
Jak dodawać lub usuwać strony PDF używając Python
W tym artykule pokażemy, jak dodawać lub usuwać strony PDF za pomocą języka Python i biblioteki PDF o nazwie IronPDF for Python.
1. IronPDF for Python
IronPDF to wiodąca na rynku biblioteka PDF dla języka Python, która zapewnia programistom możliwość łatwego generowania, modyfikowania i pracy z dokumentami PDF w ich aplikacjach. Dzięki IronPDF programiści mogą płynnie zintegrować funkcjonalność PDF ze swoimi projektami w języku Python, niezależnie od tego, czy chodzi o tworzenie dynamicznych raportów, generowanie faktur, czy konwersję treści internetowych do plików PDF. Ta biblioteka oferuje przyjazny dla użytkownika i wydajny sposób obsługi zadań związanych z plikami PDF, umożliwiając łatwe tworzenie i edycję plików PDF.
Niezależnie od tego, czy tworzysz aplikacje internetowe, oprogramowanie desktopowe, czy automatyzujesz przepływ dokumentów, IronPDF jest cennym narzędziem, które umożliwia pracę z plikami PDF w środowisku Python, co czyni go niezbędnym dodatkiem do zestawu narzędzi każdego programisty. W tym przewodniku wprowadzającym omówimy kluczowe funkcje i możliwości biblioteki IronPDF for Python. Korzystając z IronPDF, programiści mogą łączyć kilka plików PDF w jeden dokument, wyodrębniać tekst z określonej strony, dodawać znaki wodne oraz wykonywać inne operacje, takie jak usuwanie stron, usuwanie pustych stron, obracanie stron, dodawanie stron i odczytywanie plików PDF.
2. Instalacja IronPDF
Aby zainstalować IronPDF, wystarczy otworzyć PyCharm lub dowolny inny kompilator języka Python, a następnie utworzyć nowy projekt w języku Python lub otworzyć istniejący. Po utworzeniu lub otwarciu projektu otwórz terminal.
IronPDF for Python można łatwo zainstalować za pomocą polecenia terminala. Wystarczy uruchomić następujące polecenie w terminalu, a IronPDF powinien zostać zainstalowany w ciągu minuty.
pip install ironpdf
 Zainstaluj pakiet IronPDF
Zainstaluj pakiet IronPDF
Po zakończeniu instalacji wszystko jest gotowe do rozpoczęcia pracy z kodem.
3. Przykłady kodu
Zanim zaczniemy dodawać i usuwać strony z dokumentu PDF, stwórzmy prosty, 4-stronicowy plik PDF, korzystając z konwersji HTML na PDF. Poniższy kod tworzy pliki PDF, które posłużą jako dokumenty wejściowe w kolejnych przykładach kodu.
from ironpdf import *
# HTML content to be converted to PDF
html = """
<p> Hello Iron</p>
<p> This is 1st Page </p>
<div style='page-break-after: always;'></div>
<p> This is 2nd Page</p>
<div style='page-break-after: always;'></div>
<p> This is 3rd Page</p>
<div style='page-break-after: always;'></div>
<p> This is 4th Page</p>
"""
# Initialize the renderer
renderer = ChromePdfRenderer()
# Render the HTML as a PDF document
pdf = renderer.RenderHtmlAsPdf(html)
# Save the PDF to a file
pdf.SaveAs("Page1And4.pdf")from ironpdf import *
# HTML content to be converted to PDF
html = """
<p> Hello Iron</p>
<p> This is 1st Page </p>
<div style='page-break-after: always;'></div>
<p> This is 2nd Page</p>
<div style='page-break-after: always;'></div>
<p> This is 3rd Page</p>
<div style='page-break-after: always;'></div>
<p> This is 4th Page</p>
"""
# Initialize the renderer
renderer = ChromePdfRenderer()
# Render the HTML as a PDF document
pdf = renderer.RenderHtmlAsPdf(html)
# Save the PDF to a file
pdf.SaveAs("Page1And4.pdf")Ten kod w języku Python wykorzystuje bibliotekę IronPDF do tworzenia dokumentu PDF na podstawie treści HTML. Treść HTML jest zdefiniowana jako ciąg znaków zawierający akapity oraz tagi div "page-break-after", wskazujące na podziały stron. Dokument ma strukturę czterech stron. Następnie kod wykorzystuje ChromePdfRenderer do konwersji tego kodu HTML na dokument PDF. Na koniec zapisuje wynikowy plik PDF jako "Page1And4.PDF".
