Python用IronPDFとPyPDFの比較
PDF(ポータブル・ドキュメント・フォーマット)は、異なるプラットフォーム間で文書情報のレイアウトや書式を保持するために広く使用されているファイル形式です。 デバイスやオペレーティングシステムに関係なく、一貫した外観を維持できるため、さまざまな業界で高い人気を誇っています。 PDFは一般的に、レポート、請求書、フォーム、電子書籍、カスタムデータ、その他の重要な文書を共有するために使用されます。
PythonでPDFファイルを扱うことは、多くのプロジェクトで重要な側面となっています。 Pythonは、PDFファイルの操作を簡素化するライブラリをいくつか提供しており、情報の抽出、新しい文書の作成、既存の文書の結合や分割、その他のPDF関連のタスクの実行を容易にします。
この記事では、PDFファイルを操作するために設計された2つの有名なPythonライブラリの包括的な比較を行います:PyPDFとIronPDFです。 両ライブラリの特長と機能を評価することで、開発者に貴重な洞察を提供し、特定のソフトウェア・アプリケーションのニーズに最も適したものを意識的に選択できるようにすることを目指しています。
これらのライブラリは、PDFの作業を効率化する堅牢なツールを提供し、開発者がPythonアプリケーション内でPDF文書を効率的に扱えるようにします。 それでは、この比較に深く入り込み、PDF関連の作業を容易にするための各ライブラリの長所を探ってみましょう。
PyPDF - 純粋なPython PDFライブラリ
PyPDFは純粋なPython PDFライブラリで、PDFファイルの読み取り、書き込み、復号化、PDFドキュメントの操作のための基本的な機能を提供します。 開発者は、PDFからテキストや画像を抽出したり、複数のPDFファイルを結合したり、大きなPDFを小さなPDFに分割したりすることができます。 PyPDFはシンプルで使いやすいことで知られており、簡単なPDFタスクに適しています。
PDFドキュメントを扱うための包括的な機能セットを提供し、PDF関連の幅広いタスクに最適です。
特徴
PyPDFは以下の機能を持つPython PDFライブラリです:
- PDFファイルを読む:既存のPDFファイルからテキスト、画像、メタデータを抽出します。
- PDFファイルを書く:ゼロから新しいPDFを作成したり、既存のPDFをテキストや画像で修正したりします。
- Merge PDF Files:複数のPDFファイルを1つのドキュメントに結合します。
- PDFファイルを分割する: PDFを別々のファイルに分割します。
- ページの回転とオーバーレイ:ページを回転させ、透かしやオーバーレイをPDFに追加します。
- PDFファイルの暗号化と復号化:PDFを暗号化および復号化することによって、PDFにセキュリティを追加します。
- テキストの抽出: PDFまたはページ内の特定の領域からプレーンテキストを取得します。
- 画像の抽出: PDF内に埋め込まれた画像を取得します。
- PDFファイルを操作する: PDFファイル内のページをコピー、削除、または並べ替えます。
- フォームフィールドの入力: PDFのフォームフィールドをプログラムで入力します。
IronPDF - Python PDF ライブラリ
