Python용 IronPDF와 PyPDF 비교
PDF(Portable Document Format) 는 다양한 플랫폼에서 문서 정보의 레이아웃과 서식을 유지하는 데 널리 사용되는 파일 형식입니다. 이러한 파일 형식은 어떤 기기나 운영 체제를 사용하더라도 일관된 모양을 유지할 수 있기 때문에 다양한 산업 분야에서 매우 인기가 높습니다. PDF는 보고서, 송장, 양식, 전자책, 사용자 지정 데이터 및 기타 중요한 문서를 공유하는 데 일반적으로 사용됩니다.
Python에서 PDF 파일을 다루는 것은 많은 프로젝트에서 매우 중요한 부분이 되었습니다. Python은 PDF 파일 조작을 간소화하는 여러 라이브러리를 제공하여 정보 추출, 새 문서 생성, 기존 문서 병합 또는 분할, 기타 PDF 관련 작업 수행을 용이하게 합니다.
이 글에서는 PDF 파일을 조작하도록 설계된 두 가지 유명한 Python 라이브러리인 PyPDF 와 IronPDF 종합적으로 비교해 보겠습니다. 본 논문에서는 두 라이브러리의 기능과 성능을 평가하여 개발자들이 특정 소프트웨어 애플리케이션 요구 사항에 가장 적합한 라이브러리를 선택하는 데 도움이 되는 유용한 정보를 제공하고자 합니다.
이러한 라이브러리는 PDF 작업을 간소화하는 강력한 도구를 제공하여 개발자가 Python 애플리케이션 내에서 PDF 문서를 효율적으로 처리할 수 있도록 지원합니다. 그럼 이제 각 라이브러리의 장점을 자세히 비교하고 PDF 관련 작업을 더욱 효율적으로 수행할 수 있는 방법을 알아보겠습니다.
PyPDF - 순수 Python PDF 라이브러리
PyPDF 는 PDF 파일을 읽고, 쓰고, 암호 해독하고, PDF 문서를 조작하는 기본적인 기능을 제공하는 순수 Python PDF 라이브러리입니다. 이 도구를 사용하면 개발자는 PDF에서 텍스트와 이미지를 추출하고, 여러 PDF 파일을 병합하고, 큰 PDF 파일을 더 작은 파일로 분할하는 등의 작업을 수행할 수 있습니다. PyPDF는 단순하고 사용하기 쉬운 것으로 유명하며, 간단한 PDF 작업에 적합한 선택입니다.
이 프로그램은 PDF 문서 작업을 위한 포괄적인 기능 세트를 제공하므로 다양한 PDF 관련 작업에 탁월한 선택입니다.
특징
PyPDF는 다음과 같은 기능을 제공하는 Python PDF 라이브러리입니다.
- PDF 파일 읽기: 기존 PDF 파일에서 텍스트, 이미지 및 메타데이터를 추출합니다.
- PDF 파일 작성: 새 PDF 파일을 처음부터 생성하거나 기존 PDF 파일에 텍스트와 이미지를 추가하여 수정할 수 있습니다.
- PDF 파일 병합: 여러 PDF 파일을 하나의 문서로 결합합니다.
- PDF 파일 분할: PDF 파일을 각각 하나 이상의 페이지를 포함하는 여러 개의 파일로 나눕니다.
- 페이지 회전 및 오버레이: PDF 파일의 페이지를 회전하고 워터마크 또는 오버레이를 추가할 수 있습니다.
- PDF 파일 암호화 및 복호화: PDF 파일을 암호화하고 복호화하여 보안을 강화하세요.
- 텍스트 추출: PDF 파일에서 일반 텍스트를 추출하거나 페이지 내 특정 영역에서 텍스트를 추출합니다.
- 이미지 추출: PDF 파일에 포함된 이미지를 추출합니다.
- PDF 파일 조작: PDF 파일 내 페이지를 복사, 삭제 또는 재배열할 수 있습니다.
- 양식 필드 채우기: PDF의 양식 필드를 프로그램 방식으로 채웁니다.
IronPDF - Python PDF 라이브러리
IronPDF 는 IronPDF의 .NET 라이브러리를 기반으로 구축된 Python용 종합 PDF 조작 라이브러리입니다. 이 서비스는 HTML을 PDF로 변환하고, PDF 주석 및 양식 필드를 처리하며, 복잡한 PDF 작업을 효율적으로 수행하는 등 고급 기능을 갖춘 강력한 API를 제공합니다. IronPDF 는 강력한 PDF 처리, 성능 및 광범위한 기능 지원이 필요한 프로젝트에 적합합니다.
IronPDF 는 PDF 처리 작업을 원활하게 처리할 수 있는 Python PDF 라이브러리입니다. 이 라이브러리는 Python 개발자에게 안정적이고 기능이 풍부한 PDF 조작 솔루션을 제공합니다. IronPDF 사용하면 PDF 내 여러 페이지의 콘텐츠를 손쉽게 생성, 수정 및 추출할 수 있으므로 다양한 PDF 관련 응용 분야에 탁월한 선택입니다.
특징
IronPDF 의 주요 기능은 다음과 같습니다.
- PDF 생성: IronPDF 사용하면 개발자는 PDF 문서를 처음부터 생성하거나 HTML 콘텐츠를 PDF 형식으로 변환할 수 있으므로 동적이고 시각적으로 매력적인 보고서와 문서를 쉽게 생성할 수 있습니다.
- 고급 텍스트 및 이미지 조작: 개발자는 PDF 파일 내의 텍스트와 이미지를 쉽게 조작할 수 있습니다. IronPDF 텍스트를 추가, 편집 및 서식 지정할 수 있을 뿐만 아니라 이미지를 삽입, 크기 조정 및 정확하게 배치할 수 있는 기능을 제공합니다.
- PDF 병합 및 분할: IronPDF 여러 PDF 파일을 하나의 문서로 병합하거나 PDF 파일을 여러 개의 개별 파일로 분할할 수 있어 PDF 콘텐츠 관리에 유연성을 제공합니다.
- PDF 양식 지원: IronPDF 사용하면 개발자는 PDF 양식을 활용하여 양식 필드를 채우고, 양식 데이터를 추출하고, 대화형 PDF를 생성할 수 있습니다.
- PDF 보안 및 암호화: IronPDF PDF 문서에 암호 보호 및 암호화 기능을 추가하여 데이터 보안 및 기밀성을 보장합니다.
