Comparação de bibliotecas Python para PDF (ferramentas gratuitas e pagas)
Trabalhar com arquivos PDF em Python é uma habilidade essencial para desenvolvedores que criam aplicativos de linha de comando e sistemas de processamento de dados. Seja para extrair texto de documentos, recuperar texto e tabelas de layouts complexos ou adicionar dados personalizados a PDFs existentes, escolher a biblioteca Python certa é crucial.
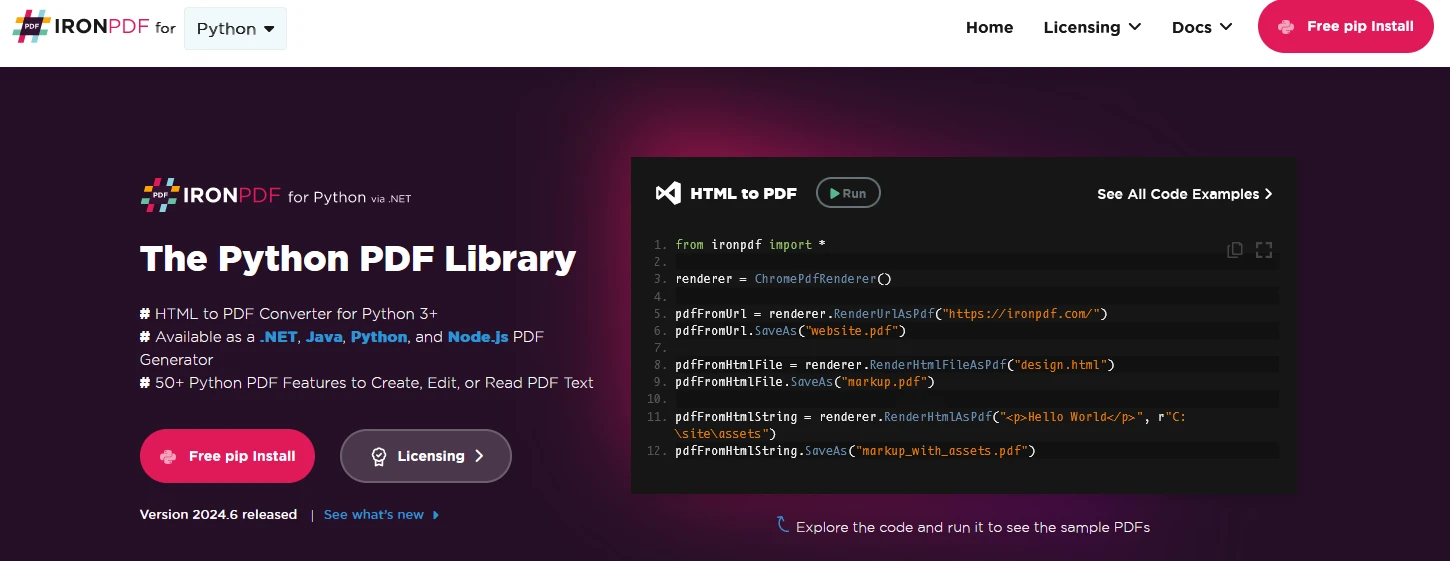
A biblioteca Python PDF files ajuda os desenvolvedores a converter strings HTML em PDF, processar ou adicionar dados personalizados e realizar operações avançadas, como extrair tabelas e texto com diferentes graus de precisão. Este guia completo explora cinco opções populares de bibliotecas, incluindo o IronPDF , cada uma com recursos e casos de uso distintos, para ajudá-lo a selecionar a solução mais adequada às suas necessidades de manipulação de PDFs.
IronPDF- Biblioteca de PDFs
O IronPDF se destaca como uma poderosa solução de processamento de PDF para desenvolvedores Python. Construído sobre o robusto motor Chromium, ele se destaca na conversão de HTML para PDF com excepcional precisão e preservação da formatação. Ele pode converter strings e arquivos HTML em PDF. Você também pode usá-lo para extrair texto de arquivos PDF. A biblioteca foi projetada especificamente para desenvolvedores que precisam de recursos de manipulação de PDF de nível profissional em ambientes de produção.
Oferece integração perfeita com aplicações Python existentes e suporta operações síncronas e assíncronas. O que diferencia o IronPDF é sua capacidade de lidar com layouts complexos, conteúdo dinâmico e tecnologias web modernas como CSS3 e JavaScript. A biblioteca inclui suporte integrado para cabeçalhos, rodapés, paginação e marcas d'água. É ideal para gerar documentos comerciais, relatórios, faturas e muitas outras operações relacionadas a PDFs.