IronPDFはPythonのための包括的なPDF操作ライブラリで、IronPDF for .NETライブラリの上に構築されています。 HTMLからPDFへの変換、PDFの注釈やフォームフィールドの処理、複雑なPDF操作の効率的な実行など、高度な機能を備えた強力なAPIを提供します。 IronPDFは堅牢なPDF処理、パフォーマンス、広範な機能サポートを必要とするプロジェクトに適しています。
IronPDFはPDF処理タスクをシームレスに処理できるPython PDFライブラリです。 Python開発者向けに、信頼性が高く機能豊富なPDF操作ソリューションを提供します。 IronPdfを使えば、PDF内の複数のページからコンテンツを簡単に生成、変更、抽出することができます。
特徴
IronPDFの主な特徴は以下の通りです:
- PDF生成: IronPDFは、開発者がゼロからPDFドキュメントを作成したり、HTMLコンテンツをPDFフォーマットに変換したりすることを可能にし、ダイナミックで視覚的に魅力的なレポートやドキュメントを簡単に生成できるようにします。
- 高度なテキストと画像の操作:開発者はPDFファイル内のテキストと画像を簡単に操作できます。 IronPdfはテキストの追加、編集、書式設定、画像の挿入、リサイズ、配置を正確に行う機能を提供します。
- PDFマージとPDF分割: IronPDFは複数のPDFファイルを1つのドキュメントにマージしたり、PDFを複数のファイルに分割したりすることができます。
- PDFフォームのサポート: IronPDFを使うことで、開発者はPDFフォームを扱うことができ、フォームフィールドへの入力、フォームデータの抽出、インタラクティブなPDFの作成が可能になります。
- PDFセキュリティと暗号化: IronPDFはPDFドキュメントにパスワード保護と暗号化を追加する機能を提供し、データのセキュリティと機密性を確保します。
- PDF注釈:開発者は、コメント、ハイライト、しおりなどの注釈を追加して、PDF内のコラボレーションと読みやすさを向上させることができます。
- ヘッダーとフッター: IronPDFではPDFページにヘッダーとフッターを追加することができます。
- バーコード生成: IronPDFは様々な種類のバーコードやQRコードをHTMLを使ってPDFドキュメントに直接生成することができます。
- ハイパフォーマンス: IronPDF for .NETライブラリ上に構築されたIronPDFは、大きなPDFファイルや複雑な操作の処理において高いパフォーマンスと効率性を提供します。
記事は次のようになります:
1.Pythonプロジェクトを作成する 2.PyPDFのインストール 3.IronPDFのインストール 4.PDFドキュメントの作成 5.PDFファイルのマージ 6.PDFファイルの分割 7.PDFファイルからのテキスト抽出
- ライセンス
- 結論
1.Pythonプロジェクトの作成
Pythonプロジェクトで統合開発環境(IDE)を使用すると、生産性が大幅に向上します。 一般的な選択肢の中では、インテリジェントなコード補完、強力なデバッグ、バージョン管理システムとのシームレスな統合で際立っているPyCharmを使うつもりです。 インストールされていない場合は、JetBrainsのウェブサイトPyCharmからダウンロードするか、VS CodeのようなPythonプログラミング用のIDE/テキストエディタを使用することができます。
PyCharmでPythonプロジェクトを作成する:
