
Como converter PDF em texto em Python (Tutorial)
Este artigo demonstrará como usar o IronPDF for Python, uma das bibliotecas de PDF mais poderosas, para extrair qualquer texto disponível em um documento PDF.
Como converter PDF em texto em Python
- Instale uma biblioteca Python para converter PDF em texto.
- Carregar um documento PDF existente ou gerar um novo.
- Utilize o método
ExtractAllTextpara ler o texto do arquivo aberto. - Utilize outra sobrecarga do método para ler o texto de páginas específicas.
- Imprima o texto extraído no console ou salve-o em um arquivo de texto.
2.0 Como extrair texto de um PDF usando Python?
- Instale a versão mais recente do Python a partir da página de downloads do Python.
- Abra qualquer IDE (Ideal de Desenvolvimento de Ambiente) for Python.
- Instale o runtime do .NET Core.
- Instale a biblioteca IronPDF for Python ou faça o download na página de downloads do PyPI.
- Extrair texto do PDF
2.1 O que é o IronPDF for Python?
É muito simples integrar a biblioteca IronPDF em Python, pois é uma linguagem muito mais dinâmica em comparação com outras linguagens e permite que os desenvolvedores criem interfaces gráficas de usuário de forma rápida e fácil. Possui uma vasta gama de ferramentas pré-instaladas, incluindo PyQT, wxWidgets, Kivy e inúmeros pacotes e bibliotecas adicionais, que podem ser usados para criar de forma rápida e segura uma GUI completa.
IronPDF for Python é uma biblioteca extremamente eficiente, particularmente útil para desenvolvimento web. A disponibilidade de tantos paradigmas de desenvolvimento web em Python, como Django, Flask e Pyramid, é em parte responsável por isso. Essas estruturas foram utilizadas por inúmeros sites e serviços online, incluindo Reddit, Mozilla e Spotify.
2.2 Funcionalidades do IronPDF
Um arquivo PDF pode ser criado a partir de diversas fontes , incluindo sites em HTML, HTML5, ASP e PHP. Além de arquivos HTML, também é possível converter arquivos de imagem para PDF .
- O IronPDF permite criar documentos PDF interativos, preencher e enviar formulários interativos , dividir e combinar arquivos PDF, extrair texto e imagens de arquivos PDF, pesquisar palavras específicas em um arquivo PDF, rasterizar páginas PDF em imagens , converter PDF para HTML e imprimir arquivos PDF .
- O IronPDF consegue abrir arquivos PDF e imprimir a partir de um URL. Além disso, permite que os agentes de usuário façam login por meio de formulários de login HTML, proxies, cookies, cabeçalhos HTTP, credenciais de login de rede personalizadas, variáveis de formulário e agentes de usuário.
- É possível extrair imagens de documentos usando o IronPDF. Com o IronPDF, é muito fácil adicionar cabeçalhos e rodapés , texto e imagens, marcadores e marcas d'água , e muito mais aos documentos.
- É possível combinar e separar páginas em um documento novo ou existente usando o IronPDF.
- Sem utilizar um visualizador Acrobat, os documentos podem ser convertidos em objetos PDF. Um arquivo CSS pode ser usado para criar um documento PDF.
- A criação de documentos é possível utilizando arquivos CSS do tipo mídia.
2.3 Importar a biblioteca IronPDF
Inclua as seguintes declarações de importação no início dos arquivos de origem onde o IronPDF será usado para importar o IronPDF:
from ironpdf import *from ironpdf import *2.4 Definir chave de licença (se necessário)
Embora o IronPDF for Python seja gratuito, ele adiciona marcas d'água com um fundo em mosaico aos arquivos PDF para usuários da versão gratuita. Você precisa fornecer à biblioteca uma chave de licença válida para usar o IronPDF e criar PDFs sem marcas d'água. O seguinte trecho de código mostra como configurar a biblioteca com uma chave de licença:
# Set the license key for IronPDF
License.LicenseKey = "IRONPDF-LICENSE-KEY-ABCDEFGH"# Set the license key for IronPDF
License.LicenseKey = "IRONPDF-LICENSE-KEY-ABCDEFGH"Antes de criar arquivos PDF ou fazer alterações em seu conteúdo, certifique-se de que a chave de licença esteja configurada. O método LicenseKey deve ser chamado antes de qualquer outra linha de código. Para obter uma chave de licença de avaliação gratuita , visite a página de licenciamento .
