xml2js npm (Cómo funciona para desarrolladores)
Los desarrolladores pueden incorporar fácilmente capacidades de análisis de datos XML y creación de PDF en sus aplicaciones combinando XML2JS con IronPDF en Node.js. XML2JS, un paquete popular de Node.js, facilita la transformación de datos XML en objetos JavaScript, lo que facilita la manipulación programática y el uso de material XML. Por el contrario, IronPDF se especializa en producir documentos PDF de alta calidad con tamaños de página, márgenes y encabezados ajustables a partir de HTML, incluyendo material creado dinámicamente.
Los desarrolladores ahora pueden crear dinámicamente informes PDF, facturas u otro material imprimible directamente desde fuentes de datos XML con la ayuda de XML2JS e IronPDF. Para automatizar los procesos de generación de documentos y garantizar precisión y flexibilidad en la gestión de datos basados en XML para salidas en PDF en aplicaciones Node.js, esta integración aprovecha las fortalezas de ambas bibliotecas.
¿Qué es xml2js?
Un paquete de Node.js llamado XML2JS facilita el análisis y la creación de un convertidor simple de XML (Extensible Markup Language) a objeto JavaScript. Al ofrecer formas de analizar archivos o textos XML y convertirlos en objetos JavaScript estructurados, facilita el procesamiento de documentos XML. Este procedimiento da a las aplicaciones libertad en cómo interpretan y utilizan los datos XML proporcionando opciones para gestionar solo atributos XML, contenido de texto, espacios de nombres, fusionar atributos o atributos de clave y otras características específicas de XML.
La biblioteca puede manejar documentos XML grandes o situaciones donde se requiere un análisis no bloqueante porque admite operaciones de análisis tanto sincrónicas como asincrónicas. Además, XML2JS ofrece mecanismos para validar y resolver errores durante la conversión de XML a objetos JavaScript, garantizando la estabilidad y confiabilidad de las operaciones de procesamiento de datos. En general, las aplicaciones Node.js utilizan frecuentemente XML2JS para integrar fuentes de datos basadas en XML, configurar software, cambiar formatos de datos y simplificar procedimientos de prueba automatizados.
XML2JS es una herramienta flexible e indispensable para trabajar con datos XML en aplicaciones Node.js debido a las siguientes características:
Análisis de XML
Con la ayuda de XML2JS, los desarrolladores pueden acceder y manejar más rápidamente los datos XML usando la conocida sintaxis de JavaScript al simplificar el procesamiento de cadenas o archivos XML en objetos JavaScript.
Conversión de objetos JavaScript
Trabajar con datos XML dentro de aplicaciones JavaScript es sencillo gracias a su conversión fluida de datos XML en objetos JavaScript estructurados.
Opciones configurables
XML2JS proporciona una variedad de opciones de configuración que le permiten alterar la forma en que los datos XML se analizan y se convierten en objetos JavaScript. Esto incluye gestionar espacios de nombres, contenido de texto, atributos y otras cosas.
Conversión bidireccional
Las modificaciones de datos de ida y vuelta son posibles gracias a sus capacidades de conversión bidireccional, que permiten transformar objetos JavaScript de vuelta en cadenas XML simples.
Asynchronous Parsing (Análisis asíncrono)
La soporte de XML2JS para procesos de análisis asincrónico maneja bien documentos XML grandes, sin interferir con el bucle de eventos de la aplicación.
Manejo de errores
Para gestionar problemas de validación y errores de análisis que puedan surgir durante el proceso de análisis y transformación de XML, XML2JS ofrece fuertes métodos de manejo de errores.
Integración con Promises
Funciona bien con las Promesas de JavaScript, haciendo que los patrones de código asincrónico para manejar datos XML sean más claros y fáciles de manejar.
Ganchos de análisis personalizables
Los desarrolladores pueden aumentar la flexibilidad de los procesos de procesamiento de datos creando ganchos de análisis personalizados que les permiten opciones especiales para interceptar y alterar el comportamiento del análisis XML.
Crear y configurar xml2js
Instalar la biblioteca y configurarla según sus necesidades son los pasos iniciales para usar XML2JS en una aplicación Node.js. Este es un detallado cómo para configurar y crear XML2JS.