1.PyCharm を起動し、PyCharm のウェルカム画面で "Create New Project" をクリックするか、メニューから File > New Project に進みます。
2.Pythonインタプリタを選択してください。 インタプリタを設定していない場合は、歯車のアイコンをクリックして、新しいインタプリタを設定してください。 3.プロジェクトの場所とテンプレートを選択してください。 4.プロジェクト名と設定を入力し、Createをクリックしてください。
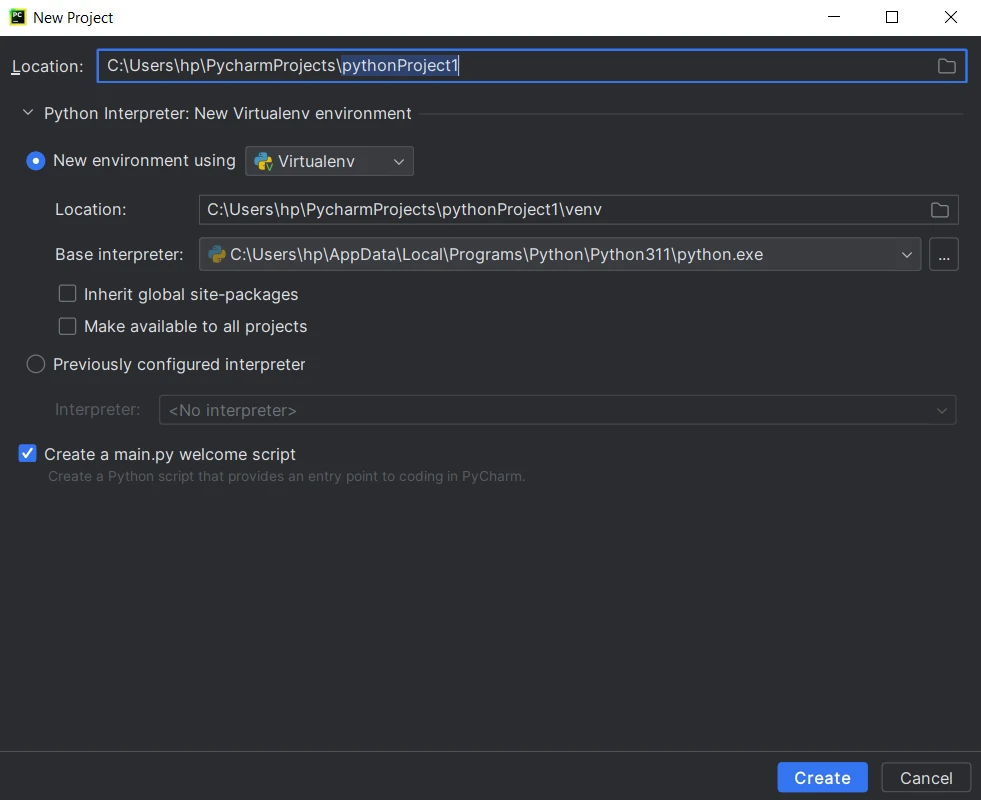
5.Pythonプロジェクトのコーディング、実行、デバッグを始めましょう。
2. PyPDFのインストール
純粋なPythonライブラリであるPyPDFは、複数の方法でインストールできます。 コマンドプロンプトとPyCharmの両方を使用してインストールできます。
2.1.コマンドプロンプトを使う
1.コンピュータのコマンドプロンプトまたはターミナルを開いてください。 2.PyPDFをインストールするには、次のpipコマンドを使用します:
pip install pypdf pip install pypdf3.PyPDFのインストールが完了するまで待ちます。 PyPDFがインストールされたことを示す成功メッセージが表示されるはずです。
PyPDFをPyCharm Terminalにインストールするときと同じプロセスを使用できます。
注意: PythonをシステムPATH環境変数に追加する必要があります。
2.2.PyCharmを使う
1.PyCharm IDEを開く。 2.新しいPythonプロジェクトを作成するか、既存のプロジェクトを開いてください。 3.プロジェクト内に入ったら、上部メニューのFileをクリックし、Settingsを選択します。 4.設定ウィンドウで、"Project:
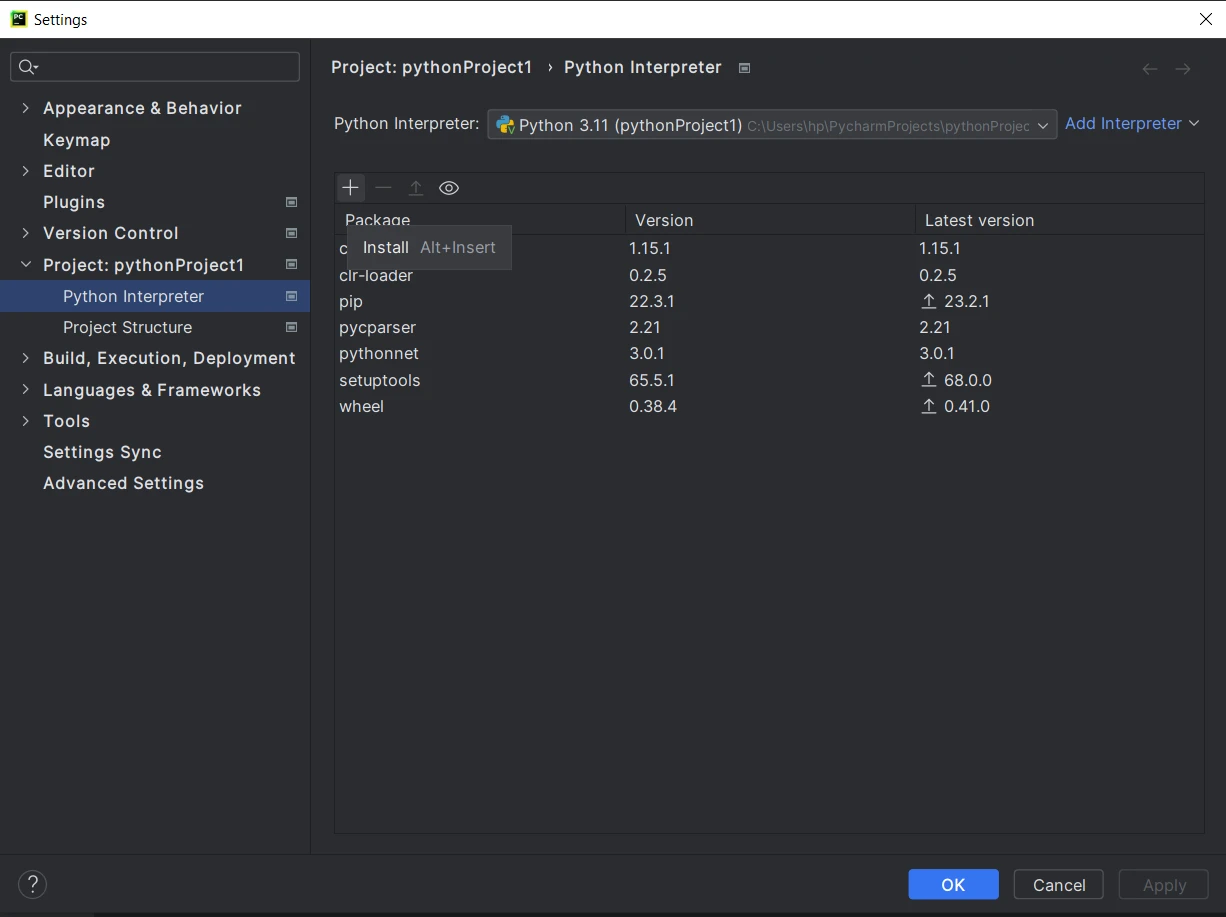
6.利用可能なパッケージ"ウィンドウで、"PyPDF"を検索してください。
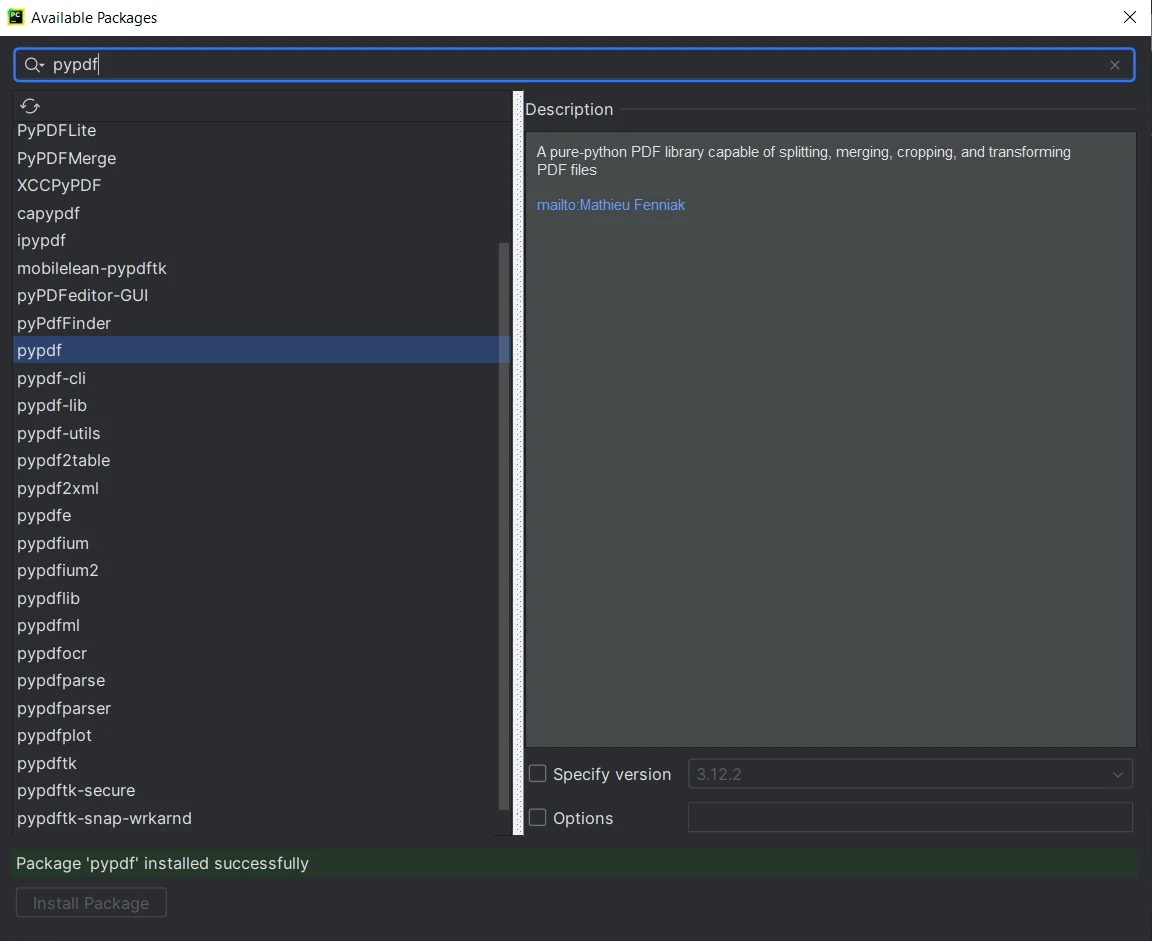
7.リストから"PyPDF"を選択し、"パッケージをインストール"ボタンをクリックしてください。 8.PyCharmがPyPDFをダウンロードしてインストールするのを待ちます。
3.IronPDFのインストール
前提条件
IronPDF for Pythonは強力な.NET 6.0テクノロジーを基盤としています。 そのため、IronPDF for Pythonを効果的に使用するには、システムに.NET 6.0ランタイムがインストールされていることが不可欠です。 LinuxとMacユーザーは、こ for Pythonパッケージで作業を進める前に、Microsoftの公式ウェブサイト(https://dotnet.microsoft.com/en-us/download/dotnet/6.0)から.NETをダウンロードしてインストールする必要があるかもしれません。 .NET 6.0ランタイムの存在を保証することで、IronPDF for PythonをPDF処理タスクに使用する際のシームレスな統合と最適なパフォーマンスを可能にします。
3.1.コマンドプロンプトを使う
1.コンピュータのコマンドプロンプトまたはターミナルを開いてください。 2.IronPdfをインストールするには、以下のpipコマンドを使用してください:
