Ein Vergleich zwischen IronPDF Für Python & PyPDF
PDFs (Portable Document Format) sind ein weit verbreitetes Dateiformat zur Bewahrung des Layouts und der Formatierung von Dokumentinformationen über verschiedene Plattformen hinweg. Sie sind in verschiedenen Branchen äußerst beliebt, da sie ein konsistentes Erscheinungsbild beibehalten, unabhängig davon, welches Gerät oder Betriebssystem zum Öffnen verwendet wird. PDFs werden häufig zum Teilen von Berichten, Rechnungen, Formularen, E-Books, benutzerdefinierten Daten und anderen wichtigen Dokumenten eingesetzt.
Das Arbeiten mit PDF-Dateien in Python ist zu einem entscheidenden Aspekt vieler Projekte geworden. Python bietet mehrere Bibliotheken, die die Manipulation von PDF-Dateien vereinfachen und es leichter machen, Informationen zu extrahieren, neue Dokumente zu erstellen, bestehende zu kombinieren oder zu teilen und andere PDF-bezogene Aufgaben durchzuführen.
In diesem Artikel führen wir einen umfassenden Vergleich von zwei renommierten Python-Bibliotheken für die Manipulation von PDF-Dateien durch: PyPDF und IronPDF. Durch die Bewertung der Funktionen und Möglichkeiten beider Bibliotheken möchten wir Entwicklern wertvolle Einblicke bieten, die ihnen helfen, eine bewusste Entscheidung zu treffen, welche am besten ihren spezifischen Software-Anwendungsanforderungen entspricht.
Diese Bibliotheken bieten robuste Werkzeuge, um die Arbeit mit PDFs zu optimieren, und geben Entwicklern die Möglichkeit, PDF-Dokumente effizient in ihren Python-Anwendungen zu verwalten. Also tauchen wir tief in den Vergleich ein und erkunden die Stärken jeder Bibliothek, um Ihre PDF-bezogenen Aufgaben zu erleichtern.
PyPDF - Pure Python PDF Library
PyPDF ist eine reine Python-PDF-Bibliothek, die grundlegende Funktionen zum Lesen, Schreiben, Entschlüsseln von PDF-Dateien und Manipulieren von PDF-Dokumenten bietet. Es ermöglicht Entwicklern, Text und Bilder aus PDFs zu extrahieren, mehrere PDF-Dateien zu kombinieren, große PDFs in kleinere zu teilen und mehr. PyPDF ist bekannt für seine Einfachheit und Benutzerfreundlichkeit, was es zu einer geeigneten Wahl für einfache PDF-Aufgaben macht.
Es bietet eine umfassende Reihe von Funktionen für die Arbeit mit PDF-Dokumenten und ist damit eine ausgezeichnete Wahl für eine Vielzahl von PDF-bezogenen Aufgaben.
Funktionen
PyPDF ist eine Python-PDF-Bibliothek, die die folgenden Funktionen bietet:
- PDF-Dateien lesen: Text, Bilder und Metadaten aus bestehenden PDF-Dateien extrahieren.
- PDF-Dateien schreiben: Neue PDFs von Grund auf neu erstellen oder bestehende mit Text und Bildern ändern.
- PDF-Dateien kombinieren: Mehrere PDF-Dateien zu einem einzigen Dokument zusammenfügen.
- PDF-Dateien teilen: Ein PDF in separate Dateien aufteilen, die jeweils eine oder mehrere Seiten enthalten.
- Seiten drehen und überlagern: Seiten drehen und Wasserzeichen oder Überlagerungen zu PDFs hinzufügen.
- PDF-Dateien verschlüsseln und entschlüsseln: PDFs durch Verschlüsselung und Entschlüsselung absichern.
- Text extrahieren: Klartext aus PDFs oder bestimmten Bereichen innerhalb einer Seite erhalten.
- Bilder extrahieren: In PDFs eingebettete Bilder abrufen.
- PDF-Dateien manipulieren: Seiten innerhalb einer PDF-Datei kopieren, löschen oder neu anordnen.
- Formularfelder ausfüllen: Formularfelder in PDFs programmatisch befüllen.
IronPDF - Python PDF Library
IronPDF ist eine umfassende PDF-Manipulationsbibliothek für Python, die auf der IronPDF for .NET-Bibliothek aufbaut. Es bietet eine leistungsstarke API mit erweiterten Funktionen wie der Konvertierung von HTML in PDF, dem Umgang mit PDF-Anmerkungen und Formularfeldern sowie der effizienten Durchführung komplexer PDF-Operationen. IronPDF wird für Projekte bevorzugt, die robuste PDF-Verarbeitung, Leistung und umfassende Funktionsunterstützung erfordern.
IronPDF ist eine Python-PDF-Bibliothek, die in der Lage ist, PDF-Verarbeitungsaufgaben nahtlos zu bewältigen. Es bietet eine zuverlässige und funktionsreiche PDF-Manipulationslösung für Python-Entwickler. Mit IronPDF können Sie mühelos Inhalte aus mehreren Seiten in einem PDF generieren, ändern und extrahieren, was es zu einer ausgezeichneten Wahl für verschiedene PDF-bezogene Anwendungen macht.
Funktionen
Hier sind einige herausragende Merkmale von IronPDF:
- PDF-Erzeugung: Mit IronPDF können Entwickler PDF-Dokumente von Grund auf neu erstellen oder HTML-Inhalte in das PDF-Format umwandeln, was es einfach macht, dynamische und optisch ansprechende Berichte und Dokumente zu erzeugen.
- Erweiterte Text- und Bildmanipulation: Entwickler können Texte und Bilder innerhalb von PDF-Dateien einfach manipulieren. IronPDF bietet Funktionen zum Hinzufügen, Bearbeiten und Formatieren von Text sowie zum Einfügen, Größenändern und Positionieren von Bildern mit Präzision.
- PDF-Zusammenführung und PDF-Teilung: IronPDF ermöglicht das Zusammenführen mehrerer PDF-Dateien zu einem einzelnen Dokument und das Aufteilen eines PDF in mehrere separate Dateien, was Flexibilität im Umgang mit PDF-Inhalten bietet.
- PDF-Formularunterstützung: Mit IronPDF können Entwickler mit PDF-Formularen arbeiten, sodass sie Formularfelder ausfüllen, Formulardaten extrahieren und interaktive PDFs erstellen können.
- PDF-Sicherheit und Verschlüsselung: IronPDF bietet Funktionen zum Hinzufügen von Passwortschutz und Verschlüsselung zu PDF-Dokumenten, um Datensicherheit und Vertraulichkeit zu gewährleisten.