- PDF 주석: 개발자는 댓글, 강조 표시, 책갈피와 같은 주석을 추가하여 PDF 내에서 공동 작업 및 가독성을 향상시킬 수 있습니다.
- 머리글 및 바닥글: IronPDF 사용하면 PDF 페이지에 머리글과 바닥글을 추가하여 문서에 브랜드 이미지와 맥락을 부여할 수 있습니다.
- 바코드 생성: IronPDF HTML을 사용하여 다양한 유형의 바코드와 QR 코드를 PDF 문서에 직접 생성할 수 있도록 지원합니다.
- 고성능: IronPDF 는 .NET 라이브러리를 기반으로 구축되어 대용량 PDF 파일 및 복잡한 작업을 처리하는 데 있어 뛰어난 성능과 효율성을 제공합니다.
기사 내용은 다음과 같습니다.
- Python 프로젝트 생성
- PyPDF 설치
- IronPDF 설치
- PDF 문서 생성
- PDF 파일 병합
- PDF 파일 분할
- PDF 파일에서 텍스트 추출
- 라이선스
- 결론
1. Python 프로젝트 생성
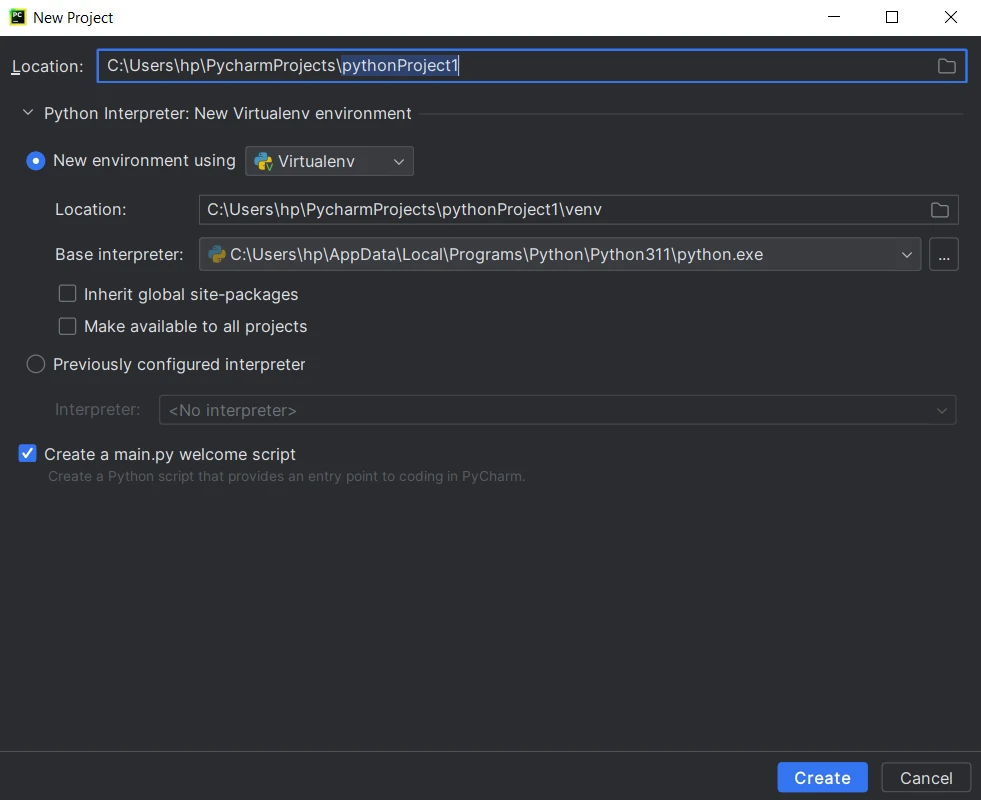
Python 프로젝트에 통합 개발 환경 (IDE)을 사용하면 생산성을 크게 향상시킬 수 있습니다. 인기 있는 선택지 중에서 저는 PyCharm을 사용하려고 합니다. PyCharm은 지능형 코드 자동 완성, 강력한 디버깅 기능, 그리고 버전 관리 시스템과의 원활한 통합이 뛰어나기 때문입니다. PyCharm 이 설치되어 있지 않다면 JetBrains 웹사이트에서 다운로드하거나 VS Code와 같은 Python 프로그래밍용 IDE/텍스트 편집기를 사용할 수 있습니다.
PyCharm에서 Python 프로젝트를 생성하려면 다음 단계를 따르세요.
- PyCharm을 실행하고 PyCharm 시작 화면에서 " 새 프로젝트 만들기 "를 클릭하거나 메뉴에서 파일 > 새 프로젝트를 선택합니다.
- Python 인터프리터를 선택하세요. 아직 통역사를 설정하지 않았다면, 톱니바퀴 아이콘을 클릭하고 새 통역사를 설정하세요.
- 프로젝트 위치와 템플릿을 선택합니다.
- 프로젝트 이름과 설정을 입력한 다음 [생성]을 클릭합니다.
- Python 프로젝트를 코딩하고 실행하고 디버깅해 보세요.
2. PyPDF 설치
PyPDF는 순수 Python 라이브러리로, 여러 가지 방법으로 설치할 수 있습니다. 명령 프롬프트와 PyCharm을 모두 사용하여 설치할 수 있습니다.
2.1. 명령 프롬프트 사용
- 컴퓨터에서 명령 프롬프트 또는 터미널을 엽니다.
PyPDF를 설치하려면 다음 pip 명령어를 사용하십시오.
pip install pypdfpip install pypdfSHELL- PyPDF 설치가 완료될 때까지 기다리세요. PyPDF가 설치되었다는 성공 메시지가 표시될 것입니다.
PyCharm 터미널에 PyPDF를 설치하는 데에도 동일한 절차를 사용할 수 있습니다.
참고: Python을 시스템 PATH 환경 변수에 추가해야 합니다.
2.2. PyCharm 사용하기
- PyCharm IDE를 엽니다.
- 새 Python 프로젝트를 생성하거나 기존 프로젝트를 엽니다.
