body parser node (Comment ça marche pour les développeurs)
Avec son architecture d'E/S non bloquante et axée sur les événements, Node.js, un puissant moteur d'exécution JavaScript basé sur le moteur V8 de JavaScript de Chrome, a complètement changé le développement web côté serveur. Analyser les corps de requêtes entrants est une étape courante du processus de traitement rapide des requêtes HTTP avec Node.js, ce qui est essentiel pour le développement web et la création d'applications web fiables. Le middleware body-parser est utile dans cette situation.
Body-parser est un middleware pour le célèbre framework Node.js Express.js qui facilite l'accès et la modification des données envoyées par le client en simplifiant le processus d'analyse des corps de requêtes entrants avant vos gestionnaires. Le middleware Body-parser offre une méthode efficace pour gérer différents types de contenu, tels que les charges utiles JSON, les formulaires codés en URL ou le texte brut, afin que votre application puisse traiter les entrées utilisateur de manière efficace.
D'autre part, IronPDF est une bibliothèque puissante de génération PDF pour Node.js. Cela permet aux développeurs de créer, modifier et manipuler des documents PDF de manière programmatique avec facilité. Combiner body-parser avec IronPDF ouvre un éventail de possibilités pour les applications web qui ont besoin de gérer les entrées utilisateurs et de générer des documents PDF dynamiques basés sur ces données.
Dans cet article, nous explorerons comment intégrer body-parser avec Node.js pour gérer les requêtes HTTP et utiliser ensuite IronPDF pour générer des documents PDF à partir de l'objet corps déjà analysé. Cette combinaison est particulièrement utile pour les applications nécessitant la génération de rapports automatisés, la création de factures ou tout scénario où un contenu PDF dynamique est nécessaire.
Principales caractéristiques du Body Parser
Analyse JSON
Analyse les corps de requêtes au format JSON, simplifiant la gestion des données JSON dans les API à l'aide de ces analyseurs de corps.
Analyse des données codées en URL
Analyse les données codées avec une URL, couramment rencontrées dans les soumissions de formulaires HTML. Les structures d'objets basiques et sophistiquées sont prises en charge.
Analyse des données brutes
Analyse les données binaires brutes des requêtes entrantes, ce qui aide à gérer les formats de données uniques et les types de contenu non standard.
Analyse des données textuelles
Analyse les requêtes entrantes pour les données de texte brut, ce qui simplifie le traitement du contenu basé sur le texte.
Limites de taille configurables
Permet d'établir des limitations de taille du corps de la requête pour éviter que des charges lourdes n'encombrent le serveur. Cela aide à améliorer la sécurité et à contrôler l'utilisation des ressources.
Détection automatique du type de contenu
Gère différents types de contenu plus efficacement en identifiant et en traitant automatiquement le corps de la requête en fonction de l'en-tête Content-Type, éliminant le besoin d'interaction manuelle.
Gestion des erreurs
Gestion des erreurs robuste pour garantir que les applications peuvent réagir poliment aux requêtes qui posent problème, telles que les formats de média non valides, les JSON malformés ou les corps excessivement grands.
Intégration avec d'autres middlewares
Permet une pile de middlewares modulaire et bien organisée en s'intégrant parfaitement avec le middleware Express existant. Cela améliore la maintenabilité et la flexibilité de l'application.
Options de configuration étendues
Fournit des options de configuration pour modifier le comportement du processus d'analyse, comme modifier le type d'encodage pour l'analyse du texte ou définir la profondeur de traitement pour les données codées en URL.
Optimisation des performances
Gère efficacement les opérations d'analyse, réduisant la surcharge de performance, et garantissant que le programme reste réactif même dans des situations de charge lourde.
