Vergleich von Python-PDF-Bibliotheken (Kostenlose & Bezahltools)
Die Arbeit mit PDF-Dateien in Python ist eine unverzichtbare Fähigkeit für Entwickler, die CLI-Anwendungen und Datenverarbeitungssysteme bauen. Ob Sie Text aus Dokumenten extrahieren, Text und Tabellen aus komplexen Layouts abrufen oder benutzerdefinierte Daten zu vorhandenen PDFs hinzufügen müssen, die Wahl der richtigen Python-Bibliothek ist entscheidend.
Die Python PDF-Dateibibliothek hilft Entwicklern, HTML-Strings in PDF zu konvertieren, benutzerdefinierte Daten zu verarbeiten oder hinzuzufügen und erweiterte Operationen wie das Extrahieren von Tabellen und Text mit unterschiedlichen Genauigkeit zu performen. Dieser umfassende Leitfaden untersucht fünf beliebte Bibliotheksoptionen, darunter IronPDF, jede mit unterschiedlichen Fähigkeiten und Anwendungsfällen, um Ihnen bei der Auswahl der am besten geeigneten Lösung für Ihre PDF-Manipulationsbedürfnisse zu helfen.
IronPDF- PDF-Bibliothek
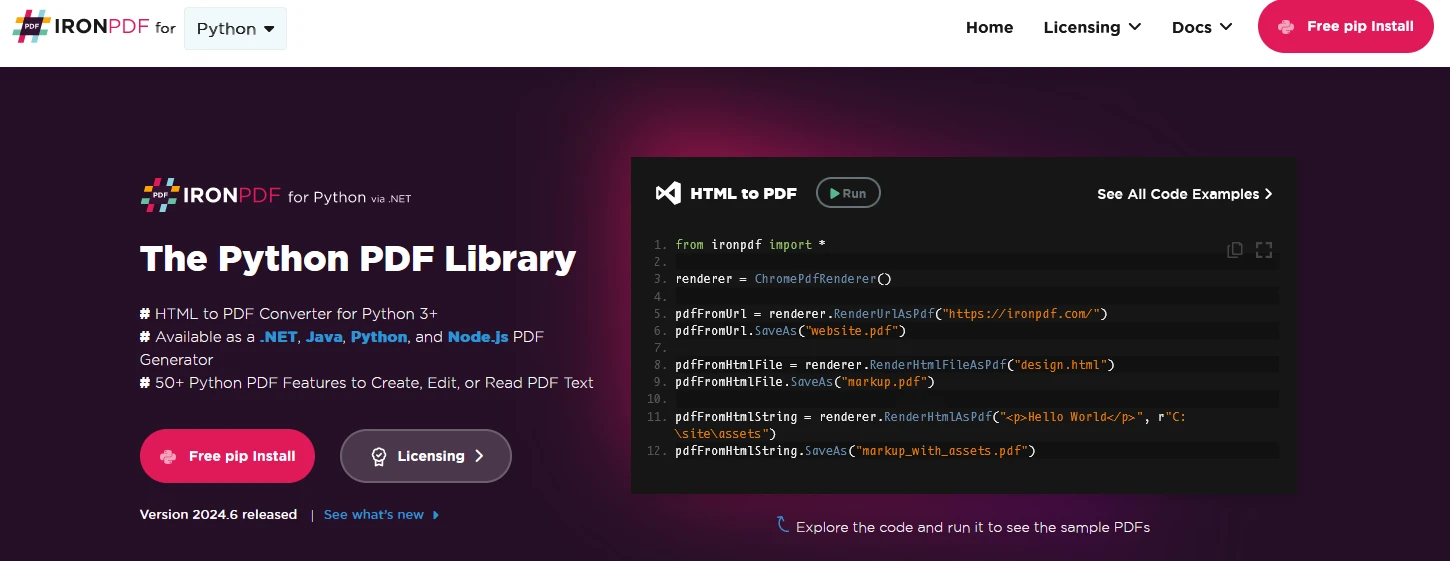
IronPDF steht als leistungsstarke PDF-Verarbeitungslösung für Python-Entwickler. Es basiert auf der robusten Chromium-Engine und glänzt durch die Umwandlung von HTML zu PDF mit außergewöhnlicher Genauigkeit und Beibehaltung der Formatierung. Es kann HTML-Strings und -Dateien in PDF konvertieren. Sie können es auch zum Extrahieren von Text aus PDF-Dateien verwenden. Die Bibliothek wurde speziell für Entwickler entwickelt, die professionelle PDF-Manipulationsfähigkeiten in Produktionsumgebungen benötigen.
