
Node.js で PDF ドキュメントを解析する方法
この記事では、PDF パーサー Node.js ライブラリである IronPDF を使用して Node.js で PDF を解析する方法を説明します。
ノードとは何ですか?
クロスプラットフォームのオープンソース Node.js JavaScript ランタイム環境により、JavaScript コードを Web ブラウザー外部で実行できるようになります。 プログラマーは、サーバー側の JavaScript または JS モジュールの実行を有効にすることで、スケーラブルで高速かつ効果的なネットワーク アプリケーションを作成できます。 Node.js はイベント駆動型の非ブロッキング I/O モデルであるため、インタラクティブなフォーム要素を使用して複数の接続を同時に管理するリアルタイム アプリケーションの開発に最適です。
Node.js は、Web サーバー、API、データ構造ストリーミング アプリケーション、リアルタイム チャット アプリケーション、モノのインターネット (IoT) デバイスなど、幅広いアプリケーションの作成に頻繁に使用されます。 総合的に考えると、Node.js は、その有効性、速度、フロントエンドとバックエンドの両方における JavaScript の互換性により人気が高まっており、フルスタック開発のための単一の言語を提供しています。 Node.js について詳しくは、この説明 Web サイトのドキュメント ページを参照してください。
Node.jsでPDFドキュメントを解析する方法
- PDF を解析して読み取り可能なストリームを作成するには、Node.js パッケージをダウンロードします。
- Node.js ライブラリ用の IronPDF をインストールします。
- 解析されたドキュメント データを使用して新しい PDF を作成するか、既存の PDF をインポートします。
- すべてのテキスト行を抽出するには、
extractTextメソッドを使用します。 - 解析された PDF コンテンツを表示して、生の PDF を読み取ります。
IronPDF for Node.js
2022 年 1 月の私の最後の知識更新の時点では、IronPDF は主に .NET Framework 内で動作するように構築された .NET ライブラリであり、開発者は C# または VB.NET を使用して PDF ドキュメントを操作できるようになりました。 しかし、Node.js 専用に作られた IronPDF のネイティブ バージョンまたは直接バージョンはありませんでした。
IronPDF は Node.js のバインディングをサポートして組み込むように拡張されたため、Node.js アプリケーションで PDF ドキュメントを作成、編集、および処理するためのツールが Node.js 用の IronPDF で利用できるようになると考えられます。
IronPDFの特長
- HTML から PDF への生成: HTML コンテンツを PDF ドキュメントに変換する機能。
- PDF ファイルからテキスト、図形、画像、その他の要素を追加、変更、または削除することを、テキストおよび画像の操作と呼びます。
- PDF ファイルの結合、ページの抽出、 PDF ファイルの分割、暗号化および復号化はすべて、PDF ドキュメントの改ざんの例です。 -フォーム処理には、フォームの記入、フォーム データの取得、プログラミングによる PDF フォームの活用が含まれます。
- PDF セキュリティとは、PDF ドキュメントにデジタル署名、暗号化、およびパスワード保護を使用することです。
- PDF ファイルの取得と変更は、ページ メタデータの処理と呼ばれます。
IronPDF が製品範囲を拡張して Node.js バージョンを含めると、Node.js アプリを作成する開発者は IronPDF の PDF 操作機能を利用できるようになります。 これは、.NET 環境で IronPDF と同様の機能を提供するライブラリを使用したい開発者にとって役立つ可能性があります。
IronPDF の機能、互換性、および Node.js のサポートに関する最新の情報については、常に IronPDF チームからの公式ドキュメント、リリース ノート、またはアップデートを参照してください。 IronPDF と各リリースの新機能の詳細については、こちらをご覧ください。 IronPDF の詳細については、この公式ドキュメント ページを参照してください。
パッケージ要件
- IDEとしてのVisual Studio Code
- Node.js
- パッケージのインストールに必要なパッケージ管理には、Yarn または npm を使用できます。
Node.js用のIronPDFパッケージをインストールする