Zasadniczo kod ten generuje wielo-stronicowy plik PDF, w którym każda strona odpowiada treści zawartej między dwoma kolejnymi tagami div "page-break" w kodzie HTML, a następnie zapisuje tę treść HTML do pliku PDF.
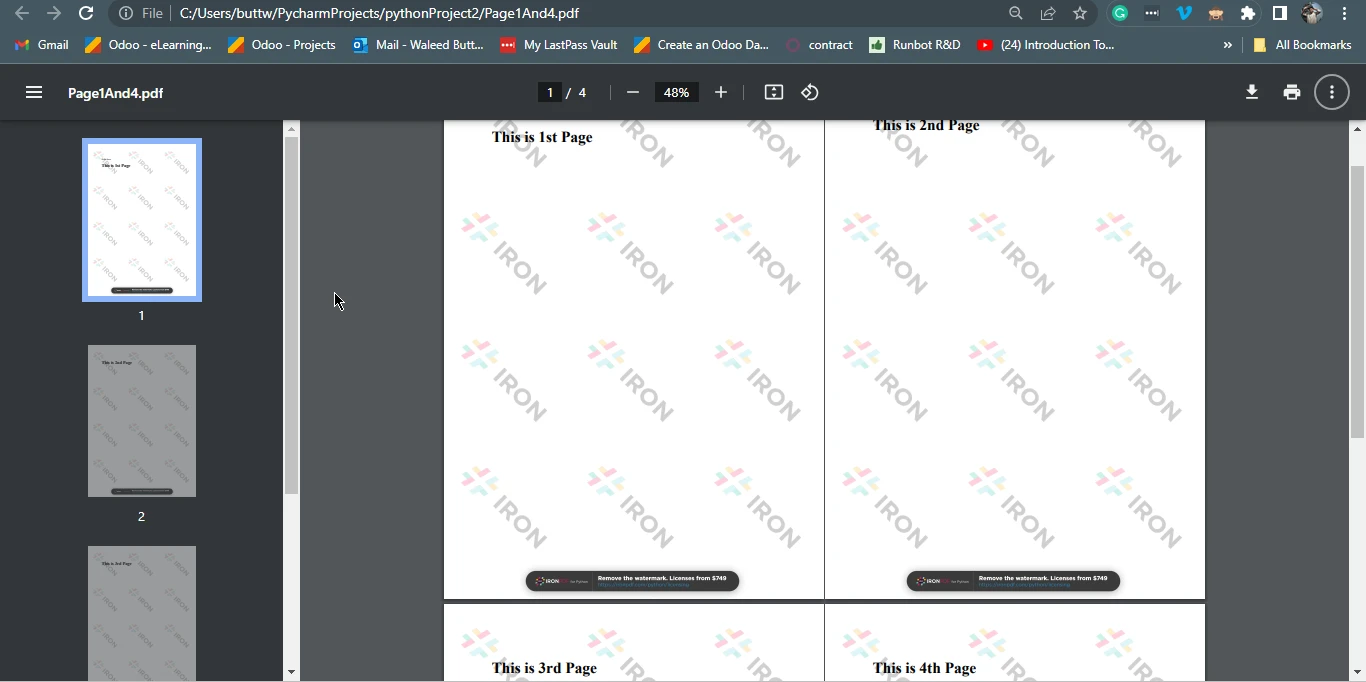 Page1And4.PDF
Page1And4.PDF
3.1. Usuwanie określonych stron z plików PDF za pomocą IronPDF
W tej sekcji usuniemy strony z wcześniej utworzonego pliku PDF. Poniższy kod usunie stronę z pliku PDF.
from ironpdf import *
# Load the existing PDF document
pdf = PdfDocument.FromFile("Page1And4.pdf")
# Remove the page at index 1 (second page)
pdf.RemovePage(1)
# Save the modified PDF to a new file
pdf.SaveAs("removed.pdf")from ironpdf import *
# Load the existing PDF document
pdf = PdfDocument.FromFile("Page1And4.pdf")
# Remove the page at index 1 (second page)
pdf.RemovePage(1)
# Save the modified PDF to a new file
pdf.SaveAs("removed.pdf")Powyższy kod wykorzystuje bibliotekę IronPDF do manipulowania dokumentem PDF. Rozpoczyna się od zaimportowania niezbędnych komponentów, a następnie ładuje istniejący dokument PDF o nazwie "Page1And4.pdf" przy użyciu metody FromFile(). Następnie usuwa stronę z pliku PDF, identyfikowaną przez indeks "1", a następnie wywołuje metodę SaveAs, która zapisuje zmodyfikowany dokument jako nowy plik PDF o nazwie removed.pdf. Zasadniczo kod wykonuje zadanie polegające na usunięciu drugiej strony z oryginalnego dokumentu PDF i zapisaniu wynikowego dokumentu jako oddzielnego pliku.