- PDF-Anmerkungen: Entwickler können Anmerkungen wie Kommentare, Hervorhebungen und Lesezeichen hinzufügen, um die Zusammenarbeit und Lesbarkeit in PDFs zu verbessern.
- Kopf- und Fußzeile: IronPDF erlaubt das Hinzufügen von Kopf- und Fußzeilen zu PDF-Seiten, um dem Dokument Marken- und Kontextinformationen zu geben.
- Barcode-Erzeugung: IronPDF erleichtert die Erzeugung verschiedener Arten von Barcodes und QR-Codes direkt in PDF-Dokumente mithilfe von HTML.
- Hohe Leistung: Aufgebaut auf der IronPDF for .NET-Bibliothek, bietet IronPDF hohe Leistung und Effizienz beim Umgang mit großen PDF-Dateien und komplexen Operationen.
Der Artikel geht jetzt wie folgt weiter:
- Ein Python-Projekt erstellen
- PyPDF-Installation
- IronPDF-Installation
- PDF-Dokumente erstellen
- PDF-Dateien zusammenführen
- PDF-Dateien aufteilen
- Text aus PDF-Dateien extrahieren
- Lizenzierung
- Fazit
1. Ein Python-Projekt erstellen
Die Verwendung einer Integrierten Entwicklungsumgebung (IDE) für Python-Projekte kann die Produktivität erheblich steigern. Unter den beliebten Optionen werde ich PyCharm verwenden, da es sich durch seine intelligente Code-Vervollständigung, leistungsstarke Debugging-Funktionen und nahtlose Integration mit Versionskontrollsystemen auszeichnet. Wenn Sie es nicht installiert haben, können Sie es von der JetBrains-Website herunterladen PyCharm, oder Sie können jede IDE/Texteditor für die Python-Programmierung wie VS Code verwenden.
Um ein Python-Projekt in PyCharm zu erstellen:
-
Starten Sie PyCharm und klicken Sie auf dem Willkommensbildschirm auf "Neues Projekt erstellen", oder gehen Sie im Menü zu Datei > Neues Projekt.
- Wählen Sie den Python-Interpreter. Wenn Sie noch keinen Interpreter eingerichtet haben, klicken Sie auf das Zahnradsymbol und konfigurieren Sie einen neuen.
- Wählen Sie den Speicherort und die Vorlage des Projekts.
-
Geben Sie den Projektnamen und die Einstellungen ein und klicken Sie dann auf Erstellen.
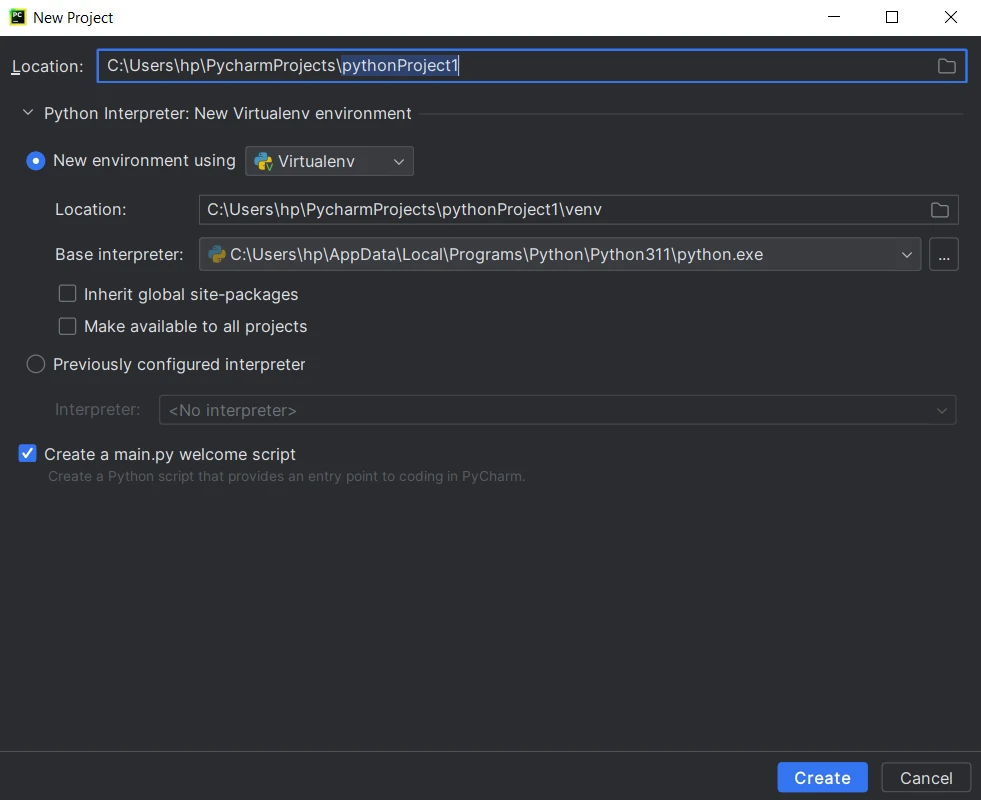
- Beginnen Sie mit dem Codieren, Ausführen und Debuggen Ihres Python-Projekts.
2. PyPDF-Installation
PyPDF, eine reine Python-Bibliothek, kann auf verschiedene Weisen installiert werden. Wir können es sowohl über die Eingabeaufforderung als auch in PyCharm installieren.
2.1. Die Eingabeaufforderung verwenden
- Öffnen Sie die Eingabeaufforderung oder das Terminal auf Ihrem Computer.
-
Um PyPDF zu installieren, verwenden Sie den folgenden pip-Befehl:
pip install pypdfpip install pypdfSHELL - Warten Sie, bis die Installation von PyPDF abgeschlossen ist. Sie sollten eine Erfolgsmeldung sehen, dass PyPDF installiert wurde.
Sie können denselben Vorgang nutzen, um PyPDF im PyCharm-Terminal zu installieren.
Hinweis: Python muss der Systemumgebungsvariable PATH hinzugefügt werden.
2.2. PyCharm verwenden
- Öffnen Sie die PyCharm-IDE.
- Erstellen Sie ein neues Python-Projekt oder öffnen Sie ein bestehendes.
- Klicken Sie innerhalb des Projekts im oberen Menü auf Datei und wählen Sie Einstellungen.
- Navigieren Sie im Einstellungsfenster zu "Projekt:
" und klicken Sie auf "Python Interpreter". -
Klicken Sie im Fenster Python-Interpreter auf das Symbol "+" um ein neues Paket hinzuzufügen.
