

Cómo Leer Archivos PDF en Node.js
En el mundo en constante evolución del desarrollo web, Node.js ha surgido como una plataforma poderosa que permite a los desarrolladores construir aplicaciones escalables y eficientes. Un aspecto fascinante de Node.js es su capacidad para trabajar sin problemas con varias bibliotecas y módulos, ampliando sus funcionalidades. En este artículo, exploraremos el ámbito de las capacidades del lector de PDF de Node.js, explorando la biblioteca IronPDF y cómo se puede aprovechar para manejar archivos PDF.
¿Qué es Node.js PDF Reader?
Node.js PDF Reader es una herramienta especializada diseñada para facilitar la lectura y manipulación de archivos PDF (Formato de Documento Portátil) dentro del entorno de Node.js. Los archivos PDF se utilizan ampliamente para compartir documentos debido a su formato consistente en diferentes plataformas. Incorporar capacidades de lectura de PDF en aplicaciones Node.js abre una multitud de posibilidades, desde extraer información hasta generar informes dinámicos.
¿Cómo leer PDF con Node.js PDF Reader?
- Instalar la biblioteca Node.js PDF Reader.
- Importe las dependencias requeridas.
- Abra el archivo PDF utilizando el método
PdfDocument.open. - Extraiga el texto del archivo PDF utilizando el método
extractText. - Mostrar el texto extraído en la consola utilizando el método
console.log.
2. Introducción a IronPDF for Node.js
IronPDF es una biblioteca integral para trabajar con archivos PDF en el ecosistema de Node.js. Proporciona una gama de funcionalidades, convirtiéndose en una opción preferida para desarrolladores que necesitan interactuar con documentos PDF de manera programática. Desarrollado por el equipo de Iron Software, IronPDF se destaca por su simplicidad y facilidad de integración en proyectos de Node.js.
2.1. Características principales de IronPDF
- Generación de PDF: IronPDF permite a los desarrolladores crear documentos PDF desde cero, proporcionando control total sobre el contenido, formato y diseño.
- Análisis de PDF: La biblioteca permite la extracción de texto, imágenes y otros elementos de archivos PDF existentes, capacitando a los desarrolladores para trabajar con los datos almacenados en estos documentos.
- Modificación de PDF: IronPDF admite la modificación de archivos PDF existentes, permitiendo agregar, eliminar o actualizar contenido de manera dinámica.
- Renderizado de PDF: Con IronPDF, los desarrolladores pueden renderizar archivos PDF en varios formatos, incluyendo desde imágenes o desde HTML, ampliando las posibilidades para mostrar contenido PDF dentro de aplicaciones web.
- Compatibilidad multiplataforma: IronPDF está diseñado para funcionar sin problemas en diferentes sistemas operativos, asegurando un comportamiento consistente sin importar el entorno de implementación.
2.2. Instalación de IronPDF
Antes de sumergirse en las funcionalidades de IronPDF, es esencial instalar la biblioteca en su proyecto de Node.js. El proceso de instalación es sencillo y se puede realizar utilizando el gestor de paquetes NPM. Abre tu terminal y ejecuta el siguiente comando:
npm install @ironsoftware/ironpdfnpm install @ironsoftware/ironpdfEste comando instala la biblioteca IronPDF y la hace disponible para su uso en su aplicación Node.js.
Para instalar el motor IronPDF necesario para usar la biblioteca IronPDF, ejecute el siguiente comando en la consola:
npm install @ironsoftware/ironpdf-engine-windows-x64npm install @ironsoftware/ironpdf-engine-windows-x643. Lectura de archivos PDF con Node.js y IronPDF
La lectura de archivos PDF con Node.js e IronPDF implica una serie de pasos sencillos, y el ejemplo de código proporcionado ilustra un enfoque conciso pero poderoso para lograr esto. El código utiliza la clase PdfDocument del paquete @ironsoftware/ironpdf para abrir y extraer texto de un archivo PDF. Analicemos el código paso a paso:
Importación de
PdfDocument:import { PdfDocument } from "@ironsoftware/ironpdf";import { PdfDocument } from "@ironsoftware/ironpdf";JAVASCRIPTEl código comienza importando la clase
PdfDocumentde la biblioteca IronPDF. Esta clase proporciona métodos para trabajar con documentos PDF, como abrir, extraer texto y realizar varias manipulaciones.Apertura de un archivo PDF:
const pdf = await PdfDocument.open("output.pdf");const pdf = await PdfDocument.open("output.pdf");JAVASCRIPTEl método
PdfDocument.opense utiliza para abrir un archivo PDF. En este ejemplo, se especifica el archivo "output.pdf". Se utiliza la palabra claveawaitporque el métodoopendevuelve una promesa. Esto garantiza que el código espere a que el PDF se haya cargado por completo antes de pasar a los siguientes pasos.Extracción de texto del PDF:
const text = await pdf.extractText();const text = await pdf.extractText();JAVASCRIPTUna vez abierto el PDF, se invoca el método
extractTexten el objetopdf. Este método extrae asincrónicamente el contenido de texto del documento PDF. El resultado se almacena en la variabletext.Registro del texto extraído:
console.log(text);console.log(text);JAVASCRIPTPor último, el texto extraído se registra en la consola utilizando
console.log. Este paso es crucial para que los desarrolladores verifiquen que el proceso de extracción de texto fue exitoso y para inspeccionar el contenido extraído del PDF de muestra.asyncEnvoltura de funciones:(async () => { // Code goes here })();(async () => { // Code goes here })();JAVASCRIPTTodo el código está envuelto en una función asíncrona que utiliza una expresión de función de invocación inmediata (IIFE) con la palabra clave
async. Esto permite el uso deawaitdentro de la función, lo que habilita operaciones asíncronas como la carga del PDF y la extracción de texto.