Créer et configurer Body Parser dans Node.js
Pour utiliser Express.js afin de construire et de configurer Body Parser dans une application Node.js
Installer Express et Body-Parser
Installez les packages Express et Body-Parser en utilisant ces commandes npm dans la ligne de commande :
npm install express
npm install body-parsernpm install express
npm install body-parserCréer et configurer l'application
Dans le répertoire de votre projet, créez un nouveau fichier JavaScript appelé app.js, et configurez le middleware body-parser pour l'application Express :
const express = require('express');
const bodyParser = require('body-parser');
const app = express();
// Use body-parser middleware to parse JSON and URL-encoded data
app.use(bodyParser.json());
app.use(bodyParser.urlencoded({ extended: true }));
// Example route that handles POST requests using the req.body property
app.post('/submit', (req, res) => {
const data = req.body;
res.send(`Received data: ${JSON.stringify(data)}`);
});
// Start the server
const PORT = process.env.PORT || 3000;
app.listen(PORT, () => {
console.log(`Server is running on port ${PORT}`);
});const express = require('express');
const bodyParser = require('body-parser');
const app = express();
// Use body-parser middleware to parse JSON and URL-encoded data
app.use(bodyParser.json());
app.use(bodyParser.urlencoded({ extended: true }));
// Example route that handles POST requests using the req.body property
app.post('/submit', (req, res) => {
const data = req.body;
res.send(`Received data: ${JSON.stringify(data)}`);
});
// Start the server
const PORT = process.env.PORT || 3000;
app.listen(PORT, () => {
console.log(`Server is running on port ${PORT}`);
});Gestion des différents types de contenu
De plus, nous pouvons configurer Body Parser pour gérer plusieurs types de données, y compris le texte brut ou les données binaires brutes de :
Analyse des données brutes
app.use(bodyParser.raw({ type: 'application/octet-stream' }));app.use(bodyParser.raw({ type: 'application/octet-stream' }));Analyse des données textuelles
app.use(bodyParser.text({ type: 'text/plain' }));app.use(bodyParser.text({ type: 'text/plain' }));Gestion des erreurs
Un middleware pour la gestion des erreurs peut être utilisé pour gérer les problèmes potentiels qui surviennent lors de l'analyse du corps.
app.use((err, req, res, next) => {
if (err) {
res.status(400).send('Invalid request body');
} else {
next();
}
});app.use((err, req, res, next) => {
if (err) {
res.status(400).send('Invalid request body');
} else {
next();
}
});Commencer avec IronPDF
Qu'est-ce qu'IronPDF ?
Avec IronPDF, les développeurs peuvent produire, modifier et manipuler des documents PDF de manière programmatique. IronPDF est une bibliothèque robuste de génération de PDF pour Node.js avec prise en charge de plusieurs fonctionnalités, y compris le style, le script, et les mises en page complexes. Il facilite le processus de conversion du contenu HTML en PDF.
Les rapports dynamiques, les factures et autres documents peuvent être générés directement à partir des applications web avec IronPDF. C'est une solution flexible pour toute application nécessitant des capacités PDF car il s'intègre facilement avec Node.js et d'autres frameworks. IronPDF est l'outil incontournable pour les développeurs qui veulent une création et une modification de PDF fiables grâce à son ensemble étendu de fonctionnalités et sa facilité d'utilisation.
Caractéristiques principales d'IronPDF
Conversion HTML en PDF
Permet des mises en page sophistiquées, CSS et JavaScript lors de la conversion du contenu HTML en documents PDF. Permet aux développeurs de créer des PDF en utilisant des modèles web préexistants.
Options avancées pour le rendu
Offre des choix de numérotation de page, de pied de page et d'en-tête. Les filigranes, les images de fond, et d'autres éléments de mise en page sophistiqués sont pris en charge.
Éditer et manipuler des PDF
Permet des modifications de page, la fusion de pages et la division de pages dans des documents PDF déjà existants. Permet l'ajout, la suppression ou le réarrangement de pages au sein d'un PDF.
Installer IronPDF
Pour activer la fonctionnalité IronPDF, installez le package nécessaire dans Node.js en utilisant le gestionnaire de packages Node.
npm install @ironsoftware/ironpdfnpm install @ironsoftware/ironpdfCréer un PDF de rapport avec IronPDF
Avec IronPDF et Body Parser fonctionnant ensemble dans Node.js, les développeurs peuvent gérer les données des requêtes et produire efficacement des documents PDF dynamiques. Voici un guide détaillé pour configurer et utiliser ces fonctionnalités dans une application Node.js.
