Uma comparação entre IronPDF for Python e PyPDF
Os PDFs (Portable Document Format) são um formato de arquivo amplamente utilizado para preservar o layout e a formatação das informações do documento em diferentes plataformas. Eles são extremamente populares em diversos setores devido à sua capacidade de manter uma aparência consistente, independentemente do dispositivo ou sistema operacional usado para abri-los. Os PDFs são comumente utilizados para compartilhar relatórios, faturas, formulários, livros eletrônicos, dados personalizados e outros documentos importantes.
Trabalhar com arquivos PDF em Python tornou-se um aspecto crucial em muitos projetos. O Python oferece diversas bibliotecas que simplificam a manipulação de arquivos PDF, facilitando a extração de informações, a criação de novos documentos, a fusão ou divisão de documentos existentes e a execução de outras tarefas relacionadas a PDFs.
Neste artigo, faremos uma comparação abrangente de duas bibliotecas Python renomadas, projetadas para manipular arquivos PDF: PyPDF e IronPDF . Ao avaliar os recursos e as capacidades de ambas as bibliotecas, pretendemos fornecer aos desenvolvedores informações valiosas para ajudá-los a tomar uma decisão consciente sobre qual delas melhor se adapta às necessidades específicas de sua aplicação de software.
Essas bibliotecas oferecem ferramentas robustas para agilizar o trabalho com PDFs, permitindo que os desenvolvedores manipulem documentos PDF de forma eficiente em seus aplicativos Python. Vamos então analisar a fundo a comparação e explorar os pontos fortes de cada biblioteca para facilitar suas tarefas relacionadas a PDFs.
PyPDF - Biblioteca PDF em Python puro
PyPDF é uma biblioteca Python pura para PDF que fornece funcionalidades básicas para leitura, escrita, descriptografia de arquivos PDF e manipulação de documentos PDF. Permite aos desenvolvedores extrair texto e imagens de PDFs, mesclar vários arquivos PDF, dividir PDFs grandes em PDFs menores e muito mais. O PyPDF é conhecido por sua simplicidade e facilidade de uso, tornando-o uma escolha adequada para tarefas simples com PDFs.
Oferece um conjunto abrangente de recursos para trabalhar com documentos PDF, tornando-se uma excelente opção para uma ampla gama de tarefas relacionadas a PDFs.
Características
PyPDF é uma biblioteca Python para PDF capaz de realizar as seguintes funcionalidades:
- Ler arquivos PDF: Extrair texto, imagens e metadados de arquivos PDF existentes.
- Criar arquivos PDF: Crie novos PDFs do zero ou modifique os existentes com texto e imagens.
- Unir arquivos PDF: Combine vários arquivos PDF em um único documento.
- Dividir arquivos PDF: Divida um PDF em arquivos separados, cada um contendo uma ou mais páginas.
- Girar e sobrepor páginas: Gire as páginas e adicione marcas d'água ou sobreposições aos PDFs.
- Criptografar e descriptografar arquivos PDF: Adicione segurança aos seus PDFs criptografando-os e descriptografando-os.
- Extração de texto: Obtenha texto simples de PDFs ou de regiões específicas dentro de uma página.
- Extração de imagens: Recuperar imagens incorporadas em PDFs.
- Manipular arquivos PDF: Copiar, excluir ou reorganizar páginas dentro de um arquivo PDF.
- Preenchimento de campos de formulário: Preencha campos de formulário em PDFs programaticamente.
IronPDF - Biblioteca PDF em Python
IronPDF é uma biblioteca abrangente para manipulação de PDFs em Python, construída sobre a biblioteca .NET do IronPDF. Oferece uma API poderosa com recursos avançados, como conversão de HTML para PDF, manipulação de anotações e campos de formulário em PDF e execução eficiente de operações complexas em PDF. O IronPDF é a opção preferida para projetos que exigem processamento robusto de PDF, alto desempenho e amplo suporte a recursos.
IronPDF é uma biblioteca Python para PDF capaz de lidar com tarefas de processamento de PDF de forma integrada. Oferece uma solução confiável e rica em recursos para manipulação de PDFs para desenvolvedores Python. Com o IronPDF, você pode gerar, modificar e extrair conteúdo de várias páginas de um PDF sem esforço, tornando-o uma excelente opção para diversas aplicações relacionadas a PDFs.
Características
Aqui estão alguns recursos importantes do IronPDF:
- Geração de PDF: O IronPDF permite que os desenvolvedores criem documentos PDF do zero ou convertam conteúdo HTML em formato PDF, facilitando a geração de relatórios e documentos dinâmicos e visualmente atraentes.
- Manipulação avançada de texto e imagem: os desenvolvedores podem manipular facilmente texto e imagens em arquivos PDF. O IronPDF oferece funcionalidades para adicionar, editar e formatar texto, bem como inserir, redimensionar e posicionar imagens com precisão.
- Fusão e divisão de PDFs: O IronPDF permite mesclar vários arquivos PDF em um único documento e dividir um PDF em vários arquivos separados, oferecendo flexibilidade no gerenciamento do conteúdo do PDF.
- Suporte a formulários PDF: Com o IronPDF, os desenvolvedores podem trabalhar com formulários PDF, permitindo que preencham campos, extraiam dados e criem PDFs interativos.
- Segurança e criptografia de PDF: O IronPDF oferece recursos para adicionar proteção por senha e criptografia a documentos PDF, garantindo a segurança e a confidencialidade dos dados.
- Anotações em PDF: Os desenvolvedores podem adicionar anotações, como comentários, destaques e marcadores, para melhorar a colaboração e a legibilidade em PDFs.
- Cabeçalho e rodapé: O IronPDF permite adicionar cabeçalhos e rodapés às páginas PDF, fornecendo identidade visual e contexto ao documento.
- Geração de código de barras: O IronPDF facilita a geração de vários tipos de códigos de barras e códigos QR diretamente em documentos PDF usando HTML.
- Alto desempenho: Construído sobre a biblioteca .NET do IronPDF, o IronPDF oferece alto desempenho e eficiência no processamento de arquivos PDF grandes e operações complexas.