En resumen, este código muestra un método conciso pero efectivo para leer archivos PDF usando Node.js y IronPDF. Al aprovechar las capacidades de la biblioteca IronPDF, los desarrolladores pueden abrir fácilmente documentos PDF, extraer contenido de texto e integrar estas funcionalidades en sus aplicaciones Node.js.
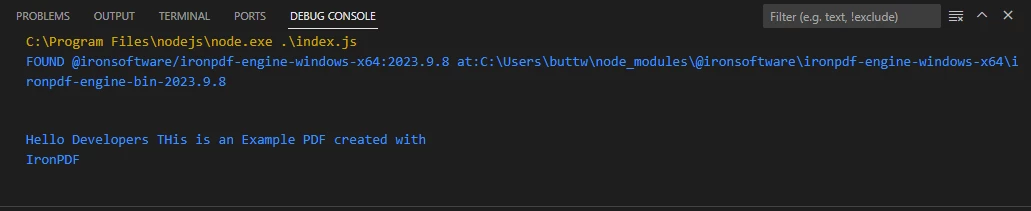 Texto extraído de un archivo PDF de muestra
Texto extraído de un archivo PDF de muestra
3.1. Lectura de archivos PDF protegidos con contraseña
La lectura de archivos PDF protegidos con contraseña requiere abordar la capa adicional de seguridad que protege el contenido del documento. En tales casos, es crucial usar bibliotecas de lectura de PDF, como IronPDF, que admitan la autenticación de contraseñas.
El proceso implica proporcionar la contraseña correcta durante la fase de apertura del archivo, lo que permite la descifrado del contenido dentro del PDF. Esto asegura que solo los usuarios autorizados puedan acceder y extraer información de archivos PDF protegidos con contraseña, mejorando la seguridad de los datos sensibles contenidos en estos documentos.
const pdf = await PdfDocument.open("encrypted.pdf", "password");const pdf = await PdfDocument.open("encrypted.pdf", "password");Usando el código anterior, los usuarios pueden leer el contenido de archivos PDF protegidos con contraseña.
3.2. Lectura de metadatos de archivos PDF
IronPDF for Node.js ofrece la posibilidad de leer metadatos de archivos PDF. El siguiente código demostrará cómo leer metadatos de un archivo PDF.
import { PdfDocument } from "@ironsoftware/ironpdf";
(async () => {
// Step 1. Import a PDF
const pdf = await PdfDocument.open("output.pdf");
const metadata = await pdf.getMetadata();
console.log("\n");
console.log(metadata);
})();import { PdfDocument } from "@ironsoftware/ironpdf";
(async () => {
// Step 1. Import a PDF
const pdf = await PdfDocument.open("output.pdf");
const metadata = await pdf.getMetadata();
console.log("\n");
console.log(metadata);
})();Resultado
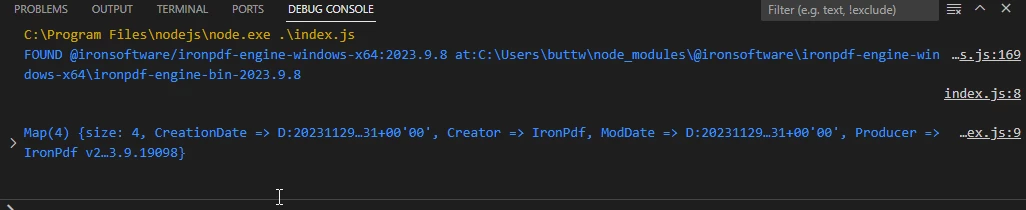 Metadatos extraídos de un archivo PDF de muestra
Metadatos extraídos de un archivo PDF de muestra
4. Conclusión
En conclusión, Node.js PDF Reader, particularmente cuando se utiliza la biblioteca IronPDF, abre un mundo de posibilidades para los desarrolladores que trabajan con archivos PDF. Ya sea extrayendo texto, imágenes o modificando dinámicamente documentos existentes, IronPDF proporciona un conjunto versátil de herramientas para manejar PDFs en un entorno de Node.js. También soporta datos tabulares y el módulo de lector de PDF extrae entradas de texto.