Créez l'application Express en utilisant Body Parser et IronPDF, puis créez un fichier appelé app.js.
const express = require('express');
const bodyParser = require('body-parser');
const IronPdf = require("@ironsoftware/ironpdf");
const app = express();
// Middleware to parse JSON and URL-encoded data
app.use(bodyParser.json());
app.use(bodyParser.urlencoded({ extended: true }));
// Route to handle PDF generation
app.post('/generate-pdf', async (req, res) => {
const data = req.body;
// HTML content to be converted into PDF
const htmlContent = `
<html>
<head></head>
<body>
<h1>${JSON.stringify(data, null, 2)}</h1>
</body>
</html>
`;
try {
// Create an instance of IronPDF document
const document = await IronPdf.PdfDocument.fromHtml(htmlContent);
// Convert to PDF buffer
let pdfBuffer = await document.saveAsBuffer();
// Set response headers to serve the PDF
res.setHeader('Content-Type', 'application/pdf');
res.setHeader('Content-Disposition', 'attachment; filename=generated.pdf');
// Send the PDF as the response
res.send(pdfBuffer);
} catch (error) {
console.error('Error generating PDF:', error);
res.status(500).send('Error generating PDF');
}
});
// Start the server
const PORT = process.env.PORT || 3000;
app.listen(PORT, () => {
console.log(`Server is running on port ${PORT}`);
});const express = require('express');
const bodyParser = require('body-parser');
const IronPdf = require("@ironsoftware/ironpdf");
const app = express();
// Middleware to parse JSON and URL-encoded data
app.use(bodyParser.json());
app.use(bodyParser.urlencoded({ extended: true }));
// Route to handle PDF generation
app.post('/generate-pdf', async (req, res) => {
const data = req.body;
// HTML content to be converted into PDF
const htmlContent = `
<html>
<head></head>
<body>
<h1>${JSON.stringify(data, null, 2)}</h1>
</body>
</html>
`;
try {
// Create an instance of IronPDF document
const document = await IronPdf.PdfDocument.fromHtml(htmlContent);
// Convert to PDF buffer
let pdfBuffer = await document.saveAsBuffer();
// Set response headers to serve the PDF
res.setHeader('Content-Type', 'application/pdf');
res.setHeader('Content-Disposition', 'attachment; filename=generated.pdf');
// Send the PDF as the response
res.send(pdfBuffer);
} catch (error) {
console.error('Error generating PDF:', error);
res.status(500).send('Error generating PDF');
}
});
// Start the server
const PORT = process.env.PORT || 3000;
app.listen(PORT, () => {
console.log(`Server is running on port ${PORT}`);
});Dans cette configuration, IronPDF est utilisé pour générer des PDF tandis que les fonctionnalités du Body Parser Node.js sont combinées. Pour commencer, nous importons les modules requis, tels que IronPDF pour la génération de PDF, Body Parser pour l'analyse du corps des requêtes entrantes, et Express pour la construction du serveur. Ensuite, nous configurons le middleware Express pour analyser les données de formulaire JSON et codées URL en utilisant Body Parser.
Pour gérer les requêtes POST, nous établissons une route appelée generate-pdf, où nous recevons le contenu du corps de la requête. Ces données au format JSON sont intégrées dans un modèle HTML qui sera utilisé comme contenu du PDF. Nous instancions un document en utilisant IronPdf et transformons le contenu HTML en un document PDF.
Après que le PDF a été généré avec succès, nous envoyons la réponse avec les en-têtes appropriés pour indiquer le nom du fichier et le type de contenu. La gestion des erreurs garantit que tout problème survenant lors de la création de PDF est identifié, enregistré et communiqué au client avec des codes d'état pertinents.
