
Computación Distribuida con Python
Python distribuido
Existe una necesidad mayor que nunca de soluciones informáticas escalables y efectivas en el campo de la tecnología en constante cambio. La computación distribuida se está volviendo cada vez más necesaria para trabajos que involucran grandes volúmenes de procesamiento de datos distribuidos, solicitudes concurrentes de usuarios y tareas computacionalmente exigentes. Para permitir que los desarrolladores aprovechen al máximo el Python Distribuido, examinaremos sus aplicaciones, principios y herramientas en este artículo.
La producción dinámica y la modificación de documentos PDF es un requerimiento común en el campo del desarrollo web. La capacidad de crear PDFs programáticamente es útil para crear facturas, informes y certificados sobre la marcha.
La extensa ecología y versatilidad de Python permiten trabajar con una multitud de bibliotecas de PDF. IronPDF es una solución formidable que ayuda a los desarrolladores a utilizar plenamente su infraestructura agilizando el proceso de creación de PDF y permitiendo también el paralelismo de tareas y la computación distribuida.
Entender el Python distribuido
Fundamentalmente, el Python distribuido es el proceso de dividir un trabajo computacional en partes más pequeñas y distribuirlas entre varios nodos o unidades de procesamiento. Estos nodos podrían ser máquinas individuales conectadas a una red, núcleos de CPU individuales dentro de un sistema, objetos remotos, funciones remotas, ejecución de llamadas remotas o incluso hilos individuales dentro de un solo proceso. El objetivo es aumentar el rendimiento, la escalabilidad y la tolerancia a fallos mediante la paralelización de la carga de trabajo.
Python es una excelente opción para cargas de trabajo de computación distribuida debido a su facilidad de uso, adaptabilidad y un ecosistema robusto de bibliotecas. Python ofrece una gran cantidad de herramientas para la computación distribuida en todas las escalas y casos de uso, que van desde marcos sólidos como Celery, Dask y Apache Spark hasta módulos integrados como multiprocessing y threading.
Antes de profundizar en los detalles, examinemos las ideas y preceptos básicos sobre los que se construye el Python Distribuido:
Paralelismo frente a concurrencia
El paralelismo implica llevar a cabo múltiples tareas al mismo tiempo, mientras que la concurrencia se refiere a manejar muchas tareas que pueden seguir adelante concurrentemente pero no necesariamente simultáneamente. Tanto el paralelismo como la concurrencia están cubiertos por el Python distribuido, dependiendo de las tareas en cuestión y del diseño del sistema.
Distribución de tareas
Un componente clave de la computación paralela y distribuida es la distribución del trabajo entre varios nodos o unidades de procesamiento. Una distribución de trabajo efectiva es crucial para optimizar el rendimiento general, la eficiencia y el uso de recursos, ya sea que la ejecución de funciones en un programa computacional se paralelice en múltiples núcleos o que una tubería de procesamiento de datos se divida en etapas más pequeñas.
Comunicación y coordinación
La comunicación y coordinación efectivas entre nodos son esenciales en sistemas distribuidos para facilitar la orquestación de la ejecución de funciones remotas, flujos de trabajo complejos, intercambio de datos y sincronización del cómputo.
Los programas de Python distribuido se benefician de tecnologías como las colas de mensajes, estructuras de datos distribuidas y llamadas a procedimientos remotos (RPC) que permiten una coordinación y comunicación fluida entre la ejecución de funciones remotas y reales.
Fiabilidad y prevención de errores
La capacidad de un sistema para acomodar cargas de trabajo crecientes al agregar nodos o unidades de procesamiento en diferentes máquinas se refiere a la escalabilidad. Por el contrario, la tolerancia a fallas se refiere al diseño de sistemas que pueden soportar malfuncionamientos tales como fallos de máquinas, particiones de red y caídas de nodos y aún así funcionar de manera confiable.
Para garantizar la estabilidad y resiliencia de las aplicaciones distribuidas a lo largo de múltiples máquinas, los marcos de Python distribuido frecuentemente incluyen características de tolerancia a fallas y escalado automático.
Aplicaciones de Python distribuido
Procesamiento y análisis de datos: Se pueden procesar grandes conjuntos de datos en paralelo utilizando marcos de Python distribuidos como Apache Spark y Dask, lo que permite que las aplicaciones Python distribuidas realicen actividades como procesamiento por lotes, procesamiento de flujo en tiempo real y aprendizaje automático a escala.
