
scikit-image Python (Jak działa: Przewodnik dla programistów)
Scikit-image to zbiór algorytmów przeznaczonych do przetwarzania obrazów w języku Python. Jest on dostępny bezpłatnie i bez ograniczeń, oferując wysokiej jakości, recenzowany kod pochodzący od aktywnej społeczności wolontariuszy. Projekt Scikit-image rozpoczął się w Google w 2009 roku w ramach programu Google Summer Code pod opieką Stefana van der Walta i innych współpracowników Scikit-image. Celem było stworzenie biblioteki Python do przetwarzania obrazów, która byłaby łatwa w użyciu, wydajna i rozszerzalna do zastosowań akademickich i przemysłowych. W tym artykule zapoznamy się z biblioteką obrazowania Scikit-image dla języka Python oraz biblioteką do generowania plików PDF firmy IronSoftware o nazwie IronPDF.
Pierwsze kroki
Aby dowiedzieć się więcej o Scikit-image, odwiedź oficjalną stronę internetową. Ponadto Data Carpentry oferuje świetną lekcję na temat przetwarzania obrazów w języku Python przy użyciu Scikit.
Instalacja za pomocą pip
- Upewnij się, że masz zainstalowany Python (co najmniej wersja 3.10).
Otwórz terminal lub wiersz poleceń.
- Zaktualizuj pip:
python -m pip install -U pippython -m pip install -U pipSHELL- Zainstaluj scikit-image za pomocą pip:
python -m pip install -U scikit-imagepython -m pip install -U scikit-imageSHELL- Aby uzyskać dostęp do przykładowych zbiorów danych, użyj:
python -m pip install -U scikit-image[data]python -m pip install -U scikit-image[data]SHELL- W przypadku dodatkowych pakietów naukowych, w tym z możliwością przetwarzania równoległego:
python -m pip install -U scikit-image[optional]python -m pip install -U scikit-image[optional]SHELL
Podstawowy przykład
import skimage.io
import matplotlib.pyplot as plt
# Load an image from file
image = skimage.io.imread(fname='land.jpg')
# Display the image
plt.imshow(image)
plt.show()import skimage.io
import matplotlib.pyplot as plt
# Load an image from file
image = skimage.io.imread(fname='land.jpg')
# Display the image
plt.imshow(image)
plt.show()Filtry
import skimage as ski
# Load a sample image from the scikit-image default collection
image = ski.data.coins()
# Apply a Sobel filter to detect edges
edges = ski.filters.sobel(image)
# Display the edges
ski.io.imshow(edges)
ski.io.show()import skimage as ski
# Load a sample image from the scikit-image default collection
image = ski.data.coins()
# Apply a Sobel filter to detect edges
edges = ski.filters.sobel(image)
# Display the edges
ski.io.imshow(edges)
ski.io.show()Scikit-image, często skracane do skimage, to potężna biblioteka języka Python przeznaczona do zadań związanych z przetwarzaniem obrazów. Jest oparty na tablicach NumPy, SciPy i matplotlib oraz zapewnia różne funkcje i algorytmy do manipulowania i analizowania obrazów. Symbol skimage.data.coins() służy do uzyskania dostępu do przykładowych obrazów z biblioteki. skimage.filters zapewnia dostęp do wbudowanych filtrów i funkcji użytkowych.