3.1.1. Plik wyjściowy PDF
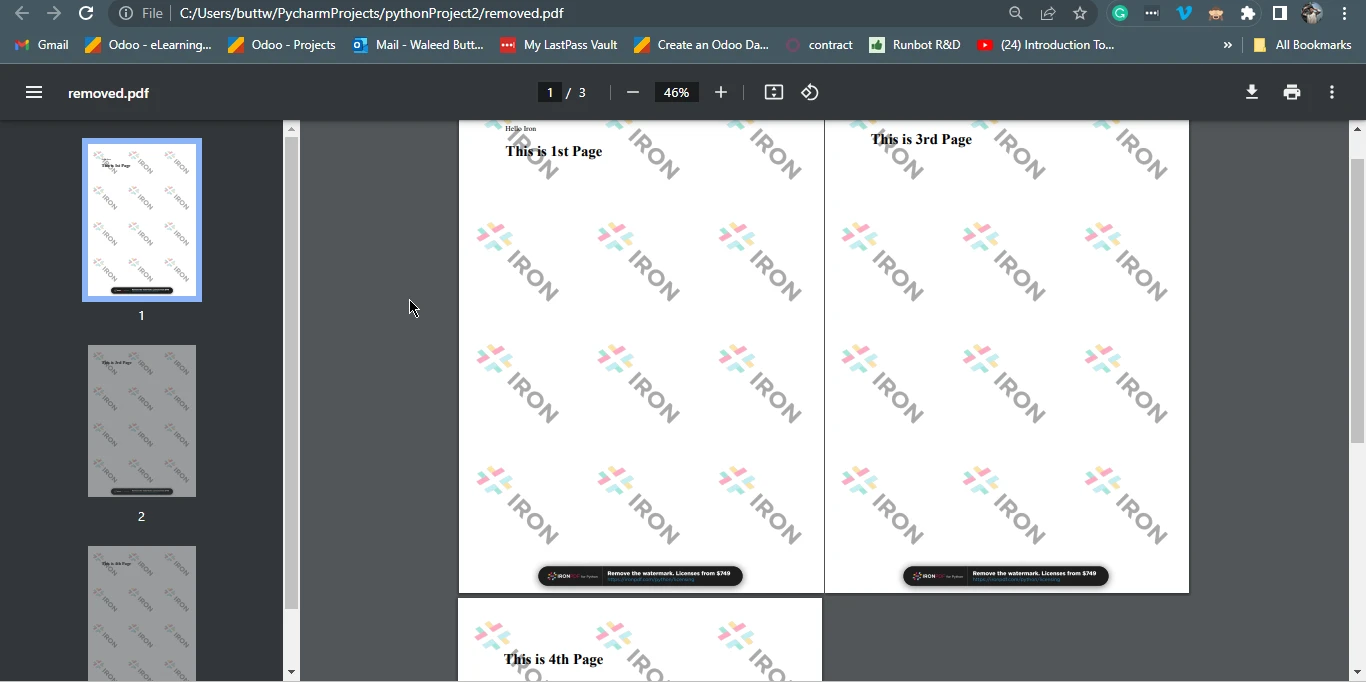 Plik wyjściowy
Plik wyjściowy
3.2. Dodawanie strony do dokumentu PDF za pomocą IronPDF
W tej sekcji omówimy, jak dodać nową stronę do istniejących plików PDF. W tym celu utwórzmy nowy plik PDF, a następnie dodajmy nowo utworzony plik PDF do wcześniej utworzonego pliku PDF, używając numerów stron za pomocą zaledwie kilku linii kodu.
Poniżej znajduje się przykładowy kod dodający nową stronę PDF do oryginalnego dokumentu.
from ironpdf import *
# HTML content to represent a new page
pdf_page = """
<h1> Cover Page</h1>
"""
# Initialize the renderer and render the new PDF page
renderer = ChromePdfRenderer()
pdfdoc_a = renderer.RenderHtmlAsPdf(pdf_page)
# Load the existing PDF file
pdf = PdfDocument.FromFile("removed.pdf")
# Prepend the new page to the beginning of the existing PDF
pdf.PrependPdf(pdfdoc_a)
# Save the combined PDF to a new file
pdf.SaveAs("addPage.pdf")from ironpdf import *
# HTML content to represent a new page
pdf_page = """
<h1> Cover Page</h1>
"""
# Initialize the renderer and render the new PDF page
renderer = ChromePdfRenderer()
pdfdoc_a = renderer.RenderHtmlAsPdf(pdf_page)
# Load the existing PDF file
pdf = PdfDocument.FromFile("removed.pdf")
# Prepend the new page to the beginning of the existing PDF
pdf.PrependPdf(pdfdoc_a)
# Save the combined PDF to a new file
pdf.SaveAs("addPage.pdf")Ten fragment kodu w języku Python wykorzystuje bibliotekę IronPDF do manipulowania dokumentami PDF. Początkowo definiuje fragment treści HTML przedstawiający stronę tytułową z nagłówkiem. Następnie wykorzystuje metodę ChromePdfRenderer() do konwersji tego kodu HTML na dokument PDF, zapisując go w pdfdoc_a.
