

Node.jsでPDFファイルを読む方法
進化を続ける Web 開発の世界において、Node.js は、開発者がスケーラブルで効率的なアプリケーションを構築できる強力なプラットフォームとして登場しました。 Node.js の魅力的な側面の 1 つは、さまざまなライブラリやモジュールとシームレスに連携して機能を拡張できることです。 この記事では、Node.js PDF リーダー機能の領域を詳しく調べ、 IronPDFライブラリと、それを活用して PDF ファイルを処理する方法について説明します。
Node.js PDF リーダーとは何ですか?
Node.js PDF Reader は、Node.js 環境内で PDF (Portable Document Format) ファイルの読み取りと操作を容易にするために設計された専用ツールです。 PDF ファイルは、さまざまなプラットフォーム間でフォーマットが一貫しているため、ドキュメントの共有に広く使用されています。 Node.js アプリケーションに PDF 読み取り機能を組み込むと、情報の抽出から動的なレポートの生成まで、さまざまな可能性が広がります。
Node.js PDF リーダーを使用して PDF を読む方法は?
- Node.js PDF リーダー ライブラリをインストールします。
- 必要な依存関係をインポートします。
PdfDocument.openメソッドを使用してPDFファイルを開きます。extractTextメソッドを使用してPDFファイルからテキストを抽出します。console.logメソッドを使用して、抽出されたテキストをコンソールに表示します。
2. Node.js 用 IronPDF の紹介
IronPDF は、Node.js エコシステムで PDF ファイルを操作するための包括的なライブラリです。 さまざまな機能を提供するため、プログラムで PDF ドキュメントを操作する必要がある開発者にとって最適な選択肢となります。 Iron Software チームによって開発された IronPDF は、そのシンプルさと Node.js プロジェクトへの統合の容易さで際立っています。
2.1. IronPDFの主な機能
- PDF 生成: IronPDF を使用すると、開発者はコンテンツ、書式、レイアウトを完全に制御しながら、PDF ドキュメントをゼロから作成できます。
- PDF 解析:このライブラリを使用すると、既存の PDF ファイルからテキスト、画像、その他の要素を抽出できるため、開発者はこれらのドキュメント内に保存されているデータを操作できるようになります。
- PDF の変更: IronPDF は既存の PDF ファイルの変更をサポートしており、コンテンツを動的に追加、削除、更新することができます。
- PDF レンダリング: IronPDF を使用すると、開発者は画像やHTML などさまざまな形式で PDF ファイルをレンダリングできるため、Web アプリケーション内で PDF コンテンツを表示する可能性が広がります。 5.クロスプラットフォームの互換性: IronPDF は、さまざまなオペレーティング システム間でシームレスに動作するように設計されており、展開環境に関係なく一貫した動作を保証します。
2.2. IronPDFのインストール
IronPDF の機能の詳細に入る前に、Node.js プロジェクトにライブラリをインストールすることが重要です。 インストール プロセスは簡単で、NPM パッケージ マネージャーを使用して実行できます。 ターミナルを開き、次のコマンドを実行してください。
npm install @ironsoftware/ironpdfnpm install @ironsoftware/ironpdfこのコマンドは、IronPDF ライブラリをインストールし、Node.js アプリケーションで使用できるようにします。
IronPDF ライブラリを使用するために必須の IronPDF エンジンをインストールするには、コンソールで次のコマンドを実行します。
npm install @ironsoftware/ironpdf-engine-windows-x64npm install @ironsoftware/ironpdf-engine-windows-x643. Node.jsとIronPDFでPDFファイルを読む
Node.js と IronPDF を使用して PDF ファイルを読み取るには、一連の簡単な手順を実行する必要があります。提供されているコード例では、これを実現するための簡潔かつ強力なアプローチが示されています。 コードは、IronPDFライブラリの@ironsoftware/ironpdf パッケージからPdfDocument クラスを利用してPDFファイルを開き、テキストを抽出します。コードをステップごとに分解しましょう:
PdfDocumentのインポート:import { PdfDocument } from "@ironsoftware/ironpdf";import { PdfDocument } from "@ironsoftware/ironpdf";JAVASCRIPTコードは、IronPDFライブラリから
PdfDocumentクラスをインポートすることから始まります。 このクラスは、PDF ドキュメントを開く、テキストを抽出、さまざまな操作を実行するなど、PDF ドキュメントを操作するためのメソッドを提供します。PDFファイルを開く:
const pdf = await PdfDocument.open("output.pdf");const pdf = await PdfDocument.open("output.pdf");JAVASCRIPTPdfDocument.openメソッドは、PDFファイルを開くために使用されます。この例では、"output.pdf" ファイルが指定されています。openメソッドがプロミスを返すため、awaitキーワードが使用されます。これにより、PDFが完全にロードされるまでコードが次のステップに進まないことが保証されます。PDFからテキストを抽出する:
