


如何在Node.js中将PDF转换为图像文件
IronPDF for Node.js通过单一方法调用将PDF页面转换为图像。 rasterizeToImageFiles 方法可将任何 PDF(单页或多页)转换为 PNG、JPG、GIF、BMP 等格式,并能直接控制输出分辨率和页面选择。
方法自动检测您提供的文件扩展名中的输出格式,因此在格式之间切换不需要配置更改。 在无法更改扩展名的环境中,显式的 ImageType 枚举值将覆盖基于扩展名的检测。 IronPDF Node.js文档涵盖支持的输入来源的全范围,包括文件路径、字节缓冲区、转换为PDF的HTML字符串,以及栅格化之前的。
快速入门:将PDF转换为PNG
- 安装 IronPDF:
npm install @ironsoftware/ironpdf - 从包中导入
PdfDocument - 加载您的 PDF 文件
PdfDocument.fromFile() - 调用
rasterizeToImageFiles()并指定输出路径
//:path=/static-assets/pdf/content-code-examples/how-to/nodejs-pdf-to-image/quickstart.js
import { PdfDocument } from "@ironsoftware/ironpdf";
PdfDocument.fromFile("./sample.pdf").then((pdf) => {
pdf.rasterizeToImageFiles("./output.png");
});最小工作流程(5 个步骤)
1. 通过npm安装IronPDF for Node.js 2. 导入 `PdfDocument` 类 3. 使用 `PdfDocument.fromFile()` 加载 PDF 文件 4. 调用 `rasterizeToImageFiles()` 并传入所需的输出路径和扩展名 5. 对于多页PDF,方法会自动将页码附加到每个输出文件名如何安装 IronPDF for Node.js?
npm install @ironsoftware/ironpdfnpm install @ironsoftware/ironpdf从npm安装IronPDF的Node.js包以将PDF转换为PNG、JPG、GIF、BMP和其他图像格式。
在生产中将PDF转换为图像之前,配置您的许可证密钥。 该包还需要在您的系统上安装IronPDF引擎——这个二进制文件处理所有PDF渲染操作,并必须存在以进行转换。
系统要求是什么?
需要Node.js 12或更高。 IronPDF引擎二进制文件首次加载包时会自动下载,但如果您的部署环境限制出站网络访问,您也可以手动安装。 @ironsoftware/ironpdf 包已在 npm 注册表中发布,且无需进行原生模块编译步骤,从而使持续集成 (CI) 管道保持简洁。
如何将 PDF 转换为图像?
rasterizeToImageFiles 方法读取 PDF 文档,并将每页内容写入您指定的输出路径中,生成一个图像文件。对于单页 PDF,该方法将生成恰好一个图像文件。 对于多页PDF,它会自动在每个文件名后追加页码后缀。
下面的示例加载一个来自Learning Container的示例PDF,并将其转换为PNG文件。
 在查看器中打开的示例PDF文件。 从Learning Container下载此文件和其他测试PDF。
在查看器中打开的示例PDF文件。 从Learning Container下载此文件和其他测试PDF。
//:path=/static-assets/pdf/content-code-examples/how-to/nodejs-pdf-to-image/convert-to-png.js
import { PdfDocument } from "@ironsoftware/ironpdf";
// Load the PDF and convert it to a PNG image.
// The output path determines the format — change .png to .jpg for JPEG output.
PdfDocument.fromFile("./sample-pdf-file.pdf").then((pdf) => {
pdf.rasterizeToImageFiles("./images/sample-pdf-file.png");
return pdf;
}).catch((error) => {
console.error("Error converting PDF to image:", error);
});PdfDocument.fromFile 加载 PDF 并返回一个 Promise,该 Promise 解析为 PdfDocument 对象。 .then 回调函数接收已解析的文档,并使用目标路径调用 rasterizeToImageFiles。 路径中的文件扩展名(此处为 .png)用于告知 IronPDF 生成何种格式。 .catch 代码块用于处理任何读取或转换错误。
 从上述示例PDF生成的PNG。 IronPDF仅用三行代码转换了文档。
从上述示例PDF生成的PNG。 IronPDF仅用三行代码转换了文档。
有关此方法选项的更多详细示例,请参见PDF到图片代码示例页面。
如何将PDF转换为JPEG格式?