コマンド プロンプトまたはターミナルを起動します。コマンド プロンプトまたはターミナルを開きます。 オペレーティング システムに応じて、さまざまなアクセス方法があります。
- Windows: PowerShellまたはコマンドプロンプト
- macOSのターミナル
- Linux上のターミナル
パッケージをインストールするには、パッケージ名と npm install コマンドを使用します。 例えば、パッケージ @ironsoftware/ironpdf をインストールするには、ターミナルで以下のコマンドを実行してください。
npm install @ironsoftware/ironpdfnpm install @ironsoftware/ironpdf他のパッケージをインストールする場合は、@ironsoftware/ironpdf をそのパッケージの名前に置き換えてください。
 IronPDFをインストールする
IronPDFをインストールする
PDFファイルを解析してデータを抽出する
実験してみると、IronPDF には Node.js で PDF を扱いやすくする多くの機能が提供されていることがわかります。 必要な形式であらゆる PDF ドキュメントを生成、表示、変更することに重点を置いています。 PDF ファイルの解析は非常に簡単です。
const { PdfDocument } = require("@ironsoftware/ironpdf");
const pdfProcess = async () => {
// Load the existing PDF document
const pdf = await PdfDocument.fromFile("Demo.pdf");
// Extract text data from the loaded PDF
const data = await pdf.extractText();
// Output the extracted text to the console
console.log(data);
};
pdfProcess();fromFile 関数の重要性は、上記のコードによって示されています。 fromFile メソッドはPDFドキュメントを読み込み、そのPDFファイルを PdfDocument オブジェクトに変換し、既存のファイルシステムからファイルをロードします。 したがって、PdfDocument はPDFのメタデータを保持します。 pdf オブジェクト内のファイル メタデータは、ユーザーの希望に応じて使用できます。 このオブジェクトが解析したドキュメントデータは、PDFページオブジェクト内に含まれるテキストとグラフィックスです。 extractText 関数は、提供されたPDFファイルから全テキストを抽出するために使用されます。その後、取得したテキストは文字列として保存され、JSONフォーマットの作成など追加処理のために準備されます。
ページごとのテキスト抽出
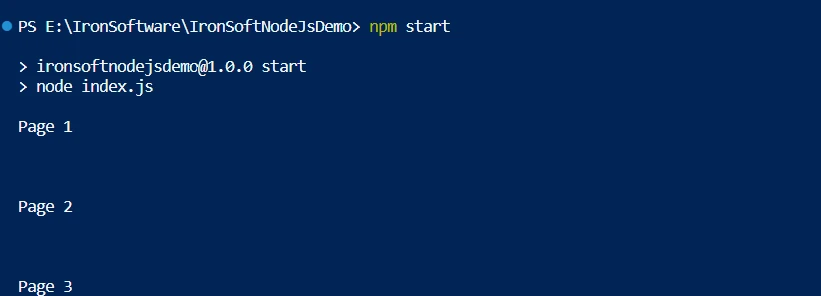
以下は、PDF ファイルの各ページからテキストを明示的に抽出する別のアプローチのコードです。
const pdf = await PdfDocument.fromFile("Demo.pdf");
// Get the total number of pages in the PDF
const pageCount = await pdf.getPageCount();
// Loop through each page to extract text
for (let i = 0; i < pageCount; i++) {
const pageText = await pdf.extractText(i);
// Output the text of each page
console.log(pageText);
}メモリ内に既にあるPDFからの生のPDF読み込みは、指定されたディレクトリから完全に読み込まれ、その後 PdfDocument という名前の pdf オブジェクトを作成します。 PDF文書は、複数の基本データオブジェクト型で構成されるデータ構造です。PDFファイル内の各ページデータは、PDFオブジェクト内のページ番号またはページインデックスを使用して取得され、順番に処理されることが保証されます。 まず、PDFオブジェクトのgetPageCount メソッドを使用して、提供されたPDFの総ページ数を確認します。