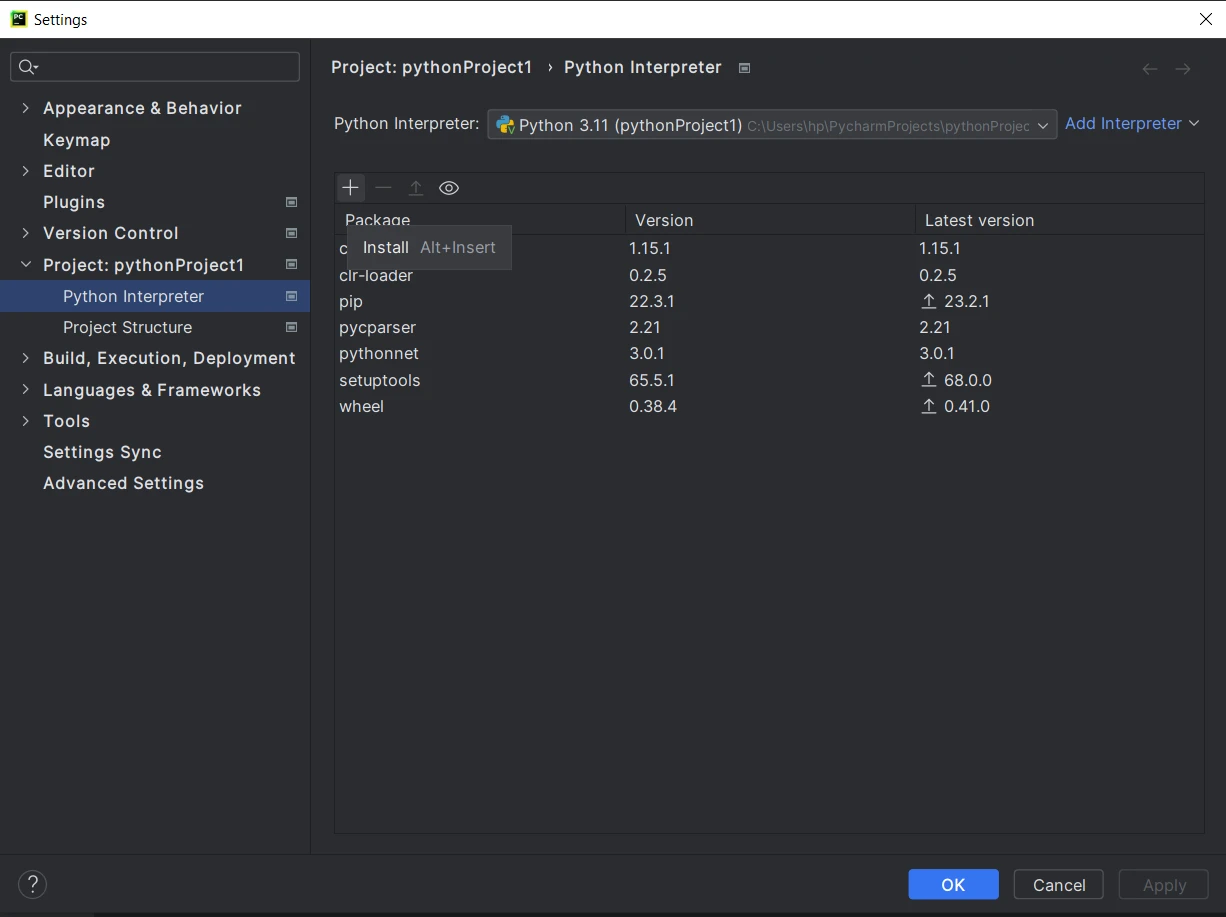
- 프로젝트에 들어가면 상단 메뉴에서 [파일]을 클릭하고 [설정]을 선택합니다.
- 설정 창에서 " 프로젝트:"로 이동합니다.
"그리고 ' Python 인터프리터 '를 클릭하세요." - Python 인터프리터 창에서 " + " 아이콘을 클릭하여 새 패키지를 추가합니다.
- " 사용 가능한 패키지 " 창에서 " PyPDF "를 검색합니다.
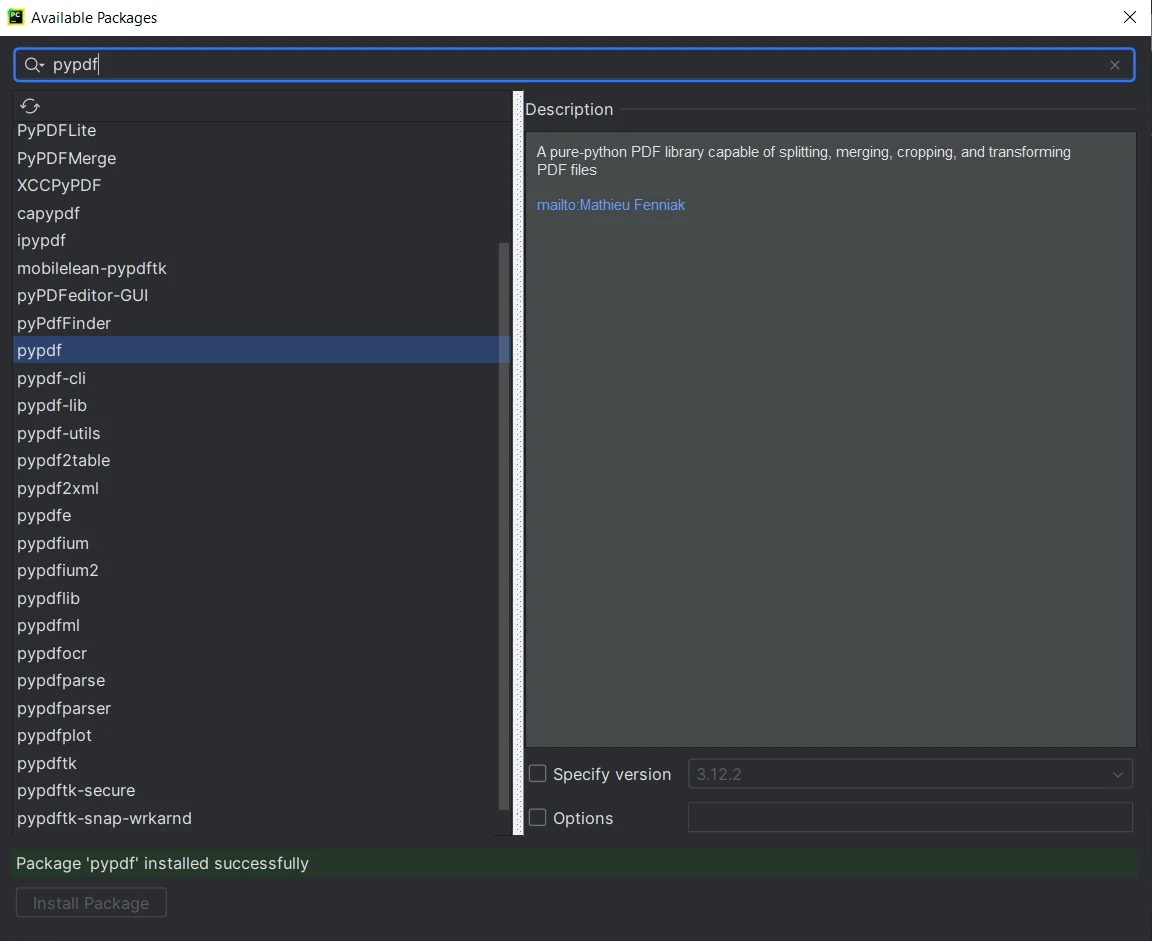
- 목록에서 " PyPDF "를 선택하고 " Install-Package " 버튼을 클릭합니다.