const text = await pdf.extractText();const text = await pdf.extractText();JAVASCRIPTPDFが開かれると、
pdfオブジェクトに対してextractTextメソッドが呼び出されます。 このメソッドは、PDF ドキュメントからテキスト コンテンツを非同期的に抽出します。 結果はtext変数に格納されます。
4.抽出したテキストの記録:
```javascript
console.log(text);
```
最後に、抽出されたテキストが`console.log` を使用してコンソールに記録されます。 この手順は、開発者がテキスト抽出プロセスが成功したことを確認し、サンプル PDF から抽出されたコンテンツを検査するために重要です。async関数ラッパー:(async () => { // Code goes here })();(async () => { // Code goes here })();JAVASCRIPT全体のコードは非同期関数に包まれており、
asyncキーワードを用いた即時実行関数式 (IIFE) を使用しています。 これにより、関数内でawaitを使用することが可能となり、非同期操作(PDFのロードやテキスト抽出など)が可能になります。
要約すると、このコードは、Node.js と IronPDF を使用して PDF ファイルを読み取るための簡潔かつ効果的な方法を示しています。 IronPDF ライブラリの機能を活用することで、開発者は PDF ドキュメントを簡単に開き、テキスト コンテンツを抽出し、これらの機能を Node.js アプリケーションに統合できます。
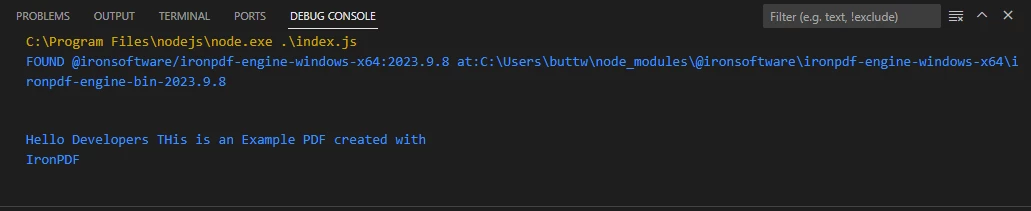 サンプルPDFファイルから抽出したテキスト
サンプルPDFファイルから抽出したテキスト
3.1. パスワード保護されたPDFファイルの読み取り
パスワードで保護された PDF ファイルを読み取るには、ドキュメントのコンテンツを保護する追加のセキュリティ層に対処する必要があります。 このような場合、パスワード認証をサポートする IronPDF などの PDF 読み取りライブラリを使用することが重要です。
このプロセスでは、ファイルを開く段階で正しいパスワードを入力し、PDF 内のコンテンツの暗号化を解除します。 これにより、許可されたユーザーのみがパスワードで保護された PDF ファイルにアクセスして情報を抽出できるようになり、これらのドキュメントに含まれる機密データのセキュリティが強化されます。
const pdf = await PdfDocument.open("encrypted.pdf", "password");const pdf = await PdfDocument.open("encrypted.pdf", "password");上記のコードを使用すると、ユーザーはパスワードで保護された PDF ファイルの内容を読み取ることができます。
3.2. PDFファイルのメタデータの読み取り
Node.js 用の IronPDF は、PDF ファイルのメタデータを読み取る機能を提供します。 以下のコードは、PDF ファイルからメタデータを読み取る方法を示しています。
import { PdfDocument } from "@ironsoftware/ironpdf";
(async () => {
// Step 1. Import a PDF
const pdf = await PdfDocument.open("output.pdf");
const metadata = await pdf.getMetadata();
console.log("\n");
console.log(metadata);
})();import { PdfDocument } from "@ironsoftware/ironpdf";
(async () => {
// Step 1. Import a PDF
const pdf = await PdfDocument.open("output.pdf");
const metadata = await pdf.getMetadata();
console.log("\n");
console.log(metadata);
})();出力
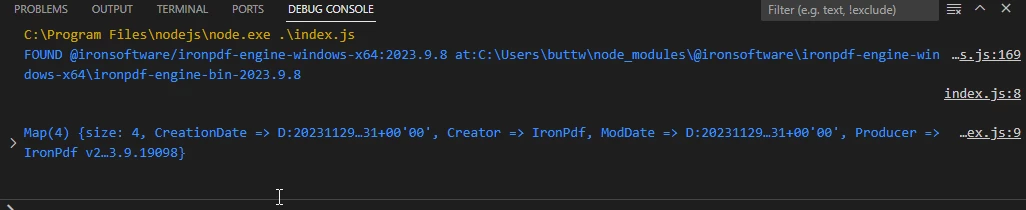 サンプルPDFファイルから抽出したメタデータ
サンプルPDFファイルから抽出したメタデータ
4. 結論
結論として、Node.js PDF リーダーは、特に IronPDF ライブラリを利用する場合、PDF ファイルを扱う開発者に無限の可能性をもたらします。 テキストや画像を抽出したり、既存のドキュメントを動的に変更したりする場合でも、IronPDF は Node.js 環境で PDF を処理するための多目的なツール セットを提供します。 また、表形式のデータもサポートしており、PDF リーダー モジュールはテキスト エントリを抽出します。
Node.js PDF Reader と IronPDF を使い始めるには、この記事に記載されている手順に従ってください。 より詳細な情報や高度な使用例については、ドキュメントを参照してください。 適切なツールと知識があれば、PDF 読み取り機能をシームレスに統合して Node.js アプリケーションを強化できます。
Node.js に IronPDF を使用する理由は何ですか?
