
Pythonでの分散コンピューティング
分散型Python
急速に変化する技術分野において、拡張性が高く効果的なコンピューティングソリューションのニーズがこれまで以上に高まっています。 分散コンピューティングは、多量の分散データ処理、同時ユーザーリクエスト、および計算負荷の高いタスクを伴う仕事において、ますます必要となっています。 開発者が分散型Pythonを最大限に活用できるように、そのアプリケーション、原則、ツールをこの投稿で検討します。
PDFドキュメントを動的に生成および変更することは、Web開発の分野で一般的な要件です。 プログラムによってPDFを作成する機能は、請求書、レポート、証明書などを即座に作成するのに便利です。
Pythonの広大なエコシステムと多様性により、無数のPDFライブラリに対応することが可能です。 IronPDFは、PDF作成のプロセスを簡素化し、タスクの並列処理と分散コンピューティングを可能にすることで、開発者がインフラストラクチャを最大限に活用するのを助ける強力なソリューションです。
分散型Pythonの理解
基本的に、分散型Pythonは計算作業を小さい塊に分割し、それをいくつかのノードまたは処理ユニットに分配するプロセスです。 これらのノードはネットワークに接続された個々のマシン、システム内の個々のCPUコア、リモートオブジェクト、リモート関数、リモートまたは関数呼び出しの実行、さらには単一プロセス内の個々のスレッドである可能性があります。 目的は、負荷を並列化することでパフォーマンス、スケーラビリティ、フォールトトレランスを向上させることです。
Pythonは、使いやすさ、適応性、および堅牢なライブラリエコシステムのため、分散コンピューティングワークロードに最適な選択肢です。 Pythonは、強力なフレームワークのthreadingまで、あらゆる規模とユースケースの分散コンピューティングのための豊富なツールを提供します。
詳細に入る前に、分散型Pythonが基づく基本的な考え方と原則を見直しましょう:
並列性と同時性
並列性は複数のタスクを同時に実行することであり、同時性は多くのタスクを扱うことに関係しており、それらは同時でなくても進行中である可能性があります。 並列性と同時性は、作業内容とシステムの設計によって、分散型Pythonでカバーされています。
タスクの分配
並列および分散コンピューティングの重要な要素は、複数のノードまたは処理ユニットに作業を分配することです。 計算プログラム内の関数実行が複数コアに並列化されたり、データ処理パイプラインが小さな段階に分割されたりする場合など、作業を効果的に分配することは全体的なパフォーマンス、効率、リソース使用を最適化するために重要です。
通信と調整
リモート関数実行、複雑なワークフロー、データ交換、および計算同期のオーケストレーションを促進するために、分散システムでは効果的な通信と調整が不可欠です。
分散型Pythonプログラムは、メッセージキュー、分散データ構造、およびリモートプロシージャコール(RPC)などの技術を活用して、リモートと実際の関数実行間でのスムーズな調整と通信を可能にします。
信頼性とエラー防止
スケーラビリティとは、さまざまなマシン上のノードや処理ユニットを追加することによって、システムが増大するワークロードに対応できる能力を指します。 一方で、フォールトトレランスは、マシンの故障、ネットワークの分割、ノードのクラッシュなど、機能不全に耐えつつも安定して機能するシステムの設計を指します。
複数のマシンにわたる分散型アプリケーションの安定性および回復力を保証するため、分散型Pythonフレームワークには故障許容と自動スケーリング機能がよく組み込まれています。
分散型Pythonの応用
データ処理と分析: 分散PythonフレームワークのDaskを使用して、大規模データセットを並列に処理することができ、バッチ処理、リアルタイムのストリーム処理、機械学習を大規模に実行する分散Pythonアプリケーションが可能になります。
マイクロサービスを使用したWeb開発: Python WebフレームワークのCeleryを組み合わせて、スケーラブルなWebアプリケーションやマイクロサービスアーキテクチャを作成できます。 Webアプリケーションは、分散キャッシュ、非同期リクエスト処理、バックグラウンドジョブ処理などの機能を簡単に組み込むことができます。
科学計算とシミュレーション: Pythonの科学ライブラリの強力なエコシステムと分散コンピューティングフレームワークによって、ハイパフォーマンスコンピューティング(HPC)および機器の集合にわたる並列シミュレーションが可能です。 アプリケーションには、金融リスク分析、気候モデル、機械学習アプリケーション、および物理学および計算生物学のシミュレーションが含まれます。
エッジコンピューティングとモノのインターネット(IoT): IoTデバイスとエッジコンピューティング設計が増加するにつれて、分散Pythonはセンサデータの処理、エッジコンピューティングプロセスの調整、分散アプリケーションの共同構築、エッジでの現代アプリケーションのための分散機械学習モデルの実践においてますます重要になります。
分散型Pythonの作成と使用
Dask-MLを使用した分散機械学習
Daskを拡張します。 マシンクラスター内の複数のコアまたはプロセッサにタスクを分割することで、Python開発者は大規模なデータセット上で機械学習モデルを効果的に分散して訓練および適用できます。
import dask.dataframe as dd
from dask_ml.model_selection import train_test_split
from dask_ml.xgboost import XGBoostClassifier
from sklearn.metrics import accuracy_score
# Load and prepare data (replace with your data loading logic)
df = dd.read_csv("training_data.csv")
X = df.drop("target_column", axis=1) # Features
y = df["target_column"] # Target variable
# Split data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# Define and train the XGBoost model in a distributed fashion
model = XGBoostClassifier(n_estimators=100) # Adjust hyperparameters as needed
model.fit(X_train, y_train)
# Make predictions on test data (can be further distributed)
y_pred = model.predict(X_test)