Następnie ładuje istniejący dokument PDF "removed.pdf" za pomocą PdfDocument.FromFile("removed.pdf"). Kod dodaje treść pdfdoc_a na początku istniejącego pliku PDF przy użyciu metody pdf.PrependPdf(pdfdoc_a). Zasadniczo kod ten łączy plik PDF strony tytułowej z plikiem "removed.pdf", tworząc nowy dokument PDF o nazwie "addPage.pdf", co w efekcie powoduje dodanie strony tytułowej na początku oryginalnego pliku PDF.
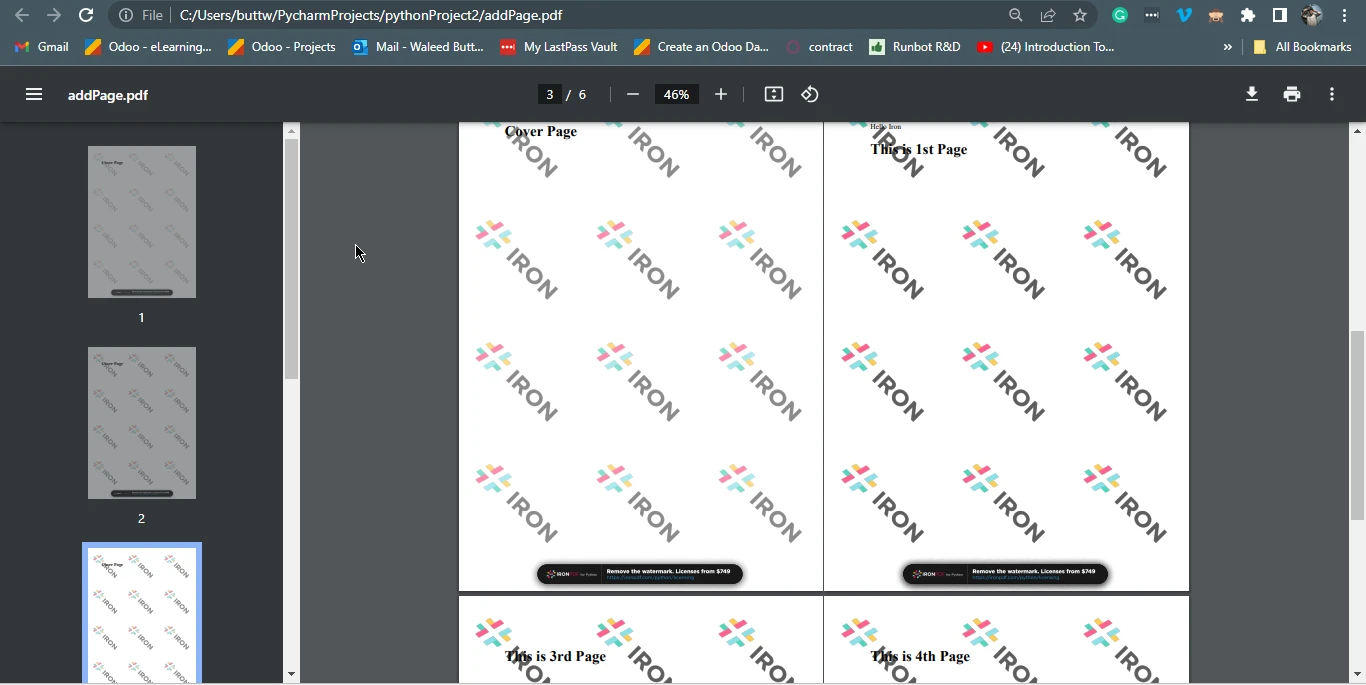 Plik wyjściowy
Plik wyjściowy
4. Podsumowanie
W tym artykule omówiono świat manipulacji plikami PDF przy użyciu języka Python, ze szczególnym uwzględnieniem biblioteki IronPDF. Możliwość dodawania lub usuwania stron z dokumentów PDF jest cenną umiejętnością w dzisiejszym cyfrowym świecie, a Python oferuje przystępny i potężny sposób na realizację tych zadań. Artykuł omawiał podstawowe kroki instalacji IronPDF i zawierał przykłady kodu ilustrujące proces tworzenia, usuwania i dodawania stron w plikach PDF.
