
Cómo Extraer Texto De Un PDF Escaneado en Python
Extraer texto de archivos PDF, especialmente escaneados, puede ser un desafío. Sin embargo, este proceso puede simplificarse con las herramientas y técnicas adecuadas. Este tutorial le guiará en el uso de IronPDF, una biblioteca de Python, para extraer texto de un archivo PDF escaneado. Este artículo cubrirá cómo configurar su entorno, aplicar reconocimiento óptico de caracteres (OCR) y realizar la extracción de texto de manera efectiva.
1. Introducción a IronPDF
 La Biblioteca de PDF for Python
La Biblioteca de PDF for Python
IronPDF es una biblioteca versátil y potente diseñada para la manipulación y procesamiento de PDFs dentro del entorno de Python. Renombrada por su capacidad de integrarse perfectamente con aplicaciones de Python, IronPDF ofrece una variedad de funcionalidades que van más allá de la lectura y escritura de PDF esenciales. Destaca por su capacidad para convertir HTML a PDF, renderizar documentos PDF desde páginas web o códigos HTML crudos, y editar archivos PDF existentes.
Además, su función de Reconocimiento Óptico de Caracteres (OCR) es útil para extraer texto de documentos PDF escaneados. Es una herramienta de referencia para desarrolladores que manejan varias tareas relacionadas con PDFs. Ya sea para crear, modificar o extraer datos de archivos PDF, IronPDF es una solución sólida y confiable, atendiendo las diversas necesidades de los desarrolladores de Python en varias aplicaciones.
2. Requisitos previos
Antes de profundizar en el proceso de extracción de texto de PDFs, es esencial tener algunos prerrequisitos y bibliotecas necesarias en su lugar. Esto garantizará un flujo de trabajo fluido y efectivo a medida que avance.
- Entorno de Python: Asegúrese de tener Python instalado en su sistema informático. Python es un lenguaje de programación versátil, y su extenso soporte de bibliotecas lo hace ideal para tareas como la extracción de texto. Si no ha instalado Python, puede descargarlo del sitio web oficial de Python. Asegúrese de descargar una versión de Python que sea compatible con su sistema operativo.
- Instalación del SDK de .NET 6.0: Dado que IronPDF for Python aprovecha la biblioteca IronPDF for .NET, que está construida sobre .NET 6.0, es crucial tener el SDK de .NET 6.0 instalado en su sistema. Este SDK proporciona el tiempo de ejecución y las bibliotecas necesarias para que la biblioteca IronPDF funcione correctamente. Puede descargar e instalar el SDK de .NET 6.0 desde el sitio web oficial de Microsoft .NET.
- Biblioteca IronPDF for Python: IronPDF es una biblioteca robusta para trabajar con documentos PDF en Python. No solo facilita la extracción de texto, sino que también ofrece funcionalidades como la creación, edición y conversión de PDFs.
- Documento PDF Escaneado: Tenga un documento PDF escaneado listo para la extracción de texto. Este documento debería ser idealmente claro y legible, ya que la calidad del PDF escaneado puede impactar significativamente la precisión del OCR y del texto extraído.
- Comprensión Básica de Python: Una comprensión básica de la programación en Python es beneficiosa. La familiaridad con conceptos como variables, bucles y operaciones básicas de archivos le ayudará a navegar por el código y comprender el proceso de extracción de texto de manera más efectiva.
- Un Entorno de Desarrollo Adecuado: Aunque no es estrictamente necesario, tener un entorno de desarrollo como Visual Studio Code, PyCharm, o incluso un Jupyter Notebook puede hacer que su experiencia de codificación sea más manejable. Estos entornos proporcionan características como resaltado de sintaxis, autocompletado de código y herramientas de depuración que son extremadamente útiles al trabajar con scripts de Python.
Con estos prerrequisitos, está bien preparado para comenzar a extraer texto de documentos PDF escaneados usando la biblioteca IronPDF for Python. Los pasos subsecuentes lo guiarán a través de la instalación de IronPDF, cargando su documento PDF, aplicando OCR, extrayendo texto y utilizando los datos extraídos para sus necesidades específicas.