- PyCharm이 PyPDF를 다운로드하고 설치할 때까지 기다립니다.
3. IronPDF 설치
필수 조건
IronPDF for Python은 강력한 .NET 6.0 기술을 기반으로 합니다. 따라서 Python용 IronPDF 효과적으로 사용하려면 시스템에 .NET 6.0 런타임이 설치되어 있어야 합니다. Linux 및 Mac 사용자는 Microsoft 공식 웹사이트에서 .NET 다운로드하여 설치해야 할 수 있습니다.https://dotnet.microsoft.com/en-us/download/dotnet/6.0 이 Python 패키지를 사용하기 전에 다음 사항을 확인하십시오. .NET 6.0 런타임이 설치되어 있어야 PDF 처리 작업에 IronPDF for Python을 사용할 때 원활한 통합과 최적의 성능을 구현할 수 있습니다.
3.1. 명령 프롬프트 사용
- 컴퓨터에서 명령 프롬프트 또는 터미널을 엽니다.
IronPDF 설치하려면 다음 pip 명령어를 사용하십시오.
pip install ironpdf
- 설치가 완료될 때까지 기다리세요. IronPDF 설치되었다는 성공 메시지가 표시될 것입니다.
3.2. PyCharm 사용하기
- 컴퓨터에서 PyCharm IDE를 엽니다.
- 새 Python 프로젝트를 생성하거나 기존 프로젝트를 엽니다.
- 프로젝트에 들어가면 상단 메뉴에서 " 파일 "을 클릭하고 " 설정 "을 선택합니다.
- 설정 창에서 " 프로젝트:"로 이동합니다.
"를 클릭하고 "Python Interpreter"를 선택하세요. - Python 인터프리터 창에서 " + " 아이콘을 클릭하여 새 패키지를 추가합니다.
- "사용 가능한 패키지" 창에서 "IronPDF"를 검색합니다.
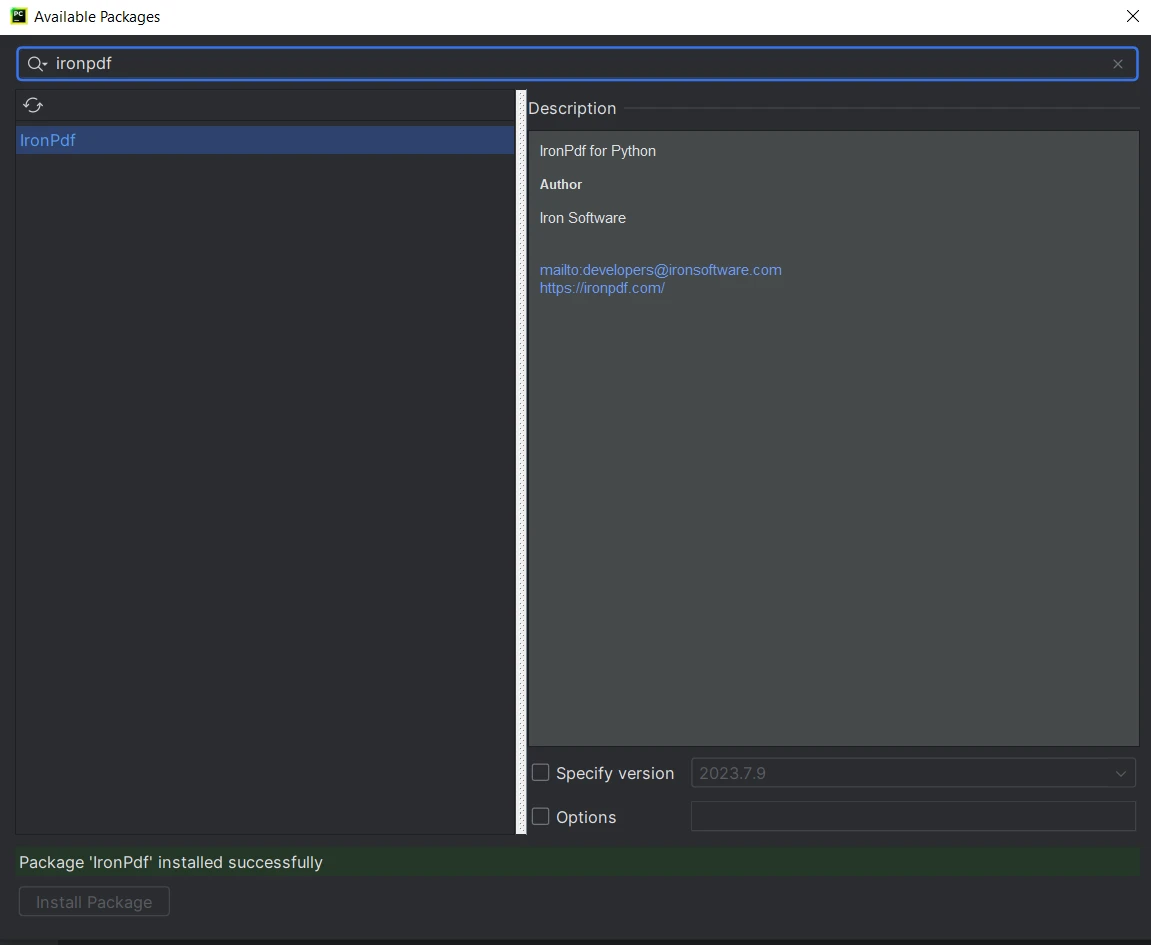
- 목록에서 "IronPDF"를 선택하고 "Install-Package" 버튼을 클릭합니다.
- IronPDF 가 다운로드 및 설치될 때까지 기다리세요. IronPDF 설치되었다는 성공 메시지가 표시됩니다.