pip install ironpdf pip install ironpdf3.インストールが完了するまでお待ちください。 IronPDFがインストールされたことを示す成功メッセージが表示されるはずです。
3.2.PyCharmを使う
1.コンピュータでPyCharm IDEを開きます。 2.新しいPythonプロジェクトを作成するか、既存のプロジェクトを開いてください。 3.プロジェクトに入ったら、上部メニューの"File"をクリックし、"Settings"を選択してください。 4.設定ウィンドウで、"Project:
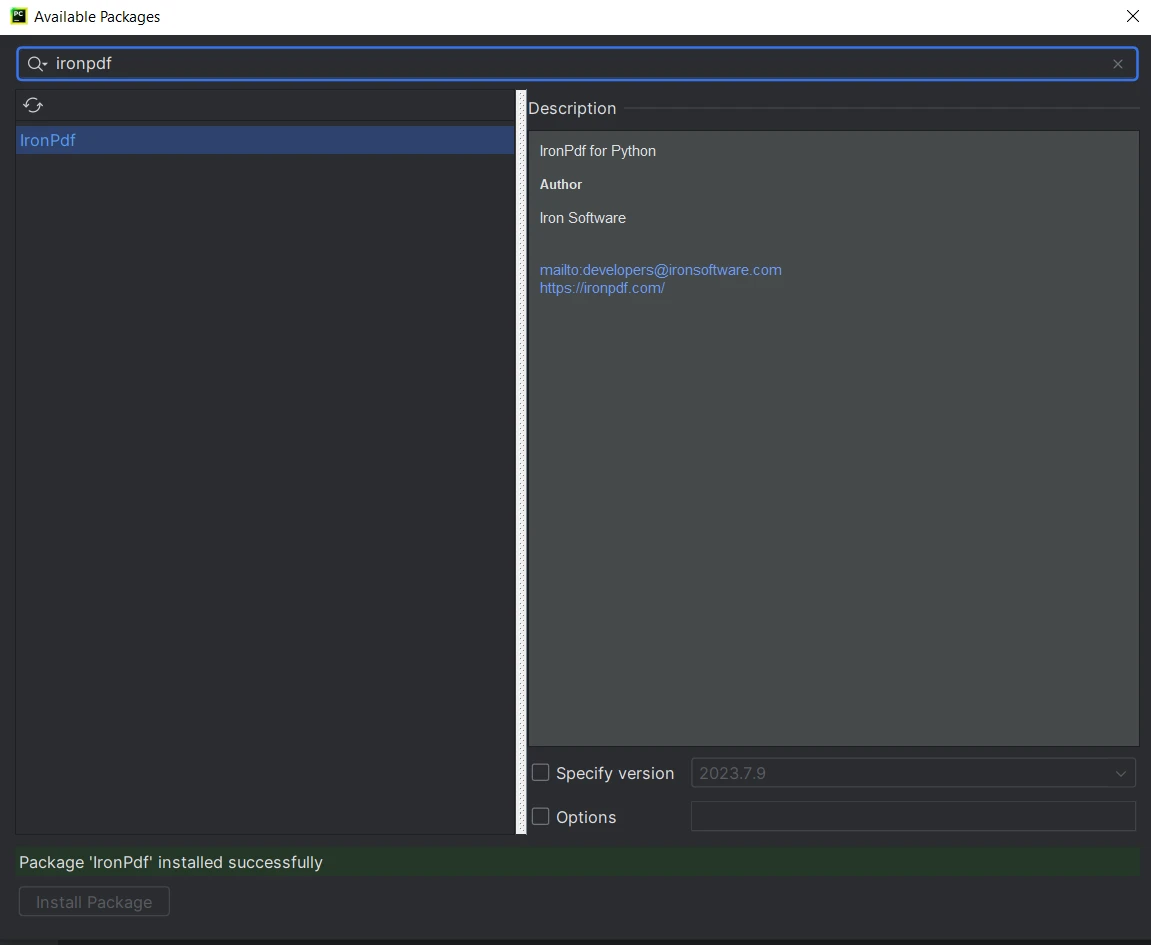
7.リストから"ironpdf"を選択し、"パッケージをインストール"ボタンをクリックしてください。 8.IronPDFのダウンロードとインストールをお待ちください。 IronPDFがインストールされたという成功メッセージが表示されます。
これで、両方のライブラリがインストールされ、使用できるようになりました。 比較の話に移りましょう。
4.PDFドキュメントの作成
4.1.PyPDFを使う
PyPDFは新しいPDFファイルを作成する基本的な機能を提供します。 ただし、HTMLコンテンツを直接PDFに変換する方法は組み込まれていません。 PyPDFを使って新しいPDFを作成するには、既存のPDFにコンテンツを追加するか、新しい空のPDFを作成し、そこにテキストや画像を追加する必要があります。 以下のコードは、PDFファイルを作成するというこのタスクを達成するのに役立ちます:
from pypdf import PdfWriter, PdfReader
# Create a new PDF file
pdf_output = PdfWriter()
# Add a new blank page
page = pdf_output.add_blank_page(width=610, height=842) # Width and height are in points (1 inch = 72 points)
# Read content from an existing PDF
with open('input.pdf', 'rb') as existing_pdf:
existing_pdf_reader = PdfReader(existing_pdf)
# Merge content from the first page of the existing PDF
page.merge_page(existing_pdf_reader.pages[0])
# Save the new PDF to a file
with open('output.pdf', 'wb') as output_file:
pdf_output.write(output_file)from pypdf import PdfWriter, PdfReader
# Create a new PDF file
pdf_output = PdfWriter()
# Add a new blank page
page = pdf_output.add_blank_page(width=610, height=842) # Width and height are in points (1 inch = 72 points)
# Read content from an existing PDF
with open('input.pdf', 'rb') as existing_pdf:
existing_pdf_reader = PdfReader(existing_pdf)
# Merge content from the first page of the existing PDF
page.merge_page(existing_pdf_reader.pages[0])
# Save the new PDF to a file
with open('output.pdf', 'wb') as output_file:
pdf_output.write(output_file)入力ファイルには28ページが含まれ、最初のページだけが新しいPDFファイルに追加されます。出力は以下の通りです:
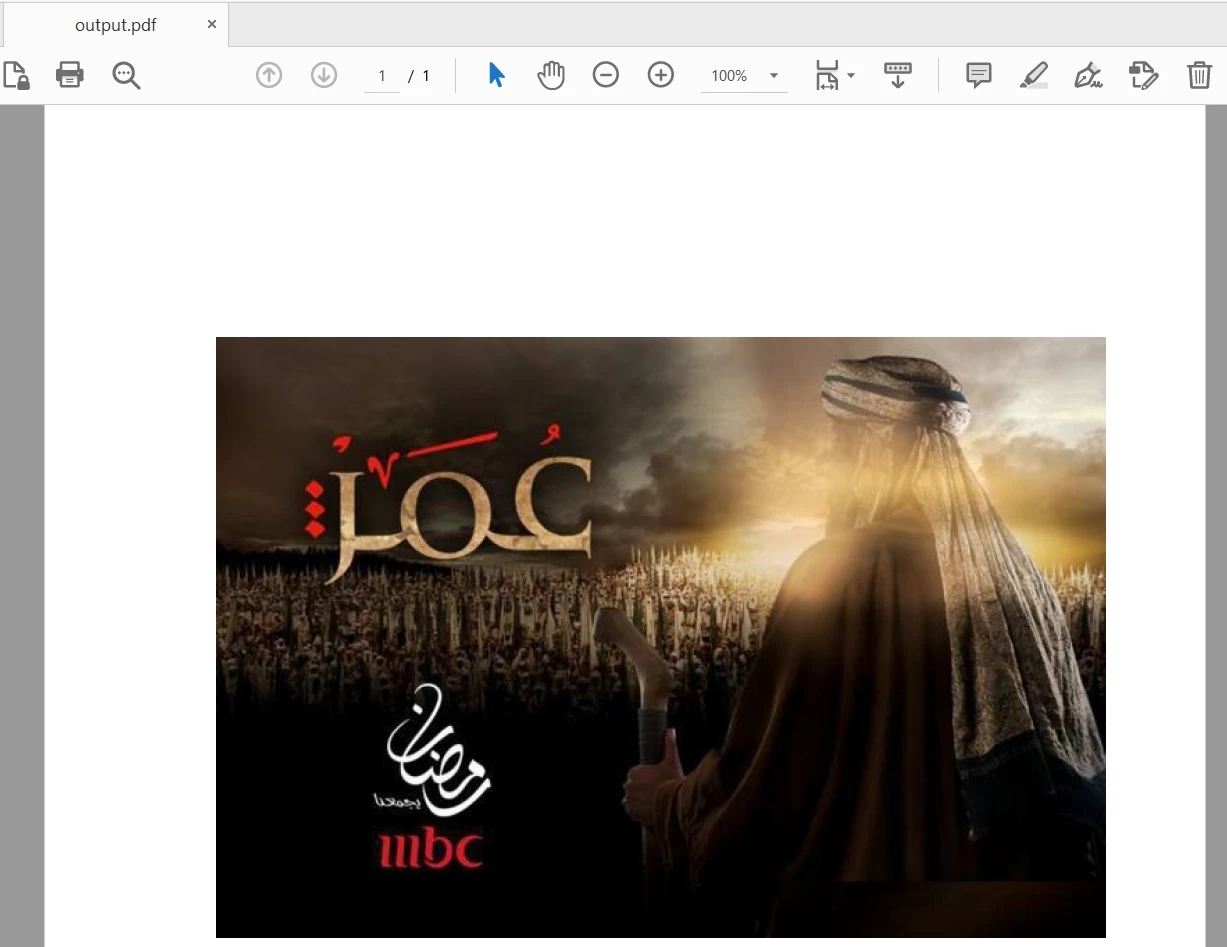
4.2.IronPDFを使う.
IronPdfはHTMLコンテンツから直接新しいPDFファイルを作成する高度な機能を提供します。 そのため、追加の手順を踏むことなく、動的なレポートや文書を作成するのに便利です。 以下はサンプルコードです:
import ironpdf
# Set IronPDF license key to unlock full features
ironpdf.License.LicenseKey = "YOUR-LICENSE-KEY-HERE"
# Create a PDF from an HTML string using Python
renderer = ironpdf.ChromePdfRenderer()
pdf = renderer.RenderHtmlAsPdf("<h1>Hello World</h1><p>This PDF is created using IronPDF for Python</p>")
# Export to a file or stream
pdf.SaveAs("output.pdf")
# Advanced Example with HTML Assets
# Load external html assets Images, CSS, and JavaScript.
# An optional BasePath 'C:\site\assets\' is set as the file location to load assets from
myAdvancedPdf = renderer.RenderHtmlAsPdf("<img src='icons/iron.png'>", "C:\\site\\assets")
myAdvancedPdf.SaveAs("html-with-assets.pdf")import ironpdf
# Set IronPDF license key to unlock full features
ironpdf.License.LicenseKey = "YOUR-LICENSE-KEY-HERE"
# Create a PDF from an HTML string using Python
renderer = ironpdf.ChromePdfRenderer()
pdf = renderer.RenderHtmlAsPdf("<h1>Hello World</h1><p>This PDF is created using IronPDF for Python</p>")
# Export to a file or stream
pdf.SaveAs("output.pdf")