格式选择为自动模式:您传递给 rasterizeToImageFiles 的扩展名将决定输出格式。 要生成JPEG而不是PNG,请更改目标路径中的扩展名:
//:path=/static-assets/pdf/content-code-examples/how-to/nodejs-pdf-to-image/convert-to-jpeg-extension.js
// Switch to JPEG by changing the file extension in the output path.
pdf.rasterizeToImageFiles("./images/pdf-to-jpeg.jpg");当无法控制输出文件名时(例如在采用固定命名规则的自动化管道中),请在选项对象中传入 ImageType 值以覆盖基于扩展名的检测:
//:path=/static-assets/pdf/content-code-examples/how-to/nodejs-pdf-to-image/convert-to-jpeg-imagetype.js
import { PdfDocument, ImageType } from "@ironsoftware/ironpdf";
// ImageType.JPG forces JPEG output regardless of the file extension.
const options = {
type: ImageType.JPG,
dpi: 300
};
PdfDocument.fromFile("./sample-pdf-file.pdf").then((pdf) => {
pdf.rasterizeToImageFiles("./images/output.png", options);
return pdf;
});选项对象中的 type 属性优先于文件名扩展名。 在上例中,即使目标路径以 .png 结尾,rasterizeToImageFiles 仍会生成一个 JPEG 文件。 相同的模式适用于GIF和BMP输出。
DPI设置如何影响输出质量?
options 对象中的 dpi 属性用于控制栅格化输出的像素密度。 更高的值生成更大的文件,细节更多; 较低的值减小文件大小,但会损失清晰度。
dpi: 300 可生成适合高分辨率打印或归档的印刷级图像。 (用于屏幕显示或生成缩略图时,dpi: 96 可在保持网络使用所需清晰度的同时减小文件大小。150 DPI是大多数归档或预览场景的合理默认值 — 输出足够清晰以便在屏幕上阅读,并且文件大小保持在可控范围。 对于将在转换后打印或进行OCR处理的内容,建议使用300 DPI或更高。
如何将多页PDF转换为图片?
对于多页文档,rasterizeToImageFiles 会为每页生成一张图片。 IronPDF在每个输出文件名后面追加基于零的页索引,使输出无需额外代码即可保持有序。
 一个两页的示例PDF。 IronPDF在转换过程中为每页创建一个图像文件。
一个两页的示例PDF。 IronPDF在转换过程中为每页创建一个图像文件。
//:path=/static-assets/pdf/content-code-examples/how-to/nodejs-pdf-to-image/convert-multipage.js
import { PdfDocument } from "@ironsoftware/ironpdf";
// Each page of the PDF becomes a separate image file.
// Output filenames: multipage-pdf-page_1.png, multipage-pdf-page_2.png, etc.
PdfDocument.fromFile("./multipage-pdf.pdf").then((pdf) => {
pdf.rasterizeToImageFiles("./images/multipage-pdf/multipage-pdf-page.png");
}); 从两页PDF生成的两个PNG文件。 IronPDF使用其页码命名每个输出文件。
从两页PDF生成的两个PNG文件。 IronPDF使用其页码命名每个输出文件。
此自动页面分割行为适用于所有支持的图像格式。 结合下一节中的 fromPages 选项,可仅转换大型文档中的特定页面。 为了向相反方向操作,请查看图片到PDF示例以了解如何将多个图像文件合并成一个PDF文档。
输出文件名是如何构建的?