for ループは、このページ数を使用して各ページを反復し、extractText 関数を呼び出して各PDFページからテキストを取得します。 抽出されたテキストは、ユーザーの画面に表示することも、文字列変数に保存することもできます。 この技術により、個々の PDF ページからテキストを体系的に抽出することが可能になります。 これらの手法は、PDF タスク専用に作成された Node.js ライブラリである IronPDF を使用して、PDF ファイルからテキストを簡単かつ徹底的に抽出する方法を示しています。 このアクセシビリティにより、さまざまなコンテキストでの PDF の有用性が向上し、数多くの実用的なアプリケーションが実現します。
 PDFをページごとに読む
PDFをページごとに読む
上記の両方のコードは同じ出力を実現しますが、唯一の違いはユーザーの要件に基づいたコードの実装にあります。 IronPDF の詳細については、この詳細なドキュメント ページを参照してください。
結論
IronPDF ライブラリは、リスクを軽減し、データのセキュリティを確保するための強力なセキュリティ対策を提供します。 すべての一般的なブラウザと互換性があり、いずれかのブラウザに限定されません。 開発者のさまざまな要求に応えるため、ライブラリでは、無料の開発者ライセンスや購入可能な追加の開発ライセンスなど、幅広いライセンス オプションを提供しています。
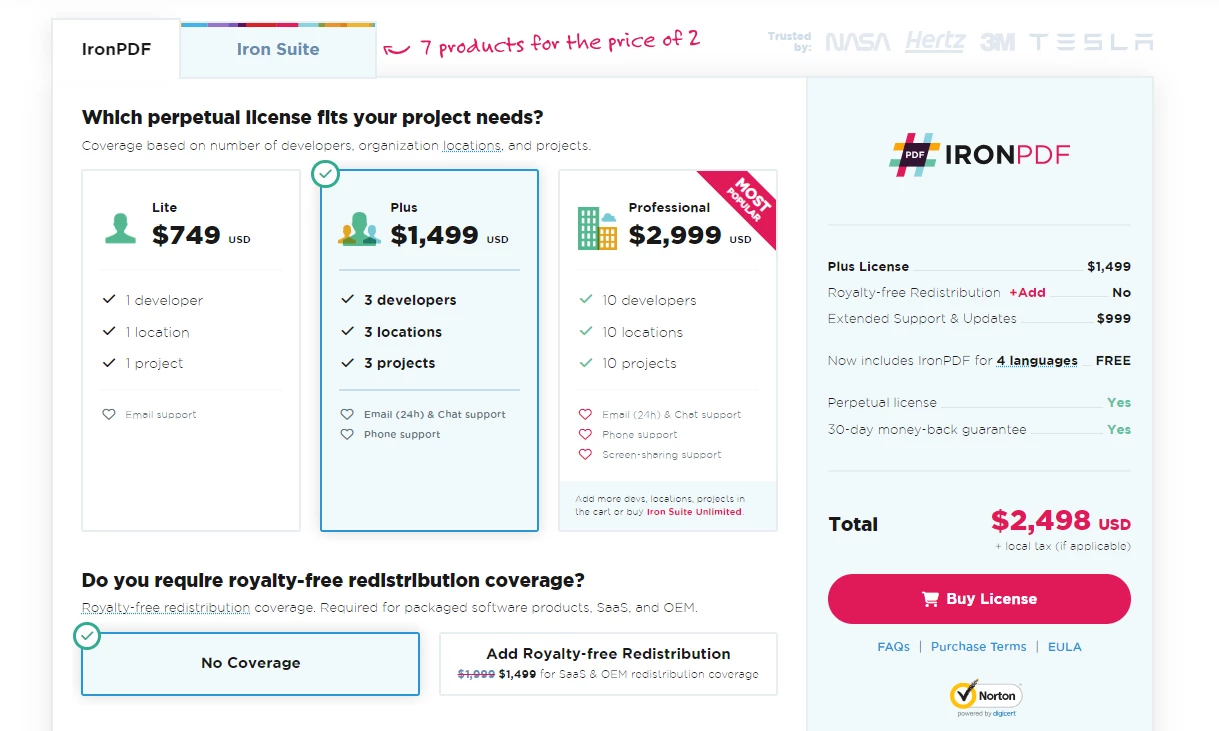
恒久ライセンスだけでなく、1年間のソフトウェアメンテナンスや30日間の返金保証に加えて、$799 Liteバンドルにはアップグレードの可能性が含まれています。 ユーザーは、透かし入りの試用期間中、実際のアプリケーション状況で製品を評価する機会があります。 IronPDF のコスト、ライセンス、試用版の詳細については、提供されているライセンス ページを確認してください。 Iron Software が提供するその他の製品については、公式 Web サイトをご覧ください。
 Iron Softwareの価格
Iron Softwareの価格
よくある質問
Node.js を使用して PDF を解析するにはどうすればよいですか?
Node.js を使用して PDF を解析するには、IronPDF ライブラリを利用できます。npm install @Iron Software/ironpdf を使用して IronPDF パッケージをインストールしてから、fromFile メソッドで PDF を読み込み、extractText メソッドを使用してテキストを抽出します。
Node.js における HTML から PDF への変換手順は?
IronPDF を使用して Node.js で HTML を PDF に変換できます。HTML 文字列の場合は RenderHtmlAsPdf メソッドを、HTML ファイルの場合は RenderHtmlFileAsPdf を使用して効率的に PDF を生成します。
Node.js を使用して PDF の各ページからテキストを抽出するにはどうすればよいですか?
IronPDF を使用すると、PDF の各ページからテキストを抽出できます。ページを反復して移動し、getPageCount メソッドでページ数を確認し、extractText 関数を使用して各ページのテキストを抽出します。
Node.js 用 IronPDF ライブラリにはどのような機能がありますか?
IronPDF for Node.js には、HTML から PDF への変換、テキストおよび画像の操作、PDF の結合および分割、暗号化、デジタル署名、フォーム処理など、さまざまな機能があります。
Node.js で PDF ドキュメントのセキュリティを確保する方法は?
IronPDF は、デジタル署名、暗号化、パスワード保護などの包括的なセキュリティ機能を提供し、Node.js アプリケーションでの PDF ドキュメントのセキュリティを確保します。
Node.jsのPDFライブラリを選ぶ際に考慮すべきことは何ですか?
Node.jsのPDFライブラリを選ぶ際には、異なるブラウザとの互換性、セキュリティオプション、使いやすさ、包括的なドキュメント、ライセンスの柔軟性などの機能を考慮してください。IronPDFはこれらの機能を提供しており、開発者にとって強力な選択肢となります。
Node.jsでのIronPDFのライセンスオプションは何ですか?
IronPDFは無料の開発者ライセンス、永久ライセンス、1年間のソフトウェアメンテナンスなど、さまざまなライセンスオプションを提供しています。また、異なる開発者のニーズに応じた透かし付きの試用版も用意されています。
Node.jsを使用してPDF内の画像を操作することは可能ですか?
はい、IronPDF を使用すると、Node.js アプリケーションで PDF 内の画像を操作できます。これには、PDF ドキュメントに埋め込まれた画像の追加、抽出、または変更が含まれます。















