


Node.jsでPDFを画像ファイルに変換する方法
IronPDF for Node.jsは単一のメソッドコールでPDFページを画像に変換します。 rasterizeToImageFiles メソッドは、出力解像度やページの選択を直接制御しながら、1ページまたは複数ページのあらゆるPDFから、PNG、JPG、GIF、BMPなどの形式のファイルを作成します。
このメソッドは、指定されたファイル拡張子から出力形式を自動的に検出するため、形式を切り替える際に設定変更は必要ありません。 拡張子を変更できない環境では、明示的な ImageType 列挙型値が、拡張子に基づく検出よりも優先されます。 IronPDF Node.jsドキュメントには、ファイルパス、バイトバッファ、ラスタライズ前のPDFに変換されたHTML文字列を含む、サポートされている入力ソースの全範囲が記載されています。
Quickstart: PDFをPNGに変換as-heading:2()
- IronPDFのインストール:
npm install @ironsoftware/ironpdf - パッケージから
PdfDocumentをインポートします PdfDocument.fromFile()を使用して PDF を読み込みます- 出力パスを指定して
rasterizeToImageFiles()を呼び出します
//:path=/static-assets/pdf/content-code-examples/how-to/nodejs-pdf-to-image/quickstart.js
import { PdfDocument } from "@ironsoftware/ironpdf";
PdfDocument.fromFile("./sample.pdf").then((pdf) => {
pdf.rasterizeToImageFiles("./output.png");
});最小限のワークフロー(5ステップ)
1. npmを経由してNode.js向けのIronPDFをインストールします 2. `PdfDocument` クラスをインポートします 3. `PdfDocument.fromFile()` を使用して PDF ファイルを読み込む 4. 希望の出力パスと拡張子を指定して `rasterizeToImageFiles()` を呼び出します 5. 複数ページのPDFの場合、メソッドは自動的に各出力ファイル名にページ番号を追加しますどのようにIronPDF for Node.jsをインストールしますか?
npm install @ironsoftware/ironpdfnpm install @ironsoftware/ironpdfIronPDF for Node.jsパッケージをnpmからインストールして、PDFをPNG、JPG、GIF、BMP、その他の画像形式に変換します。
本番環境でPDFを画像に変換する前に、ライセンスキーを構成してください。 このパッケージには、システムにIronPDFエンジンをインストールする必要もあります。このバイナリはすべてのPDFレンダリング操作を処理し、変換が機能するためには存在している必要があります。
システム要件は何ですか?
Node.js 12以上が必要です。 IronPDF Engineバイナリは、パッケージが初めて読み込まれる際に自動的にダウンロードされますが、展開環境で外部ネットワークアクセスが制限されている場合は、手動でインストールすることも可能です。 @ironsoftware/ironpdf パッケージは npm レジストリで利用可能であり、ネイティブモジュールのコンパイル工程が不要なため、CI パイプラインをシンプルに保つことができます。
PDFを画像に変換するには?
rasterizeToImageFiles メソッドは、PDF ドキュメントを読み取り、指定された出力パスに 1 ページにつき 1 つの画像ファイルを書き出します。1 ページの PDF の場合、正確に 1 つの画像が生成されます。 複数ページのPDFの場合、各ファイル名にページ番号の接尾辞が自動的に追加されます。
以下の例では、Learning ContainerのサンプルPDFを読み込み、PNGファイルに変換します。
 ビューアで開かれたサンプルPDFファイル Learning Containerからこのファイルおよび他のテストPDFをダウンロードしてください。
ビューアで開かれたサンプルPDFファイル Learning Containerからこのファイルおよび他のテストPDFをダウンロードしてください。
//:path=/static-assets/pdf/content-code-examples/how-to/nodejs-pdf-to-image/convert-to-png.js
import { PdfDocument } from "@ironsoftware/ironpdf";
// Load the PDF and convert it to a PNG image.
// The output path determines the format — change .png to .jpg for JPEG output.
PdfDocument.fromFile("./sample-pdf-file.pdf").then((pdf) => {
pdf.rasterizeToImageFiles("./images/sample-pdf-file.png");
return pdf;
}).catch((error) => {
console.error("Error converting PDF to image:", error);
});PdfDocument.fromFile は PDF を読み込み、PdfDocument オブジェクトを解決する Promise を返します。 .then コールバックは、解決されたドキュメントを受け取り、宛先パスを引数として rasterizeToImageFiles を呼び出します。 パス内のファイル拡張子(ここでは .png)は、IronPDF に対してどの形式で出力するかを指定します。 .catch ブロックは、読み取りエラーや変換エラーを処理します。
 上記のサンプルPDFから生成されたPNG IronPDFは3行のコードでドキュメントを変換します。
上記のサンプルPDFから生成されたPNG IronPDFは3行のコードでドキュメントを変換します。
このメソッドのオプションをより詳しく示す例については、PDFから画像へのコード例ページを参照してください。
PDFをJPEG形式に変換する方法
フォーマットの選択は自動で行われます。rasterizeToImageFiles に渡す拡張子によって、出力フォーマットが決まります。 PNGの代わりにJPEGを生成するには、宛先パスの拡張子を変更します:
//:path=/static-assets/pdf/content-code-examples/how-to/nodejs-pdf-to-image/convert-to-jpeg-extension.js
// Switch to JPEG by changing the file extension in the output path.