Najważniejsze cechy Scikit-image
1. Filtrowanie obrazów i wykrywanie krawędzi
from skimage import io, filters
# Load an image
image = io.imread('image.jpg')
# Apply Gaussian blur
blurred_image = filters.gaussian(image, sigma=1.0)
# Apply Sobel edge detection
edges = filters.sobel(image)
# Display the original image, blurred image, and edges
io.imshow_collection([image, blurred_image, edges])
io.show()from skimage import io, filters
# Load an image
image = io.imread('image.jpg')
# Apply Gaussian blur
blurred_image = filters.gaussian(image, sigma=1.0)
# Apply Sobel edge detection
edges = filters.sobel(image)
# Display the original image, blurred image, and edges
io.imshow_collection([image, blurred_image, edges])
io.show()Wynik
2. Wyodrębnianie cech za pomocą HOG (histogram zorientowanych gradientów)
from skimage import io, color, feature
# Load an example image and convert to grayscale
image = io.imread('image.jpg')
gray_image = color.rgb2gray(image)
# Compute HOG features and visualize them
hog_features, hog_image = feature.hog(gray_image, visualize=True)
# Display the original image and the HOG image
io.imshow_collection([image, gray_image, hog_image])
io.show()from skimage import io, color, feature
# Load an example image and convert to grayscale
image = io.imread('image.jpg')
gray_image = color.rgb2gray(image)
# Compute HOG features and visualize them
hog_features, hog_image = feature.hog(gray_image, visualize=True)
# Display the original image and the HOG image
io.imshow_collection([image, gray_image, hog_image])
io.show()Wynik
3. Transformacja geometryczna – zmiana rozmiaru i obrót
from skimage import io, transform
# Load an image
image = io.imread('image.jpg')
# Resize image by dividing its dimensions by 2
resized_image = transform.resize(image, (image.shape[0] // 2, image.shape[1] // 2))
# Rotate image by 45 degrees
rotated_image = transform.rotate(image, angle=45)
# Display the original image, resized image, and rotated image
io.imshow_collection([image, resized_image, rotated_image])
io.show()from skimage import io, transform
# Load an image
image = io.imread('image.jpg')
# Resize image by dividing its dimensions by 2
resized_image = transform.resize(image, (image.shape[0] // 2, image.shape[1] // 2))
# Rotate image by 45 degrees
rotated_image = transform.rotate(image, angle=45)
# Display the original image, resized image, and rotated image
io.imshow_collection([image, resized_image, rotated_image])
io.show()Wynik
4. Usuwanie szumów z obrazów za pomocą filtra całkowitej zmienności
from skimage import io, restoration
# Load a noisy image
image = io.imread('image.jpg')
# Apply total variation denoising
denoised_image = restoration.denoise_tv_chambolle(image, weight=0.1)
# Display the noisy image and the denoised image
io.imshow_collection([image, denoised_image])
io.show()from skimage import io, restoration
# Load a noisy image
image = io.imread('image.jpg')
# Apply total variation denoising
denoised_image = restoration.denoise_tv_chambolle(image, weight=0.1)
# Display the noisy image and the denoised image
io.imshow_collection([image, denoised_image])
io.show()Wynik
Więcej informacji na temat przetwarzania obrazów i tablic NumPy można znaleźć na oficjalnej stronie.
Przedstawiamy IronPDF
IronPDF to solidna biblioteka w języku Python, zaprojektowana do obsługi tworzenia, edycji i podpisywania dokumentów PDF przy użyciu HTML, CSS, obrazów i JavaScript. Priorytetem jest wydajność, a działanie odbywa się przy minimalnym zużyciu pamięci. Najważniejsze cechy to:
Konwersja HTML do PDF: Konwertuj pliki HTML, ciągi znaków HTML i adresy URL na dokumenty PDF, wykorzystując funkcje takie jak renderowanie stron internetowych za pomocą renderera PDF przeglądarki Chrome.
Obsługa wielu platform: Kompatybilność z Python 3+ w systemach Windows, Mac, Linux oraz na różnych platformach chmurowych. IronPDF jest również dostępny dla środowisk .NET, Java, Python i Node.js.
Edycja i podpisywanie: dostosowuj właściwości plików PDF, stosuj środki bezpieczeństwa, takie jak hasła i uprawnienia, oraz płynnie stosuj podpisy cyfrowe.
Szablony stron i ustawienia: Twórz układy PDF z takimi funkcjami, jak nagłówki, stopki, numery stron, regulowane marginesy, niestandardowe rozmiary papieru i responsywne projekty.
- Zgodność ze standardami: Ściśle przestrzega standardów PDF, takich jak PDF/A i PDF/UA, zapewnia zgodność z kodowaniem znaków UTF-8 oraz sprawnie zarządza zasobami, takimi jak obrazy, arkusze stylów CSS i czcionki.
Instalacja
pip install ironpdf
pip install scikit-imagepip install ironpdf
pip install scikit-imageGenerowanie dokumentów PDF przy użyciu IronPDF i Scikit Image
Wymagania wstępne
- Upewnij się, że Visual Studio Code jest zainstalowane jako edytor kodu
- Zainstalowano Python w wersji 3
Na początek utwórzmy plik w języku Python, aby dodać nasze skrypty.
