
Najlepsze biblioteki Python do przetwarzania PDF
Programowanie w języku Python oferuje wiele bibliotek Python do niemal każdego zadania, jakie można sobie wyobrazić. Od przetwarzania języka naturalnego po analizę tekstu — ekosystem jest bardzo dynamiczny. Jednak w przypadku plików PDF, takich jak generowanie dokumentów PDF, wybór bibliotek napisanych wyłącznie w języku Python może być przytłaczający. Znalezienie najlepszej biblioteki plików PDF dla języka Python ma kluczowe znaczenie dla analityków danych, programistów oraz wszystkich osób, które chcą edytować pliki PDF lub tworzyć dokumenty w tym formacie.
W tym artykule porównamy trzy biblioteki do przetwarzania plików PDF napisane w czystym Pythonie: IronPDF, PyPDF2 i ReportLab. Przyjrzymy się ich funkcjom, zaletom i wadom oraz opcjom licencyjnym, aby pomóc Ci podjąć świadomą decyzję dotyczącą pisania plików PDF w języku Python.
IronPDF — nowoczesna biblioteka PDF dla języka Python
 IronPDF is a pure Python PDF library that empowers developers to create, manipulate, and process PDF files with or without structured data effortlessly. Dzięki IronPDF możesz tworzyć pliki PDF od podstaw, łączyć różne typy plików PDF, nakładać tekst i obrazy, a nawet wyodrębniać kluczowe dane. Zaprojektowany z myślą o szerokim zakresie zadań, IronPDF jest kompleksowym narzędziem i jedną z popularnych bibliotek Python dla każdego, kto chce zarządzać dokumentami PDF przy użyciu języka programowania Python.
IronPDF is a pure Python PDF library that empowers developers to create, manipulate, and process PDF files with or without structured data effortlessly. Dzięki IronPDF możesz tworzyć pliki PDF od podstaw, łączyć różne typy plików PDF, nakładać tekst i obrazy, a nawet wyodrębniać kluczowe dane. Zaprojektowany z myślą o szerokim zakresie zadań, IronPDF jest kompleksowym narzędziem i jedną z popularnych bibliotek Python dla każdego, kto chce zarządzać dokumentami PDF przy użyciu języka programowania Python.
Zaprojektowany z myślą o wszechstronności, IronPDF opiera się na silniku przeglądarki internetowej Chromium. Ta technologia pozwala na dokładne renderowanie HTML i CSS, umożliwiając programistom konwersję skomplikowanych stron internetowych z dynamiczną treścią i elementami interaktywnymi na dokumenty PDF o wysokiej jakości.
Biblioteka jest spakowana jako pakiet Python i można ją łatwo zainstalować za pomocą pip. Po dodaniu jako zależność, integracja IronPDF z projektem Python staje się dziecinnie prosta. Co więcej, IronPDF oferuje obszerną dokumentację, stanowiącą skarbnicę zasobów, takich jak samouczki, Dokumentacja API oraz kompleksową bazę wiedzy, które pomogą w pełni wykorzystać możliwości biblioteki.
IronPDF Pros & Cons
Zalety
Bogactwo funkcji: Pod względem funkcjonalności IronPDF znacznie przewyższa wiele innych bibliotek PDF dla języka Python. Oferuje różne funkcje do tworzenia plików PDF opartych na danych, edycji i manipulacji plikami PDF. Obejmuje to między innymi obsługę wielu standardów i formatów PDF oraz unikalną możliwość konwersji HTML do PDF.
Łatwość użytkowania: Wystarczy kilka wierszy kodu w języku Python, aby generować dokumenty PDF, konwertować pliki PDF do formatów pośrednich, wyodrębniać tekst i wykonywać wiele innych czynności.
Wysoki stopień dostosowania: Biblioteka oferuje wiele opcji przekształcania plików PDF, od obracania stron PDF po konwersję do różnych formatów danych.
- Kompatybilność: Chociaż niniejszy artykuł skupia się na możliwościach IronPDF w języku programowania Python, warto zauważyć, że IronPDF jest również dostępny dla programistów .NET i Java. Dostępność w wielu językach sprawia, że jest to wszechstronny wybór dla zespołów pracujących nad projektami wykorzystującymi wiele technologii.
Wady
Cena: IronPDF jest biblioteką płatną, co może stanowić ograniczenie dla małych projektów lub niezależnych programistów.
- Krzywa uczenia się: Chociaż narzędzie jest bogate w funkcje, zapoznanie się ze wszystkimi jego możliwościami może zająć trochę czasu.