3. Guía paso a paso para extraer texto de un PDF escaneado
Paso 1: Instalar IronPDF
Primero, debe instalar la biblioteca IronPDF de Python en su entorno de Python. Esto se hace típicamente usando el gestor de paquetes de Python, pip. Abra su interfaz de línea de comandos y ejecute el siguiente comando:
pip install ironpdf
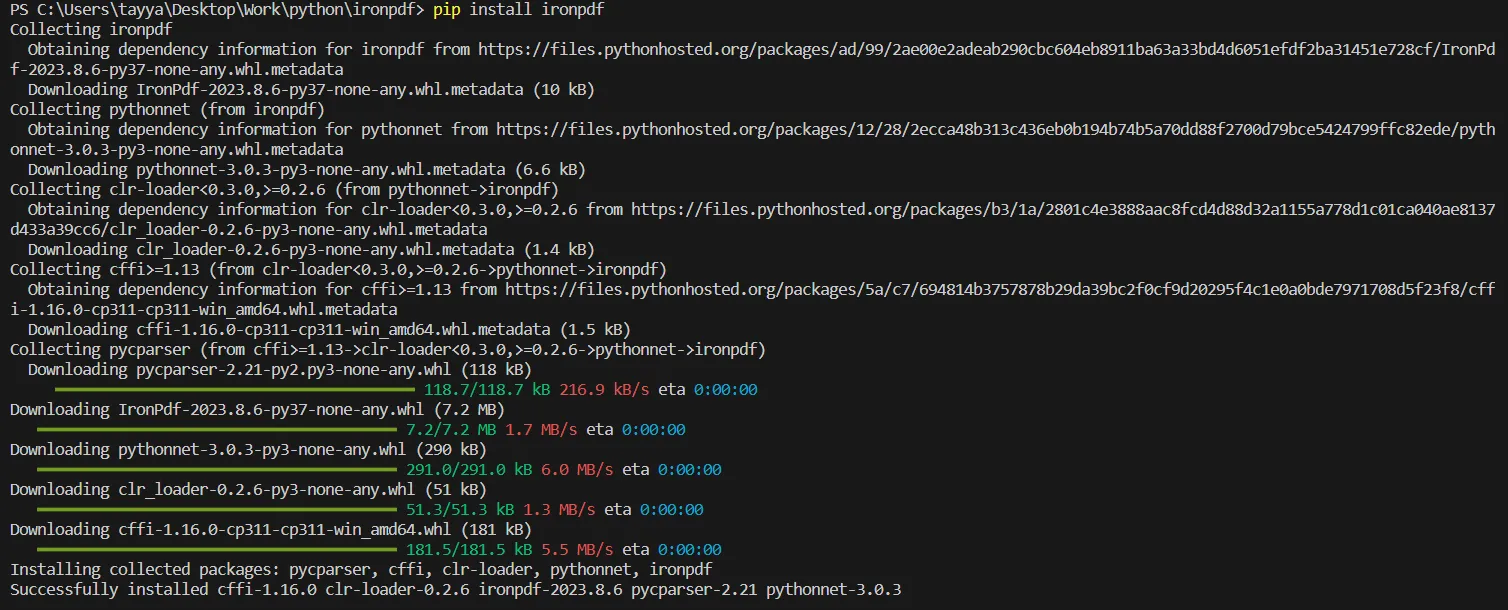 Instalar el paquete IronPDF
Instalar el paquete IronPDF
Paso 2: Importar IronPDF
Después de la instalación, importe la biblioteca IronPDF a su script de Python. Este paso es crucial para acceder a las funcionalidades proporcionadas por IronPDF:
import ironpdfimport ironpdfAl importar IronPDF, ahora puede usar sus clases y métodos en su script.
Paso 3: Solicite su clave de licencia
IronPDF requiere una clave de licencia para toda su funcionalidad. Si ha comprado una licencia, aplique su clave de licencia de la siguiente manera:
ironpdf.License.LicenseKey = "YOUR-LICENSE-KEY-HERE"ironpdf.License.LicenseKey = "YOUR-LICENSE-KEY-HERE"Sustituya "YOUR-LICENSE-KEY-HERE" por su clave de licencia real de IronPDF. Este paso es esencial para desbloquear todas las características de IronPDF sin limitaciones.