이제 두 라이브러리 모두 설치되었고 사용할 준비가 되었습니다. 이제 본격적인 비교로 넘어가 보겠습니다.
4. PDF 문서 생성
4.1. PyPDF 사용하기
PyPDF는 새로운 PDF 파일을 생성하는 기본적인 기능을 제공합니다. 하지만 HTML 콘텐츠를 PDF로 직접 변환하는 내장 기능은 없습니다. PyPDF를 사용하여 새 PDF를 만들려면 기존 PDF에 콘텐츠를 추가하거나 새 빈 PDF를 만든 다음 텍스트나 이미지를 추가해야 합니다. 다음 코드는 PDF 파일을 생성하는 데 도움이 됩니다.
from pypdf import PdfWriter, PdfReader
# Create a new PDF file
pdf_output = PdfWriter()
# Add a new blank page
page = pdf_output.add_blank_page(width=610, height=842) # Width and height are in points (1 inch = 72 points)
# Read content from an existing PDF
with open('input.pdf', 'rb') as existing_pdf:
existing_pdf_reader = PdfReader(existing_pdf)
# Merge content from the first page of the existing PDF
page.merge_page(existing_pdf_reader.pages[0])
# Save the new PDF to a file
with open('output.pdf', 'wb') as output_file:
pdf_output.write(output_file)from pypdf import PdfWriter, PdfReader
# Create a new PDF file
pdf_output = PdfWriter()
# Add a new blank page
page = pdf_output.add_blank_page(width=610, height=842) # Width and height are in points (1 inch = 72 points)
# Read content from an existing PDF
with open('input.pdf', 'rb') as existing_pdf:
existing_pdf_reader = PdfReader(existing_pdf)
# Merge content from the first page of the existing PDF
page.merge_page(existing_pdf_reader.pages[0])
# Save the new PDF to a file
with open('output.pdf', 'wb') as output_file:
pdf_output.write(output_file)입력 파일은 28페이지로 구성되어 있으며, 새 PDF 파일에는 첫 번째 페이지만 추가됩니다. 출력 결과는 다음과 같습니다.
4.2. IronPDF 사용
IronPDF HTML 콘텐츠에서 직접 새 PDF 파일을 생성할 수 있는 고급 기능을 제공합니다. 이를 통해 추가적인 단계 없이 동적 보고서 및 문서를 편리하게 생성할 수 있습니다. 다음은 예시 코드입니다.
import ironpdf
# Set IronPDF license key to unlock full features
ironpdf.License.LicenseKey = "YOUR-LICENSE-KEY-HERE"
# Create a PDF from an HTML string using Python
renderer = ironpdf.ChromePdfRenderer()
pdf = renderer.RenderHtmlAsPdf("<h1>Hello World</h1><p>This PDF is created using IronPDF for Python</p>")
# Export to a file or stream
pdf.SaveAs("output.pdf")
# Advanced Example with HTML Assets
# Load external html assets Images, CSS, and JavaScript.
# An optional BasePath 'C:\site\assets\' is set as the file location to load assets from
myAdvancedPdf = renderer.RenderHtmlAsPdf("<img src='icons/iron.png'>", "C:\\site\\assets")
myAdvancedPdf.SaveAs("html-with-assets.pdf")import ironpdf
# Set IronPDF license key to unlock full features
ironpdf.License.LicenseKey = "YOUR-LICENSE-KEY-HERE"
# Create a PDF from an HTML string using Python
renderer = ironpdf.ChromePdfRenderer()
pdf = renderer.RenderHtmlAsPdf("<h1>Hello World</h1><p>This PDF is created using IronPDF for Python</p>")
# Export to a file or stream
pdf.SaveAs("output.pdf")
# Advanced Example with HTML Assets
# Load external html assets Images, CSS, and JavaScript.
# An optional BasePath 'C:\site\assets\' is set as the file location to load assets from
myAdvancedPdf = renderer.RenderHtmlAsPdf("<img src='icons/iron.png'>", "C:\\site\\assets")
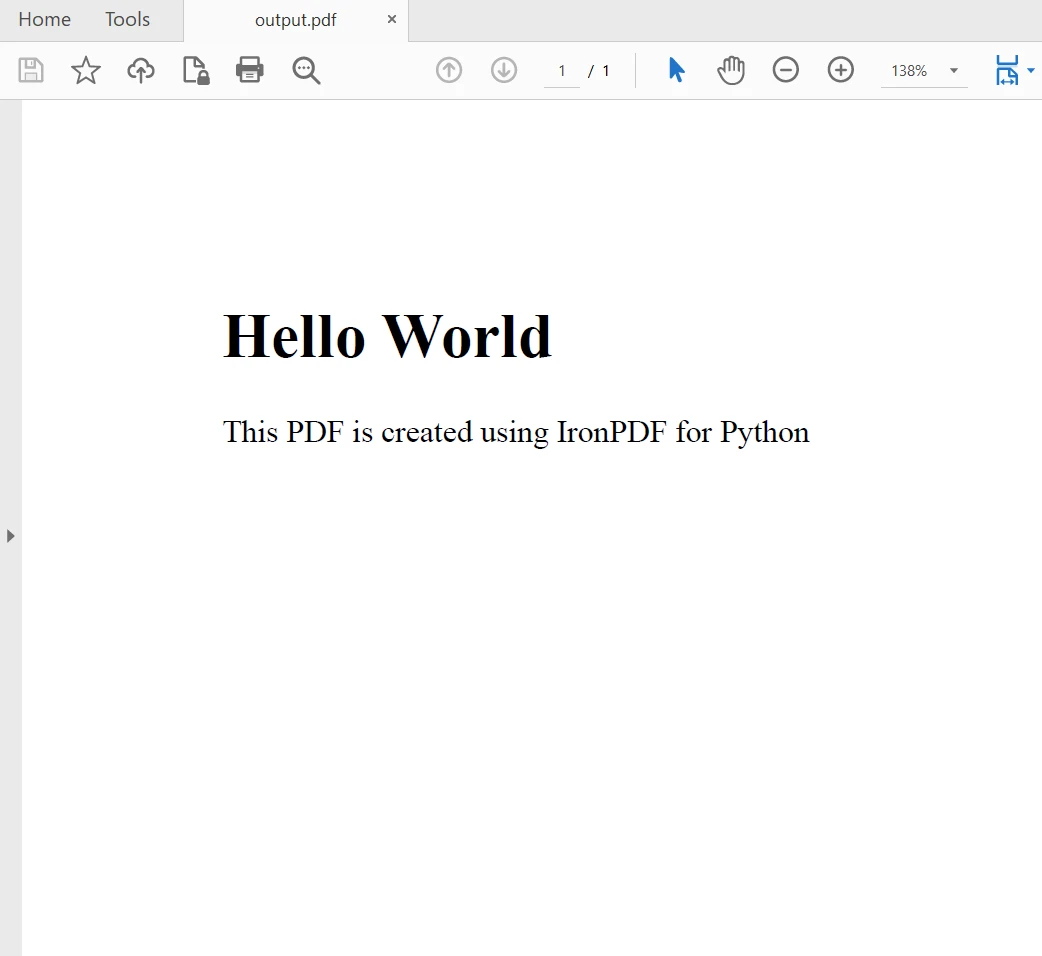
myAdvancedPdf.SaveAs("html-with-assets.pdf")위 코드에서는 먼저 라이선스 키를 적용하여 IronPDF의 모든 기능을 활용했습니다. 라이선스 키 없이도 사용할 수 있지만, 생성된 PDF 파일에 워터마크가 표시됩니다. 다음으로, 첫 번째 문서는 HTML 문자열을 콘텐츠로 사용하고 두 번째 문서는 에셋을 사용하여 두 개의 PDF 문서를 생성합니다. 출력 결과는 다음과 같습니다.