O artigo agora segue da seguinte forma:
- Criar um projeto em Python
- Instalação do PyPDF
- Instalação do IronPDF
- Criando documentos PDF
- Unir arquivos PDF
- Dividir arquivos PDF
- Extraindo texto de arquivos PDF
- Licenciamento
- Conclusão
1. Criar um projeto em Python
Utilizar um Ambiente de Desenvolvimento Integrado (IDE) para projetos em Python pode aumentar significativamente a produtividade. Dentre as opções populares, vou usar o PyCharm, pois ele se destaca pelo seu recurso inteligente de preenchimento automático de código, depuração poderosa e integração perfeita com sistemas de controle de versão. Caso não o tenha instalado, você pode baixá-lo do site da JetBrains (PyCharm ) ou usar qualquer IDE/editor de texto para programação em Python, como o VS Code.
Para criar um projeto Python no PyCharm:
- Inicie o PyCharm e clique em " Criar novo projeto " na tela de boas-vindas do PyCharm ou acesse Arquivo > Novo projeto no menu.
- Escolha o interpretador Python. Se você ainda não configurou um interpretador, clique no ícone de engrenagem e configure um novo.
- Selecione a localização e o modelo do projeto.
- Forneça o nome e as configurações do projeto e clique em Criar .
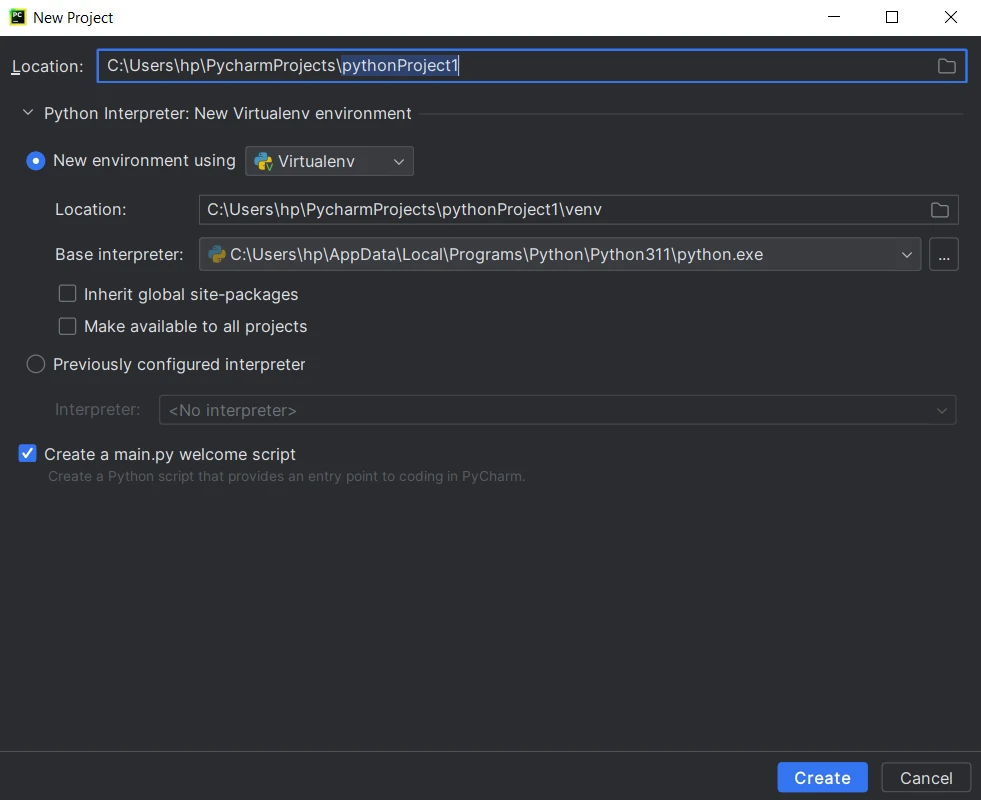
- Comece a programar, executar e depurar seu projeto Python.
2. Instalação do PyPDF
PyPDF, uma biblioteca Python pura, pode ser instalada de diversas maneiras. Podemos instalá-lo usando tanto o Prompt de Comando quanto o PyCharm.
2.1. Usando o Prompt de Comando
- Abra o Prompt de Comando ou o terminal no seu computador.
-
Para instalar o PyPDF, utilize o seguinte comando pip:
pip install pypdfpip install pypdfSHELL - Aguarde a conclusão da instalação do PyPDF. Você deverá ver uma mensagem de sucesso indicando que o PyPDF foi instalado.
Você pode usar o mesmo processo para instalar o PyPDF no Terminal do PyCharm.
Observação: o Python deve ser adicionado à variável de ambiente PATH do sistema.
2.2. Usando o PyCharm
- Abra o ambiente de desenvolvimento integrado (IDE) PyCharm.
- Crie um novo projeto Python ou abra um já existente.
- Depois de acessar o projeto, clique em Arquivo no menu superior e selecione Configurações .
- Na janela de configurações, navegue até " Projeto:
"e clique em " Interpretador Python ". - Na janela do interpretador Python, clique no ícone " + " para adicionar um novo pacote.