Paso 4: Cargar el archivo PDF escaneado
Para extraer texto, comience cargando el documento PDF en su script:
pdf = ironpdf.PdfDocument.FromFile("scannedpdf.pdf")pdf = ironpdf.PdfDocument.FromFile("scannedpdf.pdf")Aquí, "scannedpdf.pdf" debe sustituirse por la ruta de archivo real del documento PDF que se desea procesar. Este comando lee el archivo PDF y lo prepara para la extracción de texto.
Paso 5: Extraer texto del archivo PDF
Una vez cargado el PDF, ya puede extraer texto utilizando el método ExtractAllText() de IronPDF, tal y como se muestra en el siguiente código:
text = pdf.ExtractAllText()text = pdf.ExtractAllText()Esta línea de código procesa todo el documento PDF y extrae su contenido de texto, almacenándolo en la variable text.
Paso 6: Procesar y utilizar el texto extraído
Tras la extracción, los datos de texto están disponibles en la variable text. Puede imprimir este texto en la consola o procesarlo más de acuerdo a sus necesidades:
print(text)
# Additional code here to process or utilize the extracted textprint(text)
# Additional code here to process or utilize the extracted textEste paso puede implicar diversas operaciones como guardar el texto extraído en un archivo, realizar análisis de datos de texto, o integrarlo en una base de datos o una aplicación web. Aquí puede ver la salida del código anterior.
Texto de salida
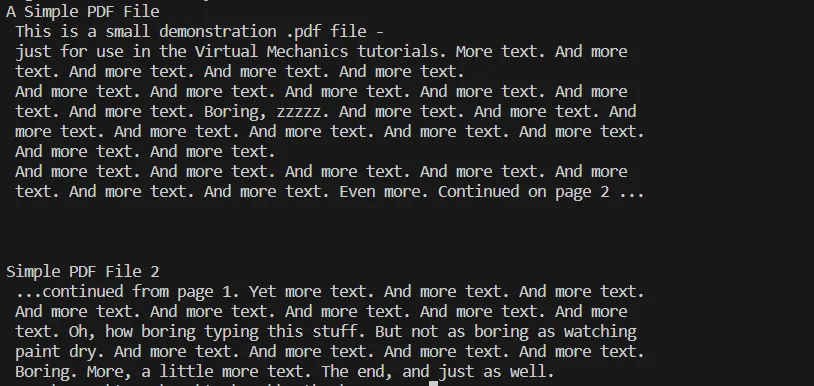 Salida de consola del proceso anterior de extracción de texto del archivo PDF
Salida de consola del proceso anterior de extracción de texto del archivo PDF
Paso 7: Operaciones adicionales (opcional)
Las capacidades de IronPDF se extienden más allá de la extracción de texto. Dependiendo de los requisitos de su proyecto, puede explorar características adicionales como la edición de PDFs, la conversión de PDFs a diferentes formatos, o incluso la generación de PDFs desde HTML.
4. Técnicas avanzadas
4.1 Manejo de elementos no textuales
Los PDFs escaneados a menudo contienen elementos no textuales como imágenes o gráficos. Mientras que el OCR se centra en el texto, puede que desee manejar estos elementos de manera diferente. Podría necesitar bibliotecas adicionales de Python para procesar o ignorar el contenido no textual.
4.2 Mejorar la precisión del OCR
La precisión de la extracción de texto puede variar según la calidad de los documentos escaneados. Para mejorar los resultados del OCR, asegúrese de que su PDF escaneado sea de alta calidad y que el texto sea lo más claro posible.
4.3 Conversión a otros formatos
Después de extraer el texto del PDF, puede que desee convertirlo a otros formatos como CSV, JSON o XML para un procesamiento posterior. IronPDF permite tales conversiones, proporcionándole opciones flexibles para el manejo de datos.
5. Solución de problemas comunes
Cuando se trabaja con OCR y extracción de texto, puede encontrar problemas tales como:
- Baja precisión del OCR debido a escaneos de baja calidad.
- Texto faltante si el OCR no reconoce algunos caracteres.