Desarrollo web con microservicios: Se pueden crear aplicaciones web escalables y arquitecturas de microservicios con marcos web Python como Flask y Django junto con colas de tareas distribuidas como Celery. Las aplicaciones web pueden incorporar fácilmente características como almacenamiento en caché distribuido, manejo de solicitudes asincrónicas y procesamiento de trabajos en segundo plano.
Computación Científica y Simulación: La computación de alto rendimiento (HPC) y la simulación paralela sobre clusters de máquinas son posibles gracias al robusto ecosistema de Python de bibliotecas científicas y marcos de computación distribuida. Las aplicaciones incluyen análisis de riesgo financiero, modelado climático, aplicaciones de aprendizaje automático y simulaciones de física y biología computacional.
Computación en el Borde y el Internet de las Cosas (IoT): A medida que proliferen los dispositivos IoT y los diseños de computación en el borde, Python Distribuido se vuelve cada vez más importante para manejar datos de sensores, coordinar procesos de computación en el borde, construir aplicaciones distribuidas en conjunto y poner en práctica modelos de aprendizaje automático distribuidos para aplicaciones modernas en el borde.
Creación y uso de Python distribuido
Aprendizaje automático distribuido con Dask-ML
Una potente biblioteca llamada Dask-ML amplía el marco de computación paralela Dask para trabajos que involucran aprendizaje automático. Dividir la tarea entre varios núcleos o procesadores en un cluster de máquinas permite a los desarrolladores de Python entrenar y aplicar modelos de aprendizaje automático en grandes conjuntos de datos de manera distribuida y efectiva.
import dask.dataframe as dd
from dask_ml.model_selection import train_test_split
from dask_ml.xgboost import XGBoostClassifier
from sklearn.metrics import accuracy_score
# Load and prepare data (replace with your data loading logic)
df = dd.read_csv("training_data.csv")
X = df.drop("target_column", axis=1) # Features
y = df["target_column"] # Target variable
# Split data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# Define and train the XGBoost model in a distributed fashion
model = XGBoostClassifier(n_estimators=100) # Adjust hyperparameters as needed
model.fit(X_train, y_train)
# Make predictions on test data (can be further distributed)
y_pred = model.predict(X_test)
# Evaluate model performance (replace with your desired evaluation metric)
accuracy = accuracy_score(y_test, y_pred)
print(f"Model Accuracy: {accuracy}")import dask.dataframe as dd
from dask_ml.model_selection import train_test_split
from dask_ml.xgboost import XGBoostClassifier
from sklearn.metrics import accuracy_score
# Load and prepare data (replace with your data loading logic)
df = dd.read_csv("training_data.csv")
X = df.drop("target_column", axis=1) # Features
y = df["target_column"] # Target variable
# Split data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# Define and train the XGBoost model in a distributed fashion
model = XGBoostClassifier(n_estimators=100) # Adjust hyperparameters as needed
model.fit(X_train, y_train)
# Make predictions on test data (can be further distributed)
y_pred = model.predict(X_test)
# Evaluate model performance (replace with your desired evaluation metric)
accuracy = accuracy_score(y_test, y_pred)
print(f"Model Accuracy: {accuracy}")Llamadas a funciones paralelas con Ray
Con la ayuda del robusto marco de computación distribuida Ray, puede ejecutar funciones o tareas de Python simultáneamente en varios núcleos o computadoras de un clúster. Al utilizar el decorador @ray.remote, Ray le permite especificar funciones como remotas. Después de eso, estas tareas u operaciones remotas pueden ejecutarse asincrónicamente en los trabajadores de Ray del cluster.
import ray
import numpy as np
# Define the Monte Carlo simulation function
@ray.remote
def simulate(seed):
np.random.seed(seed) # Set random seed for reproducibility
# Perform your simulation logic here (replace with your specific simulation)
# This example simulates a random walk and returns the final position
steps = 1000
position = 0
for _ in range(steps):
position += np.random.choice([-1, 1])
return position
# Initialize Ray cluster (comment out if using existing cluster)
ray.init()
# Number of simulations to run
num_sims = 10000
# Run simulations in parallel using Ray's map function
simulations = ray.get([simulate.remote(seed) for seed in range(num_sims)])
# Analyze simulation results (calculate statistics like average final position)
average_position = np.mean(simulations)
print(f"Average final position: {average_position}")
# Shut down Ray cluster (comment out if using existing cluster)
ray.shutdown()import ray
import numpy as np
# Define the Monte Carlo simulation function
@ray.remote
def simulate(seed):
np.random.seed(seed) # Set random seed for reproducibility
# Perform your simulation logic here (replace with your specific simulation)
# This example simulates a random walk and returns the final position
steps = 1000
position = 0
for _ in range(steps):
position += np.random.choice([-1, 1])
return position
# Initialize Ray cluster (comment out if using existing cluster)
ray.init()
# Number of simulations to run
num_sims = 10000
# Run simulations in parallel using Ray's map function
simulations = ray.get([simulate.remote(seed) for seed in range(num_sims)])
# Analyze simulation results (calculate statistics like average final position)
average_position = np.mean(simulations)
print(f"Average final position: {average_position}")
# Shut down Ray cluster (comment out if using existing cluster)
ray.shutdown()Empezando
¿Qué es IronPDF?