Instalar XML2JS npm
Asegúrese de que npm y Node.js estén instalados primero. XML2JS se puede instalar con npm:
npm install xml2jsnpm install xml2jsUso básico de XML2JS
Este es un simple ejemplo de cómo usar XML2JS para analizar texto XML en objetos JavaScript:
const xml2js = require('xml2js');
// Example XML content
const xmlContent = `
<bookstore>
<book category="fiction">
<title>Harry Potter</title>
<author>J.K. Rowling</author>
</book>
<book category="nonfiction">
<title>Thinking, Fast and Slow</title>
<author>Daniel Kahneman</author>
</book>
</bookstore>
`;
// Configure XML2JS parser
const parser = new xml2js.Parser();
// Parse XML content
parser.parseString(xmlContent, (err, result) => {
if (err) {
console.error('Error parsing XML:', err);
return;
}
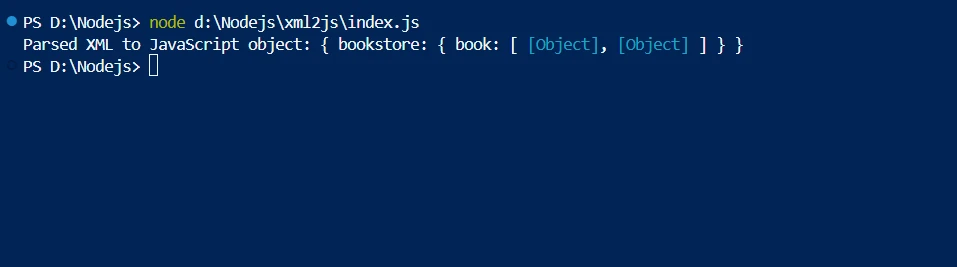
console.log('Parsed XML to JavaScript object:', result);
});const xml2js = require('xml2js');
// Example XML content
const xmlContent = `
<bookstore>
<book category="fiction">
<title>Harry Potter</title>
<author>J.K. Rowling</author>
</book>
<book category="nonfiction">
<title>Thinking, Fast and Slow</title>
<author>Daniel Kahneman</author>
</book>
</bookstore>
`;
// Configure XML2JS parser
const parser = new xml2js.Parser();
// Parse XML content
parser.parseString(xmlContent, (err, result) => {
if (err) {
console.error('Error parsing XML:', err);
return;
}
console.log('Parsed XML to JavaScript object:', result);
});
Opciones de configuración
XML2JS ofrece una gama de opciones de configuración y ajustes predeterminados que le permiten alterar el comportamiento del análisis. Aquí hay una ilustración de cómo configurar ajustes de análisis predeterminados para XML2JS:
const xml2js = require('xml2js');
// Example XML content
const xmlContent = `
<bookstore>
<book category="fiction">
<title>Harry Potter</title>
<author>J.K. Rowling</author>
</book>
<book category="nonfiction">
<title>Thinking, Fast and Slow</title>
<author>Daniel Kahneman</author>
</book>
</bookstore>
`;
// Configure XML2JS parser with options
const parser = new xml2js.Parser({
explicitArray: false, // Converts child elements to objects instead of arrays when there is only one child
trim: true // Trims leading/trailing whitespace from text nodes
});
// Parse XML content
parser.parseString(xmlContent, (err, result) => {
if (err) {
console.error('Error parsing XML:', err);
return;
}
console.log('Parsed XML to JavaScript object with options:', result);
});const xml2js = require('xml2js');
// Example XML content
const xmlContent = `
<bookstore>
<book category="fiction">
<title>Harry Potter</title>
<author>J.K. Rowling</author>
</book>
<book category="nonfiction">
<title>Thinking, Fast and Slow</title>
<author>Daniel Kahneman</author>
</book>
</bookstore>
`;
// Configure XML2JS parser with options
const parser = new xml2js.Parser({
explicitArray: false, // Converts child elements to objects instead of arrays when there is only one child
trim: true // Trims leading/trailing whitespace from text nodes
});
// Parse XML content
parser.parseString(xmlContent, (err, result) => {
if (err) {
console.error('Error parsing XML:', err);
return;
}
console.log('Parsed XML to JavaScript object with options:', result);
});Manejo del análisis asíncrono
El análisis asincrónico es compatible con XML2JS, lo cual es útil para manejar documentos XML grandes sin detener el bucle de eventos. Aquí hay una ilustración de cómo usar la sintaxis async/await con XML2JS:
const xml2js = require('xml2js');
// Example XML content (assume it's loaded asynchronously, e.g., from a file)
const xmlContent = `
<bookstore>
<book category="fiction">
<title>Harry Potter</title>
<author>J.K. Rowling</author>
</book>
<book category="nonfiction">
<title>Thinking, Fast and Slow</title>
<author>Daniel Kahneman</author>
</book>
</bookstore>
`;
// Configure XML2JS parser
const parser = new xml2js.Parser();
// Async function to parse XML content
async function parseXml(xmlContent) {
try {
const result = await parser.parseStringPromise(xmlContent);
console.log('Parsed XML to JavaScript object (async):', result);
} catch (err) {
console.error('Error parsing XML (async):', err);
}
}
// Call async function to parse XML content
parseXml(xmlContent);const xml2js = require('xml2js');
// Example XML content (assume it's loaded asynchronously, e.g., from a file)
const xmlContent = `
<bookstore>
<book category="fiction">
<title>Harry Potter</title>
<author>J.K. Rowling</author>
</book>
<book category="nonfiction">
<title>Thinking, Fast and Slow</title>
<author>Daniel Kahneman</author>
</book>
</bookstore>
`;
// Configure XML2JS parser
const parser = new xml2js.Parser();
// Async function to parse XML content
async function parseXml(xmlContent) {
try {
const result = await parser.parseStringPromise(xmlContent);
console.log('Parsed XML to JavaScript object (async):', result);
} catch (err) {
console.error('Error parsing XML (async):', err);
}
}
// Call async function to parse XML content
parseXml(xmlContent);Empezando
Para usar IronPDF y XML2JS en una aplicación Node.js, primero debe leer los datos XML y luego crear un documento PDF a partir del contenido que se ha procesado. Este es un detallado cómo que le ayudará a instalar y configurar estas bibliotecas.