# Evaluate model performance (replace with your desired evaluation metric)
accuracy = accuracy_score(y_test, y_pred)
print(f"Model Accuracy: {accuracy}")import dask.dataframe as dd
from dask_ml.model_selection import train_test_split
from dask_ml.xgboost import XGBoostClassifier
from sklearn.metrics import accuracy_score
# Load and prepare data (replace with your data loading logic)
df = dd.read_csv("training_data.csv")
X = df.drop("target_column", axis=1) # Features
y = df["target_column"] # Target variable
# Split data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# Define and train the XGBoost model in a distributed fashion
model = XGBoostClassifier(n_estimators=100) # Adjust hyperparameters as needed
model.fit(X_train, y_train)
# Make predictions on test data (can be further distributed)
y_pred = model.predict(X_test)
# Evaluate model performance (replace with your desired evaluation metric)
accuracy = accuracy_score(y_test, y_pred)
print(f"Model Accuracy: {accuracy}")Rayによる並列関数呼び出し
強力な分散計算フレームワークRayの助けを借りて、クラスターの多くのコアやコンピュータでPython関数やタスクを同時に実行できます。 @ray.remoteデコレーターを利用することで、Rayはリモートとして関数を指定できるようにします。 その後、これらのリモートタスクや操作は、クラスター内のRayワーカーで非同期に実行できます。
import ray
import numpy as np
# Define the Monte Carlo simulation function
@ray.remote
def simulate(seed):
np.random.seed(seed) # Set random seed for reproducibility
# Perform your simulation logic here (replace with your specific simulation)
# This example simulates a random walk and returns the final position
steps = 1000
position = 0
for _ in range(steps):
position += np.random.choice([-1, 1])
return position
# Initialize Ray cluster (comment out if using existing cluster)
ray.init()
# Number of simulations to run
num_sims = 10000
# Run simulations in parallel using Ray's map function
simulations = ray.get([simulate.remote(seed) for seed in range(num_sims)])
# Analyze simulation results (calculate statistics like average final position)
average_position = np.mean(simulations)
print(f"Average final position: {average_position}")
# Shut down Ray cluster (comment out if using existing cluster)
ray.shutdown()import ray
import numpy as np
# Define the Monte Carlo simulation function
@ray.remote
def simulate(seed):
np.random.seed(seed) # Set random seed for reproducibility
# Perform your simulation logic here (replace with your specific simulation)
# This example simulates a random walk and returns the final position
steps = 1000
position = 0
for _ in range(steps):
position += np.random.choice([-1, 1])
return position
# Initialize Ray cluster (comment out if using existing cluster)
ray.init()
# Number of simulations to run
num_sims = 10000
# Run simulations in parallel using Ray's map function
simulations = ray.get([simulate.remote(seed) for seed in range(num_sims)])
# Analyze simulation results (calculate statistics like average final position)
average_position = np.mean(simulations)
print(f"Average final position: {average_position}")
# Shut down Ray cluster (comment out if using existing cluster)
ray.shutdown()開始方法
IronPDF とは何ですか?