# Advanced Example with HTML Assets
# Load external html assets Images, CSS, and JavaScript.
# An optional BasePath 'C:\site\assets\' is set as the file location to load assets from
myAdvancedPdf = renderer.RenderHtmlAsPdf("<img src='icons/iron.png'>", "C:\\site\\assets")
myAdvancedPdf.SaveAs("html-with-assets.pdf")上記のコードでは、まずIronPDFのフルパワーを利用するためにライセンスキーを適用しています。 ライセンスキーなしで使用することもできますが、作成されたPDFファイルには透かしが入ります。 次に、2つのPDF文書を作成します。1つ目はHTML文字列をコンテンツとして使用し、2つ目はアセットを使用します。 出力は以下の通りです。
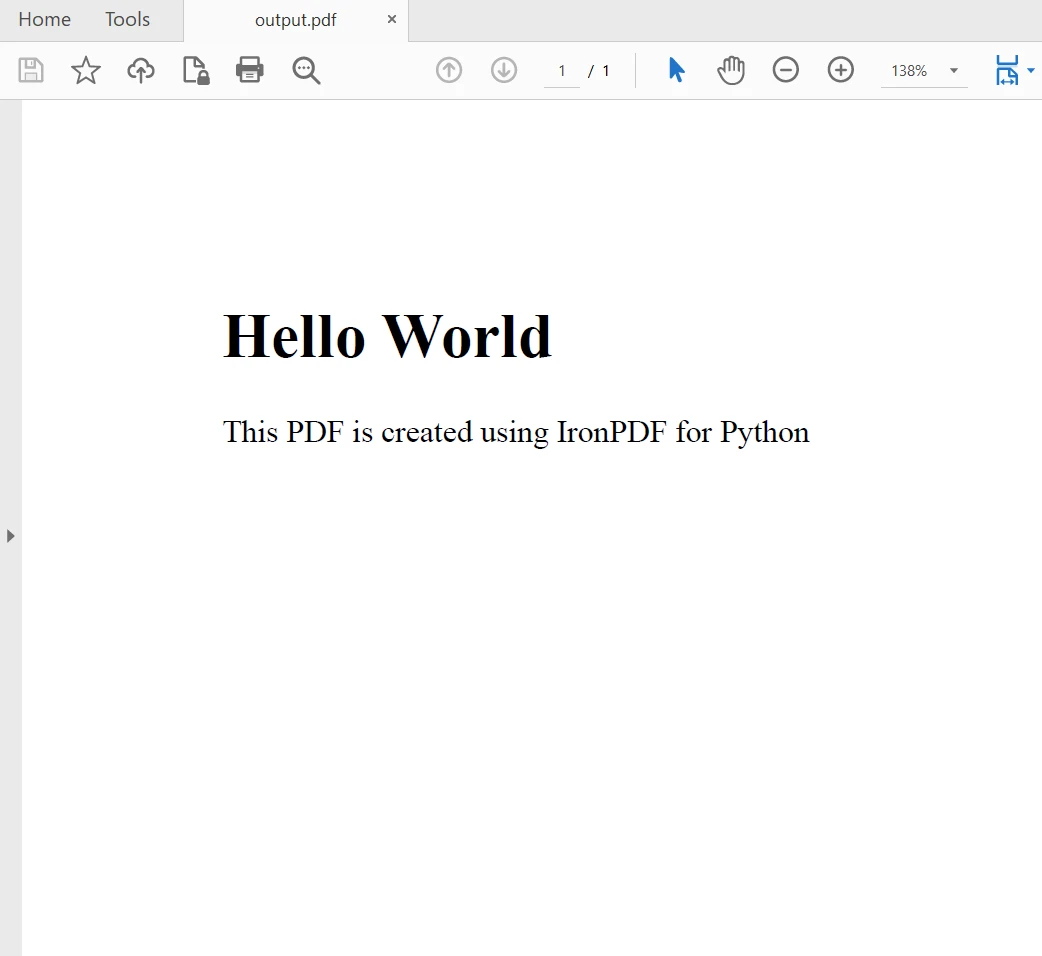
5.PDF ファイルのマージ
5.1.PyPDFを使う
PyPDFは、1つのPDFから別のPDFにページを追加することによって、複数のページ/ドキュメントを1つのPDFにマージすることができます。 リスト内のすべてのPDFファイルの入力パスを追加し、appendメソッドを使用して単一のファイルをマージして生成します。
from pypdf import PdfWriter
merger = PdfWriter()
for pdf in ["file1.pdf", "file2.pdf", "file3.pdf"]:
merger.append(pdf)
merger.write("merged-pdf.pdf")
merger.close()from pypdf import PdfWriter
merger = PdfWriter()
for pdf in ["file1.pdf", "file2.pdf", "file3.pdf"]:
merger.append(pdf)
merger.write("merged-pdf.pdf")
merger.close()5.2.IronPDFを使う.
IronPdfはまた、異なるPDFソースのコンテンツを簡単に統合するために、ドキュメントを1つにマージするための同様の機能を提供します。
import ironpdf
ironpdf.License.LicenseKey = "YOUR-LICENSE-KEY-HERE"
html_a = """<p> [PDF_A] </p>
<p> [PDF_A] 1st Page </p>
<div style='page-break-after: always;'></div>
<p> [PDF_A] 2nd Page</p>"""
html_b = """<p> [PDF_B] </p>
<p> [PDF_B] 1st Page </p>
<div style='page-break-after: always;'></div>
<p> [PDF_B] 2nd Page</p>"""
renderer = ironpdf.ChromePdfRenderer()
pdfdoc_a = renderer.RenderHtmlAsPdf(html_a)
pdfdoc_b = renderer.RenderHtmlAsPdf(html_b)
merged = ironpdf.PdfDocument.Merge([pdfdoc_a, pdfdoc_b])
merged.SaveAs("Merged.pdf")import ironpdf
ironpdf.License.LicenseKey = "YOUR-LICENSE-KEY-HERE"
html_a = """<p> [PDF_A] </p>
<p> [PDF_A] 1st Page </p>
<div style='page-break-after: always;'></div>
<p> [PDF_A] 2nd Page</p>"""
html_b = """<p> [PDF_B] </p>
<p> [PDF_B] 1st Page </p>
<div style='page-break-after: always;'></div>
<p> [PDF_B] 2nd Page</p>"""
renderer = ironpdf.ChromePdfRenderer()
pdfdoc_a = renderer.RenderHtmlAsPdf(html_a)
pdfdoc_b = renderer.RenderHtmlAsPdf(html_b)
merged = ironpdf.PdfDocument.Merge([pdfdoc_a, pdfdoc_b])
merged.SaveAs("Merged.pdf")6.PDFファイルを分割する
6.1.PyPDFを使う
PyPDFは、1つのPDFを、それぞれが1つ以上のPDFページを含む複数の別々のPDFに分割することができるPythonライブラリです。
from pypdf import PdfReader, PdfWriter
# Open the PDF file
pdf_file = open('input.pdf', 'rb')
# Create a PdfFileReader object
pdf_reader = PdfReader(pdf_file)
# Split each page into separate PDFs
for page_num in range(len(pdf_reader.pages)):
pdf_writer = PdfWriter()
pdf_writer.add_page(pdf_reader.pages[page_num])
output_filename = f'page_{page_num + 1}_pypdf.pdf'
with open(output_filename, 'wb') as output_file:
pdf_writer.write(output_file)
# Close the PDF file
pdf_file.close()from pypdf import PdfReader, PdfWriter
# Open the PDF file
pdf_file = open('input.pdf', 'rb')
# Create a PdfFileReader object
pdf_reader = PdfReader(pdf_file)
# Split each page into separate PDFs
for page_num in range(len(pdf_reader.pages)):
pdf_writer = PdfWriter()
pdf_writer.add_page(pdf_reader.pages[page_num])
output_filename = f'page_{page_num + 1}_pypdf.pdf'
with open(output_filename, 'wb') as output_file:
pdf_writer.write(output_file)
# Close the PDF file
pdf_file.close()上のコードは、28ページのPDF文書を分割して1ページにし、28個の新しいPDFファイルとして保存します。
6.2.IronPDFを使う.