5. PDF 파일 병합
5.1. PyPDF 사용하기
PyPDF는 한 PDF 파일의 페이지를 다른 PDF 파일에 추가하여 여러 페이지/문서를 하나의 PDF 파일로 병합할 수 있도록 해줍니다. 목록에 있는 모든 PDF 파일의 입력 경로를 추가하고 append 메서드를 사용하여 병합하여 단일 파일을 생성합니다.
from pypdf import PdfWriter
merger = PdfWriter()
for pdf in ["file1.pdf", "file2.pdf", "file3.pdf"]:
merger.append(pdf)
merger.write("merged-pdf.pdf")
merger.close()from pypdf import PdfWriter
merger = PdfWriter()
for pdf in ["file1.pdf", "file2.pdf", "file3.pdf"]:
merger.append(pdf)
merger.write("merged-pdf.pdf")
merger.close()5.2. IronPDF 사용
IronPDF 여러 PDF 문서를 하나로 병합하는 유사한 기능도 제공하여 다양한 PDF 소스의 콘텐츠를 쉽게 통합할 수 있도록 합니다.
import ironpdf
ironpdf.License.LicenseKey = "YOUR-LICENSE-KEY-HERE"
html_a = """<p> [PDF_A] </p>
<p> [PDF_A] 1st Page </p>
<div style='page-break-after: always;'></div>
<p> [PDF_A] 2nd Page</p>"""
html_b = """<p> [PDF_B] </p>
<p> [PDF_B] 1st Page </p>
<div style='page-break-after: always;'></div>
<p> [PDF_B] 2nd Page</p>"""
renderer = ironpdf.ChromePdfRenderer()
pdfdoc_a = renderer.RenderHtmlAsPdf(html_a)
pdfdoc_b = renderer.RenderHtmlAsPdf(html_b)
merged = ironpdf.PdfDocument.Merge([pdfdoc_a, pdfdoc_b])
merged.SaveAs("Merged.pdf")import ironpdf
ironpdf.License.LicenseKey = "YOUR-LICENSE-KEY-HERE"
html_a = """<p> [PDF_A] </p>
<p> [PDF_A] 1st Page </p>
<div style='page-break-after: always;'></div>
<p> [PDF_A] 2nd Page</p>"""
html_b = """<p> [PDF_B] </p>
<p> [PDF_B] 1st Page </p>
<div style='page-break-after: always;'></div>
<p> [PDF_B] 2nd Page</p>"""
renderer = ironpdf.ChromePdfRenderer()
pdfdoc_a = renderer.RenderHtmlAsPdf(html_a)
pdfdoc_b = renderer.RenderHtmlAsPdf(html_b)
merged = ironpdf.PdfDocument.Merge([pdfdoc_a, pdfdoc_b])
merged.SaveAs("Merged.pdf")6. PDF 파일 분할
6.1. PyPDF 사용하기
PyPDF는 하나의 PDF 파일을 여러 개의 개별 PDF 파일로 분할할 수 있는 Python 라이브러리입니다. 각 개별 PDF 파일에는 하나 이상의 PDF 페이지가 포함될 수 있습니다.
from pypdf import PdfReader, PdfWriter
# Open the PDF file
pdf_file = open('input.pdf', 'rb')
# Create a PdfFileReader object
pdf_reader = PdfReader(pdf_file)
# Split each page into separate PDFs
for page_num in range(len(pdf_reader.pages)):
pdf_writer = PdfWriter()
pdf_writer.add_page(pdf_reader.pages[page_num])
output_filename = f'page_{page_num + 1}_pypdf.pdf'
with open(output_filename, 'wb') as output_file:
pdf_writer.write(output_file)
# Close the PDF file
pdf_file.close()from pypdf import PdfReader, PdfWriter
# Open the PDF file
pdf_file = open('input.pdf', 'rb')
# Create a PdfFileReader object
pdf_reader = PdfReader(pdf_file)
# Split each page into separate PDFs
for page_num in range(len(pdf_reader.pages)):
pdf_writer = PdfWriter()
pdf_writer.add_page(pdf_reader.pages[page_num])
output_filename = f'page_{page_num + 1}_pypdf.pdf'
with open(output_filename, 'wb') as output_file:
pdf_writer.write(output_file)
# Close the PDF file
pdf_file.close()위 코드는 28페이지짜리 PDF 문서를 개별 페이지로 분할하여 각각 28개의 새로운 PDF 파일로 저장합니다.