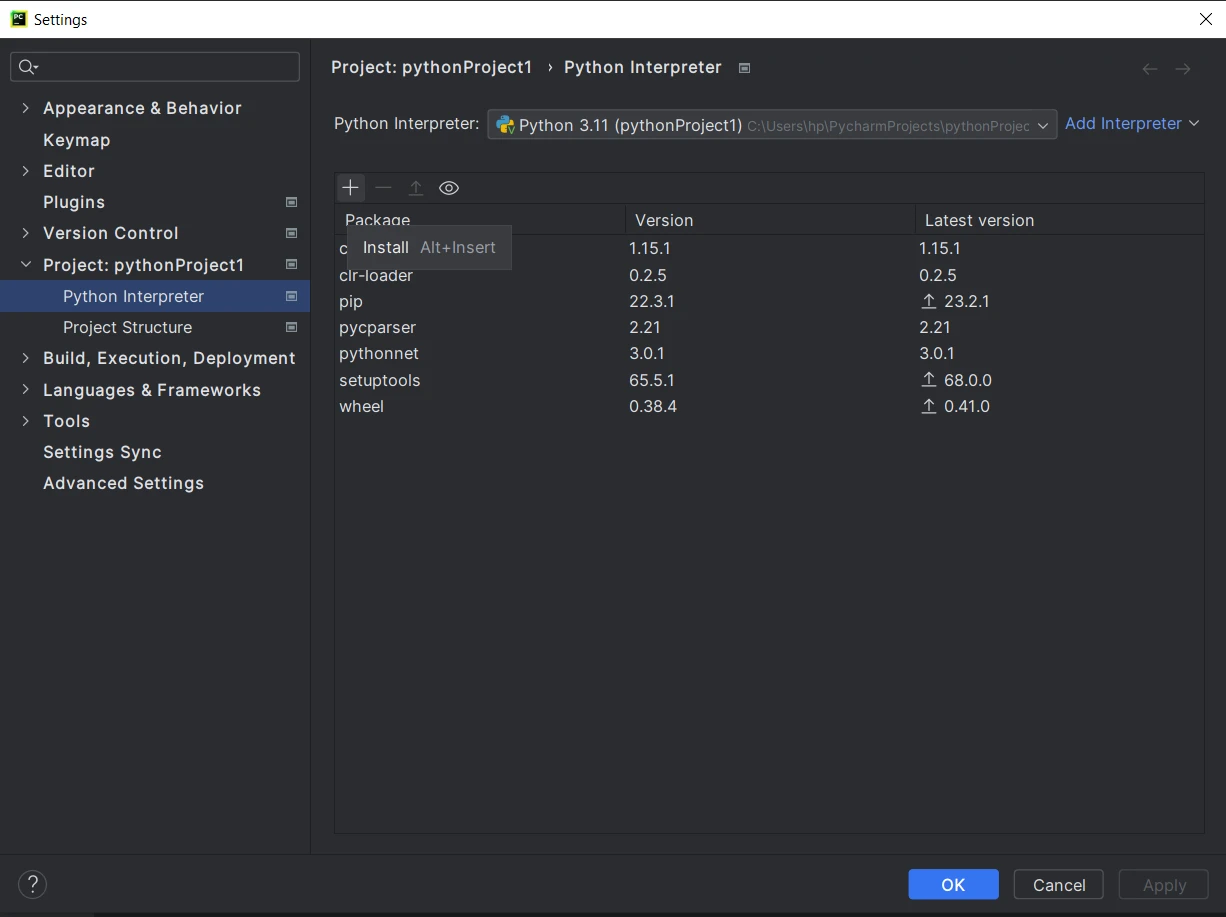
- Na janela " Pacotes Disponíveis ", procure por " PyPDF ".
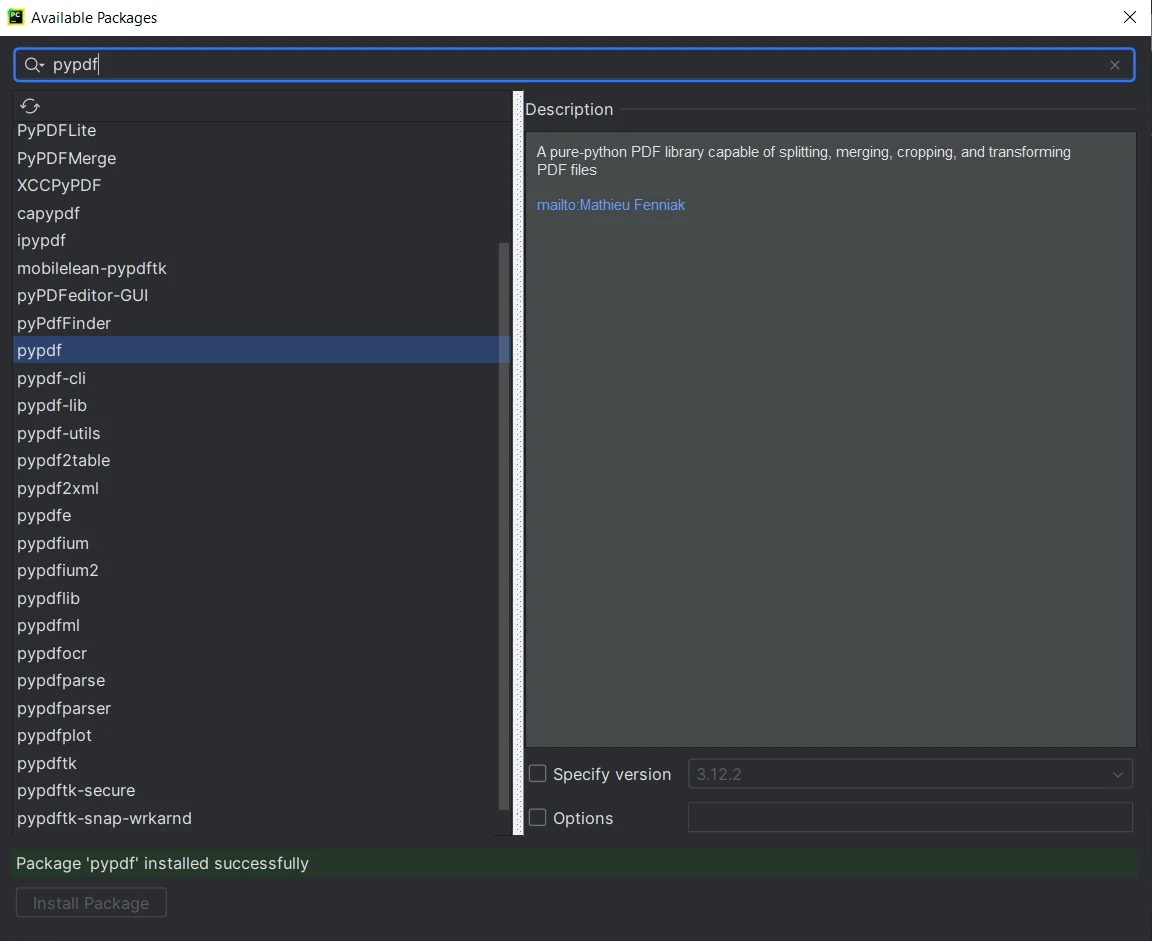
- Selecione " PyPDF " na lista e clique no botão " Instalar pacote ".
- Aguarde o PyCharm baixar e instalar o PyPDF.
3. Instalação do IronPDF
Pré-requisito
O IronPDF for Python utiliza a poderosa tecnologia .NET 6.0 como base. Consequentemente, para utilizar o IronPDF for Python de forma eficaz, é essencial ter o ambiente de execução .NET 6.0 instalado em seu sistema. Usuários de Linux e Mac podem precisar baixar e instalar o .NET do site oficial da Microsoft (https://dotnet.microsoft.com/en-us/download/dotnet/6.0 ) antes de prosseguir com o trabalho com este pacote Python. Garantir a presença do ambiente de execução .NET 6.0 permitirá uma integração perfeita e um desempenho ideal ao usar o IronPDF for Python em tarefas de processamento de PDF.