Otwórz Visual Studio Code i utwórz plik scikitDemo.py.
Zainstaluj niezbędne biblioteki:
pip install scikit-image
pip install ironpdfpip install scikit-image
pip install ironpdfNastępnie dodaj poniższy kod w języku Python, aby zademonstrować wykorzystanie pakietów IronPDF i scikit-image.
from skimage import io, filters
from ironpdf import *
# Apply your license key
License.LicenseKey = "YOUR_LICENSE_KEY"
# Load an image
image = io.imread('image.jpg')
# Apply Gaussian blur
blurred_image = filters.gaussian(image, sigma=1.0)
# Apply Sobel edge detection
edges = filters.sobel(image)
# Save the results to a file
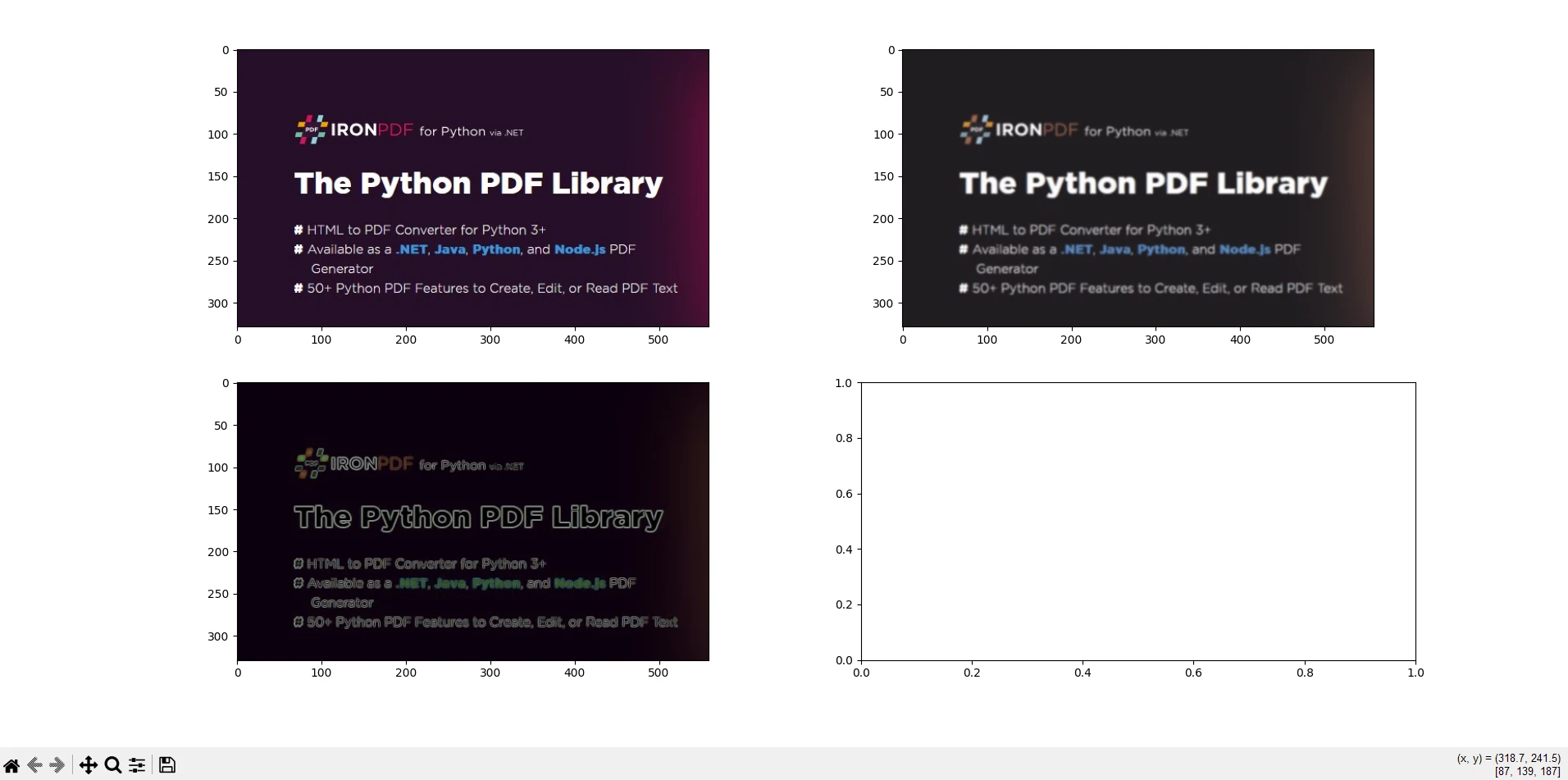