IronPDFはPDFの分割にも同様の機能を提供し、ユーザーは一つのPDFを複数のPDFファイルに分割することができます。 複数のページがあるPDFから特定のページを分割することができます。 以下のコードは、ドキュメントを複数のファイルに分割するのに役立ちます:
import ironpdf
ironpdf.License.LicenseKey = "YOUR-LICENSE-KEY-HERE"
html = """<p> Hello Iron </p>
<p> This is 1st Page </p>
<div style='page-break-after: always;'></div>
<p> This is 2nd Page</p>
<div style='page-break-after: always;'></div>
<p> This is 3rd Page</p>"""
renderer = ironpdf.ChromePdfRenderer()
pdf = renderer.RenderHtmlAsPdf(html)
# take the first page
page1doc = pdf.CopyPage(0)
page1doc.SaveAs("Split1.pdf")
# take the pages 2 & 3
page23doc = pdf.CopyPages(1, 2)
page23doc.SaveAs("Split2.pdf")import ironpdf
ironpdf.License.LicenseKey = "YOUR-LICENSE-KEY-HERE"
html = """<p> Hello Iron </p>
<p> This is 1st Page </p>
<div style='page-break-after: always;'></div>
<p> This is 2nd Page</p>
<div style='page-break-after: always;'></div>
<p> This is 3rd Page</p>"""
renderer = ironpdf.ChromePdfRenderer()
pdf = renderer.RenderHtmlAsPdf(html)
# take the first page
page1doc = pdf.CopyPage(0)
page1doc.SaveAs("Split1.pdf")
# take the pages 2 & 3
page23doc = pdf.CopyPages(1, 2)
page23doc.SaveAs("Split2.pdf")PDFファイルの読み込み、PDFページの回転、ページの切り取り、所有者/ユーザーパスワードの設定、その他のセキュリティオプションに関するIronPdfの詳細な情報については、こちらのIronPDF for Python コード例ページをご覧ください。
7.PDFファイルからテキストを抽出する
7.1.PyPDFを使う
PyPDFはPDFからテキストを抽出する簡単な方法を提供します。 これは、ユーザーが PDF からテキスト コンテンツを読み取ることができる PdfReader クラスを提供します。
from pypdf import PdfReader
reader = PdfReader("input.pdf")
page = reader.pages[0]
print(page.extract_text())from pypdf import PdfReader
reader = PdfReader("input.pdf")
page = reader.pages[0]
print(page.extract_text())7.2.IronPDFを使う
IronPDF は、PdfDocument クラスを使用して PDF からテキストを抽出することもサポートしています。 PDF からテキスト コンテンツを取得するための ExtractAllText というメソッドを提供します。 しかしながら、IronPdfの無料版はPDFドキュメントから数文字しか抽出しません。 PDFから全文を抽出するには、IronPDFのライセンスが必要です。 以下は、PDFファイルからコンテンツを抽出するコードサンプルです:
import ironpdf
ironpdf.License.LicenseKey = "YOUR-LICENSE-KEY-HERE"
# Load existing PDF document
pdf = ironpdf.PdfDocument.FromFile("input.pdf")
# Extract text from PDF document
all_text = pdf.ExtractAllText()
print(all_text)import ironpdf
ironpdf.License.LicenseKey = "YOUR-LICENSE-KEY-HERE"
# Load existing PDF document
pdf = ironpdf.PdfDocument.FromFile("input.pdf")
# Extract text from PDF document
all_text = pdf.ExtractAllText()
print(all_text)テキスト抽出の詳細については、PDF Text to Pythonの例をご覧ください。
8. ライセンス
パイPDF
PyPDFは、寛容な条項で知られるオープンソースソフトウェアライセンスであるMITライセンスの下で配布されています。 MITライセンスは、ユーザーがPyPDFライブラリを制限なく自由に使用、変更、配布、サブライセンスすることを許可します。 ユーザーは、PyPDFを使用するアプリケーションのソースコードを公開する必要がないため、個人プロジェクトにも商用プロジェクトにも適しています。