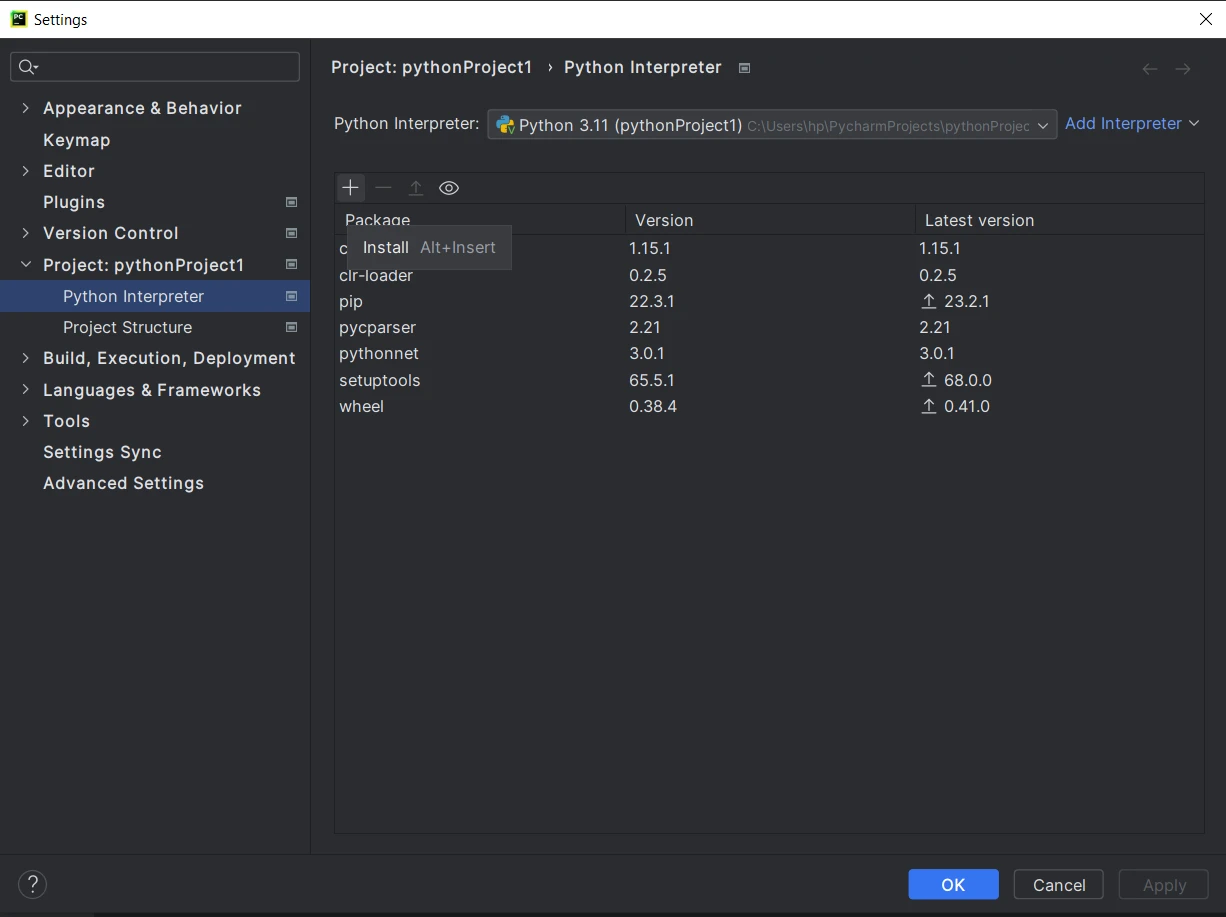
-
Suchen Sie im Fenster "Verfügbare Pakete" nach "PyPDF".
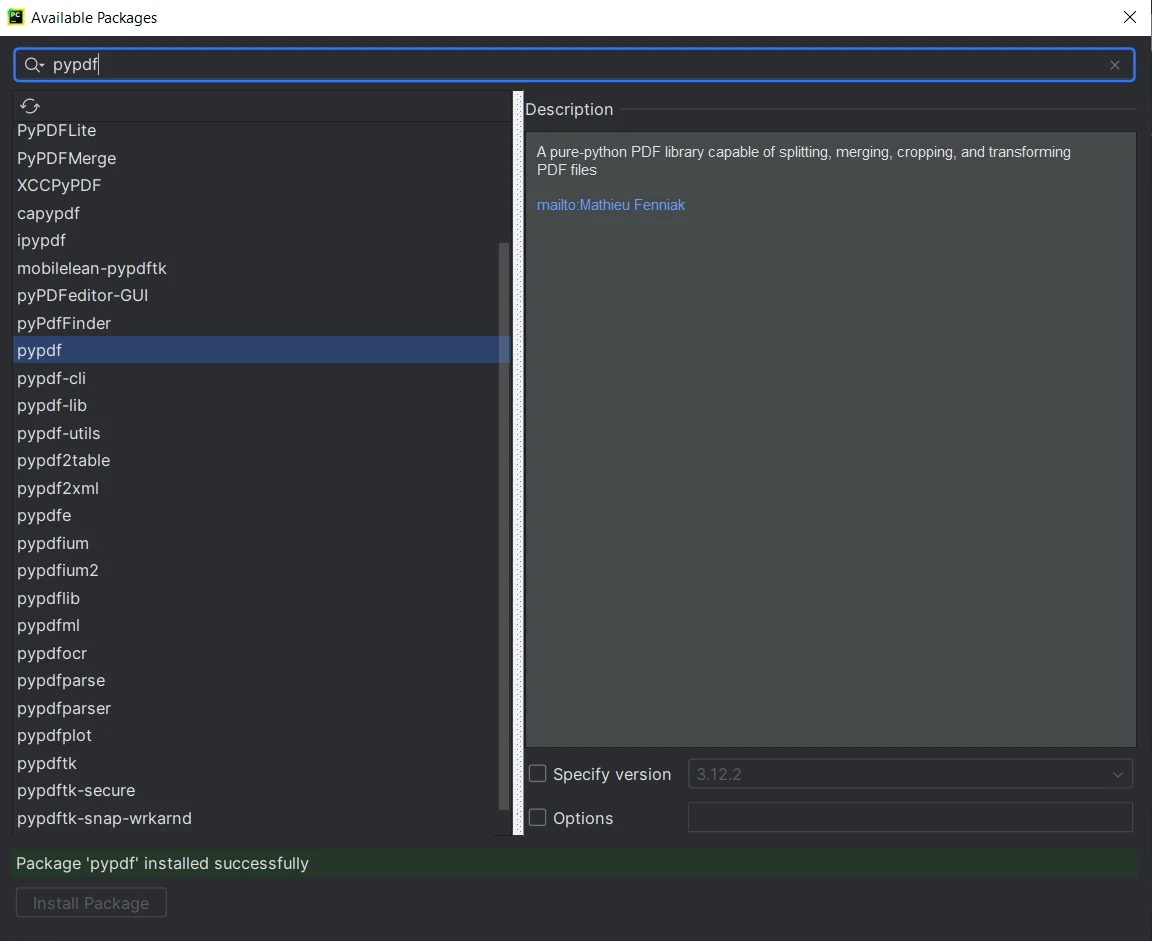
- Wählen Sie "PyPDF" aus der Liste und klicken Sie auf die Schaltfläche "Paket installieren".