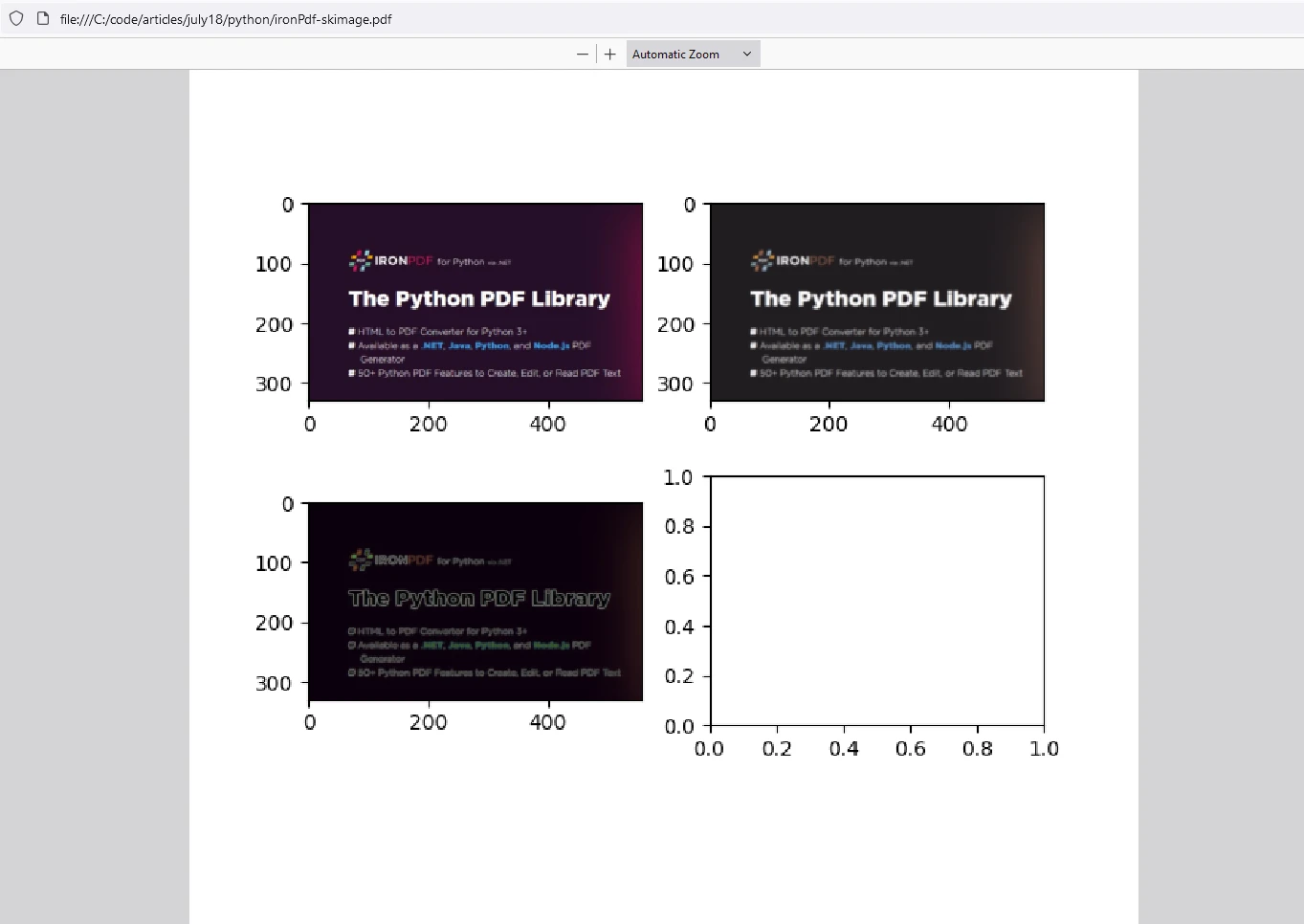
io.imshow_collection([image, blurred_image, edges]).savefig('ironPdf-skimage.png')
# Convert the saved image to a PDF document
ImageToPdfConverter.ImageToPdf("ironPdf-skimage.png").SaveAs("ironPdf-skimage.pdf")
# Display the images
io.show()from skimage import io, filters
from ironpdf import *
# Apply your license key
License.LicenseKey = "YOUR_LICENSE_KEY"
# Load an image
image = io.imread('image.jpg')
# Apply Gaussian blur
blurred_image = filters.gaussian(image, sigma=1.0)
# Apply Sobel edge detection
edges = filters.sobel(image)
# Save the results to a file
io.imshow_collection([image, blurred_image, edges]).savefig('ironPdf-skimage.png')