2.5 Configurar arquivos de log
Um arquivo de texto chamado "Default" pode armazenar mensagens de log produzidas pelo Custom.log dentro do diretório do script Python. O trecho de código abaixo pode ser usado para definir a propriedade LogFilePath e personalizar o nome e a localização do arquivo de log:
# Enable debugging and set the log file path and mode
Logger.EnableDebugging = True
Logger.LogFilePath = "Custom.log"
Logger.LoggingMode = Logger.LoggingModes.All# Enable debugging and set the log file path and mode
Logger.EnableDebugging = True
Logger.LogFilePath = "Custom.log"
Logger.LoggingMode = Logger.LoggingModes.All3.0 Extrair texto de PDF com o IronPDF
A biblioteca IronPDF for Python pode converter páginas PDF em objetos PDF e permite a extração de texto de arquivos PDF, incluindo arquivos PDF digitalizados. Aqui está um exemplo que mostra como ler um PDF existente usando o IronPDF.
O primeiro método envolve extrair todo o texto disponível em um PDF; Segue abaixo um exemplo do código.
from ironpdf import *
# Load existing PDF document
pdf = PdfDocument.FromFile("content.pdf")
# Extract all the text from the entire PDF document
all_text = pdf.ExtractAllText()
# Display the extracted text
print(all_text)from ironpdf import *
# Load existing PDF document
pdf = PdfDocument.FromFile("content.pdf")
# Extract all the text from the entire PDF document
all_text = pdf.ExtractAllText()
# Display the extracted text
print(all_text)Como ilustrado no código acima, o método FromFile é um objeto leitor de PDF que carrega o arquivo PDF existente e o converte em objetos de documento PDF. Este objeto pode ser usado para ler o texto e as imagens disponíveis nas páginas do PDF. O objeto fornece um método chamado ExtractAllText que extrai cada pedaço de texto de todo o arquivo PDF, mantendo o texto em uma string que pode ser processada. E então use a função print para exibir o texto.
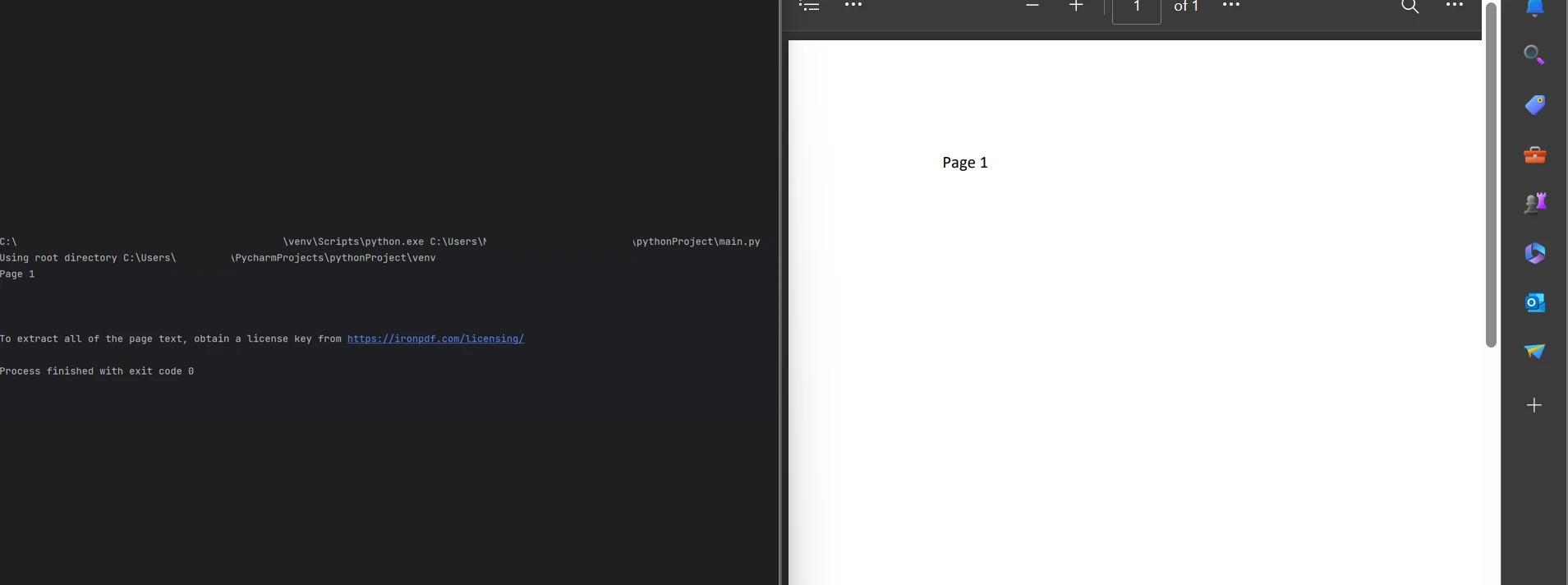 Exibindo o texto
Exibindo o texto
O exemplo de código para o segundo método, que pode ser usado para extrair texto página por página de um arquivo PDF, é fornecido abaixo.