6.2. IronPDF 사용
IronPDF PDF를 분할하는 유사한 기능도 제공하여 사용자가 하나의 PDF 파일을 여러 개의 PDF 파일로 나눌 수 있도록 하며, 각 파일에는 하나의 PDF 페이지가 포함됩니다. 이 기능을 사용하면 여러 페이지로 구성된 PDF에서 특정 페이지만 분리할 수 있습니다. 다음 코드는 문서를 여러 파일로 분할하는 데 도움이 됩니다.
import ironpdf
ironpdf.License.LicenseKey = "YOUR-LICENSE-KEY-HERE"
html = """<p> Hello Iron </p>
<p> This is 1st Page </p>
<div style='page-break-after: always;'></div>
<p> This is 2nd Page</p>
<div style='page-break-after: always;'></div>
<p> This is 3rd Page</p>"""
renderer = ironpdf.ChromePdfRenderer()
pdf = renderer.RenderHtmlAsPdf(html)
# take the first page
page1doc = pdf.CopyPage(0)
page1doc.SaveAs("Split1.pdf")
# take the pages 2 & 3
page23doc = pdf.CopyPages(1, 2)
page23doc.SaveAs("Split2.pdf")import ironpdf
ironpdf.License.LicenseKey = "YOUR-LICENSE-KEY-HERE"
html = """<p> Hello Iron </p>
<p> This is 1st Page </p>
<div style='page-break-after: always;'></div>
<p> This is 2nd Page</p>
<div style='page-break-after: always;'></div>
<p> This is 3rd Page</p>"""
renderer = ironpdf.ChromePdfRenderer()
pdf = renderer.RenderHtmlAsPdf(html)
# take the first page
page1doc = pdf.CopyPage(0)
page1doc.SaveAs("Split1.pdf")
# take the pages 2 & 3
page23doc = pdf.CopyPages(1, 2)
page23doc.SaveAs("Split2.pdf")PDF 파일 읽기, PDF 페이지 회전, 페이지 자르기, 소유자/사용자 암호 설정 및 기타 보안 옵션에 대한 IronPDF 의 자세한 내용은 Python용 IronPDF 코드 예제 페이지를 참조하십시오.
7. PDF 파일에서 텍스트 추출
7.1. PyPDF 사용하기
PyPDF는 PDF에서 텍스트를 추출하는 간단한 방법을 제공합니다. 사용자가 PDF에서 텍스트 콘텐츠를 읽을 수 있는 PdfReader 클래스를 제공합니다.
from pypdf import PdfReader
reader = PdfReader("input.pdf")
page = reader.pages[0]
print(page.extract_text())from pypdf import PdfReader
reader = PdfReader("input.pdf")
page = reader.pages[0]
print(page.extract_text())7.2. IronPDF 사용
IronPDF는 또한 PdfDocument 클래스를 사용하여 PDF에서 텍스트를 추출하는 것을 지원합니다. PDF에서 텍스트 콘텐츠를 얻기 위해 ExtractAllText라는 메소드를 제공합니다. 하지만 IronPDF 의 무료 버전은 PDF 문서에서 몇 글자만 추출합니다. PDF에서 전체 텍스트를 추출하려면 IronPDF 라이선스가 필요합니다. 다음은 PDF 파일에서 콘텐츠를 추출하는 코드 예시입니다.
import ironpdf
ironpdf.License.LicenseKey = "YOUR-LICENSE-KEY-HERE"
# Load existing PDF document
pdf = ironpdf.PdfDocument.FromFile("input.pdf")
# Extract text from PDF document
all_text = pdf.ExtractAllText()
print(all_text)import ironpdf
ironpdf.License.LicenseKey = "YOUR-LICENSE-KEY-HERE"
# Load existing PDF document
pdf = ironpdf.PdfDocument.FromFile("input.pdf")
# Extract text from PDF document
all_text = pdf.ExtractAllText()
print(all_text)텍스트 추출에 대한 자세한 내용은 이 PDF 텍스트를 Python으로 변환하는 예제를 참조하세요.
8. 라이선스
PyPDF
PyPDF는 MIT 라이선스에 따라 배포됩니다. MIT 라이선스는 관대한 조건으로 알려진 오픈 소스 소프트웨어 라이선스입니다. MIT 라이선스는 사용자가 PyPDF 라이브러리를 어떠한 제한 없이 자유롭게 사용, 수정, 배포 및 서브라이선스할 수 있도록 허용합니다. PyPDF를 사용하는 애플리케이션의 소스 코드는 공개할 필요가 없으므로 개인 프로젝트와 상업 프로젝트 모두에 적합합니다.
MIT 라이선스의 전문은 일반적으로 PyPDF 소스 코드에 포함되어 있으며, 사용자는 라이브러리 배포판 내의 "LICENSE" 파일에서 확인할 수 있습니다. 또한 PyPDF GitHub 저장소( GitHub )는 라이브러리의 최신 버전과 관련 라이선스 정보에 접근할 수 있는 주요 소스입니다.
IronPDF
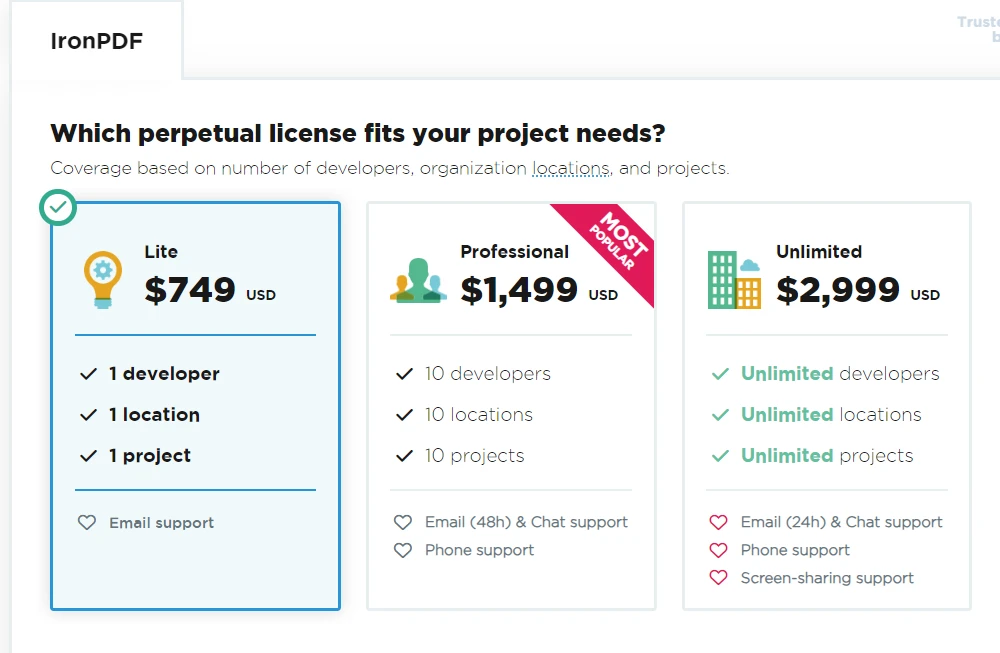
IronPDF 는 상용 라이브러리이며 오픈 소스가 아닙니다. 이 제품은 Iron Software 에서 개발 및 배포합니다. IronPDF 를 사용하려면 Iron Software 에서 발급한 유효한 라이선스가 필요합니다. 평가용 체험판과 상업적 용도를 위한 유료 라이선스를 포함하여 다양한 유형의 라이선스가 제공됩니다.