# Convert the saved image to a PDF document
ImageToPdfConverter.ImageToPdf("ironPdf-skimage.png").SaveAs("ironPdf-skimage.pdf")
# Display the images
io.show()Wyjaśnienie kodu
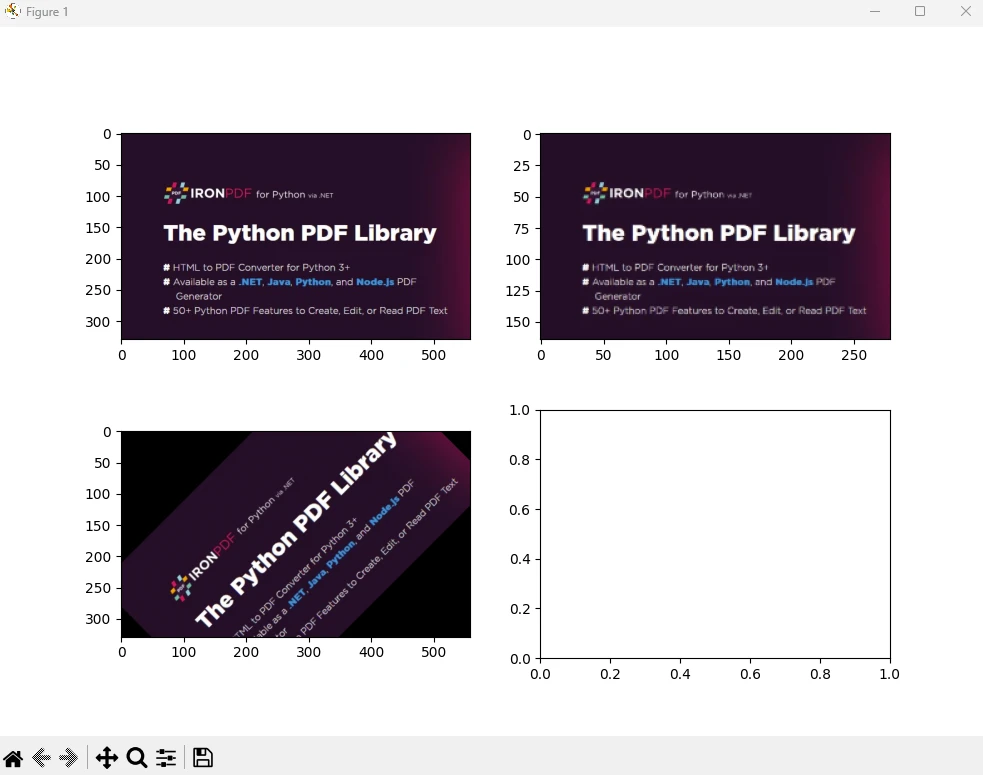
Ten fragment kodu pokazuje, jak używać scikit-image (skimage) i IronPDF razem, aby przetworzyć obraz i przekonwertować wyniki na dokument PDF. Oto wyjaśnienie poszczególnych części:
Instrukcje importu: Importuje niezbędne funkcje z biblioteki scikit-image do ładowania i filtrowania obrazów oraz importuje funkcjonalność IronPDF.
Stosowanie klucza licencyjnego: Ustawia klucz licencyjny dla IronPDF. Ten krok jest wymagany do korzystania z funkcji IronPDF.
