)
# Save the PDF to a file
pdf_document.SaveAs("output.pdf")Ten kod pokazuje, jak używać TypeDB i IronPDF w Pythonie do wyciągania danych z bazy danych TypeDB i generowania raportu PDF. Łączy się z lokalnym serwerem TypeDB, pobiera encje o nazwie "Alice" oraz odzyskuje ich imiona i wiek. Wyniki są następnie wykorzystywane do tworzenia treści HTML, która jest konwertowana na dokument PDF przy użyciu funkcji ChromePdfRenderer biblioteki IronPDF i zapisywana jako "output.pdf".
Wynik
Licencjonowanie
Do usunięcia znaków wodnych z wygenerowanych plików PDF wymagany jest klucz licencyjny. Możesz zarejestrować się na bezpłatną wersję próbną pod tym linkiem. Należy pamiętać, że do rejestracji nie jest wymagana karta kredytowa; Do skorzystania z bezpłatnej wersji próbnej wystarczy podać adres e-mail.
Wnioski
Grakn (obecnie TypeDB) zintegrowany z IronPDF zapewnia solidne rozwiązanie do zarządzania i analizowania dużych ilości danych z dokumentów PDF. Dzięki możliwościom IronPDF w zakresie ekstrakcji i manipulacji danymi oraz biegłości Grakn w modelowaniu złożonych relacji i wnioskowaniu, można przekształcić nieustrukturyzowane dane dokumentów w ustrukturyzowane informacje, które można przeszukiwać.
Ta integracja ułatwia pozyskiwanie cennych informacji z plików PDF, zwiększając możliwości wyszukiwania i analizy dzięki większej precyzji. Łącząc zaawansowane funkcje zarządzania danymi Grakn z funkcjami przetwarzania plików PDF IronPDF, można opracować bardziej wydajne sposoby obsługi informacji, co pozwoli na podejmowanie lepszych decyzji i uzyskanie głębszego wglądu w złożone zbiory danych. IronSoftware oferuje również szereg bibliotek ułatwiających tworzenie aplikacji na wielu systemach operacyjnych i platformach, w tym Windows, Android, macOS, Linux i innych.
