Podemos crear, modificar y renderizar documentos PDF dentro de programas .NET con la ayuda del conocido paquete IronPDF for .NET. Trabajar con PDFs se puede hacer de muchas maneras diferentes: desde crear nuevos documentos PDF a partir de contenido HTML, fotografías o datos en bruto, hasta extraer texto e imágenes de documentos existentes, convertir páginas HTML a PDFs y agregar texto, imágenes y formas a los que ya existen.
La simplicidad y facilidad de uso de IronPDF son dos de sus principales beneficios. Los desarrolladores pueden comenzar a producir PDFs dentro de sus aplicaciones .NET con facilidad gracias a su API fácil de usar y documentación extensa. La velocidad y la eficiencia de IronPDF son dos características más que facilitan a los desarrolladores producir documentos PDF de alta calidad rápidamente.
Algunas ventajas de IronPDF:
- Creación de PDFs a partir de datos en bruto, imágenes y HTML.
- Extracción de imágenes y texto de archivos PDF.
- Incluir encabezados, pies de página y marcas de agua en los archivos PDF.
- Los archivos PDF están protegidos con contraseña y cifrado.
- La capacidad de llenar y firmar documentos electrónicamente.
Generación distribuida de PDF con IronPDF
La distribución de tareas entre numerosos núcleos o computadoras dentro de un clúster es posible gracias a marcos de Python distribuidos como Dask y Ray. Esto hace posible ejecutar tareas complejas como la generación de PDF en paralelo a través de un cluster y aprovechar múltiples núcleos dentro de ellos, lo que reduce drásticamente la cantidad de tiempo necesario para crear un gran lote de PDFs.
Comience instalando IronPDF y la biblioteca ray usando pip:
pip install ironpdf
pip install celerypip install ironpdf
pip install celeryAquí hay un código Python conceptual que demuestra dos métodos que utilizan IronPDF y Python para la generación distribuida de PDF:
Cola de tareas con un trabajador central
Trabajador Central (worker.py):
from ironpdf import ChromePdfRenderer
from celery import Celery
app = Celery('pdf_tasks', broker='pyamqp://')
app.autodiscover_tasks()
@app.task(name='generate_pdf')
def generate_pdf(data):
print(data)
renderer = ChromePdfRenderer() # Instantiate renderer
pdf = renderer.RenderHtmlAsPdf(str(data))
pdf.SaveAs("output.pdf")
return f"PDF generated for data {data}"
if __name__ == '__main__':
app.worker_main(argv=['worker', '--loglevel=info', '--without-gossip', '--without-mingle', '--without-heartbeat', '-Ofair', '--pool=solo'])from ironpdf import ChromePdfRenderer
from celery import Celery
app = Celery('pdf_tasks', broker='pyamqp://')
app.autodiscover_tasks()
@app.task(name='generate_pdf')
def generate_pdf(data):
print(data)
renderer = ChromePdfRenderer() # Instantiate renderer
pdf = renderer.RenderHtmlAsPdf(str(data))
pdf.SaveAs("output.pdf")
return f"PDF generated for data {data}"
if __name__ == '__main__':
app.worker_main(argv=['worker', '--loglevel=info', '--without-gossip', '--without-mingle', '--without-heartbeat', '-Ofair', '--pool=solo'])Script Cliente (client.py):
from celery import Celery
app = Celery('pdf_tasks', broker='pyamqp://localhost')
def main():
# Send task to worker
task = app.send_task('generate_pdf', args=("<h1>This is a sample PDF</h1>",))
print(task.get()) # Wait for task completion and print result
if __name__ == '__main__':
main()from celery import Celery
app = Celery('pdf_tasks', broker='pyamqp://localhost')
def main():
# Send task to worker
task = app.send_task('generate_pdf', args=("<h1>This is a sample PDF</h1>",))
print(task.get()) # Wait for task completion and print result
if __name__ == '__main__':
main()Celery es el sistema de cola de tareas que empleamos. Los trabajos se envían al trabajador central (worker.py) junto con datos que contienen contenido HTML. La función crea un PDF usando IronPDF y lo guarda.