Es bietet nahtlose Integration mit bestehenden Python-Anwendungen und unterstützt sowohl synchrone als auch asynchrone Operationen. Was IronPDF auszeichnet, ist seine Fähigkeit, mit komplexen Layouts, dynamischen Inhalten und modernen Webtechnologien wie CSS3 und JavaScript umzugehen. Die Bibliothek umfasst eingebaute Unterstützung für Header, Fußzeilen, Paginierung und Wasserzeichen. Es eignet sich am besten zum Erstellen von Geschäftsdokumenten, Berichten, Rechnungen und vielen anderen mit PDF verwandten Operationen.
Pros
- Funktionsreich mit über 50+ Funktionen
- Hervorragende HTML/CSS-Rendering-Genauigkeit
- Volle Multithreading- und Async-Unterstützung
- Plattformübergreifende Kompatibilität (Windows, macOS, Linux)
- Umfassende Dokumentation und Support
Kosten
- Gewerbliche Lizenz erforderlich (beginnt bei $999)
- Erfordert .NET 6.0 Laufzeitinstallation
ReportLab
ReportLab hat sich im Laufe der letzten zwei Jahrzehnte als der De-facto-Standard für PDF-Erstellung in Python etabliert. Es ist der Motor hinter Wikipedias PDF-Exportfunktion und wird von zahlreichen Fortune-500-Unternehmen eingesetzt. Die Bibliothek bietet zwei verschiedene Versionen: eine kommerzielle Edition (ReportLab PLUS) und ein Open-Source-Toolkit.
Im Kern bietet ReportLab einen robusten Seitenlayout-Motor und eine leistungsstarke Grafik-Canvas-API. Die Bibliothek glänzt bei der programmgesteuerten Erstellung komplexer Dokumente, insbesondere solcher, die eine präzise Kontrolle über Layout und Design erfordern. Sie umfasst Funktionen wie Flowables (Elemente, die über mehrere Seiten fließen können), Tabellen, Diagramme und Vektorgrafiken. ReportLabs Architektur ist darauf ausgelegt, sowohl kleine Dokumente als auch groß angelegte Batch-Verarbeitung von Tausenden von personalisierten Dokumenten zu bewältigen.
Pros
- Hervorragend geeignet für die Erstellung komplexer Formulare
- Starke Unterstützung für datengesteuerte PDFs
- Umfassende Anpassungsoptionen
- Integration mit Web-Frameworks wie Django
Kosten
- Die Dokumentation könnte besser sein
- Lernkurve für komplexe Projekte
- API ist nicht sehr Pythonic
- Installation kann umständlich sein
PyPDF2/PyPDF4
PyPDF2 (und sein Fork PyPDF4) ist eine reine Python PDF-Bibliothek in der Python-Umgebung. Ursprünglich als Fork von pypdf entwickelt, hat es sich zu einer stabilen, zuverlässigen Lösung für grundlegende PDF-Operationen entwickelt. Die Bibliothek ist vollständig in Python geschrieben. Sie ist mit einem Fokus auf PDF-Manipulation anstelle von Erstellung entworfen. Es ist effektiv für Aufgaben wie das Zusammenfügen, Teilen und Transformieren bestehender PDF-Dokumente.