3.1. Usando o Prompt de Comando
- Abra o Prompt de Comando ou o terminal no seu computador.
-
Para instalar o IronPDF, utilize o seguinte comando pip:
pip install ironpdf
- Aguarde a conclusão da instalação. Você deverá ver uma mensagem de sucesso indicando que o IronPDF foi instalado.
3.2. Usando o PyCharm
- Abra o ambiente de desenvolvimento integrado (IDE) PyCharm no seu computador.
- Crie um novo projeto Python ou abra um já existente.
- Depois de acessar o projeto, clique em " Arquivo " no menu superior e selecione " Configurações ".
- Na janela de configurações, navegue até " Projeto:
"e clique em "Interpretador Python". - Na janela do interpretador Python, clique no ícone " + " para adicionar um novo pacote.
- Na janela "Pacotes Disponíveis", pesquise por "IronPDF".
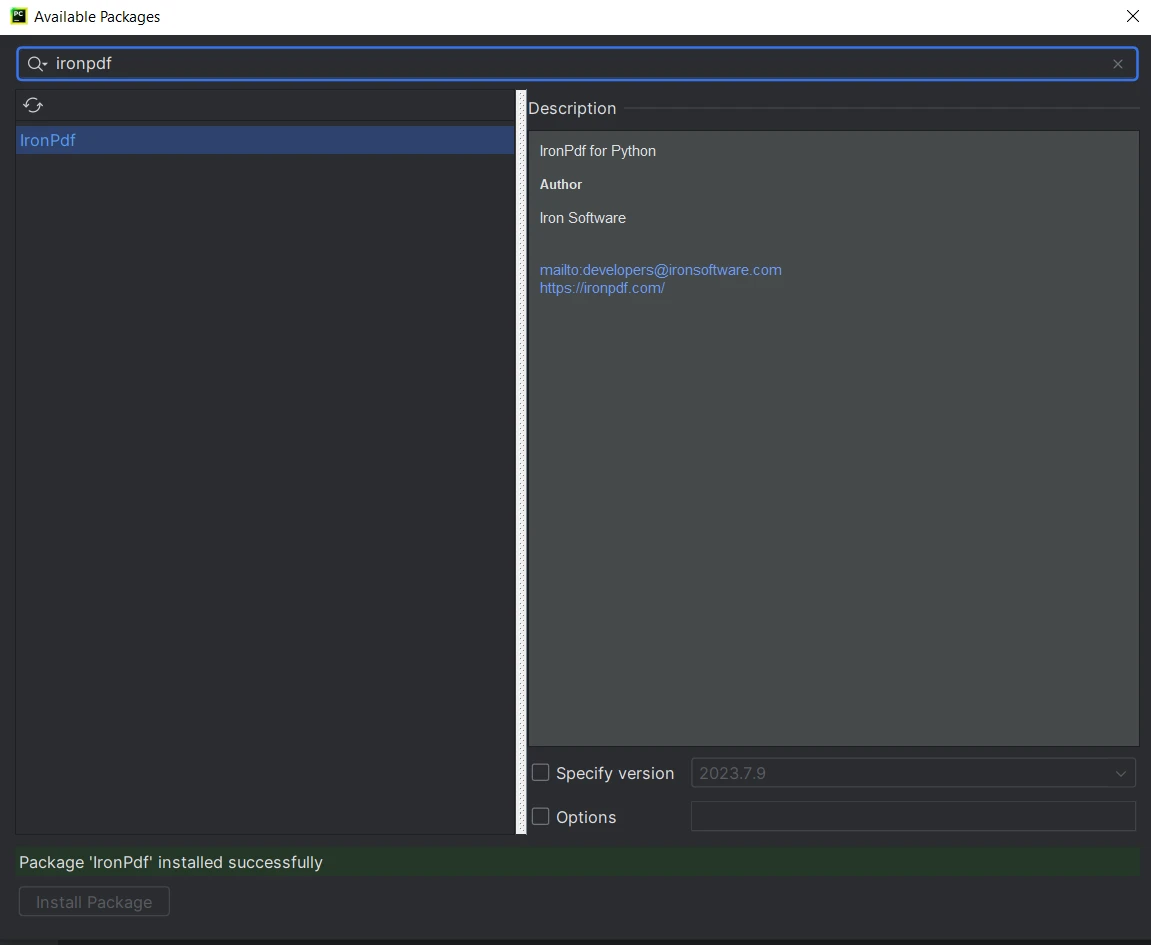
- Selecione "IronPDF" da lista e clique no botão "Instalar Pacote".
- Aguarde o download e a instalação do IronPDF . Uma mensagem de sucesso será exibida, informando que o IronPDF foi instalado.
Agora, ambas as bibliotecas estão instaladas e prontas para uso. Vamos passar à comparação propriamente dita.