Prós
- Repleto de recursos com mais de 50 funcionalidades
- Excelente precisão na renderização de HTML/CSS
- Suporte completo a multithreading e assíncrono
- Compatibilidade multiplataforma (Windows, macOS, Linux)
- Documentação e suporte robustos
Contras
- Licença comercial necessária (começa em $999)
- Requer a instalação do runtime do .NET 6.0
ReportLab
Ao longo das últimas duas décadas, o ReportLab se consolidou como o padrão de facto para geração de PDFs em Python. É o mecanismo por trás da funcionalidade de exportação de PDF da Wikipédia e é usado por inúmeras empresas da lista Fortune 500. A biblioteca oferece duas versões distintas: uma edição comercial (ReportLab PLUS) e um conjunto de ferramentas de código aberto.
Em sua essência, oReportLaboferece um mecanismo robusto de layout de página e uma API poderosa para telas gráficas. A biblioteca se destaca na geração programática de documentos complexos, especialmente aqueles que exigem controle preciso sobre layout e design. Inclui funcionalidades como elementos fluidos (elementos que podem fluir entre páginas), tabelas, gráficos e gráficos vetoriais. A arquitetura doReportLabfoi projetada para lidar tanto com documentos pequenos quanto com o processamento em lote em larga escala de milhares de documentos personalizados.
Prós
- Excelente para gerar formas complexas
- Forte suporte para PDFs baseados em dados
- Ampla gama de opções de personalização
- Integração com frameworks web como o Django
Contras
- A documentação poderia ser melhor.
- Curva de aprendizado para projetos complexos
- A API não é muito "pythonica".
- A instalação pode ser complicada
PyPDF2/PyPDF4
PyPDF2 (e seu fork PyPDF4 ) é uma biblioteca PDF escrita puramente em Python, presente no ecossistema Python. Originalmente desenvolvido como um fork do pypdf, evoluiu para uma solução estável e confiável para operações básicas em PDF. A biblioteca foi escrita inteiramente em Python. Ele foi projetado com foco na manipulação de PDFs, e não na criação. É eficaz para tarefas como mesclar, dividir e transformar documentos PDF existentes.
Inclui suporte robusto para PDFs criptografados e pode lidar tanto com a leitura quanto com a gravação de metadados de PDF. A arquitetura doPyPDF2é modular e permite que os desenvolvedores trabalhem com componentes PDF em vários níveis de abstração. Você pode instalá-lo com este comando:
# InstallPyPDF2using pip, a package manager for Python
pip install pypdf2# InstallPyPDF2using pip, a package manager for Python
pip install pypdf2Prós
- Sem dependências externas
- Processo de instalação simples
- Excelente para operações básicas com PDFs
- Grande apoio da comunidade
- Mais de 10 anos de uso comprovado
Contras
- Funcionalidade limitada em comparação com as alternativas pagas
- Recursos básicos de extração de texto
- Sem funcionalidades avançadas como preenchimento de formulários
PyFPDF
PyFPDF é uma versão em Python da popular biblioteca PHP de mesmo nome para PDF. Oferece uma abordagem direta para a geração de PDFs, com foco na simplicidade e facilidade de uso. A biblioteca foi projetada com a filosofia de tornar a criação de PDFs tão simples quanto escrever arquivos de texto simples. Ele lida com todas as operações de baixo nível em PDFs, ao mesmo tempo que fornece uma interface de alto nível para tarefas comuns. O PyFPDF inclui suporte integrado para várias fontes, incluindo TrueType e Type1, e pode incorporar fontes diretamente em documentos PDF. A biblioteca também oferece suporte básico a HTML por meio de sua classe HTMLMixin.
Prós
- Fácil de usar para iniciantes
- Sem dependências externas
- Compacto e leve
- Ideal para criação de documentos simples
- Suporte a Unicode
Contras
- Suporte limitado a HTML
- Conjunto de recursos básicos
- Menos adequado para layouts complexos
PyMuPDF
PyMuPDF , também conhecido como Fitz, é uma interface Python de alto desempenho para a biblioteca MuPDF. Destaca-se pela sua versatilidade no processamento de múltiplos formatos de documentos além de PDFs, incluindo XPS, EPUB e vários formatos de imagem. OPyMuPDFoferece recursos abrangentes de manipulação de documentos, incluindo extração avançada de texto com informações de posicionamento precisas, extração e inserção de imagens e gerenciamento de anotações. A arquitetura da biblioteca foi projetada para fornecer tanto funções de conveniência de alto nível quanto acesso de baixo nível às estruturas de PDF quando necessário.
Prós
- Suporta múltiplos formatos de arquivo (PDF, XPS, EPUB)
- Extração robusta de texto e imagem
- Excelente desempenho
- Conjunto completo de funcionalidades
- Boa documentação
Contras
- Requer dependências em C
- É necessária uma licença comercial para alguns usos.