from ironpdf import *
# Load existing PDF document
pdf = PdfDocument.FromFile("content.pdf")
# Extract text from a specific page in the document
page_text = pdf.ExtractTextFromPage(1)
# Display the extracted text from the specified page
print(page_text)from ironpdf import *
# Load existing PDF document
pdf = PdfDocument.FromFile("content.pdf")
# Extract text from a specific page in the document
page_text = pdf.ExtractTextFromPage(1)
# Display the extracted text from the specified page
print(page_text)O método FromFile é usado para carregar o arquivo PDF de um arquivo existente e convertê-lo em um objeto de arquivo PDF, como mostrado no código acima. Um método no objeto de página PDF chamado ExtractTextFromPage recupera todo o texto de uma página em um arquivo PDF. O número da página deve ser fornecido como um parâmetro para extrair o texto daquela página específica. Então, após extrair o texto, page_text pode ser usado para segurar as informações que podem ser processadas.
Confira mais exemplos de como extrair texto de um PDF.
4.0 Conclusão
A biblioteca IronPDF , por outro lado, oferece fortes medidas de segurança para reduzir os riscos potenciais. Não é específico para nenhum navegador em particular e funciona com todos os navegadores mais comuns. O IronPDF permite que programadores criem e leiam arquivos PDF facilmente com apenas algumas linhas de código. A biblioteca IronPDF oferece uma variedade de opções de licenciamento, incluindo uma licença de desenvolvedor gratuita e licenças de desenvolvimento adicionais que podem ser adquiridas para atender às necessidades de diferentes desenvolvedores.
O IronPDF inclui uma licença perpétua, uma garantia de reembolso de 30 dias, um ano de suporte de software e opções de atualização. Não há custos adicionais após a compra inicial. Essas licenças podem ser usadas em ambientes de desenvolvimento, teste e produção. Saiba mais sobre licenciamento de produtos .
Faça o download do software.
Perguntas frequentes
Como posso converter um PDF em texto usando Python?
Você pode converter um PDF em texto em Python usando o método ` PdfDocument.FromFile do IronPDF para carregar o PDF e, em seguida, empregar os métodos ExtractAllText ou ExtractTextFromPage para extrair o texto desejado.
Que configuração é necessária para usar uma biblioteca PDF em Python?
Para usar o IronPDF, você precisa ter o Python e uma IDE instalados, além do ambiente de execução .NET Core. O IronPDF pode ser instalado através da página de downloads do PyPI.
Posso extrair texto de uma página específica de um PDF usando Python?
Sim, com o IronPDF, você pode usar o método ExtractTextFromPage para extrair texto de uma página específica, fornecendo o número da página como parâmetro.
Existem opções gratuitas para usar uma biblioteca PDF em Python?
O IronPDF for Python oferece uma versão gratuita que adiciona uma marca d'água aos PDFs. Para remover as marcas d'água e desbloquear todos os recursos, você precisará de uma chave de licença.
Como faço para integrar uma biblioteca de PDF com frameworks web como Django ou Flask?
O IronPDF integra-se perfeitamente com frameworks web como Django e Flask, permitindo gerar e manipular PDFs em seus projetos de aplicações web.
Que funcionalidades devo procurar numa biblioteca Python para PDF?
Uma biblioteca de PDF completa como o IronPDF deve oferecer suporte à criação de PDFs a partir de HTML e imagens, extração de texto, preenchimento de formulários, mesclagem de PDFs e adição de marcadores e marcas d'água.
Como faço para definir uma chave de licença para uma biblioteca PDF em Python?
Para o IronPDF, defina a chave de licença usando o método License.LicenseKey antes de executar qualquer outro código para registrar sua licença e remover as marcas d'água.
A biblioteca Python PDF suporta a criação de PDFs a partir de páginas web?
O IronPDF pode criar PDFs a partir de HTML, HTML5 e páginas web criadas com ASP ou PHP, tornando-se uma ferramenta versátil para geração de PDFs a partir da web.
Como posso habilitar a depuração em uma biblioteca PDF for Python?
Habilite a depuração no IronPDF definindo Logger.EnableDebugging como true e definindo um caminho de arquivo de log usando Logger.LogFilePath .
Quais são os recursos de segurança de uma biblioteca PDF em Python?
O IronPDF garante segurança e compatibilidade entre navegadores, oferecendo uma solução confiável para desenvolvedores que buscam manipulação segura de PDFs em Python.
