- Warten Sie, bis PyCharm PyPDF heruntergeladen und installiert hat.
3. IronPDF-Installation
Voraussetzung
IronPDF for Python nutzt die leistungsstarke .NET 6.0-Technologie als Grundlage. Um IronPDF for Python effektiv zu nutzen, muss daher die .NET 6.0-Laufzeit auf Ihrem System installiert sein. Linux- und Mac-Nutzer müssen möglicherweise .NET von der offiziellen Microsoft-Website (https://dotnet.microsoft.com/en-us/download/dotnet/6.0) herunterladen und installieren, bevor sie mit diesem Python-Paket arbeiten können. Durch das Vorhandensein der .NET 6.0-Laufzeit wird eine nahtlose Integration und optimale Leistung bei der Verwendung von IronPDF for Python für PDF-Verarbeitungsaufgaben ermöglicht.
3.1. Die Eingabeaufforderung verwenden
- Öffnen Sie die Eingabeaufforderung oder das Terminal auf Ihrem Computer.
-
Um IronPDF zu installieren, verwenden Sie den folgenden pip-Befehl:
pip install ironpdfpip install ironpdfSHELL - Warten Sie, bis die Installation abgeschlossen ist. Sie sollten eine Erfolgsmeldung sehen, dass IronPDF installiert wurde.
3.2. PyCharm verwenden
- Öffnen Sie die PyCharm-IDE auf Ihrem Computer.
- Erstellen Sie ein neues Python-Projekt oder öffnen Sie ein bestehendes.
- Klicken Sie innerhalb des Projekts im oberen Menü auf "Datei" und wählen Sie "Einstellungen".
- Navigieren Sie im Einstellungsfenster zu "Projekt:
" und klicken Sie auf "Python-Interpreter". - Klicken Sie im Fenster Python-Interpreter auf das Symbol "+" um ein neues Paket hinzuzufügen.
-
Suchen Sie im Fenster "Verfügbare Pakete" nach "IronPDF".
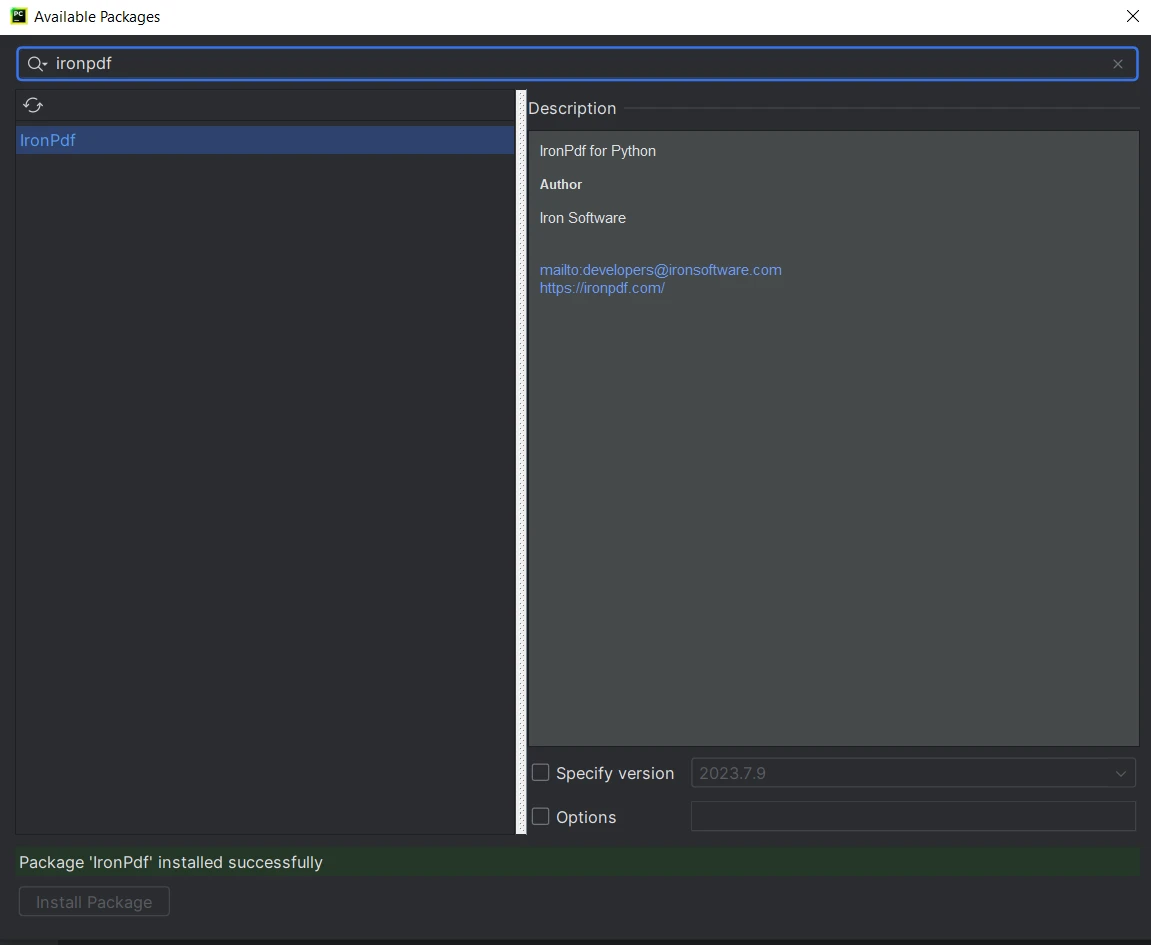
- Wählen Sie "IronPDF" aus der Liste und klicken Sie auf die Schaltfläche "Paket installieren".