よく知られたIronPDF for .NETパッケージを使って、.NETプログラム内でPDFドキュメントを作成、修正、レンダリングできます。 HTMLコンテンツ、写真、または生データから新しいPDFドキュメントを作成することから、既存のものからテキストや画像を抽出すること、HTMLページをPDFに変換すること、既存のものにテキスト、画像、および形状を追加することまで、多くの方法でPDFを扱うことができるます。
IronPDFの簡単さと使いやすさは、その主な利点の2つです。 開発者は、わかりやすいAPIと詳細なドキュメントにより、.NETアプリ内で簡単にPDFを作成し始めることができます。 IronPDFの速度と効率は、開発者が高品質のPDFドキュメントを迅速に作成するのを容易にするさらに2つの特徴です。
IronPDFの利点いくつか:
- 生データ、画像、HTMLからPDFを作成。
- PDFファイルから画像とテキストを抽出。
- PDFファイルにヘッダー、フッター、およびウォーターマークを含めること。
- PDFファイルはパスワードがかけられ、暗号化されて保護されます。
- 電子的にドキュメントに記入し、署名をする能力。
IronPDFを使用した分散型PDF生成
Rayといった分散Pythonフレームワークによって、クラスター内の多くのコアやコンピュータにわたってタスクを分散することが可能です。 これにより、クラスタ全体でPDFの生成のような複雑なタスクを並行して実行し、各クラスタ内の複数のコアを活用することができ、大規模なバッチのPDFの作成に必要な時間を大幅に短縮できます。
pipを使用してrayライブラリをインストールすることから始めます。
pip install ironpdf
pip install celerypip install ironpdf
pip install celeryこちらはIronPDFとPythonを使用して分散PDF生成を行う2つの方法を示す概念的なPythonコードです。
中央ワーカーを使用したタスクキュー
中央ワーカー (worker.py):
from ironpdf import ChromePdfRenderer
from celery import Celery
app = Celery('pdf_tasks', broker='pyamqp://')
app.autodiscover_tasks()
@app.task(name='generate_pdf')
def generate_pdf(data):
print(data)