Licencjonowanie
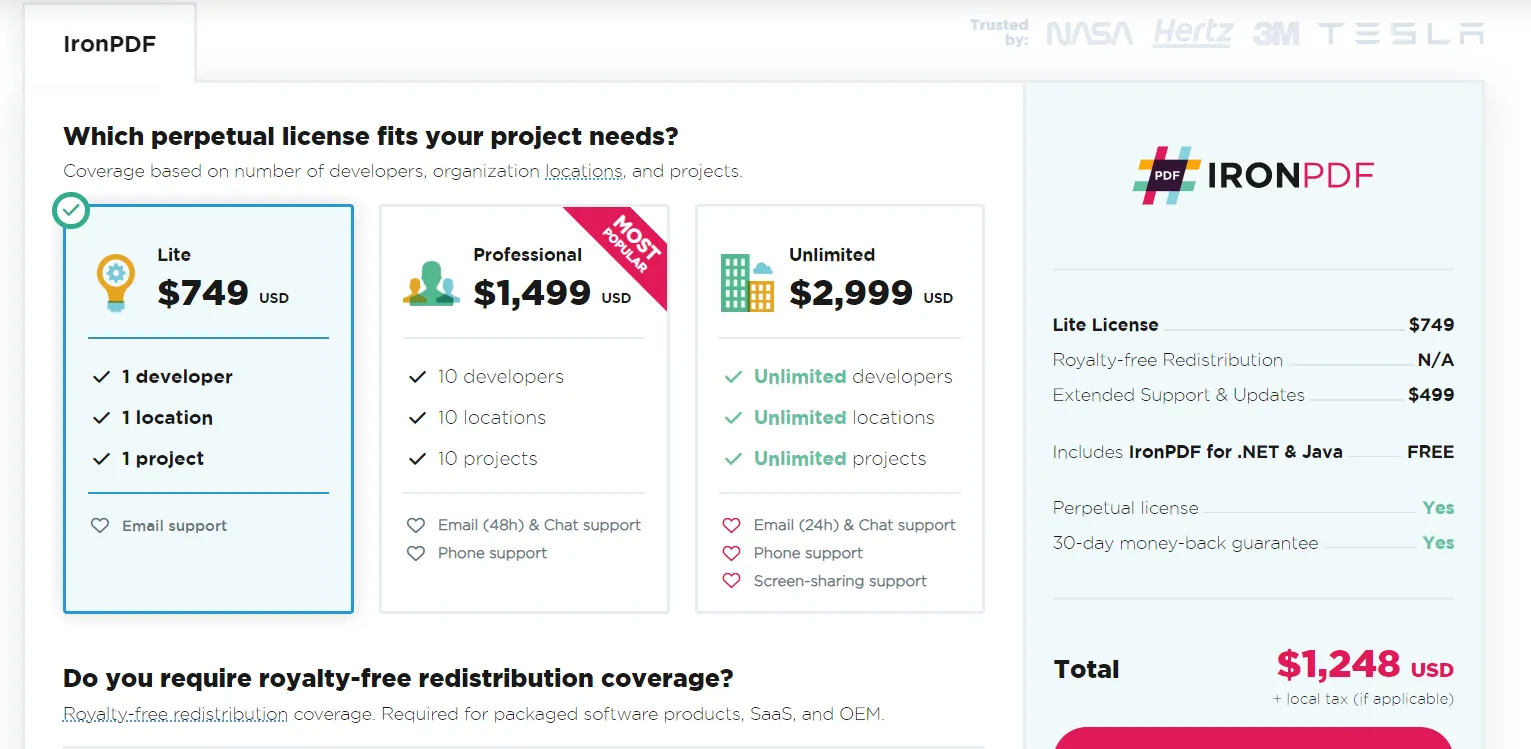
IronPDF offers a commercial license, which starts at $799 for a single developer license. Niniejsza licencja przyznaje programistom prawo do korzystania z IronPDF w wielu aplikacjach internetowych, desktopowych lub serwerowych. Ponadto ta licencja obejmuje bezpłatne aktualizacje i wsparcie techniczne przez rok, co pozwala być na bieżąco z najnowszymi funkcjami i ulepszeniami.
IronPDF oferuje bezpłatną wersję próbną, aby umożliwić programistom przetestowanie rozwiązania. W tym okresie można ocenić wszystkie funkcje, od generowania dokumentów PDF opartych na danych i wyodrębniania tekstu po integrację bibliotek do analizy tekstu. Wersja próbna zawiera wszystkie funkcje licencji komercyjnej, co pozwala w pełni zrozumieć, w co inwestujesz.
PyPDF2 – lekki mistrz szybkiego i łatwego przetwarzania plików PDF
PyPDF2 oferuje bardziej minimalistyczne podejście niż inne biblioteki PDF dla języka Python, ale niech jego rozmiar Cię nie zmyli. Zaprojektowany z myślą o programistach Pythona, którzy muszą wykonywać zadania związane z plikami PDF bez zbędnych dodatków, PyPDF2 koncentruje się na zapewnieniu najczęściej wymaganych funkcji, takich jak dzielenie, łączenie i wyodrębnianie tekstu.
Zalety
Niewielkie obciążenie: PyPDF2 jest lekki i łatwo integruje się z każdym środowiskiem Python.
Wszechstronność: Dzięki funkcjom obejmującym wszystko, od dzielenia stron PDF i łączenia plików PDF po wyodrębnianie tekstu, jest to wszechstronne narzędzie do prostych zadań.
- Bezpłatne: bez żadnych zobowiązań; PyPDF2 jest całkowicie darmowy, co sprawia, że świetnie nadaje się do małych projektów.
Wady
Ograniczone możliwości dostosowywania: PyPDF2 nie oferuje opcji dostosowywania do generowania dokumentów PDF opartych na danych.