Es umfasst robuste Unterstützung für verschlüsselte PDFs und kann sowohl das Lesen als auch das Schreiben von PDF-Metadaten handhaben. PyPDF2's Architektur ist modular und ermöglicht es Entwicklern, mit PDF-Komponenten auf verschiedenen Abstraktionsebenen zu arbeiten. Sie können es mit diesem Befehl installieren:
# Install PyPDF2 using pip, a package manager for Python
pip install pypdf2# Install PyPDF2 using pip, a package manager for Python
pip install pypdf2Pros
- Keine externen Abhängigkeiten
- Einfacher Installationsprozess
- Hervorragend für grundlegende PDF-Operationen
- Große Community-Unterstützung
- Über 10 Jahre etablierter Einsatz
Kosten
- Begrenzte Funktionalität im Vergleich zu kostenpflichtigen Alternativen
- Grundlegende Textextraktionsfähigkeiten
- Keine erweiterten Funktionen wie Formularausfüllung
PyFPDF
PyFPDF ist ein Python-Port der beliebten PHP PDF-Bibliothek mit demselben Namen. Es bietet einen einfachen Ansatz zur PDF-Erstellung mit einem Fokus auf Einfachheit und Benutzerfreundlichkeit. Die Bibliothek wurde mit der Philosophie entworfen, die PDF-Erstellung so einfach wie das Schreiben von Klartextdateien zu gestalten. Es behandelt alle low-level PDF-Operationen und bietet eine high-level Schnittstelle für allgemeine Aufgaben. PyFPDF beinhaltet eingebaute Unterstützung für mehrere Schriftarten, einschließlich TrueType und Type1, und kann Schriftarten direkt in PDF-Dokumente einbetten. Die Bibliothek bietet auch grundlegende HTML-Unterstützung durch ihre HTMLMixin-Klasse.
Pros
- Einfach zu bedienen für Anfänger
- Keine externen Abhängigkeiten
- Kompakt und leichtgewichtig
- Gut für die einfache Dokumentenerstellung
- Unicode-Unterstützung
Kosten
- Begrenzte HTML-Unterstützung
- Grundlegendes Funktionsset
- Weniger geeignet für komplexe Layouts
PyMuPDF
PyMuPDF, auch bekannt als Fitz, ist eine leistungsstarke Python-Bindung für die MuPDF-Bibliothek. Es zeichnet sich durch seine Vielseitigkeit im Umgang mit mehreren Dokumentformaten über PDFs hinaus aus, einschließlich XPS, EPUB und verschiedenen Bildformaten.PyMuPDF bietet umfassende Dokumentmanipulationsfähigkeiten, einschließlich fortgeschrittener Textextraktion mit präzisen Positionsinformationen, Bild-Extraktion und -Einfügung sowie Annotationsverarbeitung. Die Architektur der Bibliothek ist darauf ausgelegt, sowohl hochrangige Komfortfunktionen als auch Zugriff auf die niedrigen Strukturen von PDFs zu bieten.
Pros
- Unterstützt mehrere Dateiformate (PDF, XPS, EPUB)
- Starke Text- und Bildextraktion
- Hervorragende Leistung
- Umfassendes Funktionsset
- Gute Dokumentation
Kosten
- Erfordert C-Abhängigkeiten
- Eine kommerzielle Lizenz ist für einige Anwendungen erforderlich
- Komplexerer Installationsprozess
- Steilere Lernkurve
Funktionsvergleichstabelle
| Feature | IronPDF | ReportLab | PyPDF2 | FPDF | PyMuPDF |
|---|---|---|---|---|---|
| PDF-Erstellung | Yes | Yes | Begrenzt | Yes | Yes |
| Textextraktion | Erweitert | Basic | Basic | No | Erweitert |
| Formularausfüllung | Yes | Yes | Begrenzt | No | Yes |
| HTML-Unterstützung | Erweitert | Basic | No | Begrenzt | Basic |
| Bildbehandlung | Yes | Yes | Begrenzt | Yes | Yes |
| Abhängigkeiten | .NET | Minimal | Keine | Keine | C-Bibliotheken |
| Lizenz | Kommerziell | Dual | MIT | LGPL | GPL/Kommerziell |
Abschluss
Nach der Analyse dieser Python PDF-Bibliotheken zeigt sich, dass IronPDF eine umfassende Lösung für professionelle PDF-Entwicklungsbedürfnisse bietet. Während jede Bibliothek ihre Stärken hat, macht IronPDF's Kombination aus Funktionen, Leistung und unternehmensgerechten Fähigkeiten es für Produktionsumgebungen geeignet. Der auf Chromium basierende Motor der Bibliothek sorgt für eine überlegene Genauigkeit bei der HTML-zu-PDF-Konvertierung, während die umfangreiche API den Entwicklern Werkzeuge für komplexe PDF-Manipulationen bietet.