Dzięki IronPDF programiści Python mogą efektywnie pracować z dokumentami PDF, czy to w celu generowania raportów, dostosowywania treści, czy usprawniania przepływu pracy z dokumentami. Ponieważ świat cyfrowy nadal opiera się na plikach PDF do różnych celów, opanowanie tych technik pozwala programistom zaspokajać szeroki zakres potrzeb, czyniąc Python i IronPDF dynamicznym połączeniem do manipulacji plikami PDF.
Przykładowy kod usuwania stron PDF można znaleźć w poniższym przykładowym kodzie. Przykład kodu dodającego strony PDF można znaleźć w innym przykładzie kodu w języku Python. Jeśli interesuje Cię, jak działa konwersja HTML do PDF, odwiedź tę stronę z samouczkiem.
Poznaj wszechstronne funkcje biblioteki IronPDF for Python i doświadcz transformacji, wybierając bezpłatną wersję próbną już dziś.
Często Zadawane Pytania
Jak dodać nową stronę tytułową do pliku PDF w języku Python?
W języku Python można dodać nową stronę tytułową do dokumentu PDF, używając biblioteki IronPDF ChromePdfRenderer do utworzenia nowej strony na podstawie treści HTML. Następnie należy użyć metody PrependPdf, aby dodać tę nową stronę na początku istniejącego dokumentu PDF.
Jakie kroki trzeba wykonać, żeby usunąć stronę z pliku PDF za pomocą IronPDF?
Aby usunąć stronę z pliku PDF za pomocą IronPDF, najpierw załaduj plik PDF za pomocą PdfDocument.FromFile. Zidentyfikuj stronę, którą chcesz usunąć, na podstawie jej indeksu i użyj metody RemovePage, aby ją usunąć.
Czy mogę połączyć wiele plików PDF za pomocą biblioteki PDF w języku Python?
Tak, dzięki IronPDF for Python można łatwo połączyć wiele plików PDF w jeden dokument, korzystając z metod takich jak MergePdf, które płynnie łączą pliki PDF.
Jakie funkcje oferuje IronPDF do edycji plików PDF w języku Python?
IronPDF oferuje szereg funkcji do edycji plików PDF, w tym dodawanie i usuwanie stron, scalanie dokumentów, wyodrębnianie tekstu, dodawanie znaków wodnych oraz obracanie stron, co czyni go kompleksowym narzędziem do obróbki plików PDF.
Jak przekonwertować zawartość HTML na dokument PDF za pomocą IronPDF?
Aby przekonwertować zawartość HTML na dokument PDF przy użyciu IronPDF, należy skorzystać z metody RenderHtmlAsPdf, która przetwarza ciągi znaków HTML i generuje z nich pliki PDF.
Czy dostępna jest wersja próbna biblioteki IronPDF?
Tak, dostępna jest bezpłatna wersja próbna IronPDF, która pozwala użytkownikom zapoznać się z funkcjami biblioteki i jej możliwościami w zakresie obsługi dokumentów PDF w aplikacjach napisanych w języku Python.
Jakie rodzaje aplikacji mogą skorzystać z funkcji przetwarzania plików PDF za pomocą IronPDF?
Aplikacje, od platform internetowych po oprogramowanie desktopowe, mogą korzystać z funkcji edycji plików PDF za pomocą IronPDF. Obsługuje on zadania takie jak generowanie raportów, automatyzacja przepływu dokumentów oraz dostosowywanie treści plików PDF.
Gdzie mogę znaleźć przykłady kodu w języku Python dotyczące dodawania lub usuwania stron w plikach PDF?
Przykłady kodu służącego do dodawania lub usuwania stron PDF przy użyciu IronPDF można znaleźć w artykule na stronie internetowej IronPDF, który zawiera praktyczne fragmenty kodu w języku Python przeznaczone do tych operacji.
Dlaczego zarządzanie stronami PDF jest ważne w cyfrowych procesach roboczych?
Zarządzanie stronami PDF ma kluczowe znaczenie w cyfrowych procesach pracy, umożliwiając dostosowywanie układów dokumentów, usuwanie zbędnych treści oraz automatyzację generowania raportów, co zwiększa wydajność i elastyczność zarządzania dokumentami.
