Para comenzar con Node.js PDF Reader e IronPDF, siga los pasos detallados en este artículo. Explora la documentación para obtener información más detallada y casos de uso avanzados. Con las herramientas y el conocimiento adecuados, puede mejorar sus aplicaciones Node.js integrando sin problemas capacidades de lectura de PDF.
¿Por qué utilizar IronPDF for Node.js?
- Prueba gratuita: IronPDF for Node.js ofrece una prueba gratuita de IronPDF for Node.js, permitiendo a los desarrolladores explorar sus capacidades antes de comprometerse. Este periodo de prueba permite a los usuarios evaluar la idoneidad de la biblioteca para sus tareas específicas relacionadas con PDF sin compromiso financiero.
- Riqueza de funciones: IronPDF for Node.js es rico en funciones y ofrece un conjunto completo de funcionalidades para trabajar con archivos PDF en Node.js. Desde la generación de PDF hasta la extracción de texto y la modificación de documentos, la biblioteca ofrece un kit de herramientas robusto, haciéndola versátil para una amplia gama de aplicaciones.
- Ejemplos de código y documentación/soporte: IronPDF proporciona documentación extensa y soporte, lo que facilita a los desarrolladores integrar y utilizar sus características. La biblioteca viene con ejemplos detallados de conversión a PDF de Node.js, lo que facilita una curva de aprendizaje fluida y garantiza que los desarrolladores dispongan de los recursos necesarios para una implementación satisfactoria.
Preguntas Frecuentes
¿Cómo puedo leer un archivo PDF en Node.js?
Para leer un archivo PDF en Node.js, puedes usar IronPDF instalándolo a través de npm. Importa las dependencias necesarias y utiliza el método PdfDocument.open para cargar el PDF. Extrae el contenido textual usando el método extractText y presenta los resultados en la consola.
¿Cuáles son los beneficios de usar una biblioteca de PDF en Node.js?
Usar una biblioteca de PDF como IronPDF en Node.js ofrece beneficios como la generación, el análisis y la modificación de PDF. Mejora las aplicaciones de Node.js al proporcionar capacidades robustas de manejo de PDF, incluyendo compatibilidad multiplataforma e integración perfecta.
¿Cómo instalo IronPDF en un proyecto de Node.js?
Para instalar IronPDF en un proyecto de Node.js, usa el comando npm: npm install @Iron Software/ironpdf. Además, instala el motor IronPDF con npm install @Iron Software/ironpdf-engine-windows-x64 para asegurar una funcionalidad completa.
¿Puedo leer PDFs protegidos con contraseña en Node.js?
Sí, IronPDF te permite leer PDFs protegidos con contraseña en Node.js. Proporciona la contraseña correcta durante el proceso de apertura del PDF para descifrar y acceder al contenido.
¿Cómo puedo extraer metadatos de un PDF usando Node.js?
Usando IronPDF en Node.js, puedes extraer metadatos de un PDF al abrir el documento con PdfDocument.open y utilizar el método getMetadata para obtener detalles de los metadatos.
¿Qué hace que IronPDF sea una opción popular para la manipulación de PDF en Node.js?
IronPDF es popular entre los desarrolladores de Node.js debido a sus capacidades ricas en características, documentación extensa y soporte. Ofrece una prueba gratuita, haciéndolo accesible para pruebas e integración en diversas aplicaciones.
¿Cómo garantiza IronPDF la compatibilidad multiplataforma en proyectos de Node.js?
IronPDF está diseñado para mantener un rendimiento constante en diferentes sistemas operativos, asegurando que tus proyectos de Node.js funcionen de manera fiable independientemente de la plataforma de implementación.
¿Dónde puedo encontrar más recursos sobre el uso de IronPDF en Node.js?
Para más recursos y ejemplos sobre el uso de IronPDF en Node.js, visita el sitio web oficial de Iron Software. Explora su documentación y tutoriales para obtener una guía completa sobre la manipulación de PDF.