Für Unternehmen, die zuverlässige PDF-Verarbeitungsmöglichkeiten benötigen, rechtfertigen IronPDFs robuste Funktionsausstattung und professioneller Support die kommerzielle Investition. IronPDF bietet eine kostenlose Testversion an. Die kommerzielle Lizenz beginnt bei $999 pro Entwickler und beinhaltet umfassenden Support sowie regelmäßige Updates. IronPDF bietet die Zuverlässigkeit, Funktionen und Unterstützung, die erforderlich sind, um professionelle Lösungen zu liefern. Obwohl es kostenlose Alternativen gibt, macht das vollständige Funktionsset und die unternehmensbereiten Fähigkeiten von IronPDF es zu einer besseren Wahl.
Berücksichtigen Sie diese Schlüsselfaktoren bei der Auswahl:
- Projektanforderungen und Komplexität
- Budgetbeschränkungen
- Bedarf an professionellem Support
- Entwicklungsterminplan
- Langfristige Wartungsüberlegungen
Ob Sie ein Dokumentenmanagementsystem, Berichte erzeugen oder Formulare verarbeiten, IronPDF bietet die benötigten Werkzeuge und Stabilität für eine erfolgreiche Implementierung.
Häufig gestellte Fragen
Wie kann ich HTML in PDF in Python konvertieren?
Sie können die Python-Bibliothek von IronPDF verwenden, um HTML in PDF zu konvertieren. Sie unterstützt komplexe Layouts und moderne Webtechnologien, was eine genaue Umwandlung gewährleistet.
Was sollte ich bei der Auswahl einer Python-PDF-Bibliothek beachten?
Berücksichtigen Sie Faktoren wie Projektanforderungen, Budget, professionellen Support, Entwicklungszeitplan und langfristige Wartung bei der Auswahl einer Python-PDF-Bibliothek.
Wie unterscheidet sich IronPDF von anderen Python-PDF-Bibliotheken für die HTML-zu-PDF-Konvertierung?
IronPDF bietet überlegene HTML-zu-PDF-Konvertierungsfähigkeiten, unterstützt komplexe Layouts und dynamische Inhalte und ist daher die bevorzugte Wahl für professionelle Anwendungen.
Welche häufigen Funktionen sollte man in Python-PDF-Bibliotheken suchen?
Häufige Funktionen sind PDF-Erstellung, Textextraktion, Formularausfüllung, HTML-Unterstützung, Bildhandhabung, Abhängigkeiten und Lizenzierung. Diese Funktionen bestimmen die Eignung der Bibliothek für bestimmte Aufgaben.
Warum wählen Entwickler eine kommerzielle PDFs-Bibliothek statt einer kostenlosen?
Entwickler könnten sich für eine kommerzielle Bibliothek wie IronPDF entscheiden, aufgrund ihrer umfassenden Funktionen, höheren Genauigkeit bei der HTML-zu-PDF-Konvertierung und unternehmensfertigen Fähigkeiten, die die Investition für professionelle Anwendungen rechtfertigen.
Was sind die Hauptvorteile der Verwendung einer Python-PDF-Bibliothek für die Datenverarbeitung?
Eine Python-PDF-Bibliothek erleichtert die effiziente Textextraktion, Tabellenabruf und die Hinzufügung benutzerdefinierter Daten in PDFs, was für Entwickler, die an CLI-Anwendungen und Datenverarbeitungssystemen arbeiten, unerlässlich ist.
Welche einzigartigen Funktionen bietet PyMuPDF im Vergleich zu anderen Bibliotheken?
PyMuPDF ist vielseitig und kann verschiedene Dokumentformate über PDFs hinaus verarbeiten und bietet starke Text- und Bildextraktionsfähigkeiten mit exzellenter Leistung.
Wie hebt sich ReportLab im Bereich der Python-PDF-Bibliotheken hervor?
ReportLab ist bekannt für seine robuste Seitengestaltungs-Engine und Anpassungsmöglichkeiten, obwohl es eine steile Lernkurve hat. Es ist ideal zur Erstellung komplexer Dokumente mit präziser Layoutkontrolle.
Was macht PyFPDF für Anfänger geeignet?
PyFPDF ist leichtgewichtig, einfach zu bedienen und hat keine externen Abhängigkeiten, was es ideal für Anfänger und diejenigen macht, die einfache Dokumente erstellen möchten, trotz begrenzter HTML-Unterstützung.
Welche Funktionen bieten PyPDF2 und PyPDF4?
PyPDF2 und PyPDF4 glänzen in grundlegenden PDF-Operationen wie dem Zusammenführen, Teilen und Transformieren bestehender PDFs, ohne externe Abhängigkeiten unterstützt durch eine große Community.