IronPDF 는 상용 제품이기 때문에 오픈 소스 대안에 비해 추가 기능과 기술 지원을 제공합니다. IronPDF 라이선스를 취득하려면 공식 웹사이트를 방문하여 사용 가능한 라이선스 옵션, 가격 및 지원 정보를 확인하십시오. Lite 패키지는 NVIDIA_64_LICENSE로 시작하며 영구 라이선스입니다.
9. 결론
요약
PyPDF 는 PDF 파일을 다루기 위한 강력하고 사용하기 쉬운 Python 라이브러리입니다. PDF 읽기, 쓰기, 병합 및 분할 기능을 갖춘 이 프로그램은 PDF 조작 작업에 필수적인 도구입니다. PDF에서 텍스트를 추출하거나, 새 PDF를 처음부터 만들거나, 기존 문서를 병합 및 분할해야 하는 경우, PyPDF는 안정적이고 효율적인 솔루션을 제공합니다. PyPDF의 기능을 활용하면 Python 개발자는 PDF 관련 워크플로를 간소화하고 생산성을 향상시킬 수 있습니다.
IronPDF 는 Python용으로 개발된 포괄적이고 효율적인 PDF 조작 라이브러리로, PDF 파일 읽기, 생성, 병합 및 분할을 위한 다양한 기능을 제공합니다. 동적 PDF 보고서 생성, 기존 PDF에서 문서 정보 추출 또는 여러 문서 병합 등 어떤 작업이 필요하든 IronPDF 안정적이고 사용하기 쉬운 솔루션을 제공합니다. IronPDF 의 기능을 활용하면 Python 개발자는 PDF 관련 워크플로를 간소화하고 생산성을 향상시킬 수 있습니다.
종합적으로 비교해 보면, PyPDF는 기본적인 PDF 작업에 적합한 가볍고 사용하기 쉬운 라이브러리입니다. PDF 요구 사항이 간단한 프로젝트에 적합한 선택입니다. 반면 IronPDF 더욱 광범위한 API와 강력한 성능을 제공하므로 고급 PDF 처리 기능, 대용량 PDF 파일 처리 및 복잡한 작업 수행이 필요한 프로젝트에 이상적입니다.
결론
두 라이브러리 모두 일반적인 PDF 작업에 필요한 코딩 기능을 잘 갖추고 있습니다. PyPDF는 간단한 작업과 빠른 구현에 적합한 반면, IronPDF 복잡한 PDF 관련 작업을 처리하기 위한 더욱 광범위하고 다재다능한 API를 제공합니다.
성능 측면에서 IronPDF 특히 용량이 큰 PDF 파일을 처리하거나 복잡한 PDF 조작이 필요한 작업을 수행할 때 PyPDF보다 우수한 성능을 보일 가능성이 높습니다.
두 라이브러리 중 어느 것을 선택할지는 프로젝트의 구체적인 요구 사항과 관련된 PDF 작업의 복잡성에 따라 달라집니다.
IronPDF 상업용 모드에서 모든 기능을 테스트해 볼 수 있도록 무료 평가판 도 제공합니다. 여기 에서 Python용 IronPDF 다운로드하세요.
자주 묻는 질문
Python에서 PDF를 조작하는 데 있어 PyPDF와 IronPDF의 주요 차이점은 무엇인가요?
PyPDF는 PDF 읽기, 쓰기, 병합과 같은 기본적인 PDF 조작 기능을 제공하는 순수 Python 라이브러리입니다. 반면 IronPDF는 IronPDF의 .NET 라이브러리를 기반으로 구축되었으며 HTML을 PDF로 변환, 폼 처리, 복잡한 PDF 작업을 위한 고성능 연산과 같은 고급 기능을 제공합니다.
Python을 사용하여 HTML을 PDF로 변환하는 방법은 무엇인가요?
IronPDF를 사용하면 Python에서 HTML을 PDF로 변환할 수 있습니다. IronPDF는 HTML 문자열을 PDF로 변환하는 RenderHtmlAsPdf 메서드와 HTML 파일을 PDF로 변환하는 RenderHtmlFileAsPdf 메서드를 제공합니다.
Python 프로젝트에서 IronPDF를 사용하기 위한 설치 요구 사항은 무엇입니까?
Python에서 IronPDF를 사용하려면 시스템에 .NET 6.0 런타임이 설치되어 있어야 합니다. IronPDF는 pip install ironpdf 명령어를 사용하여 pip를 통해 설치할 수 있습니다.
PyPDF를 사용하여 PDF에서 텍스트와 이미지를 추출할 수 있습니까?
네, PyPDF는 PDF에서 텍스트와 이미지를 추출할 수 있도록 해줍니다. 텍스트 추출, PDF 병합 및 분할과 같은 기본적인 PDF 조작 작업을 위해 설계되었습니다.
복잡한 PDF 작업에 IronPDF를 사용하는 장점은 무엇입니까?
IronPDF는 HTML을 PDF로 변환, 양식 처리, 고급 텍스트 및 이미지 조작, 대용량 파일 처리 등 복잡한 PDF 작업에 필요한 강력한 성능과 광범위한 기능을 제공합니다.
IronPDF를 사용하여 PDF 파일을 병합하고 분할할 수 있습니까?
예, IronPDF는 PDF 파일을 효율적으로 병합하고 분할하는 기능을 제공하여 Python 애플리케이션 내에서 복잡한 PDF 작업을 관리하기 위한 포괄적인 솔루션을 제공합니다.
다양한 산업 분야에서 PDF를 사용하는 일반적인 사례는 무엇인가요?
PDF는 다양한 플랫폼과 기기에서 일관된 모양을 제공하기 때문에 보고서, 송장, 양식, 전자책과 같은 문서를 공유하는 데 여러 산업 분야에서 널리 사용됩니다.
IronPDF의 라이선스 옵션은 무엇인가요?
IronPDF는 Iron Software의 유효한 라이선스가 필요한 상용 제품입니다. 다양한 프로젝트 요구 사항에 맞춰 평가판을 포함한 여러 라이선스 옵션을 이용할 수 있습니다.