4. Criando documentos PDF
4.1. Usando PyPDF
O PyPDF oferece funcionalidades básicas para criar novos arquivos PDF. No entanto, não possui um método integrado para converter diretamente conteúdo HTML em PDF. Para criar um novo PDF usando o PyPDF, precisamos adicionar conteúdo a um PDF existente ou criar um novo PDF em branco e, em seguida, adicionar texto ou imagens a ele. O código a seguir ajuda a realizar essa tarefa de criar arquivos PDF:
from pypdf import PdfWriter, PdfReader
# Create a new PDF file
pdf_output = PdfWriter()
# Add a new blank page
page = pdf_output.add_blank_page(width=610, height=842) # Width and height are in points (1 inch = 72 points)
# Read content from an existing PDF
with open('input.pdf', 'rb') as existing_pdf:
existing_pdf_reader = PdfReader(existing_pdf)
# Merge content from the first page of the existing PDF
page.merge_page(existing_pdf_reader.pages[0])
# Save the new PDF to a file
with open('output.pdf', 'wb') as output_file:
pdf_output.write(output_file)from pypdf import PdfWriter, PdfReader
# Create a new PDF file
pdf_output = PdfWriter()
# Add a new blank page
page = pdf_output.add_blank_page(width=610, height=842) # Width and height are in points (1 inch = 72 points)
# Read content from an existing PDF
with open('input.pdf', 'rb') as existing_pdf:
existing_pdf_reader = PdfReader(existing_pdf)
# Merge content from the first page of the existing PDF
page.merge_page(existing_pdf_reader.pages[0])
# Save the new PDF to a file
with open('output.pdf', 'wb') as output_file:
pdf_output.write(output_file)O arquivo de entrada contém 28 páginas e apenas a primeira página é adicionada ao novo arquivo PDF. O resultado é o seguinte:
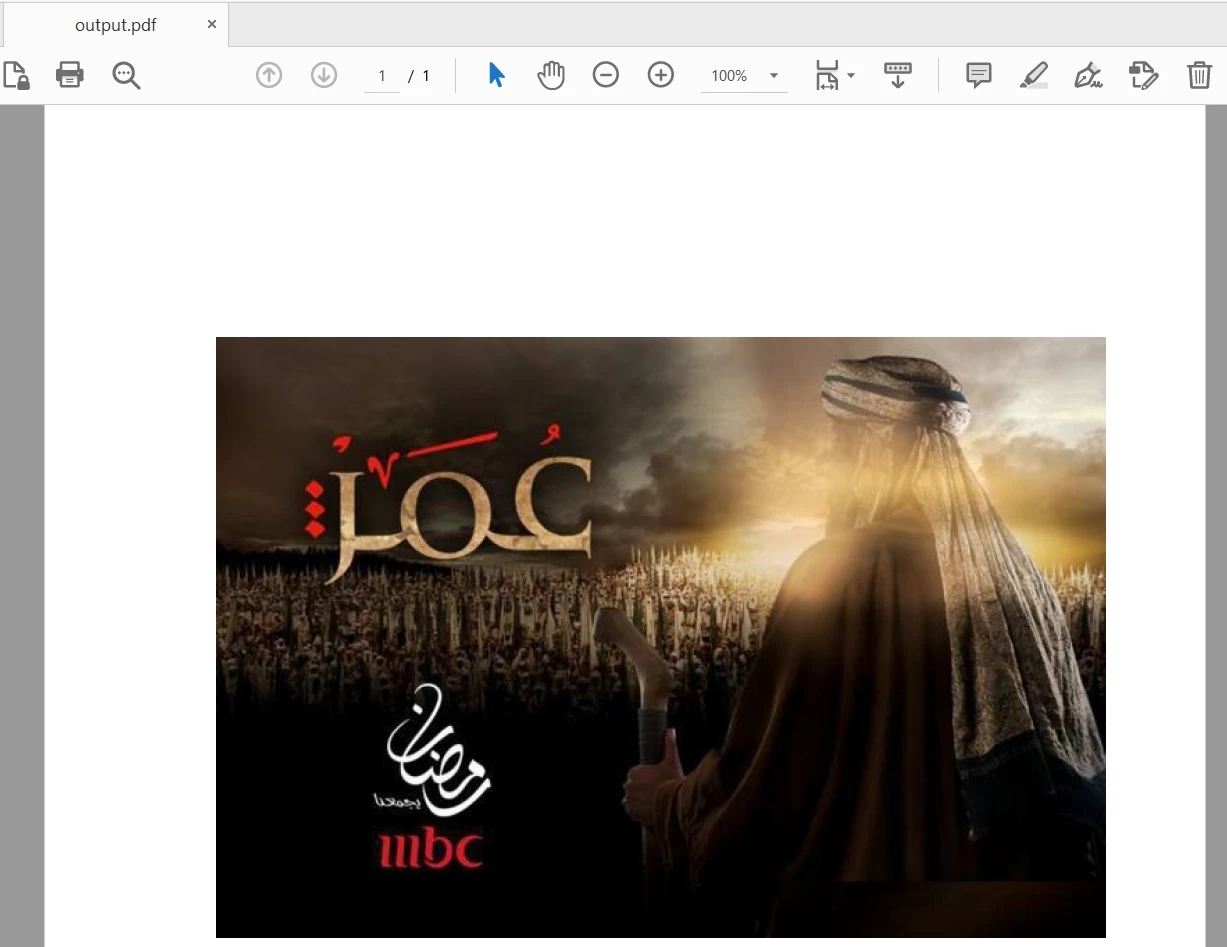
4.2. Usando o IronPDF
O IronPDF oferece recursos avançados para criar novos arquivos PDF diretamente a partir de conteúdo HTML. Isso facilita a geração de relatórios e documentos dinâmicos sem a necessidade de etapas adicionais. Aqui está o código de exemplo:
import ironpdf
# Set IronPDF license key to unlock full features
ironpdf.License.LicenseKey = "YOUR-LICENSE-KEY-HERE"
# Create a PDF from an HTML string using Python
renderer = ironpdf.ChromePdfRenderer()
pdf = renderer.RenderHtmlAsPdf("<h1>Hello World</h1><p>This PDF is created using IronPDF for Python</p>")
# Export to a file or stream
pdf.SaveAs("output.pdf")
# Advanced Example with HTML Assets
# Load external html assets Images, CSS, and JavaScript.
# An optional BasePath 'C:\site\assets\' is set as the file location to load assets from
myAdvancedPdf = renderer.RenderHtmlAsPdf("<img src='icons/iron.png'>", "C:\\site\\assets")
myAdvancedPdf.SaveAs("html-with-assets.pdf")import ironpdf
# Set IronPDF license key to unlock full features
ironpdf.License.LicenseKey = "YOUR-LICENSE-KEY-HERE"
# Create a PDF from an HTML string using Python
renderer = ironpdf.ChromePdfRenderer()
pdf = renderer.RenderHtmlAsPdf("<h1>Hello World</h1><p>This PDF is created using IronPDF for Python</p>")
# Export to a file or stream
pdf.SaveAs("output.pdf")