文件名模式使用基于一的页码附加在文件扩展名前。 如果输出路径为 ./images/report-page.png,则三页的 PDF 文件将生成 report-page_2.png 和 report-page_3.png。 调用 rasterizeToImageFiles 之前,输出目录必须已存在——该方法不会自动创建缺失的目录。
rasterizeToImageFiles 之前,请先创建输出目录。 如果目标目录不存在,该方法会抛出错误。请使用 Node.js 的 fs.mkdirSync('./images/output', { recursive: true }) 提前创建该目录。)}]如何只转换特定页面?
options 对象中的 fromPages 属性接受一个以零为起点的页面索引数组。 仅提指定的页面被栅格化; 所有其他页面被跳过。 这是处理大型PDF时很有用,只需部分页面时 — 例如,为文档预览提取封面和段落起始页面。 若需在转换前对单个页面进行操作,PdfDocument 的 Node.js API 参考文档中详细说明了其他页面级操作。
//:path=/static-assets/pdf/content-code-examples/how-to/nodejs-pdf-to-image/convert-selective-pages.js
import { PdfDocument, ImageType } from "@ironsoftware/ironpdf";
// Convert only pages 1, 4, 6, and 9 (zero-indexed: 0, 3, 5, 8) to BMP.
const options = {
type: ImageType.BMP,
fromPages: [0, 3, 5, 8],
dpi: 150
};
PdfDocument.fromFile("./sample-pdf-with-images.pdf").then((pdf) => {
pdf.rasterizeToImageFiles(
"./images/multipage-selective-pdf/multipage-pdf-page.bmp",
options
);
}).catch((error) => {
console.error("Failed to convert pages:", error);
});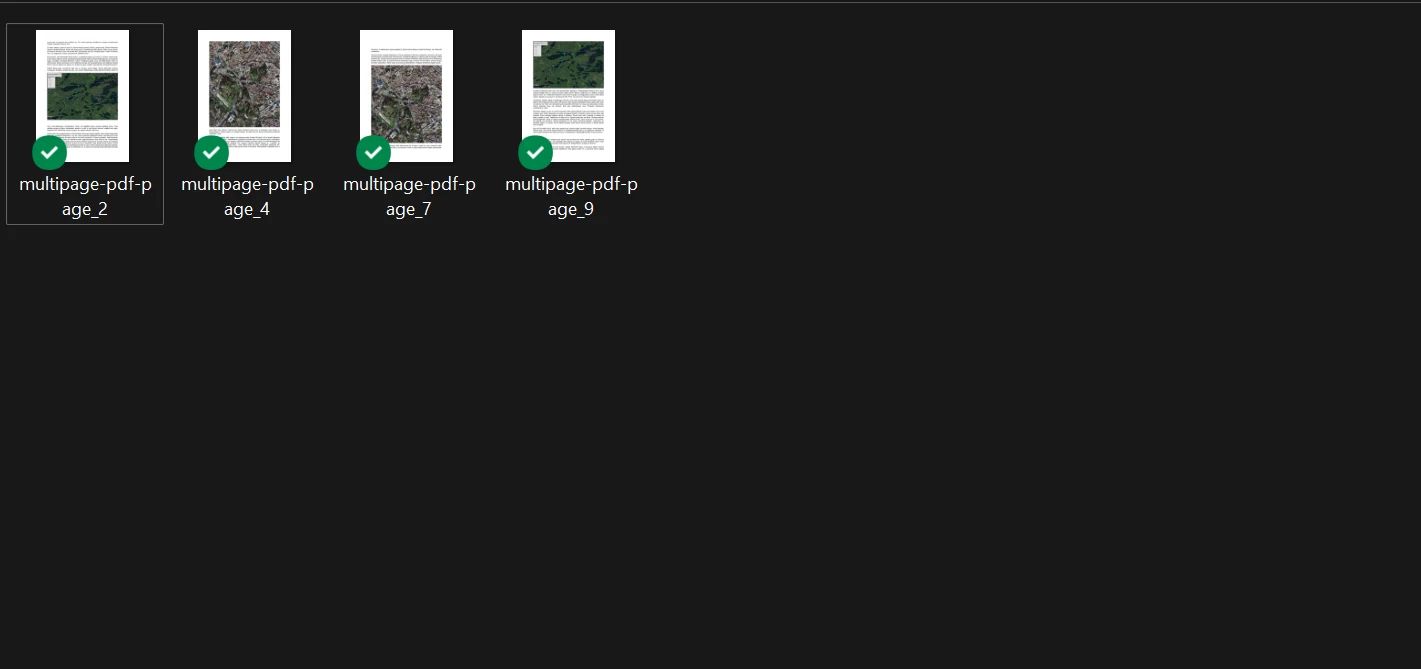 IronPDF 仅对
IronPDF 仅对 fromPages 数组中指定的四页进行了光栅化处理。 其他页面未处理。
fromPages 中的页码采用从零开始的计数方式,因此 [0, 3, 5, 8] 对应的是第 1、4、6 和 9 页。 150的DPI值在输出质量与文件大小之间取得了平衡 — 适合归档或预览用例。 选择性转换适用于所有已支持的图像类型。
零基和一基页码之间有什么区别?