- Warten Sie, bis IronPDF heruntergeladen und installiert ist. Eine Erfolgsmeldung wird angezeigt, dass IronPDF installiert ist.
Jetzt sind beide Bibliotheken installiert und einsatzbereit. Kommen wir nun zum Vergleich selbst.
4. PDF-Dokumente erstellen
4.1. PyPDF verwenden
PyPDF bietet grundlegende Funktionen zur Erstellung neuer PDF-Dateien. Es hat jedoch keine integrierte Methode zur direkten Konvertierung von HTML-Inhalten in PDF. Um ein neues PDF mit PyPDF zu erstellen, müssen wir Inhalte zu einem bestehenden PDF hinzufügen oder ein neues leeres PDF erstellen und dann Text oder Bilder hinzufügen. Der folgende Code hilft bei der Durchführung dieser Aufgabe der PDF-Erstellung:
from pypdf import PdfWriter, PdfReader
# Create a new PDF file
pdf_output = PdfWriter()
# Add a new blank page
page = pdf_output.add_blank_page(width=610, height=842) # Width and height are in points (1 inch = 72 points)
# Read content from an existing PDF
with open('input.pdf', 'rb') as existing_pdf:
existing_pdf_reader = PdfReader(existing_pdf)
# Merge content from the first page of the existing PDF
page.merge_page(existing_pdf_reader.pages[0])
# Save the new PDF to a file
with open('output.pdf', 'wb') as output_file:
pdf_output.write(output_file)from pypdf import PdfWriter, PdfReader
# Create a new PDF file
pdf_output = PdfWriter()
# Add a new blank page
page = pdf_output.add_blank_page(width=610, height=842) # Width and height are in points (1 inch = 72 points)
# Read content from an existing PDF
with open('input.pdf', 'rb') as existing_pdf:
existing_pdf_reader = PdfReader(existing_pdf)
# Merge content from the first page of the existing PDF
page.merge_page(existing_pdf_reader.pages[0])
# Save the new PDF to a file
with open('output.pdf', 'wb') as output_file:
pdf_output.write(output_file)Die Eingabedatei enthält 28 Seiten und nur die erste Seite wird der neuen PDF-Datei hinzugefügt. Die Ausgabe sieht wie folgt aus:
4.2. IronPDF verwenden
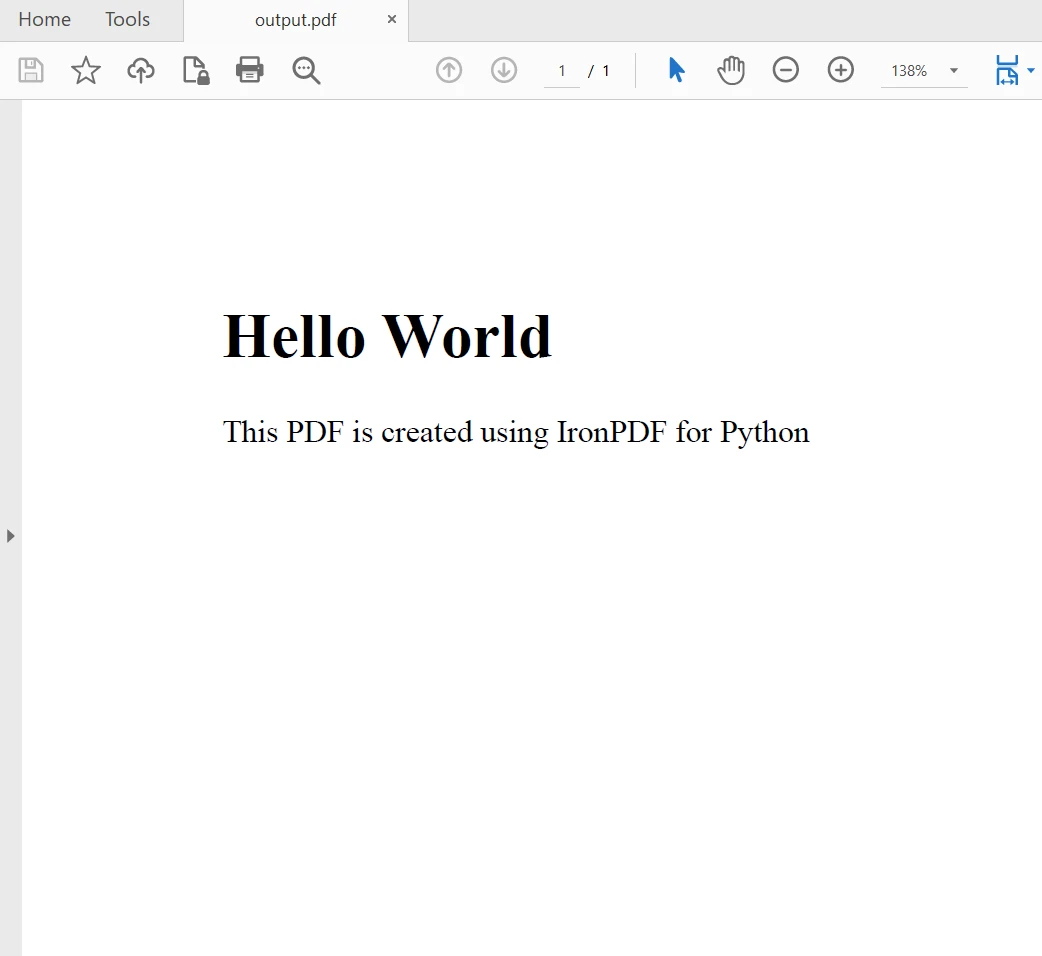
IronPDF bietet erweiterte Funktionen zur direkten Erstellung neuer PDF-Dateien aus HTML-Inhalten. Dies macht das Erstellen dynamischer Berichte und Dokumente bequem, ohne zusätzliche Schritte. Hier ist der Beispielcode:
import ironpdf
# Set IronPDF license key to unlock full features
ironpdf.License.LicenseKey = "YOUR-LICENSE-KEY-HERE"
# Create a PDF from an HTML string using Python
renderer = ironpdf.ChromePdfRenderer()
pdf = renderer.RenderHtmlAsPdf("<h1>Hello World</h1><p>This PDF is created using IronPDF for Python</p>")
# Export to a file or stream
pdf.SaveAs("output.pdf")