# Advanced Example with HTML Assets
# Load external html assets Images, CSS, and JavaScript.
# An optional BasePath 'C:\site\assets\' is set as the file location to load assets from
myAdvancedPdf = renderer.RenderHtmlAsPdf("<img src='icons/iron.png'>", "C:\\site\\assets")
myAdvancedPdf.SaveAs("html-with-assets.pdf")No código acima, primeiro aplicamos a chave de licença para utilizar todo o potencial do IronPDF. Você também pode usá-lo sem uma chave de licença, mas marcas d'água aparecerão nos arquivos PDF criados. Em seguida, criamos dois documentos PDF, o primeiro usando uma string HTML como conteúdo e o segundo usando recursos. O resultado é o seguinte:
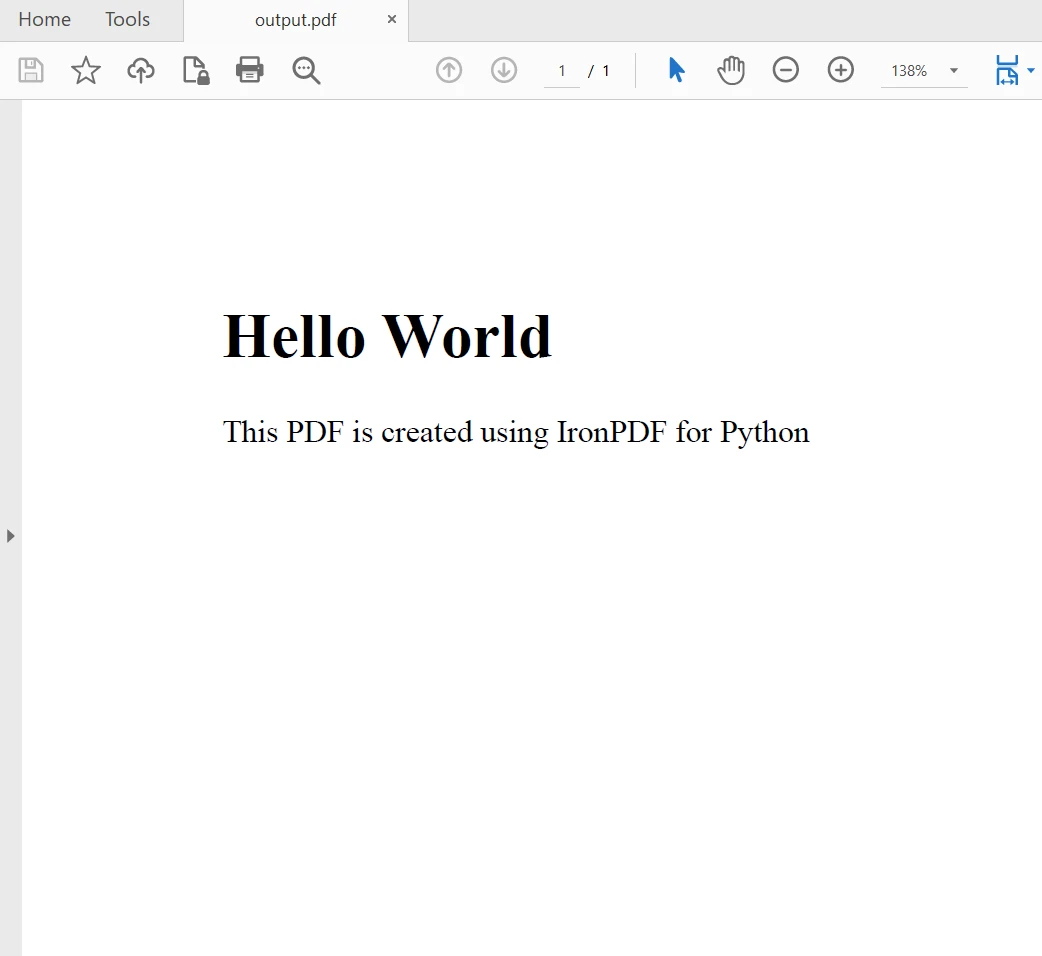
5. Unir arquivos PDF
5.1. Usando PyPDF
O PyPDF permite mesclar várias páginas/documentos em um único PDF, anexando páginas de um PDF a outro. Adicione os caminhos de entrada de todos os arquivos PDF na lista e use o método append para mesclar e gerar um único arquivo.
from pypdf import PdfWriter
merger = PdfWriter()
for pdf in ["file1.pdf", "file2.pdf", "file3.pdf"]:
merger.append(pdf)
merger.write("merged-pdf.pdf")
merger.close()from pypdf import PdfWriter
merger = PdfWriter()
for pdf in ["file1.pdf", "file2.pdf", "file3.pdf"]:
merger.append(pdf)
merger.write("merged-pdf.pdf")
merger.close()5.2. Usando o IronPDF
O IronPDF também oferece recursos semelhantes para mesclar documentos em um só, facilitando a consolidação de conteúdo de diferentes fontes de PDF.
import ironpdf
ironpdf.License.LicenseKey = "YOUR-LICENSE-KEY-HERE"
html_a = """<p> [PDF_A] </p>
<p> [PDF_A] 1st Page </p>
<div style='page-break-after: always;'></div>
<p> [PDF_A] 2nd Page</p>"""
html_b = """<p> [PDF_B] </p>
<p> [PDF_B] 1st Page </p>
<div style='page-break-after: always;'></div>
<p> [PDF_B] 2nd Page</p>"""
renderer = ironpdf.ChromePdfRenderer()
pdfdoc_a = renderer.RenderHtmlAsPdf(html_a)
pdfdoc_b = renderer.RenderHtmlAsPdf(html_b)
merged = ironpdf.PdfDocument.Merge([pdfdoc_a, pdfdoc_b])
merged.SaveAs("Merged.pdf")import ironpdf
ironpdf.License.LicenseKey = "YOUR-LICENSE-KEY-HERE"
html_a = """<p> [PDF_A] </p>
<p> [PDF_A] 1st Page </p>
<div style='page-break-after: always;'></div>
<p> [PDF_A] 2nd Page</p>"""
html_b = """<p> [PDF_B] </p>
<p> [PDF_B] 1st Page </p>
<div style='page-break-after: always;'></div>
<p> [PDF_B] 2nd Page</p>"""
renderer = ironpdf.ChromePdfRenderer()
pdfdoc_a = renderer.RenderHtmlAsPdf(html_a)
pdfdoc_b = renderer.RenderHtmlAsPdf(html_b)
merged = ironpdf.PdfDocument.Merge([pdfdoc_a, pdfdoc_b])
merged.SaveAs("Merged.pdf")6. Dividir arquivos PDF
6.1. Utilizando PyPDF
PyPDF é uma biblioteca Python capaz de dividir um único PDF em vários PDFs separados, cada um contendo uma ou mais páginas PDF.
from pypdf import PdfReader, PdfWriter
# Open the PDF file
pdf_file = open('input.pdf', 'rb')
# Create a PdfFileReader object
pdf_reader = PdfReader(pdf_file)
# Split each page into separate PDFs
for page_num in range(len(pdf_reader.pages)):
pdf_writer = PdfWriter()
pdf_writer.add_page(pdf_reader.pages[page_num])
output_filename = f'page_{page_num + 1}_pypdf.pdf'
with open(output_filename, 'wb') as output_file:
pdf_writer.write(output_file)
# Close the PDF file
pdf_file.close()from pypdf import PdfReader, PdfWriter
# Open the PDF file
pdf_file = open('input.pdf', 'rb')
# Create a PdfFileReader object
pdf_reader = PdfReader(pdf_file)
# Split each page into separate PDFs
for page_num in range(len(pdf_reader.pages)):
pdf_writer = PdfWriter()
pdf_writer.add_page(pdf_reader.pages[page_num])
output_filename = f'page_{page_num + 1}_pypdf.pdf'
with open(output_filename, 'wb') as output_file:
pdf_writer.write(output_file)
# Close the PDF file
pdf_file.close()O código acima divide o documento PDF de 28 páginas em páginas individuais e as salva como 28 novos arquivos PDF.