pdf.rasterizeToImageFiles("./images/pdf-to-jpeg.jpg");出力ファイル名を制御できない場合(たとえば、固定の命名規則を持つ自動パイプライン内など)、オプションオブジェクトに ImageType 値を指定して、拡張子に基づく検出を上書きしてください:
//:path=/static-assets/pdf/content-code-examples/how-to/nodejs-pdf-to-image/convert-to-jpeg-imagetype.js
import { PdfDocument, ImageType } from "@ironsoftware/ironpdf";
// ImageType.JPG forces JPEG output regardless of the file extension.
const options = {
type: ImageType.JPG,
dpi: 300
};
PdfDocument.fromFile("./sample-pdf-file.pdf").then((pdf) => {
pdf.rasterizeToImageFiles("./images/output.png", options);
return pdf;
});options オブジェクト内の type プロパティは、ファイル名の拡張子よりも優先されます。 上記の例では、保存先パスが .png で終わっているにもかかわらず、rasterizeToImageFiles が JPEG ファイルを生成します。 このパターンはGIFやBMPの出力にも適用されます。
DPI設定は出力品質にどのように影響しますか?
options オブジェクト内の dpi プロパティは、ラスタライズされた出力のピクセル密度を制御します。 値が高いほど、詳細が多くファイルが大きくなります; 値が低いとシャープネスが犠牲になりますが、ファイルサイズが小さくなります。
dpi: 300 を指定すると、高解像度印刷やアーカイブに適した印刷品質の画像が生成されます。 画面表示やサムネイル生成において、dpi: 96 は、Web での使用に十分な明瞭さを維持しつつ、ファイルサイズを縮小します。150 DPIはほとんどのアーカイブやプレビューシナリオに適したデフォルトで、出力は十分に鮮明であり、ファイルサイズも扱いやすい範囲です。 変換後に印刷する、またはOCR処理の対象となるコンテンツは、300 DPI以上が推奨されます。
複数ページのPDFを画像に変換するにはどうすればよいですか?
複数ページにわたるドキュメントの場合、rasterizeToImageFiles を使用すると、1ページごとに1つの画像が生成されます。 IronPDFは、ゼロベースのページインデックスを各出力ファイル名に追加し、追加のコードなしで出力を整理します。
 2ページのサンプルPDF。 IronPDFは、変換中にページごとに1つの画像ファイルを作成します。
2ページのサンプルPDF。 IronPDFは、変換中にページごとに1つの画像ファイルを作成します。
//:path=/static-assets/pdf/content-code-examples/how-to/nodejs-pdf-to-image/convert-multipage.js
import { PdfDocument } from "@ironsoftware/ironpdf";
// Each page of the PDF becomes a separate image file.
// Output filenames: multipage-pdf-page_1.png, multipage-pdf-page_2.png, etc.
PdfDocument.fromFile("./multipage-pdf.pdf").then((pdf) => {
pdf.rasterizeToImageFiles("./images/multipage-pdf/multipage-pdf-page.png");
}); 2ページのPDFから作成された2つのPNGファイル。 IronPDFは、各出力ファイルをページ番号で命名します。
2ページのPDFから作成された2つのPNGファイル。 IronPDFは、各出力ファイルをページ番号で命名します。
この自動ページ分割動作は、サポートされている全ての画像形式で機能します。 大規模なドキュメントから特定のページのみを変換するには、次のセクションにある fromPages オプションと組み合わせて使用してください。 別の方向で作業するには、画像をPDFに変換する例をご覧ください。複数の画像ファイルを単一のPDF文書に結合する方法が示されています。
出力ファイル名の構造はどうなっていますか?