¿Qué es IronPDF?
La biblioteca IronPDF es una potente biblioteca de Node.js para trabajar con PDFs. El objetivo es convertir contenido HTML en documentos PDF de calidad excepcional. Simplifica el proceso de convertir HTML, CSS, y otros archivos JavaScript en PDFs correctamente formateados sin comprometer el contenido original en línea. Esta es una herramienta muy útil para aplicaciones web que necesitan producir documentos imprimibles dinámicos como facturas, certificaciones e informes.
IronPDF tiene varias características, incluyendo configuraciones de página personalizables, encabezados, pies de página, y la capacidad de insertar fuentes e imágenes. Admite diseños y estilos complejos para garantizar que todos los PDFs de salida de prueba sigan el diseño especificado. Además, IronPDF controla la ejecución de JavaScript dentro del HTML, permitiendo una representación precisa de contenido dinámico e interactivo.
Características de IronPDF
Generación de PDF desde HTML
Convertir HTML, CSS y JavaScript a PDF. Soporta dos estándares web modernos: consultas de medios y diseño responsivo. Útil para usar HTML y CSS para decorar dinámicamente facturas PDF, informes y documentos.
Edición de PDF
Es posible agregar texto, imágenes y otro material a PDFs ya existentes. Extraer texto e imágenes de archivos PDF. Combinar muchos PDFs en un solo archivo. Dividir archivos PDF en varios documentos distintos. Agregar encabezados, pies de página, anotaciones y marcas de agua.
Rendimiento y Confiabilidad
En contextos industriales, el alto rendimiento y la fiabilidad son atributos de diseño deseables. Maneja fácilmente grandes conjuntos de documentos.
Instalar IronPDF
Para obtener las herramientas que necesita para trabajar con PDF en proyectos de Node.js, instale el paquete IronPDF.
npm install @ironsoftware/ironpdfnpm install @ironsoftware/ironpdfPreparar XML y generar PDF
Para ilustrar, generemos un archivo XML básico llamado example.xml:
<bookstore>
<book category="fiction">
<title>Harry Potter</title>
<author>J.K. Rowling</author>
</book>
<book category="nonfiction">
<title>Thinking, Fast and Slow</title>
<author>Daniel Kahneman</author>
</book>
</bookstore>
<bookstore>
<book category="fiction">
<title>Harry Potter</title>
<author>J.K. Rowling</author>
</book>
<book category="nonfiction">
<title>Thinking, Fast and Slow</title>
<author>Daniel Kahneman</author>
</book>
</bookstore>Cree el script Node.js generatePdf.js, que lee el archivo XML, utiliza XML2JS para analizarlo en un objeto JavaScript y luego utiliza IronPDF para crear un PDF a partir del objeto resultante de datos analizados.