- Processo de instalação mais complexo
- Curva de aprendizado mais acentuada
Tabela de comparação de recursos
| Recurso | IronPDF | ReportLab | PyPDF2 | FPDF | PyMuPDF |
|---|---|---|---|---|---|
| Criação de PDF | Yes | Sim | Limitado | Yes | Sim |
| Extração de texto | Avançado | Básico | Básico | No | Avançado |
| Preenchimento de formulários | Yes | Sim | Limitado | No | Yes |
| Suporte a HTML | Avançado | Básico | Não | Limitado | Básico |
| Manipulação de Imagens | Yes | Sim | Limitado | Yes | Sim |
| Dependências | .NET | Mínimo | None | None | Bibliotecas C |
| Licença | Comercial | Dual | MIT | LGPL | GPL/Comercial |
Conclusão
Após analisar essas bibliotecas Python para PDF, o IronPDF surge como uma solução completa para necessidades profissionais de desenvolvimento de PDFs. Embora cada biblioteca tenha seus pontos fortes, a combinação de recursos, desempenho e capacidades de nível empresarial do IronPDF o torna adequado para ambientes de produção. O mecanismo da biblioteca, baseado no Chromium, garante uma precisão superior na conversão de HTML para PDF, enquanto sua extensa API fornece aos desenvolvedores ferramentas para manipulações complexas de PDFs.
Para empresas que necessitam de recursos confiáveis de processamento de PDF, o conjunto robusto de funcionalidades e o suporte profissional do IronPDF justificam o investimento comercial. O IronPDF oferece um período de teste gratuito . A licença comercial começa em $999 por desenvolvedor, o que inclui suporte abrangente e atualizações regulares. O IronPDF oferece a confiabilidade, os recursos e o suporte necessários para fornecer soluções de nível profissional. Embora existam alternativas gratuitas, o conjunto completo de recursos e as capacidades para uso corporativo do IronPDF o tornam a melhor escolha.
Ao escolher, leve em consideração estes fatores-chave:
- Requisitos e complexidade do projeto
- Restrições orçamentárias
- Necessidade de apoio profissional
- Cronograma de desenvolvimento
- Considerações sobre manutenção a longo prazo
Seja para criar um sistema de gerenciamento de documentos, gerar relatórios ou processar formulários, o IronPDF oferece as ferramentas e a estabilidade necessárias para uma implementação bem-sucedida.
Perguntas frequentes
Como posso converter HTML para PDF em Python?
Você pode usar a biblioteca Python do IronPDF para converter HTML em PDF. Ela oferece suporte a layouts complexos e tecnologias web modernas, garantindo uma conversão precisa.
O que devo levar em consideração ao selecionar uma biblioteca PDF em Python?
Ao escolher uma biblioteca Python para PDF, leve em consideração fatores como requisitos do projeto, orçamento, suporte profissional, cronograma de desenvolvimento e manutenção a longo prazo.
Como o IronPDF se compara a outras bibliotecas Python para conversão de HTML em PDF?
O IronPDF oferece recursos superiores de conversão de HTML para PDF, suportando layouts complexos e conteúdo dinâmico, o que o torna a escolha preferida para aplicações de nível profissional.
Quais são algumas características comuns a serem procuradas em bibliotecas Python para PDF?
As funcionalidades comuns incluem criação de PDFs, extração de texto, preenchimento de formulários, suporte a HTML, manipulação de imagens, dependências e licenciamento. Essas funcionalidades determinam a adequação da biblioteca para tarefas específicas.
Por que os desenvolvedores escolheriam uma biblioteca de PDFs comercial em vez de uma gratuita?
Os desenvolvedores podem optar por uma biblioteca comercial como o IronPDF devido aos seus recursos abrangentes, maior precisão na conversão de HTML para PDF e capacidades prontas para uso corporativo, o que justifica o investimento para aplicações de nível profissional.
Quais são os principais benefícios de usar uma biblioteca PDF em Python para processamento de dados?
Uma biblioteca Python para PDF facilita a extração eficiente de texto, a recuperação de tabelas e a adição de dados personalizados a PDFs, sendo essencial para desenvolvedores envolvidos em aplicações de linha de comando e sistemas de processamento de dados.
Quais são as características únicas que o PyMuPDF oferece em comparação com outras bibliotecas?
O PyMuPDF é versátil, suportando diversos formatos de documentos além de PDFs, e oferece recursos robustos de extração de texto e imagem, com excelente desempenho.
Como o ReportLab se destaca no universo das bibliotecas PDF em Python?
O ReportLab é conhecido por seu robusto mecanismo de layout de páginas e opções de personalização, embora apresente uma curva de aprendizado acentuada. É ideal para gerar documentos complexos com controle preciso do layout.
O que torna o PyFPDF adequado para iniciantes?
O PyFPDF é leve, fácil de usar e não possui dependências externas, sendo ideal para iniciantes e para quem deseja criar documentos simples, apesar de oferecer suporte limitado a HTML.
Quais funcionalidades o PyPDF2 e o PyPDF4 oferecem?
PyPDF2 e PyPDF4 se destacam em operações básicas de PDF, como mesclar, dividir e transformar PDFs existentes, sem dependências externas e com suporte de uma grande comunidade.