# Advanced Example with HTML Assets
# Load external html assets Images, CSS, and JavaScript.
# An optional BasePath 'C:\site\assets\' is set as the file location to load assets from
myAdvancedPdf = renderer.RenderHtmlAsPdf("<img src='icons/iron.png'>", "C:\\site\\assets")
myAdvancedPdf.SaveAs("html-with-assets.pdf")import ironpdf
# Set IronPDF license key to unlock full features
ironpdf.License.LicenseKey = "YOUR-LICENSE-KEY-HERE"
# Create a PDF from an HTML string using Python
renderer = ironpdf.ChromePdfRenderer()
pdf = renderer.RenderHtmlAsPdf("<h1>Hello World</h1><p>This PDF is created using IronPDF for Python</p>")
# Export to a file or stream
pdf.SaveAs("output.pdf")
# Advanced Example with HTML Assets
# Load external html assets Images, CSS, and JavaScript.
# An optional BasePath 'C:\site\assets\' is set as the file location to load assets from
myAdvancedPdf = renderer.RenderHtmlAsPdf("<img src='icons/iron.png'>", "C:\\site\\assets")
myAdvancedPdf.SaveAs("html-with-assets.pdf")Im obigen Code haben wir zunächst den Lizenzschlüssel angewendet, um die volle Leistung von IronPDF zu nutzen. Sie können es auch ohne Lizenzschlüssel verwenden, aber Wasserzeichen werden in den erstellten PDF-Dateien erscheinen. Dann erstellen wir zwei PDF-Dokumente, zuerst mit einem HTML-String als Inhalt und zweitens mit Ressourcen. Das Ergebnis ist wie folgt:
5. PDF-Dateien zusammenführen
5.1. PyPDF verwenden
PyPDF ermöglicht das Zusammenführen mehrerer Seiten/Dokumente zu einem einzigen PDF, indem Seiten von einem PDF in ein anderes eingefügt werden. Fügen Sie die Eingabepfade aller PDF-Dateien in der Liste hinzu und verwenden Sie die Anhangsmethode, um eine einzelne Datei zu kombinieren und zu erstellen.
from pypdf import PdfWriter
merger = PdfWriter()
for pdf in ["file1.pdf", "file2.pdf", "file3.pdf"]:
merger.append(pdf)
merger.write("merged-pdf.pdf")
merger.close()from pypdf import PdfWriter
merger = PdfWriter()
for pdf in ["file1.pdf", "file2.pdf", "file3.pdf"]:
merger.append(pdf)
merger.write("merged-pdf.pdf")
merger.close()5.2. IronPDF verwenden
IronPDF bietet ebenfalls ähnliche Funktionen zum Zusammenführen von Dokumenten zu einem, was es einfach macht, Inhalte aus verschiedenen PDF-Quellen zu konsolidieren.
import ironpdf
ironpdf.License.LicenseKey = "YOUR-LICENSE-KEY-HERE"
html_a = """<p> [PDF_A] </p>
<p> [PDF_A] 1st Page </p>
<div style='page-break-after: always;'></div>
<p> [PDF_A] 2nd Page</p>"""
html_b = """<p> [PDF_B] </p>
<p> [PDF_B] 1st Page </p>
<div style='page-break-after: always;'></div>
<p> [PDF_B] 2nd Page</p>"""
renderer = ironpdf.ChromePdfRenderer()
pdfdoc_a = renderer.RenderHtmlAsPdf(html_a)
pdfdoc_b = renderer.RenderHtmlAsPdf(html_b)
merged = ironpdf.PdfDocument.Merge([pdfdoc_a, pdfdoc_b])
merged.SaveAs("Merged.pdf")import ironpdf
ironpdf.License.LicenseKey = "YOUR-LICENSE-KEY-HERE"
html_a = """<p> [PDF_A] </p>
<p> [PDF_A] 1st Page </p>
<div style='page-break-after: always;'></div>
<p> [PDF_A] 2nd Page</p>"""
html_b = """<p> [PDF_B] </p>
<p> [PDF_B] 1st Page </p>
<div style='page-break-after: always;'></div>
<p> [PDF_B] 2nd Page</p>"""
renderer = ironpdf.ChromePdfRenderer()
pdfdoc_a = renderer.RenderHtmlAsPdf(html_a)
pdfdoc_b = renderer.RenderHtmlAsPdf(html_b)
merged = ironpdf.PdfDocument.Merge([pdfdoc_a, pdfdoc_b])
merged.SaveAs("Merged.pdf")6. PDF-Dateien teilen
6.1. PyPDF verwenden
PyPDF ist eine Python-Bibliothek, die in der Lage ist, ein einzelnes PDF in mehrere separate PDFs zu teilen, von denen jedes eine oder mehrere PDF-Seiten enthält.
from pypdf import PdfReader, PdfWriter
# Open the PDF file
pdf_file = open('input.pdf', 'rb')
# Create a PdfFileReader object
pdf_reader = PdfReader(pdf_file)
# Split each page into separate PDFs
for page_num in range(len(pdf_reader.pages)):
pdf_writer = PdfWriter()
pdf_writer.add_page(pdf_reader.pages[page_num])
output_filename = f'page_{page_num + 1}_pypdf.pdf'
with open(output_filename, 'wb') as output_file:
pdf_writer.write(output_file)
# Close the PDF file
pdf_file.close()from pypdf import PdfReader, PdfWriter
# Open the PDF file
pdf_file = open('input.pdf', 'rb')
# Create a PdfFileReader object
pdf_reader = PdfReader(pdf_file)
# Split each page into separate PDFs
for page_num in range(len(pdf_reader.pages)):
pdf_writer = PdfWriter()
pdf_writer.add_page(pdf_reader.pages[page_num])
output_filename = f'page_{page_num + 1}_pypdf.pdf'
with open(output_filename, 'wb') as output_file:
pdf_writer.write(output_file)
# Close the PDF file
pdf_file.close()Der obige Code teilt das 28-seitige PDF-Dokument, um es in einzelne Seiten zu trennen und sie als 28 neue PDF-Dateien zu speichern.