MITライセンスの全文は通常PyPDFのソースコードに含まれており、ユーザーはライブラリの配布物内の"LICENSE"ファイルで見つけることができます。 さらに、PyPDFのGitHubリポジトリ(https://github.com/py-pdf/pypdf )は、ライブラリの最新バージョンと関連するライセンス情報にアクセスするための主要なソースとして機能します。
IronPDF
IronPdfは商用ライブラリであり、オープンソースではありません。 開発・販売元はIron Softwareです。 IronPDFの使用にはIron Softwareの有効なライセンスが必要です。 評価目的の試用版や商用利用のための有償ライセンスなど、さまざまなタイプのライセンスが用意されています。
IronPDFは商用製品であるため、オープンソースの代替製品に比べ、より多くの機能と技術サポートを提供します。 IronPDFのライセンスを取得するには、公式ウェブサイトでライセンスオプション、価格、サポートの詳細をご覧ください。 Liteパッケージは、NVIDIA_64_LICENSEから始まり、永久ライセンスです。
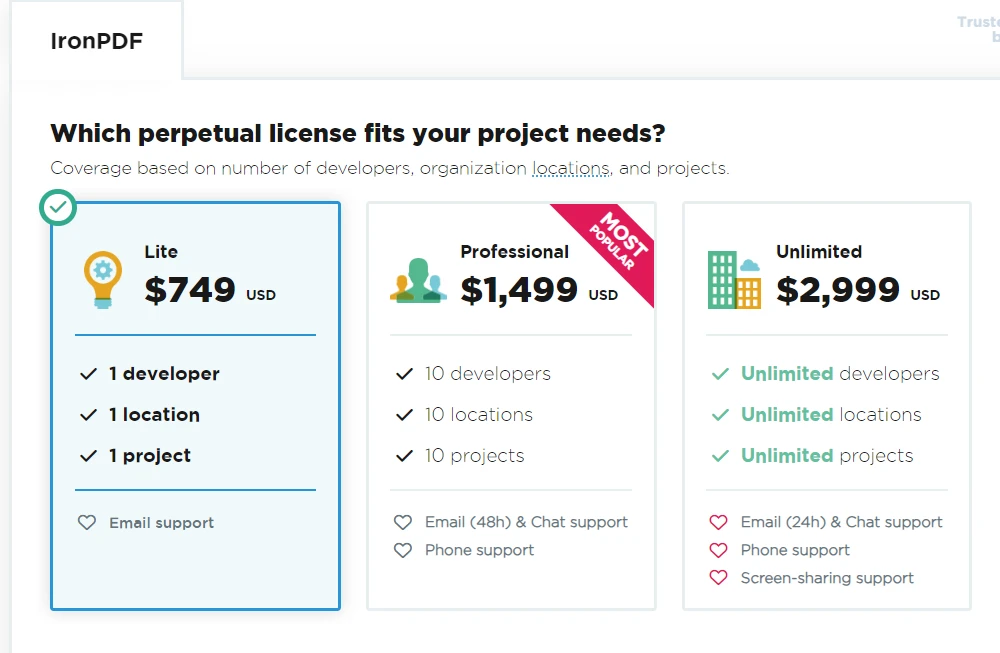
9. 結論
概要
PyPDFは、PDFファイルを扱うための強力で使いやすいPythonライブラリです。 PDFの読み取り、書き込み、結合、分割の機能により、PDF操作タスクに不可欠なツールとなっています。 PDFからテキストを抽出する必要がある場合でも、ゼロから新しいPDFを作成する必要がある場合でも、既存のドキュメントを結合したり分割したりする必要がある場合でも、PyPDFは信頼性が高く効率的なソリューションを提供します。 PyPDFの機能を活用することで、Python開発者はPDF関連のワークフローを合理化し、生産性を向上させることができます。
IronPDFは、Pythonのための包括的で効率的なPDF操作ライブラリで、PDFファイルの読み取り、作成、結合、分割のための幅広い機能を提供します。 ダイナミックなPDFレポートの作成、既存のPDFからのドキュメント情報の抽出、複数のドキュメントのマージなど、IronPDFは信頼性が高く使いやすいソリューションを提供します。 IronPDFの機能を活用することで、Python開発者はPDF関連のワークフローを合理化し、生産性を向上させることができます。
全体的な比較では、PyPDFは基本的なPDF操作に適した軽量で使いやすいライブラリです。 シンプルなPDFが要求されるプロジェクトに適しています。 一方、IronPDFはより広範なAPIと堅牢なパフォーマンスを提供し、高度なPDF処理機能、大きなPDFファイルの処理、複雑なタスクの実行を必要とするプロジェクトに最適です。
結論
どちらのライブラリも、一般的なPDFタスクのための優れたコーディング機能を備えています。 PyPDFはシンプルな操作と素早い実装に適しており、IronPDFは複雑なPDF関連のタスクを処理するための、より広範で多用途なAPIを提供します。
パフォーマンスの面では、IronPdfはPyPDFを凌駕する可能性が高く、特に大量のPDFファイルや複雑なPDF操作を必要とするタスクを扱う場合に優れています。
2つのライブラリのどちらを選択するかは、プロジェクトの具体的なニーズと、関連するPDF関連タスクの複雑さによって決まります。
IronPDFは無料トライアルでもご利用いただけます。 IronPDF for Pythonはこちらからダウンロードしてください。
よくある質問
PythonでのPDF操作におけるPyPDFとIronPDFの主な違いは何ですか?
PyPDFは、PDFの読み取り、書き込み、マージなどの基本的なPDF操作機能を提供する純粋なPythonライブラリです。それに対し、IronPDFはIronPDF for .NETライブラリを基盤に構築されており、HTMLからPDFへの変換、フォーム処理、複雑なPDFタスクの高パフォーマンス処理などの高度な機能を提供します。
PythonでHTMLをPDFに変換するにはどうすればいいですか?
IronPDFを使用してPythonでHTMLをPDFに変換できます。HTML文字列を変換するためのRenderHtmlAsPdfや、HTMLファイルをPDFに変換するためのRenderHtmlFileAsPdfなどのメソッドを提供します。
PythonプロジェクトでIronPDFを使用するためのインストール要件は何ですか?
PythonでIronPDFを使用するには、システムに.NET 6.0ランタイムがインストールされている必要があります。IronPDFは、pip install ironpdfコマンドを使用してpip経由でインストールできます。
PyPDFを使用してPDFからテキストや画像を抽出することは可能ですか?
はい、PyPDFはPDFからのテキストおよび画像の抽出を可能にします。テキストの抽出、PDFのマージや分割といった基本的なPDF操作タスク用に設計されています。
複雑なPDF操作にIronPDFを使用する利点は何ですか?
IronPDFは、HTMLからPDFへの変換、フォーム処理、高度なテキストや画像操作、大きなファイルでの高パフォーマンスなど、複雑なPDF操作に対して強力な性能と幅広い機能を提供します。
IronPDFを使用してPDFファイルをマージおよび分割できますか?
はい、IronPDFは効率的にPDFファイルをマージおよび分割する機能を提供し、Pythonアプリケーション内で複雑なPDF操作を管理するための包括的なソリューションを提供します。
さまざまな業界でPDFを利用する一般的な用途は何ですか?
PDFは、レポート、請求書、フォーム、電子書籍などの文書をさまざまなプラットフォームやデバイスで一貫した外観で共有するために、さまざまな業界で一般的に使用されています。
IronPDF のライセンスオプションはどのようになっていますか?
IronPDFは、Iron Softwareからの有効なライセンスが必要な商用製品です。さまざまなプロジェクトのニーズに合わせて、トライアル版を含むさまざまなライセンスオプションが利用可能です。