- Brak wbudowanej analizy tekstu: Do analizy danych tekstowych wymagana jest ręczna integracja z innymi bibliotekami analitycznymi.
Licencjonowanie
PyPDF2 jest dystrybuowany na licencji MIT, liberalnej licencji na oprogramowanie wolne. Oznacza to, że możesz używać, modyfikować i rozpowszechniać bibliotekę nawet w celach komercyjnych. Licencja MIT pozwala na używanie PyPDF2 w dowolnym projekcie bez obaw o koszty lub ograniczenia.
Chociaż PyPDF2 jest darmowy, warto zauważyć, że nie oferuje on oficjalnego wsparcia ani regularnych aktualizacji, które są dostępne w ramach licencji komercyjnej, takiej jak IronPDF. Niemniej jednak szerokie wsparcie społeczności często może wypełnić tę lukę.
ReportLab
ReportLab jest niczym wielki mistrz bibliotek PDF dla języka Python, obecny na rynku od dziesięcioleci. Z wiekiem przychodzi doświadczenie, a firma ReportLab od dawna jest liderem w dostarczaniu szerokiego zestawu funkcji związanych z plikami PDF, od generowania złożonych układów danych tabelarycznych po zaawansowane elementy graficzne. Jeśli szukasz biblioteki o sprawdzonej skuteczności i wielu funkcjach, warto poważnie rozważyć ReportLab.
Zalety
Bogactwo funkcji: ReportLab to potęga funkcji, od obsługi danych tabelarycznych po wbudowywanie elementów graficznych w pliki PDF.
Wsparcie społeczności: Długoletnia obecność na rynku oznacza bogatą społeczność użytkowników i dostępność licznych samouczków.
- Integracja z narzędziami do analizy tekstu: Podobnie jak IronPDF, ReportLab może integrować się z bibliotekami do analizy tekstu w celu zaawansowanej manipulacji danymi tekstowymi.
Wady
Złożoność: Bogaty zestaw funkcji może onieśmielać początkujących użytkowników.
- Mniej nowoczesny interfejs: Chociaż API jest solidne, jest mniej intuicyjne niż niektóre nowoczesne rozwiązania, takie jak IronPDF.
Licencjonowanie
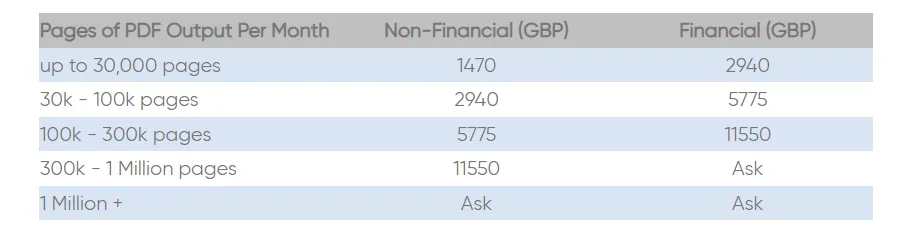
ReportLab stosuje unikalne podejście do licencjonowania dzięki licencjom ReportLab PLUS, które są dostępne w ramach rocznej umowy leasingowej. W przeciwieństwie do innych modeli licencyjnych, w których opłaty są naliczane na podstawie liczby instalacji oprogramowania, opłaty ReportLab są ustalane na podstawie liczby stron PDF generowanych każdego miesiąca. Model ten pozwala na uruchamianie wielu kopii oprogramowania w ramach organizacji, o ile nie przekroczysz zakupionego limitu użytkowania.
Oto krótkie podsumowanie struktury cenowej:
- Do 30 000 stron: 1470 GBP dla organizacji niefinansowych, 2940 GBP dla organizacji finansowych
- 30 000–100 000 stron: 2940 GBP dla organizacji niefinansowych, 5775 GBP dla organizacji finansowych
- 100 000–300 000 stron: 5775 GBP dla organizacji niefinansowych, 11 550 GBP dla organizacji finansowych
- 300 000 – 1 milion stron: 11 550 GBP dla organizacji niefinansowych, indywidualne wyceny dla organizacji finansowych
- Ponad 1 milion stron: indywidualne wyceny zarówno dla organizacji niefinansowych, jak i finansowych
Wnioski
Chociaż wszystkie trzy biblioteki oferują cenne funkcje dla każdego, kto chce przetwarzać pliki PDF, IronPDF wyróżnia się łatwością obsługi, możliwościami opartymi na danych oraz integracją z analizą tekstu. Mimo że jest to biblioteka płatna, jej zakres funkcjonalności jest wart inwestycji, zwłaszcza dla firm lub analityków danych zajmujących się złożonymi zadaniami przetwarzania plików PDF.
Jeśli więc szukasz biblioteki PDF dla języka Python, która łączy zaawansowane funkcje z łatwością obsługi, IronPDF jest najlepszym wyborem. Dzięki niej można bez wysiłku manipulować plikami PDF, konwertować je do różnych formatów i wykonywać wiele innych czynności, co czyni ją najlepszą biblioteką Python do kompleksowego przetwarzania plików PDF.
