El script del cliente (client.py) envía una tarea que contiene datos de muestra a la cola. Este script puede modificarse para enviar otras tareas desde diferentes computadoras.
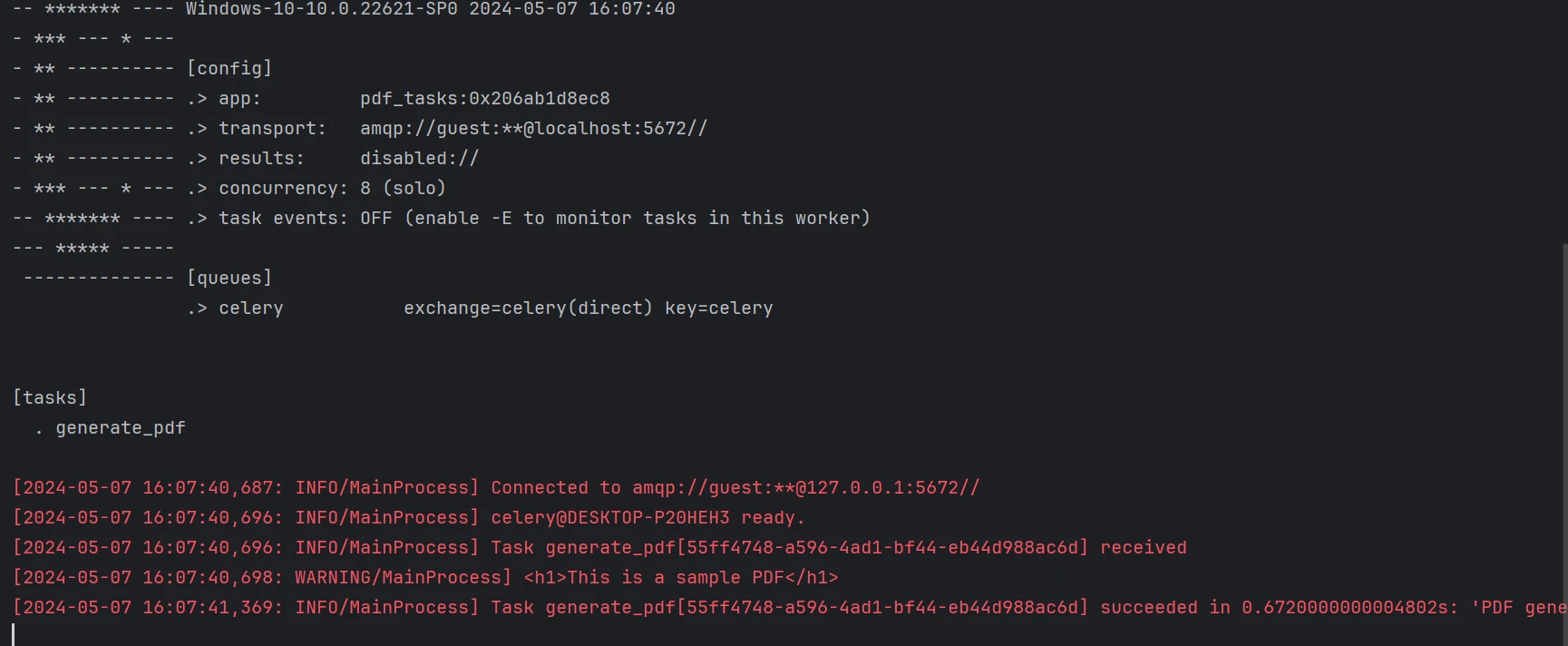
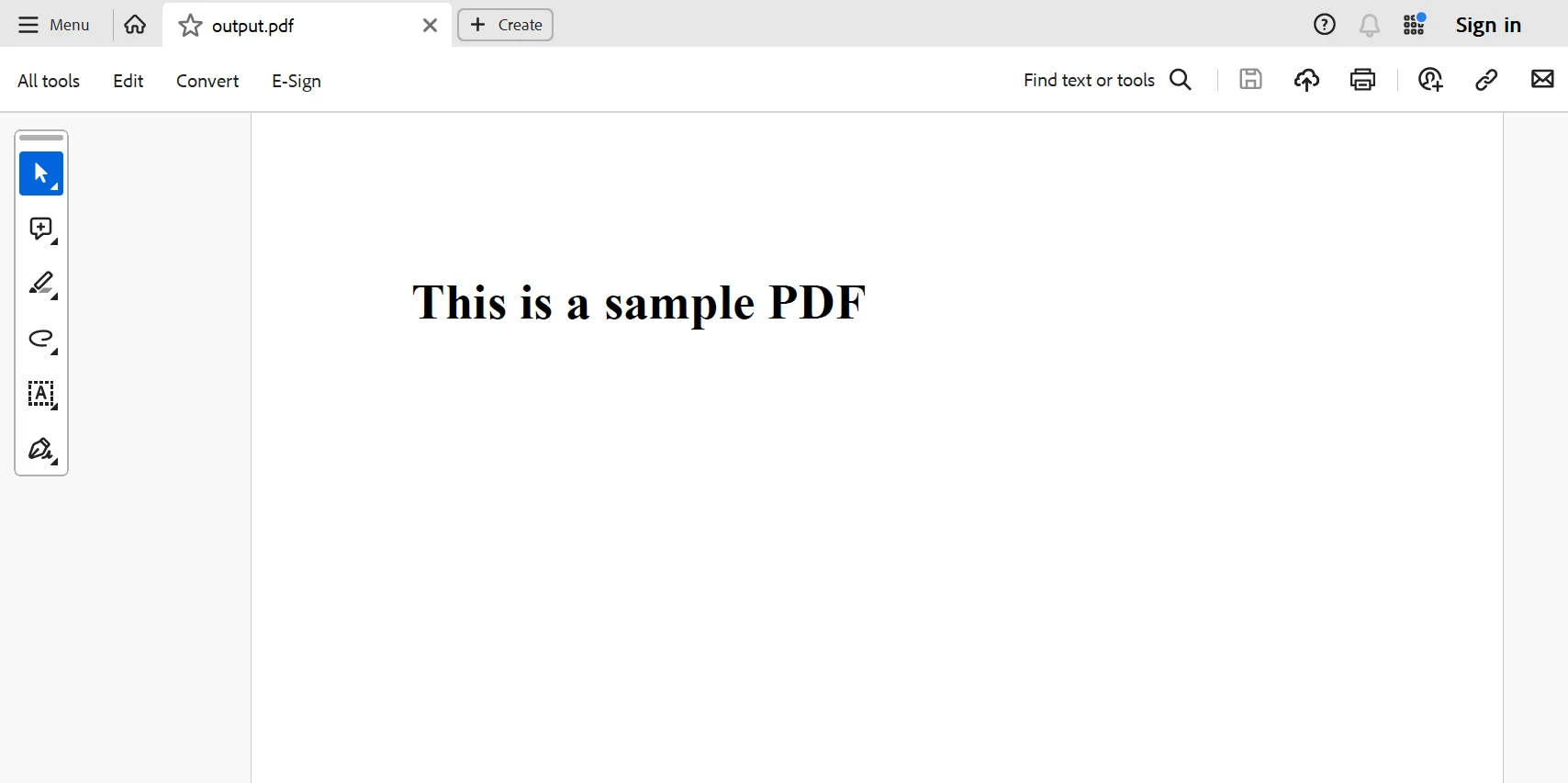
PDF generado a partir del código anterior.
Conclusión
Los usuarios de IronPDF que realizan actividades de creación de PDF a gran escala podrían liberar un enorme potencial al utilizar Python distribuido y bibliotecas como Ray o Dask. En comparación con ejecutar el código en una sola máquina, puede obtener mejoras significativas de velocidad al distribuir la misma carga de trabajo de código a través de múltiples núcleos y usarla a través de múltiples máquinas.
IronPDF puede pasar de ser una herramienta poderosa para crear archivos PDF en un solo sistema a una solución confiable para administrar de manera eficaz grandes conjuntos de datos mediante el uso del lenguaje de programación distribuido Python. Para aprovechar al máximo IronPDF en su próximo proyecto de creación de PDF a gran escala, investigue las bibliotecas de Python que se ofrecen y pruebe estos métodos.
IronPDF tiene un precio razonable cuando se compra como paquete y viene con una licencia de por vida. El paquete tiene un valor maravilloso y, para muchos sistemas, se puede comprar por solo $799. Proporciona soporte de ingeniería en línea 24/7 para los titulares de licencia. Para obtener información adicional sobre el cargo, por favor visite el sitio web. Para saber más sobre los productos que produce Iron Software, visite esta página.
