// generatePdf.js
const fs = require('fs');
const xml2js = require('xml2js');
const IronPdf = require('@ironsoftware/ironpdf');
// Configure IronPDF with license if necessary
var config = IronPdf.IronPdfGlobalConfig;
config.setConfig({ licenseKey: '' });
// Function to read and parse XML
const parseXml = async (filePath) => {
const parser = new xml2js.Parser();
const xmlContent = fs.readFileSync(filePath, 'utf8');
return await parser.parseStringPromise(xmlContent);
};
// Function to generate HTML content from the parsed object
function generateHtml(parsedXml) {
let htmlContent = `
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Bookstore</title>
<style>
body { font-family: Arial, sans-serif; }
.book { margin-bottom: 20px; }
</style>
</head>
<body>
<h1>Bookstore</h1>
`;
// Iterate over each book to append to the HTML content
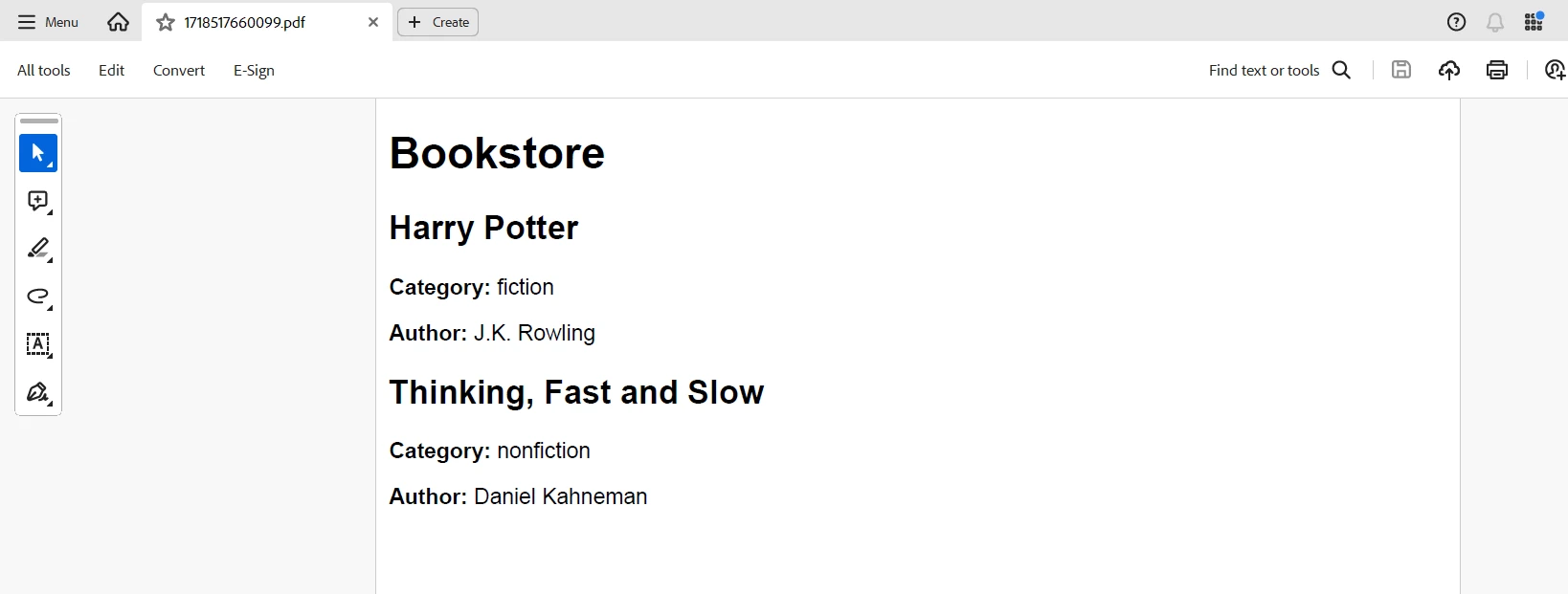
parsedXml.bookstore.book.forEach(book => {
htmlContent += `
<div class="book">
<h2>${book.title}</h2>
<p><strong>Category:</strong> ${book.$.category}</p>
<p><strong>Author:</strong> ${book.author}</p>
</div>
`;
});
htmlContent += `
</body>
</html>
`;
return htmlContent;
}
// Main function to generate PDF
const generatePdf = async () => {
try {
const parser = await parseXml('./example.xml');
const htmlContent = generateHtml(parser);
// Convert HTML to PDF
IronPdf.PdfDocument.fromHtml(htmlContent).then((pdfres) => {
const filePath = `${Date.now()}.pdf`;
pdfres.saveAs(filePath).then(() => {
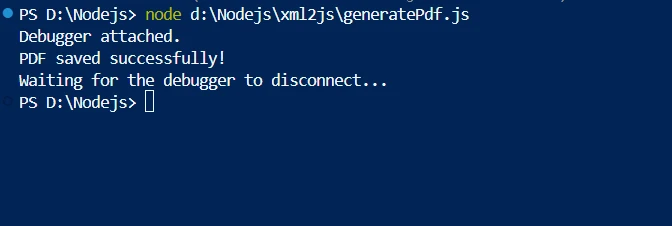
console.log('PDF saved successfully!');
}).catch((e) => {
console.log(e);
});
});
} catch (error) {
console.error('Error:', error);
}
};
// Run the main function
generatePdf();// generatePdf.js
const fs = require('fs');
const xml2js = require('xml2js');
const IronPdf = require('@ironsoftware/ironpdf');
// Configure IronPDF with license if necessary
var config = IronPdf.IronPdfGlobalConfig;
config.setConfig({ licenseKey: '' });
// Function to read and parse XML
const parseXml = async (filePath) => {
const parser = new xml2js.Parser();
const xmlContent = fs.readFileSync(filePath, 'utf8');
return await parser.parseStringPromise(xmlContent);
};
// Function to generate HTML content from the parsed object
function generateHtml(parsedXml) {
let htmlContent = `
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Bookstore</title>
<style>
body { font-family: Arial, sans-serif; }
.book { margin-bottom: 20px; }
</style>
</head>
<body>
<h1>Bookstore</h1>
`;
// Iterate over each book to append to the HTML content
parsedXml.bookstore.book.forEach(book => {
htmlContent += `
<div class="book">
<h2>${book.title}</h2>
<p><strong>Category:</strong> ${book.$.category}</p>
<p><strong>Author:</strong> ${book.author}</p>
</div>
`;
});
htmlContent += `
</body>
</html>
`;
return htmlContent;
}
// Main function to generate PDF
const generatePdf = async () => {
try {
const parser = await parseXml('./example.xml');
const htmlContent = generateHtml(parser);
// Convert HTML to PDF