ファイル名パターンは、ファイル拡張子の前に1ベースのページ番号を追加します。 出力パスが ./images/report-page.png の場合、3 ページの PDF では report-page_2.png、および report-page_3.png が生成されます。 rasterizeToImageFiles を呼び出す前に、出力ディレクトリが存在している必要があります。このメソッドは、存在しないディレクトリを自動的に作成することはありません。
rasterizeToImageFilesを呼び出す前に、出力ディレクトリを作成してください。 ターゲットディレクトリが存在しない場合、このメソッドはエラーをスローします。事前に作成するには、Node.jsのfs.mkdirSync('./images/output', { recursive: true })を使用してください。)}]特定のページだけを変換するにはどうすればよいですか?
options オブジェクトの fromPages プロパティは、0 から始まるページインデックスの配列を受け取ります。 指定されたページのみがラスタライズされます; 他のページはスキップされます。 これは、大きなPDFで一部のページのみ必要な場合に役立ちます - たとえば、ドキュメントプレビュー用の表紙やセクション開始ページを抽出するなど。 変換前に個々のページを操作する必要がある場合、PdfDocument for Node.js APIリファレンスには、ページレベルでの追加操作が記載されています。
//:path=/static-assets/pdf/content-code-examples/how-to/nodejs-pdf-to-image/convert-selective-pages.js
import { PdfDocument, ImageType } from "@ironsoftware/ironpdf";
// Convert only pages 1, 4, 6, and 9 (zero-indexed: 0, 3, 5, 8) to BMP.
const options = {
type: ImageType.BMP,
fromPages: [0, 3, 5, 8],
dpi: 150
};
PdfDocument.fromFile("./sample-pdf-with-images.pdf").then((pdf) => {
pdf.rasterizeToImageFiles(
"./images/multipage-selective-pdf/multipage-pdf-page.bmp",
options
);
}).catch((error) => {
console.error("Failed to convert pages:", error);
});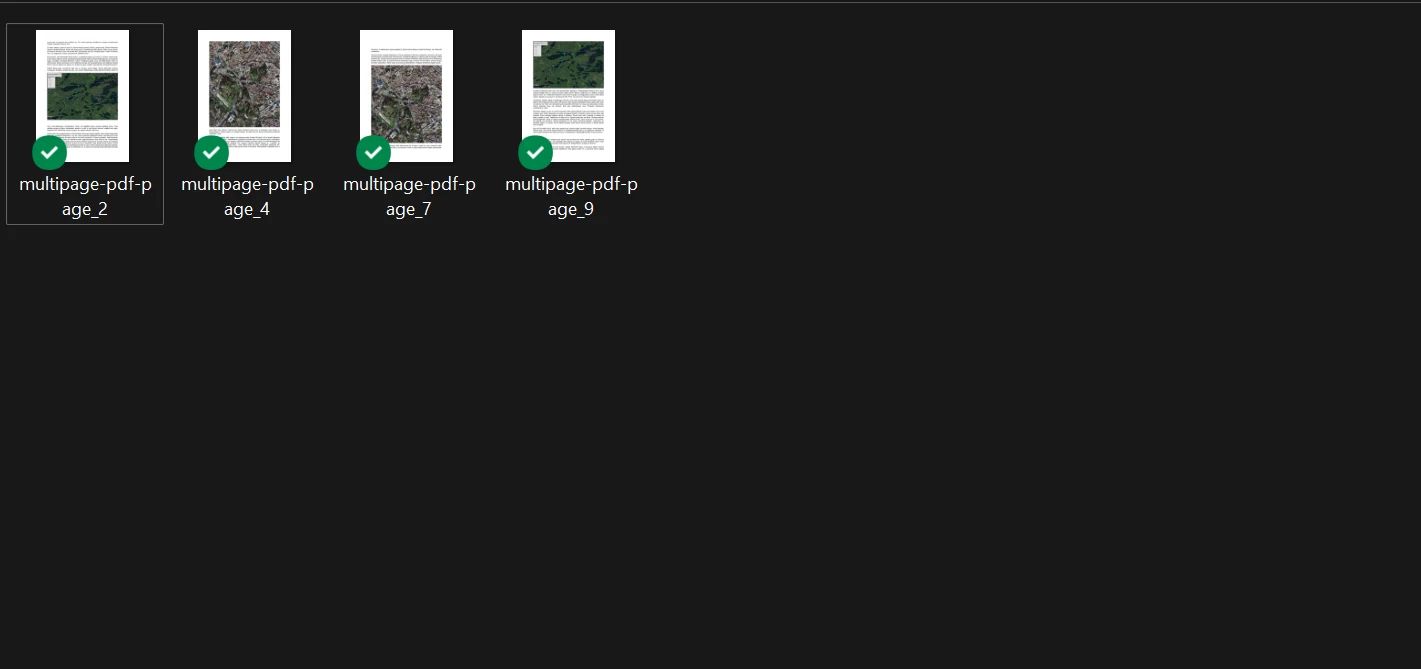 IronPDFは、
IronPDFは、fromPages配列で指定された4ページのみをラスタライズしました。 他のページは処理されませんでした。
fromPages のページインデックスは0から始まるため、[0, 3, 5, 8] は1ページ目、4ページ目、6ページ目、および9ページ目を指します。 150のDPI値は、出力品質とファイルサイズのバランスをとっています - アーカイブまたはプレビューのユースケースに適しています。 選択的変換は、サポートされているすべての画像タイプと互換性があります。
ゼロベースとワンベースのページ番号の違いは何ですか?