Ładowanie i przetwarzanie obrazu: Ładuje obraz o nazwie
'image.jpg'przy użyciu funkcjiio.imreadbiblioteki scikit-image. Następnie stosuje rozmycie gaussowskie do załadowanego obrazu przy użyciufilters.gaussianz wartością sigma wynoszącą 1,0 oraz stosuje wykrywanie krawędzi Sobela do załadowanego obrazu przy użyciufilters.sobel.Wyświetlanie i zapisywanie wyników:
io.imshow_collection([image, blurred_image, edges]).savefig('ironPdf-skimage.png'): Zapisuje zbiór obrazów (oryginalny, rozmyty i krawędzie) jako'ironPdf-skimage.png'.Konwersja obrazu do formatu PDF:
ImageToPdfConverter.ImageToPdf("ironPdf-skimage.png").SaveAs("ironPdf-skimage.pdf"): Konwertuje zapisany obraz PNG na dokument PDF przy użyciu funkcji IronPDF.- Wyświetlanie obrazów:
io.show(): Wyświetla obrazy w oknie graficznym.
Ten fragment kodu łączy możliwości biblioteki scikit-image do przetwarzania obrazów oraz biblioteki IronPDF do konwersji przetworzonych obrazów na dokumenty PDF. Pokazuje on ładowanie obrazu, zastosowanie rozmycia gaussowskiego i wykrywania krawędzi Sobela, zapisanie ich jako pliku PNG, konwersję pliku PNG do formatu PDF przy użyciu IronPDF oraz wyświetlenie przetworzonych obrazów. Ta integracja jest przydatna w zadaniach, w których obrazy muszą być przetwarzane, analizowane i dokumentowane w formacie PDF, takich jak badania naukowe, raporty z analizy obrazów lub zautomatyzowane procesy generowania dokumentów.
Wynik
Licencja IronPDF
IronPDF działa na kluczu licencyjnym dla języka Python. IronPDF for Python oferuje bezplatną licencję probną, aby umożliwić użytkownikom zapoznanie się z jego rozbudowanymi funkcjami przed zakupem.
Umieść klucz licencyjny na początku skryptu przed użyciem pakietu IronPDF:
from ironpdf import *
# Apply your license key
License.LicenseKey = "YOUR_LICENSE_KEY"from ironpdf import *
# Apply your license key
License.LicenseKey = "YOUR_LICENSE_KEY"Wnioski
scikit-image umożliwia programistom Pythona efektywne wykonywanie zadań związanych z obrazami. Niezależnie od tego, czy pracujesz nad wizją komputerową, obrazowaniem medycznym czy projektami artystycznymi, ten pakiet spełni Twoje oczekiwania. scikit-image to wszechstronna i potężna biblioteka do przetwarzania obrazów w języku Python, oferująca szeroki zakres funkcji i algorytmów do zadań takich jak filtrowanie, segmentacja, ekstrakcja cech i transformacje geometryczne. Jego płynna integracja z innymi bibliotekami naukowymi sprawia, że jest to preferowany wybór dla naukowców, programistów i inżynierów pracujących z aplikacjami do analizy obrazu i wizji komputerowej.
IronPDF to biblioteka języka Python, która ułatwia tworzenie, edycję i manipulowanie dokumentami PDF w aplikacjach napisanych w języku Python. Oferuje takie funkcje, jak generowanie plików PDF z różnych źródeł, takich jak HTML, obrazy lub istniejące pliki PDF. Ponadto IronPDF obsługuje takie zadania, jak łączenie lub dzielenie dokumentów PDF, dodawanie adnotacji, znaków wodnych lub podpisów cyfrowych, wyodrębnianie tekstu lub obrazów z plików PDF oraz zarządzanie właściwościami dokumentów, takimi jak metadane i ustawienia zabezpieczeń. Biblioteka ta zapewnia wydajny sposób programowego wykonywania zadań związanych z plikami PDF, dzięki czemu nadaje się do zastosowań wymagających generowania dokumentów, tworzenia raportów lub funkcji zarządzania dokumentami.
W połączeniu z obiema bibliotekami użytkownicy mogą pracować z obrazami, efektywnie je przetwarzać i przechowywać wyniki w dokumentach PDF do celów archiwizacji.
