6.2. Usando o IronPDF
O IronPDF também oferece recursos semelhantes para dividir PDFs, permitindo que os usuários dividam um único PDF em vários arquivos PDF, cada um contendo uma única página. Permite extrair uma página específica de um PDF com várias páginas. O código a seguir ajuda a dividir documentos em vários arquivos:
import ironpdf
ironpdf.License.LicenseKey = "YOUR-LICENSE-KEY-HERE"
html = """<p> Hello Iron </p>
<p> This is 1st Page </p>
<div style='page-break-after: always;'></div>
<p> This is 2nd Page</p>
<div style='page-break-after: always;'></div>
<p> This is 3rd Page</p>"""
renderer = ironpdf.ChromePdfRenderer()
pdf = renderer.RenderHtmlAsPdf(html)
# take the first page
page1doc = pdf.CopyPage(0)
page1doc.SaveAs("Split1.pdf")
# take the pages 2 & 3
page23doc = pdf.CopyPages(1, 2)
page23doc.SaveAs("Split2.pdf")import ironpdf
ironpdf.License.LicenseKey = "YOUR-LICENSE-KEY-HERE"
html = """<p> Hello Iron </p>
<p> This is 1st Page </p>
<div style='page-break-after: always;'></div>
<p> This is 2nd Page</p>
<div style='page-break-after: always;'></div>
<p> This is 3rd Page</p>"""
renderer = ironpdf.ChromePdfRenderer()
pdf = renderer.RenderHtmlAsPdf(html)
# take the first page
page1doc = pdf.CopyPage(0)
page1doc.SaveAs("Split1.pdf")
# take the pages 2 & 3
page23doc = pdf.CopyPages(1, 2)
page23doc.SaveAs("Split2.pdf")Para obter informações mais detalhadas sobre o IronPDF , incluindo leitura de arquivos PDF, rotação de páginas, recorte de páginas, definição de senhas de proprietário/usuário e outras opções de segurança, visite esta página de exemplos de código IronPDF for Python .
7. Extraindo texto de arquivos PDF
7.1. Usando PyPDF
PyPDF oferece um método simples para extrair texto de PDFs. Ele oferece a classe PdfReader, que permite aos usuários ler o conteúdo de texto do PDF.
from pypdf import PdfReader
reader = PdfReader("input.pdf")
page = reader.pages[0]
print(page.extract_text())from pypdf import PdfReader
reader = PdfReader("input.pdf")
page = reader.pages[0]
print(page.extract_text())7.2. Usando o IronPDF
O IronPDF também é compatível com a extração de texto de PDFs usando a classe PdfDocument. Ele fornece um método chamado ExtractAllText para obter o conteúdo de texto do PDF. No entanto, a versão gratuita do IronPDF extrai apenas alguns caracteres do documento PDF. Para extrair o texto completo de PDFs, é necessário adquirir uma licença do IronPDF . Segue um exemplo de código para extrair conteúdo de arquivos PDF:
import ironpdf
ironpdf.License.LicenseKey = "YOUR-LICENSE-KEY-HERE"
# Load existing PDF document
pdf = ironpdf.PdfDocument.FromFile("input.pdf")
# Extract text from PDF document
all_text = pdf.ExtractAllText()
print(all_text)import ironpdf
ironpdf.License.LicenseKey = "YOUR-LICENSE-KEY-HERE"
# Load existing PDF document
pdf = ironpdf.PdfDocument.FromFile("input.pdf")
# Extract text from PDF document
all_text = pdf.ExtractAllText()
print(all_text)Para saber mais sobre como extrair texto, consulte este exemplo de PDF "Texto for Python" .
8. Licenciamento
PyPDF
O PyPDF é distribuído sob a Licença MIT, uma licença de software de código aberto conhecida por seus termos permissivos. A licença MIT permite que os usuários usem, modifiquem, distribuam e sublicenciem a biblioteca PyPDF livremente, sem quaisquer restrições. Os usuários não são obrigados a divulgar o código-fonte de seus aplicativos que utilizam PyPDF, tornando-o adequado tanto para projetos pessoais quanto comerciais.
O texto completo da Licença MIT geralmente está incluído no código-fonte do PyPDF, e os usuários podem encontrá-lo no arquivo "LICENSE" dentro da distribuição da biblioteca. Além disso, o repositório PyPDF no GitHub ( GitHub ) serve como a principal fonte para acessar a versão mais recente da biblioteca e suas respectivas informações de licenciamento.
IronPDF
IronPDF é uma biblioteca comercial e não é de código aberto. É desenvolvido e distribuído pela Iron Software. A utilização do IronPDF requer uma licença válida da Iron Software. Existem diferentes tipos de licenças disponíveis, incluindo versões de teste para fins de avaliação e licenças pagas para uso comercial.
Como o IronPDF é um produto comercial, ele oferece recursos adicionais e suporte técnico em comparação com alternativas de código aberto. Para obter uma licença do IronPDF, os usuários podem visitar o site oficial para explorar as opções de licenciamento disponíveis, preços e detalhes de suporte. O pacote Lite parte da licença NVIDIA_64_LICENSE e é uma licença perpétua.