fromPages 采用从零开始的索引方式,符合 JavaScript 的标准数组规范。 文档第 1 页对应索引 0,第 2 页对应索引 1,依此类推。 这与PDF查看器中出现的一基页码不同。 将阅读器中的页码转换为 fromPages 索引时,请将每个页码减去 1。
pdf.pageCount() 读取页数,并将 [pdf.pageCount() - 1] 作为 fromPages 的值。PDF到图像转换的下一步是什么?
IronPDF 的 rasterizeToImageFiles 方法通过统一的 API 处理格式选择、多页拆分以及选定页面的转换。 选项对象是格式覆盖、DPI控制和页面过滤的唯一扩展点。
此外,IronPDF for Node.js API 参考文档详细记录了 rasterizeToImageFiles 和 PdfDocument 类中所有可用的参数。 PDF 转图像的代码示例展示了 rasterizeToImageFiles 配合额外配置的使用方式。 为了相反方向的操作,请查看图片到PDF文件转换或多帧TIFF文件到PDF转换。
开始IronPDF for Node.js的免费试用,以在您自己的项目中测试PDF到图像的转换。 查看许可选项以找到适合您团队的计划。
准备看看IronPDF还能做些什么吗? 在此查看完整的Node.js教程:Node.js中的HTML到PDF转换
常见问题解答
如何在 Node.js 中将 PDF 转换为图像?
使用IronPDF的rasterizeToImageFiles方法。通过npm install @ironsoftware/ironpdf安装包,用PdfDocument.fromFile()加载您的PDF,然后用输出路径调用rasterizeToImageFiles()。文件扩展名自动确定输出格式。
rasterizeToImageFiles支持哪些图像格式?
IronPDF支持PNG、JPG、GIF和BMP输出。格式通过输出路径中的文件扩展名检测。如需覆盖此设置,在选项对象中传入ImageType枚举值,例如{ type: ImageType.JPG }强制输出JPEG格式,不论文件名扩展名为何。
如何仅转换PDF的特定页面为图像?
在选项对象中传递fromPages数组。数组接受零基页面索引,因此fromPages: [0, 2, 4]转换第一、三、五页。数组中未列出的页面将被跳过。
要进行PDF到图像转换应该使用什么DPI?
在选项对象中设置dpi属性。对于屏幕显示和缩略图使用dpi: 96,对于归档和预览使用dpi: 150,对于打印质量输出或转换后需要OCR处理的内容使用dpi: 300。
在Node.js中安装IronPDF的要求是什么?
需要Node.js 12或更高版本。通过npm install @ironsoftware/ironpdf安装包。IronPDF引擎二进制文件在首次使用时自动下载并处理所有PDF渲染。对于生产环境,需配置许可证密钥以去除输出水印。
多页PDF的输出文件名结构是怎样的?
IronPDF在文件扩展名之前添加基于一的页码。如果输出路径为report-page.png,则三页PDF将产生report-page_1.png、report-page_2.png和report-page_3.png。在调用该方法之前,输出目录必须存在。
在Node.js中PDF到图像的转换是异步的吗?
是的。PdfDocument.fromFile()和rasterizeToImageFiles()都返回Promise。用.then()链式调用处理成功路径,用.catch()处理转换错误。您也可以使用async/await语法。


还在滚动吗?
想快速获得证据?
运行示例看着你的HTML代码变成PDF文件。