renderer = ChromePdfRenderer() # Instantiate renderer
pdf = renderer.RenderHtmlAsPdf(str(data))
pdf.SaveAs("output.pdf")
return f"PDF generated for data {data}"
if __name__ == '__main__':
app.worker_main(argv=['worker', '--loglevel=info', '--without-gossip', '--without-mingle', '--without-heartbeat', '-Ofair', '--pool=solo'])from ironpdf import ChromePdfRenderer
from celery import Celery
app = Celery('pdf_tasks', broker='pyamqp://')
app.autodiscover_tasks()
@app.task(name='generate_pdf')
def generate_pdf(data):
print(data)
renderer = ChromePdfRenderer() # Instantiate renderer
pdf = renderer.RenderHtmlAsPdf(str(data))
pdf.SaveAs("output.pdf")
return f"PDF generated for data {data}"
if __name__ == '__main__':
app.worker_main(argv=['worker', '--loglevel=info', '--without-gossip', '--without-mingle', '--without-heartbeat', '-Ofair', '--pool=solo'])クライアントスクリプト (client.py):
from celery import Celery
app = Celery('pdf_tasks', broker='pyamqp://localhost')
def main():
# Send task to worker
task = app.send_task('generate_pdf', args=("<h1>This is a sample PDF</h1>",))
print(task.get()) # Wait for task completion and print result
if __name__ == '__main__':