Sortie
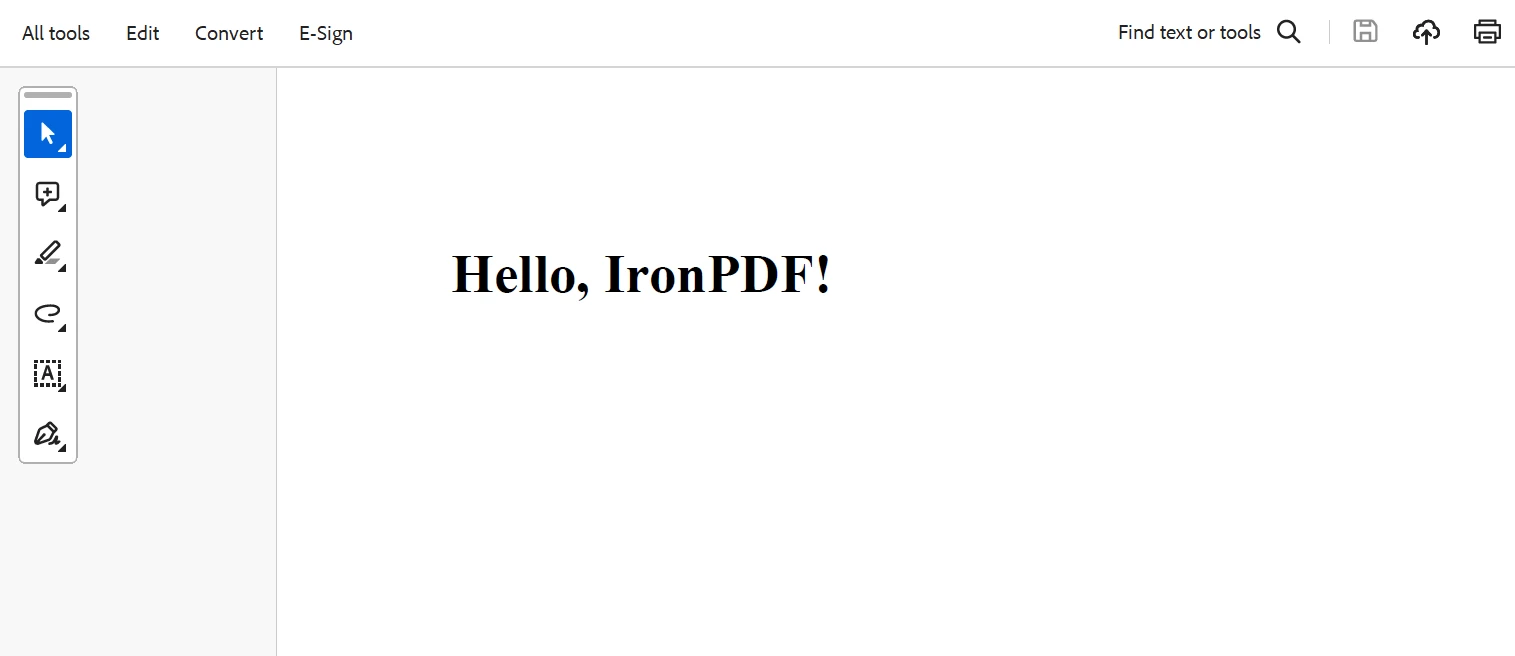
Enfin, le serveur est lancé et attend sur un port désigné les requêtes entrantes. Avec cette configuration, la gestion des requêtes avec Body Parser et la génération dynamique de PDF avec IronPDF peuvent être facilement intégrées dans une application Node.js, permettant des flux de travail plus efficaces pour le traitement des données et la génération de documents.
Conclusion
Pour résumer, la combinaison d'IronPDF et de Body Parser dans Node.js fournit un moyen stable de gérer les données du corps des requêtes HTTP et de créer des documents PDF dynamiques à utiliser dans les applications en ligne. Les développeurs peuvent plus facilement accéder et modifier les données entrantes en utilisant Body Parser, ce qui simplifie le processus d'analyse de différents types de corps de requêtes.
IronPDF, quant à lui, possède des capacités robustes pour produire des documents PDF de haute qualité avec des fonctionnalités avancées, un formatage et un style à partir de textes HTML. Les développeurs peuvent générer des documents PDF personnalisés basés sur des données d'application ou des entrées utilisateur plus rapidement en combinant ces technologies. Avec l'aide de cette intégration, les applications Node.js peuvent désormais gérer plus efficacement le contenu généré par l'utilisateur et produire des PDF d'un aspect professionnel.
Nous pouvons garantir des solutions logicielles riches en fonctionnalités et de haute qualité pour les clients et les utilisateurs finaux en intégrant IronPDF et les produits Iron Software dans votre pile de développement. De plus, cela aidera à l'optimisation des projets et des processus. Les tarifs Iron Software commencent à $999 et ils sont des collaborateurs fiables pour les projets de développement de logiciels modernes grâce à leur documentation exhaustive, leur communauté dynamique et leurs mises à jour fréquentes.