6.2. IronPDF verwenden
IronPDF bietet ebenfalls ähnliche Funktionen zum Teilen von PDFs, sodass Benutzer ein einzelnes PDF in mehrere PDF-Dateien aufteilen können, von denen jede eine einzelne PDF-Seite hat. Es erlaubt uns, eine bestimmte Seite aus einem PDF mit mehreren Seiten zu teilen. Der folgende Code hilft dabei, Dokumente in mehrere Dateien aufzuteilen:
import ironpdf
ironpdf.License.LicenseKey = "YOUR-LICENSE-KEY-HERE"
html = """<p> Hello Iron </p>
<p> This is 1st Page </p>
<div style='page-break-after: always;'></div>
<p> This is 2nd Page</p>
<div style='page-break-after: always;'></div>
<p> This is 3rd Page</p>"""
renderer = ironpdf.ChromePdfRenderer()
pdf = renderer.RenderHtmlAsPdf(html)
# take the first page
page1doc = pdf.CopyPage(0)
page1doc.SaveAs("Split1.pdf")
# take the pages 2 & 3
page23doc = pdf.CopyPages(1, 2)
page23doc.SaveAs("Split2.pdf")import ironpdf
ironpdf.License.LicenseKey = "YOUR-LICENSE-KEY-HERE"
html = """<p> Hello Iron </p>
<p> This is 1st Page </p>
<div style='page-break-after: always;'></div>
<p> This is 2nd Page</p>
<div style='page-break-after: always;'></div>
<p> This is 3rd Page</p>"""
renderer = ironpdf.ChromePdfRenderer()
pdf = renderer.RenderHtmlAsPdf(html)
# take the first page
page1doc = pdf.CopyPage(0)
page1doc.SaveAs("Split1.pdf")
# take the pages 2 & 3
page23doc = pdf.CopyPages(1, 2)
page23doc.SaveAs("Split2.pdf")Für detailliertere Informationen zu IronPDF über das Lesen von PDF-Dateien, das Drehen von PDF-Seiten, das Zuschneiden von Seiten, das Setzen von Besitzer-/Benutzer-Passwörtern und andere Sicherheitsoptionen besuchen Sie bitte diese IronPDF für Python Codebeispielseite.
7. Text aus PDF-Dateien extrahieren
7.1. PyPDF verwenden
PyPDF bietet eine unkomplizierte Methode zum Extrahieren von Text aus PDFs. Es bietet die Klasse PdfReader an, die es Benutzern ermöglicht, den Textinhalt aus der PDF-Datei zu lesen.
from pypdf import PdfReader
reader = PdfReader("input.pdf")
page = reader.pages[0]
print(page.extract_text())from pypdf import PdfReader
reader = PdfReader("input.pdf")
page = reader.pages[0]
print(page.extract_text())7.2. IronPDF verwenden
IronPDF unterstützt auch das Extrahieren von Text aus PDFs mithilfe der Klasse PdfDocument. Es stellt eine Methode namens ExtractAllText zur Verfügung, um den Textinhalt aus der PDF-Datei zu erhalten. Die kostenlose Version von IronPDF extrahiert jedoch nur wenige Zeichen aus dem PDF-Dokument. Um den vollständigen Text aus PDFs zu extrahieren, ist eine Lizenzierung von IronPDF erforderlich. Hier ist das Codebeispiel zum Extrahieren von Inhalten aus PDF-Dateien:
import ironpdf
ironpdf.License.LicenseKey = "YOUR-LICENSE-KEY-HERE"
# Load existing PDF document
pdf = ironpdf.PdfDocument.FromFile("input.pdf")
# Extract text from PDF document
all_text = pdf.ExtractAllText()
print(all_text)import ironpdf
ironpdf.License.LicenseKey = "YOUR-LICENSE-KEY-HERE"
# Load existing PDF document
pdf = ironpdf.PdfDocument.FromFile("input.pdf")
# Extract text from PDF document
all_text = pdf.ExtractAllText()
print(all_text)Um mehr über das Extrahieren von Text zu erfahren, besuchen Sie bitte dieses PDF-Text zu Python Beispiel.
8. Lizenzierung
PyPDF
PyPDF wird unter der MIT-Lizenz vertrieben, einer Open-Source-Softwarelizenz, die für ihre permissiven Bedingungen bekannt ist. Die MIT-Lizenz erlaubt es Nutzern, die PyPDF-Bibliothek uneingeschränkt zu verwenden, zu modifizieren, zu verteilen und weiterzulizenzieren. Es ist nicht erforderlich, den Quellcode von Anwendungen, die PyPDF verwenden, offenzulegen, was es sowohl für persönliche als auch kommerzielle Projekte geeignet macht.
Der vollständige Text der MIT-Lizenz ist in der Regel im PyPDF-Quellcode enthalten und kann von Nutzern in der Datei "LICENSE" innerhalb der Bibliotheksdistribution gefunden werden. Darüber hinaus dient das PyPDF GitHub-Repository (https://github.com/py-pdf/pypdf) als Hauptquelle für den Zugriff auf die neueste Version der Bibliothek und die zugehörigen Lizenzinformationen.
IronPDF
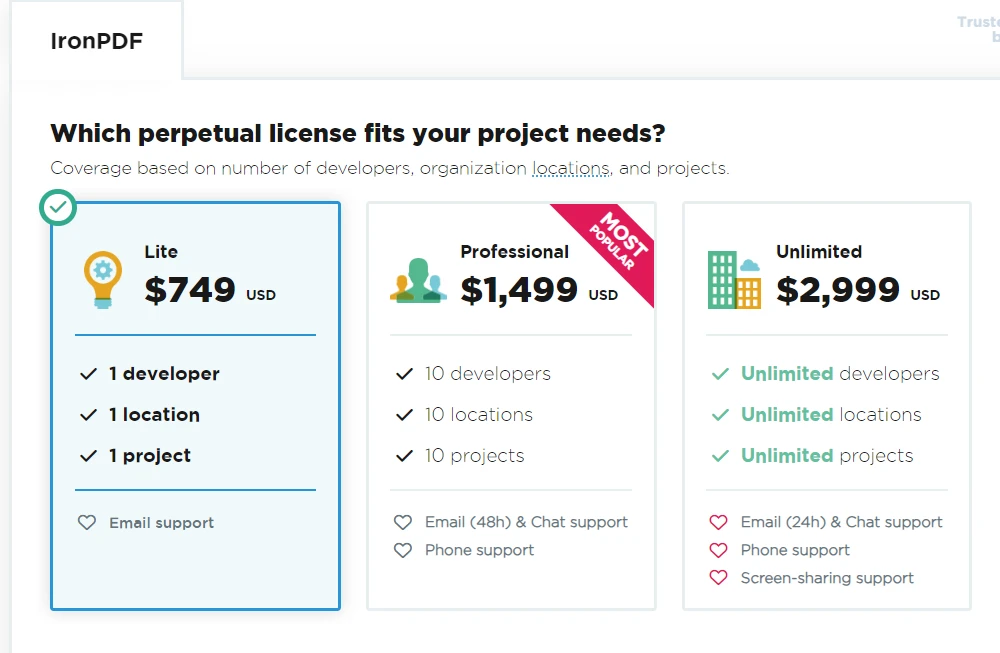
IronPDF ist eine kommerzielle Bibliothek und nicht Open-Source. Es wird von Iron Software entwickelt und vertrieben. Die Nutzung von IronPDF erfordert eine gültige Lizenz von Iron Software. Es gibt verschiedene Arten von Lizenzen, einschließlich Testversionen für Evaluierungszwecke und bezahlte Lizenzen für kommerzielle Nutzung.