main()from celery import Celery
app = Celery('pdf_tasks', broker='pyamqp://localhost')
def main():
# Send task to worker
task = app.send_task('generate_pdf', args=("<h1>This is a sample PDF</h1>",))
print(task.get()) # Wait for task completion and print result
if __name__ == '__main__':
main()Celeryは、私たちが使用しているタスクキューシステムです。 ジョブは、HTMLコンテンツを含むデータと一緒に中央のワーカー(worker.py)に送信されます。 その関数はIronPDFを使用してPDFを作成し、それを保存します。
クライアントスクリプト(client.py)によってサンプルデータを含むタスクがキューに送信されます。 このスクリプトは、他のコンピュータからタスクを送信するように変更することができます。
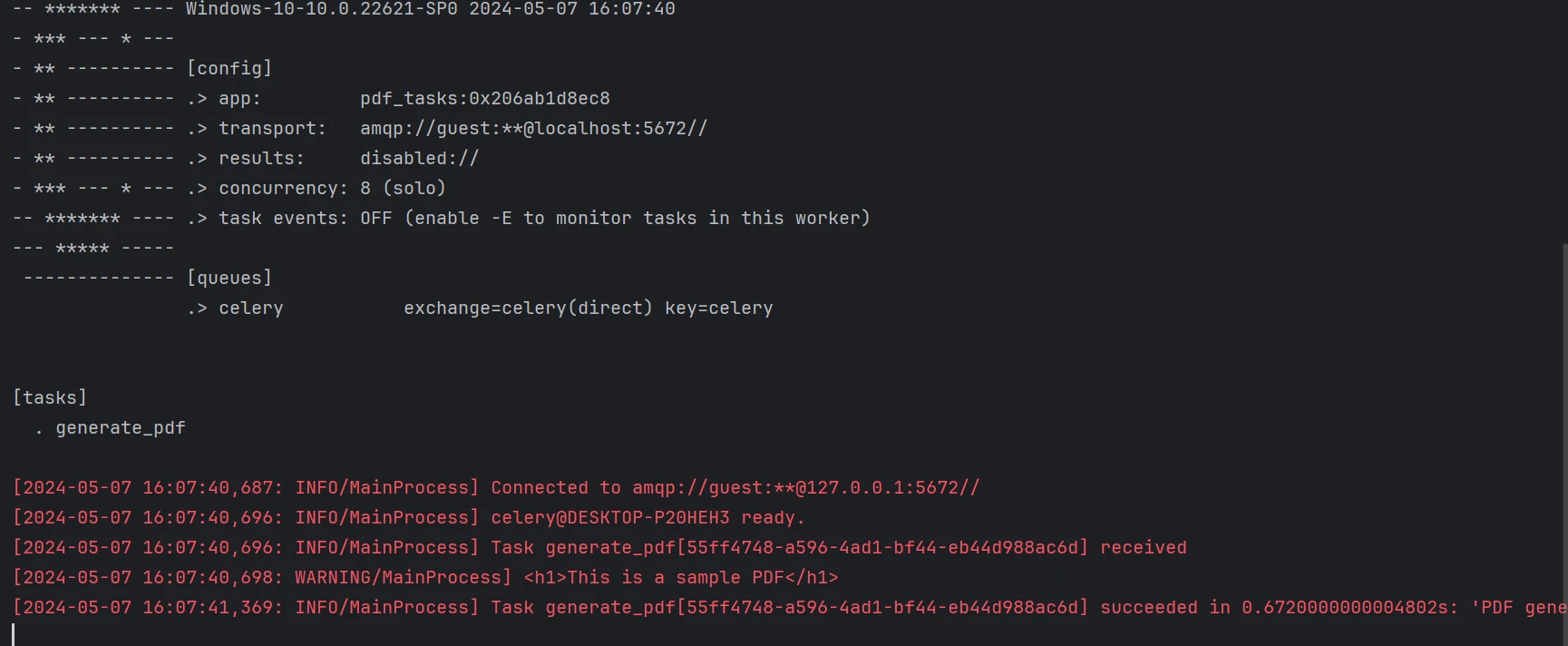
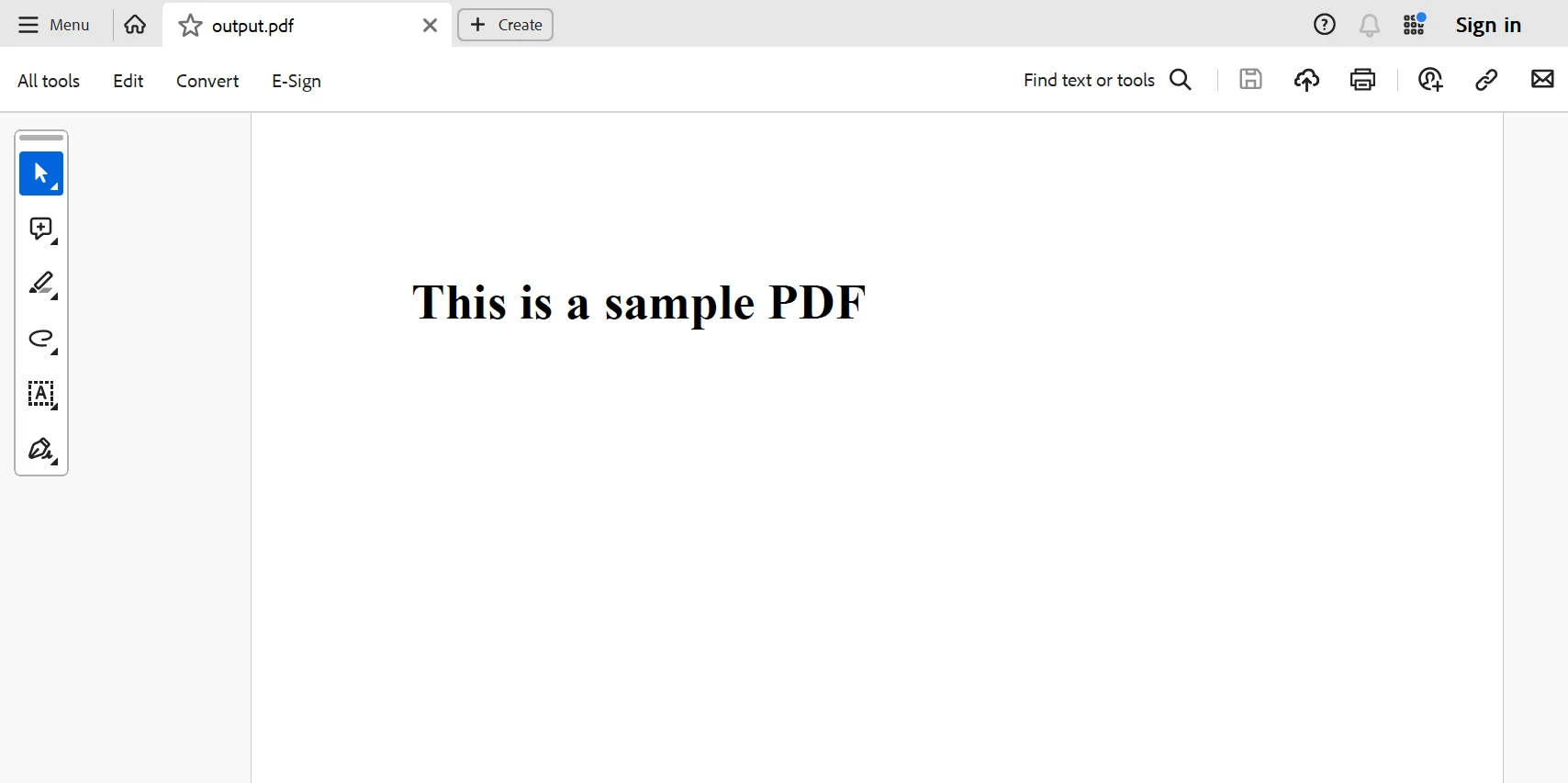
上記のコードから生成されたPDFです。
結論
大規模PDF作成タスクを扱うDaskのようなライブラリを活用することで膨大な可能性を発揮できます。 単一のマシンでコードを実行する場合と比較して、同じコードワークロードを複数のコアに分散させ、複数のマシンで使用することで、著しい速度向上を得ることができます。
IronPDFを1つのシステムでのPDF作成の強力なツールから、分散Pythonプログラミング言語を活用して大規模データセットを効果的に管理する信頼できるソリューションへと強化できます。 次の大規模PDF作成プロジェクトでIronPDFを最大限に活用するために、提供されているPythonライブラリを調査し、これらの方法を試してみてください。
IronPDFはパッケージとして購入するとお得で、生涯ライセンスが付いてきます。 このパッケージは非常にお得で、多くのシステムではわずか$799で購入可能です。 ライセンス所有者には24時間365日のオンラインエンジニアサポートを提供します。 料金の詳細については、ウェブサイトをご覧ください。 Iron Softwareが製造する製品についてもっと知りたい場合は、このページをご覧ください。
