IronPdf.PdfDocument.fromHtml(htmlContent).then((pdfres) => {
const filePath = `${Date.now()}.pdf`;
pdfres.saveAs(filePath).then(() => {
console.log('PDF saved successfully!');
}).catch((e) => {
console.log(e);
});
});
} catch (error) {
console.error('Error:', error);
}
};
// Run the main function
generatePdf();Una manera fácil de convertir datos XML y analizar múltiples archivos en documentos PDF es combinando IronPDF y XML2JS en una aplicación Node.js. Usando XML2JS, el contenido XML de múltiples archivos se analiza en un objeto JavaScript una vez que el archivo XML es leído primero usando el módulo fs de Node.js. Posteriormente, el texto HTML que forma la base del PDF se genera dinámicamente utilizando estos datos procesados.
El script comienza leyendo texto XML de un archivo y usando xml2js para analizarlo en un objeto JavaScript. A partir del objeto de datos analizados, una función personalizada crea contenido HTML, estructurándolo con los elementos requeridos, por ejemplo, autores y títulos para una librería. Este HTML posteriormente se representa en un búfer PDF usando IronPDF. El PDF producido luego se guarda en el sistema de archivos.
Usando la efectiva conversión HTML-a-PDF de IronPDF y las robustas capacidades de análisis XML de XML2JS, este método ofrece una forma simplificada de crear PDFs a partir de datos XML en aplicaciones Node.js. La conexión hace posible convertir datos XML dinámicos en documentos PDF que son imprimibles y bien formateados. Esto lo hace perfecto para aplicaciones que requieren generación automatizada de documentos desde fuentes de XML.
Conclusión
En resumen, XML2JS e IronPDF juntos en una aplicación Node.js proporcionan una forma fuerte y adaptable para convertir datos XML en documentos PDF de alta calidad. El efectivo análisis de XML en objetos JavaScript usando XML2JS hace que la extracción y manipulación de datos sea simple. Después de que los datos han sido analizados, pueden ser cambiados dinámicamente en texto HTML, que IronPDF puede luego convertir fácilmente en archivos PDF correctamente estructurados.
Las aplicaciones que requieren la creación automatizada de documentos como informes, facturas y certificados desde fuentes de datos XML pueden encontrar esta combinación especialmente útil. Los desarrolladores pueden garantizar salidas PDF precisas y estéticamente agradables, simplificar flujos de trabajo y mejorar la capacidad de las aplicaciones Node.js para manejar tareas de generación de documentos utilizando los beneficios de ambas bibliotecas.
IronPDF ofrece a los desarrolladores más capacidades junto con un desarrollo más eficiente, todo mientras utilizan los sistemas altamente flexibles y suite de Iron Software.
Es más fácil para los desarrolladores elegir el mejor modelo cuando las opciones de licencia son explícitas y específicas para el proyecto. Estas características permiten a los desarrolladores resolver una variedad de problemas de una manera intuitiva, eficiente y cohesiva.