Als kommerzielles Produkt bietet IronPDF zusätzliche Funktionen und technischen Support im Vergleich zu Open-Source-Alternativen. Um eine Lizenz für IronPDF zu erwerben, können Nutzer die offizielle Website besuchen, um verfügbare Lizenzoptionen, Preise und Support-Details zu erkunden. Das Lite-Paket beginnt ab NVIDIA_64_LICENSE und ist eine unbefristete Lizenz.
9. Schlussfolgerung
Zusammenfassung
PyPDF ist eine leistungsstarke und benutzerfreundliche Python-Bibliothek für die Arbeit mit PDF-Dateien. Seine Funktionen zum Lesen, Schreiben, Zusammenführen und Teilen von PDFs machen es zu einem unverzichtbaren Werkzeug für PDF-Manipulationsaufgaben. Egal, ob Sie Text aus einem PDF extrahieren, neue PDFs von Grund auf neu erstellen oder bestehende Dokumente zusammenführen und teilen müssen, PyPDF bietet eine zuverlässige und effiziente Lösung. Durch die Nutzung der Fähigkeiten von PyPDF können Python-Entwickler ihre PDF-bezogenen Arbeitsabläufe optimieren und ihre Produktivität steigern.
IronPDF ist eine umfassende und effiziente PDF-Manipulationsbibliothek für Python, die eine Vielzahl von Funktionen zum Lesen, Erstellen, Zusammenführen und Teilen von PDF-Dateien bietet. Ob Sie dynamische PDF-Berichte erstellen, Dokumentinformationen aus bestehenden PDFs extrahieren oder mehrere Dokumente zusammenführen müssen, IronPDF bietet eine zuverlässige und benutzerfreundliche Lösung. Durch die Nutzung der Fähigkeiten von IronPDF können Python-Entwickler ihre PDF-bezogenen Arbeitsabläufe optimieren und ihre Produktivität steigern.
Im Gesamtvergleich ist PyPDF eine leichte und einfach zu bedienende Bibliothek, die für grundlegende PDF-Operationen geeignet ist. Es ist eine gute Wahl für Projekte mit einfachen PDF-Anforderungen. IronPDF hingegen bietet eine umfassendere API und robuste Leistung, was es ideal für Projekte macht, die erweiterte PDF-Verarbeitungsmöglichkeiten, den Umgang mit großen PDF-Dateien und die Durchführung komplexer Aufgaben erfordern.
Abschluss
Beide Bibliotheken bieten gute Codierungsmöglichkeiten für allgemeine PDF-Aufgaben. PyPDF eignet sich für einfache Operationen und schnelle Implementierungen, während IronPDF eine umfassendere und vielseitigere API für den Umgang mit komplexen PDF-bezogenen Aufgaben bietet.
In Bezug auf die Leistung ist IronPDF wahrscheinlich leistungsfähiger als PyPDF, insbesondere wenn es um große PDF-Dateien oder Aufgaben geht, die komplexe PDF-Manipulationen erfordern.
Die Entscheidung zwischen den beiden Bibliotheken hängt von den spezifischen Anforderungen des Projekts und der Komplexität der PDF-bezogenen Aufgaben ab.
IronPDF ist auch für eine kostenlose Testversion erhältlich, um seine vollständige Funktionalität im kommerziellen Modus zu testen. Laden Sie IronPDF for Python von hier herunter.
Häufig gestellte Fragen
Was sind die Hauptunterschiede zwischen PyPDF und IronPDF für PDF-Manipulation in Python?
PyPDF ist eine reine Python-Bibliothek, die grundlegende Funktionen zur PDF-Manipulation wie Lesen, Schreiben und Zusammenführen von PDFs bietet. Im Gegensatz dazu basiert IronPDF auf der IronPDF for .NET-Bibliothek und bietet erweiterte Funktionen wie HTML-zu-PDF-Konvertierung, Formularverarbeitung und leistungsstarke Operationen für komplexe PDF-Aufgaben.
Wie kann ich HTML in PDF in Python konvertieren?
Sie können HTML in Python mit IronPDF in PDF umwandeln. Es bietet Methoden wie RenderHtmlAsPdf, um HTML-Strings zu konvertieren, und RenderHtmlFileAsPdf, um HTML-Dateien in PDFs zu konvertieren.
Was sind die Installationsanforderungen für die Verwendung von IronPDF in einem Python-Projekt?
Um IronPDF mit Python zu verwenden, müssen Sie die .NET 6.0-Laufzeit auf Ihrem System installiert haben. IronPDF kann über pip mit dem Befehl pip install ironpdf installiert werden.
Ist es möglich, Text und Bilder aus PDFs mit PyPDF zu extrahieren?
Ja, PyPDF ermöglicht die Extraktion von Text und Bildern aus PDFs. Es ist für grundlegende Aufgaben der PDF-Manipulation konzipiert, wie Textextraktion, Zusammenführen und Aufteilen von PDFs.
Was sind die Vorteile der Verwendung von IronPDF für komplexe PDF-Operationen?
IronPDF bietet eine robuste Leistung und umfangreiche Funktionen für komplexe PDF-Operationen, einschließlich HTML-zu-PDF-Konvertierung, Formularverarbeitung, fortgeschrittener Text- und Bildmanipulation sowie hoher Leistung bei großen Dateien.
Kann ich PDF-Dateien mit IronPDF zusammenführen und trennen?
Ja, IronPDF bietet Funktionen zum effizienten Zusammenführen und Aufteilen von PDF-Dateien und stellt eine umfassende Lösung für das Management komplexer PDF-Operationen innerhalb von Python-Anwendungen bereit.
Was sind häufige Anwendungsfälle für die Verwendung von PDFs in verschiedenen Branchen?
PDFs werden häufig für das Teilen von Dokumenten wie Berichten, Rechnungen, Formularen und E-Books in verschiedenen Branchen verwendet, da sie eine konsistente Darstellung auf verschiedenen Plattformen und Geräten bieten.
Welche Lizenzoptionen gibt es für IronPDF?
IronPDF ist ein kommerzielles Produkt, das eine gültige Lizenz von Iron Software erfordert. Verschiedene Lizenzoptionen sind verfügbar, einschließlich Testversionen, um unterschiedlichen Projektanforderungen gerecht zu werden.