fromPages は、JavaScript の標準的な配列の規則に合わせて、0 から始まるインデックスを使用しています。 ドキュメントの1ページ目はインデックス 0、2ページ目はインデックス 1 に対応し、以下同様です。 これは、PDFビューアに表示されるワンベースのページ番号とは異なります。 ページ番号を fromPages 形式のインデックスに変換する際は、各ページ番号から1を引いてください。
fromPagesの値として使用してください。PDFから画像への変換の次のステップは何ですか?
IronPDFのrasterizeToImageFilesメソッドは、一貫したAPIを通じて、フォーマットの選択、複数ページの分割、および選択的なページ変換を処理します。 オプションオブジェクトは、フォーマットのオーバーライド、DPI制御、ページフィルタリングのための単一の拡張ポイントです。
さらに詳しく知りたい場合は、IronPDF Node.js API リファレンスで、rasterizeToImageFiles および PdfDocument クラスで使用可能なすべてのパラメータを確認できます。 "PDFから画像への変換"のコード例では、追加の設定とともに rasterizeToImageFiles が使用されています。 反対方向に作業するには、画像をPDFファイルに変換するまたはマルチフレームTIFFファイルをPDFに変換するを参照してください。
IronPDF for Node.jsの無料トライアルを始めて、独自プロジェクトでのPDFから画像への変換を試すことができます。 ライセンスオプションを表示することで、チームに適したプランを見つけてください。
IronPDFの他の機能をご覧になりたいですか? 完全なNode.jsチュートリアルはこちらをご覧ください:HTMLからPDFへの変換
よくある質問
Node.jsでPDFを画像に変換するには?
IronPDFのrasterizeToImageFilesメソッドを使用します。npm install @ironsoftware/ironpdfでパッケージをインストールし、PdfDocument.fromFile()を使ってPDFをロードし、出力パスを指定してrasterizeToImageFiles()を呼び出します。ファイル拡張子が出力フォーマットを自動的に決定します。
rasterizeToImageFilesはどの画像フォーマットをサポートしていますか?
IronPDFはPNG、JPG、GIF、およびBMPの出力をサポートしています。フォーマットは出力パスのファイル拡張子から検出されます。これを上書きするには、オプションオブジェクト内でImageType列挙型の値を渡します。たとえば、{ type: ImageType.JPG }と指定すると、ファイル名の拡張子に関係なくJPEG出力が強制されます。
PDFの特定のページだけを画像に変換するにはどうすればよいですか?
オプションオブジェクト内にfromPages配列を渡します。配列は0から始まるページインデックスを受け入れるため、fromPages: [0, 2, 4]の場合、最初、三番目、および五番目のページが変換されます。配列に記載されていないページはスキップされます。
PDFを画像に変換する際に使用すべきDPIは何ですか?
オプションオブジェクト内でdpiプロパティを設定します。画面表示やサムネイルにはdpi: 96を使用し、アーカイブやプレビューのユースケースにはdpi: 150を使用します。印刷品質の出力や変換後にOCRで処理されるコンテンツにはdpi: 300を使用します。
Node.js における IronPDF のインストール要件は何ですか?
Node.js 12以降が必要です。パッケージはnpm install @ironsoftware/ironpdfでインストールしてください。IronPDF Engineバイナリは初回使用時に自動でダウンロードされ、PDFのレンダリングをすべて処理します。本番環境で使用する場合は、出力から透かしを削除するためにライセンスキーを設定してください。
複数ページのPDFの出力ファイル名はどのように構成されていますか?
IronPDFは、ファイル拡張子の前に1から始まるページ番号を付け足します。出力パスがreport-page.pngの場合、3ページのPDFはreport-page_1.png、report-page_2.png、report-page_3.pngになります。メソッドを呼び出す前に出力ディレクトリが存在している必要があります。
Node.jsでのPDFから画像への変換は非同期ですか?
はい。両方のPdfDocument.fromFile()とrasterizeToImageFiles()はPromiseを返します。成功した場合のパスには.then()をチェーンし、変換エラーを処理するには.catch()を使用します。また、これらのメソッドにはasync/await構文を使うこともできます。


まだスクロールしていますか?
すぐに証拠が欲しいですか?
サンプルを実行するHTML が PDF に変換されるのを確認します。