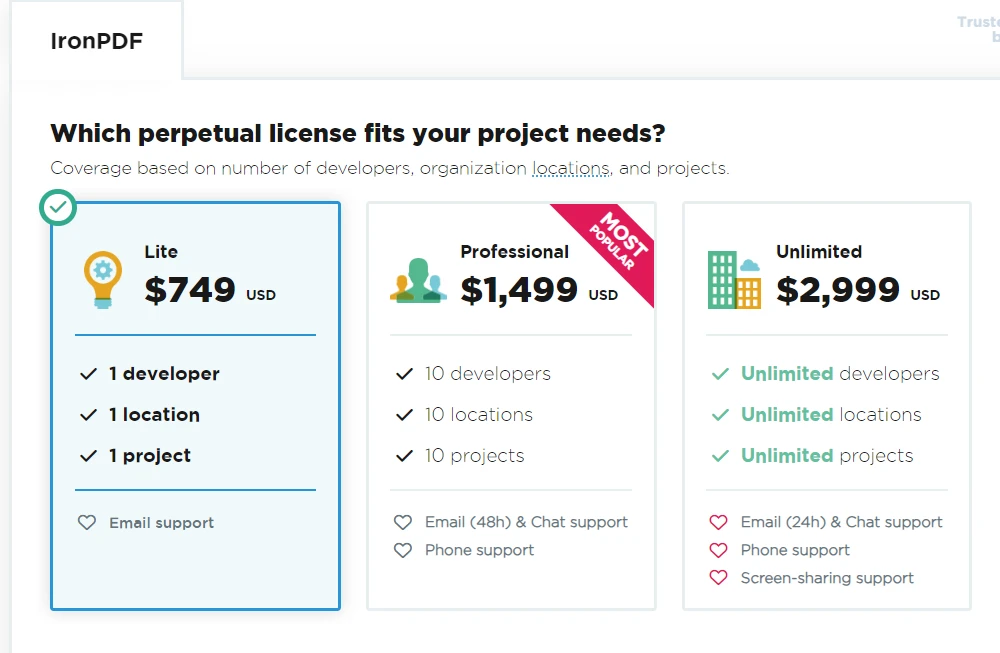
9. Conclusão
Resumo
PyPDF é uma biblioteca Python poderosa e fácil de usar para trabalhar com arquivos PDF. Suas funcionalidades para leitura, escrita, mesclagem e divisão de PDFs fazem dele uma ferramenta essencial para tarefas de manipulação de PDFs. Seja para extrair texto de um PDF, criar novos PDFs do zero ou mesclar e dividir documentos existentes, o PyPDF oferece uma solução confiável e eficiente. Ao aproveitar os recursos do PyPDF, os desenvolvedores Python podem otimizar seus fluxos de trabalho relacionados a PDFs e aumentar sua produtividade.
IronPDF é uma biblioteca abrangente e eficiente para manipulação de PDFs em Python, que oferece uma ampla gama de recursos para leitura, criação, mesclagem e divisão de arquivos PDF. Seja para gerar relatórios PDF dinâmicos, extrair informações de documentos PDF existentes ou mesclar vários documentos, o IronPDF oferece uma solução confiável e fácil de usar. Ao aproveitar os recursos do IronPDF, os desenvolvedores Python podem otimizar seus fluxos de trabalho relacionados a PDFs e aumentar sua produtividade.
Em termos gerais, o PyPDF é uma biblioteca leve e fácil de usar, adequada para operações básicas com PDFs. É uma boa opção para projetos com requisitos simples de PDF. Por outro lado, o IronPDF oferece uma API mais abrangente e um desempenho robusto, tornando-o ideal para projetos que exigem recursos avançados de processamento de PDF, gerenciamento de arquivos PDF grandes e execução de tarefas complexas.
Conclusão
Ambas as bibliotecas possuem bons recursos de codificação para tarefas comuns em PDF. PyPDF é adequado para operações simples e implementações rápidas, enquanto o IronPDF oferece uma API mais extensa e versátil para lidar com tarefas complexas relacionadas a PDFs.
Em termos de desempenho, o IronPDF provavelmente superará o PyPDF, especialmente ao lidar com arquivos PDF volumosos ou tarefas que exigem manipulações complexas de PDF.
A escolha entre as duas bibliotecas depende das necessidades específicas do projeto e da complexidade das tarefas relacionadas a PDFs.
O IronPDF também está disponível para um teste gratuito , permitindo que você experimente todas as suas funcionalidades no modo comercial. Faça o download do IronPDF for Python aqui .
Perguntas frequentes
Quais são as principais diferenças entre PyPDF e IronPDF para manipulação de PDFs em Python?
PyPDF é uma biblioteca Python pura que oferece recursos básicos de manipulação de PDFs, como leitura, escrita e mesclagem de PDFs. Em contraste, o IronPDF é construído sobre a biblioteca .NET do IronPDF e fornece recursos avançados, como conversão de HTML para PDF, manipulação de formulários e operações de alto desempenho para tarefas complexas com PDFs.
Como posso converter HTML para PDF em Python?
Você pode converter HTML para PDF em Python usando o IronPDF. Ele fornece métodos como RenderHtmlAsPdf para converter strings HTML e RenderHtmlFileAsPdf para converter arquivos HTML em PDFs.
Quais são os requisitos de instalação para usar o IronPDF em um projeto Python?
Para usar o IronPDF com Python, você precisa ter o ambiente de execução .NET 6.0 instalado em seu sistema. O IronPDF pode ser instalado via pip usando o comando pip install ironpdf .
É possível extrair texto e imagens de PDFs usando PyPDF?
Sim, o PyPDF permite a extração de texto e imagens de PDFs. Ele foi projetado para tarefas básicas de manipulação de PDFs, como extração de texto, mesclagem e divisão de PDFs.
Quais são as vantagens de usar o IronPDF para operações complexas em PDFs?
O IronPDF oferece desempenho robusto e recursos abrangentes para operações complexas em PDF, incluindo conversão de HTML para PDF, manipulação de formulários, manipulação avançada de texto e imagem e alto desempenho com arquivos grandes.
Posso mesclar e dividir arquivos PDF usando o IronPDF?
Sim, o IronPDF oferece funcionalidades para mesclar e dividir arquivos PDF de forma eficiente, proporcionando uma solução completa para gerenciar operações complexas de PDF em aplicações Python.
Quais são os casos de uso mais comuns para PDFs em diversos setores?
Os PDFs são comumente usados para compartilhar documentos como relatórios, faturas, formulários e livros eletrônicos em diversos setores devido à sua aparência consistente em diferentes plataformas e dispositivos.
Quais são as opções de licenciamento para o IronPDF?
O IronPDF é um produto comercial que requer uma licença válida da Iron Software. Diversas opções de licenciamento estão disponíveis, incluindo versões de avaliação, para atender às diferentes necessidades de cada projeto.