- Errores al cargar archivos PDF grandes.
Para solucionar estos problemas, asegúrese de que sus archivos PDF escaneados sean claros y de alta calidad, considere dividir archivos grandes en más pequeños y verifique que su biblioteca IronPDF esté actualizada.
Conclusión
Extraer texto de un archivo PDF escaneado se puede lograr sin problemas usando la biblioteca de Python IronPDF. Siguiendo los pasos detallados en este tutorial, puede convertir un documento escaneado no buscable en un formato enriquecido de texto que se puede procesar y analizar rápidamente. Recuerde manejar cada página PDF cuidadosamente y aplicar OCR para convertir su PDF escaneado en un archivo PDF buscable. Con el texto extraído, las posibilidades para la manipulación y utilización de datos son vastas, allanando el camino para soluciones innovadoras y flujos de trabajo optimizados.
En resumen, este artículo cubrió la instalación y configuración de IronPDF, la carga de archivos PDF, la aplicación de tecnología OCR para hacer que un PDF escaneado sea buscable, el proceso real de extracción de texto y el manejo de múltiples páginas de PDF. También tocó técnicas avanzadas y solución de problemas comunes. Con este conocimiento, puede extraer datos de texto de documentos PDF usando Python.
IronPDF ofrece una prueba gratuita para acceso a todas las características, permitiendo a los usuarios evaluar las capacidades de manipulación de PDF y de extracción de texto. Tras el periodo de prueba, la licencia de pago tiene un precio a partir de $999, y está pensada para uso profesional y comercial con un completo conjunto de funciones. IronPDF es gratuito para el desarrollo, permitiendo a los desarrolladores integrar y probar sus funcionalidades sin costo durante la fase de desarrollo de la aplicación.
Preguntas Frecuentes
¿Cómo configuro mi entorno para extraer texto de PDFs escaneados usando Python?
Para configurar tu entorno, instala el SDK de .NET 6.0 y la biblioteca IronPDF usando el gestor de paquetes de Python con pip install ironpdf. Asegúrate de tener un entorno de Python y un entorno de desarrollo adecuado como Visual Studio Code o PyCharm.
¿Qué es el reconocimiento óptico de caracteres (OCR) y cómo se aplica en Python?
El reconocimiento óptico de caracteres (OCR) es una tecnología usada para convertir diferentes tipos de documentos, como documentos en papel escaneados o PDFs, en datos editables y buscables. En Python, puedes aplicar OCR usando IronPDF cargando un PDF escaneado y usando las funcionalidades OCR de la biblioteca para extraer texto.
¿Cómo puedo asegurar una extracción de texto precisa de PDFs escaneados?
Para asegurar una extracción de texto precisa, utiliza PDFs escaneados de alta calidad, ya que la precisión de OCR mejora con escaneos más claros y de mejor calidad. Con IronPDF, puedes aplicar OCR para extraer texto y procesarlo según sea necesario.
¿Qué pasos están involucrados en la extracción de texto de un PDF escaneado usando IronPDF?
Los pasos incluyen instalar IronPDF, importar la biblioteca, aplicar una clave de licencia, cargar tu PDF escaneado, aplicar OCR y usar el método ExtractAllText() para extraer el texto.
¿Puedo convertir el texto extraído en formatos como CSV, JSON o XML?
Sí, una vez extraído el texto de un PDF escaneado usando IronPDF, puedes convertirlo en varios formatos como CSV, JSON o XML para análisis o manipulación de datos.
¿Cuáles son algunos pasos comunes de solución de problemas si la extracción de texto falla?
Si la extracción de texto falla, verifica la calidad del PDF escaneado. Asegúrate de que IronPDF esté correctamente instalado y que tu entorno de desarrollo esté adecuadamente configurado. También, verifica que los métodos correctos y las funcionalidades OCR estén siendo utilizados.
¿Hay una versión de prueba disponible para IronPDF?
Sí, IronPDF ofrece una versión de prueba gratuita para que los usuarios evalúen sus capacidades. Se requiere una licencia de pago para la funcionalidad completa después del periodo de prueba.
