- 無料トライアル: IronPDF for Node.jsは、IronPDF for Node.jsの無料トライアルを提供しており、開発者がその機能を試すことができます。 この試用期間により、ユーザーは金銭的な負担なく、特定の PDF 関連タスクに対するライブラリの適合性を評価できます。 2.機能豊富: IronPDF for Node.js は機能豊富で、Node.jsでPDFファイルを扱うための包括的な機能セットを提供します。 このライブラリは、PDF 生成からテキスト抽出、ドキュメントの変更まで、強力なツールキットを提供しており、幅広いアプリケーションに幅広く使用できます。 3.コード例とドキュメント/サポート: IronPDF は広範なドキュメントとサポートを提供しており、開発者が機能を簡単に統合して利用できるようになります。 ライブラリは、詳細なNode.jsのPDF変換例が付属しており、スムーズな学習曲線を促進し、開発者が実装を成功させるために必要なリソースを確保します。
よくある質問
Node.jsでPDFファイルをどのように読めますか?
Node.jsでPDFファイルを読むには、npmを通じてIronPDFをインストールして使用することができます。必要な依存関係をインポートして、PdfDocument.openメソッドを使用してPDFを読み込みます。extractTextメソッドを使用してテキストコンテンツを抽出し、その結果をコンソールに出力します。
Node.jsでPDFライブラリを使用する利点は何ですか?
IronPDFのようなPDFライブラリをNode.jsで使用することで、PDFの生成、解析、修正などの利点があります。クロスプラットフォームの互換性とスムーズな統合を提供し、Node.jsアプリケーションを強化します。
Node.js プロジェクトに IronPDF をどのようにインストールしますか?
Node.jsプロジェクトにIronPDFをインストールするには、npmコマンドを使用します:npm install @Iron Software/ironpdf。さらに、npm install @Iron Software/ironpdf-engine-windows-x64を使用してIronPDFエンジンをインストールし、完全な機能を確保してください。
Node.jsでパスワード保護されたPDFを読むことはできますか?
はい、IronPDFはNode.jsでパスワード保護されたPDFを読むことができます。PDFを開く際に正しいパスワードを入力することで、内容を復号してアクセスします。
Node.jsを使ってPDFからメタデータをどのように抽出できますか?
Node.jsでIronPDFを利用して、PdfDocument.openで開き、getMetadataでメタデータを取得できます。
IronPDFがNode.jsのPDF操作に人気の選択肢である理由は何ですか?
IronPDFは、その多機能な能力、充実したドキュメント、サポートにより、Node.js開発者の間で人気があります。無料のトライアルが提供されているため、テストおよび統合するのにアクセスしやすいです。
IronPDFはNode.jsプロジェクトにおいてクロスプラットフォーム互換性をどのように保証しますか?
IronPDFは異なるオペレーティングシステム間で一貫したパフォーマンスを維持するように設計されており、Node.jsプロジェクトが展開プラットフォームに関係なく信頼性を持って機能することを保証しています。
Node.jsでIronPDFを使うためのリソースはどこで見つけられますか?
Node.jsでのIronPDFの使用に関するリソースと例については、公式のIron Softwareウェブサイトを訪れてください。PDF操作に関する包括的なガイダンスを提供するドキュメントやチュートリアルを探求してください。















