Pythonでリスト内のアイテムを見つける
リストはPythonにおける基本的なデータ構造であり、順序付けられたデータを保存するためによく使用されます。 リスト内の特定の要素を見つけることは、データ分析、フィルタリング、操作などのさまざまなタスクにとって重要な作業です。
Pythonはそのシンプルさと読みやすさで知られる、柔軟で強力なプログラミング言語です。 Pythonでリストを扱うとき、それは他のどのプログラミング言語よりもずっと簡単になります。 この記事では、Pythonを使用するさまざまな方法を探り、リスト内の要素を見つける場合には、利用可能なオプションとそのアプリケーションについての包括的な理解を提供します。
Pythonでリスト内の要素を見つける方法
in演算子を使用するindexメソッドを使用するcountメソッドを使用する- リスト内包表記を使用する
anyとall関数を使用する- カスタム関数を使用する
リストで希望するアイテムを見つけることの重要性
Pythonのリストで値を見つけること は、基本的でよく遭遇する作業です。 in、index、count、リスト内包表記、any、all、カスタム関数など、さまざまな方法を理解し習得することで、リスト内のデータを効率的に見つけて操作することができ、クリーンで効率的なコードを実現します。 具体的なニーズと検索条件の複雑さに基づいて最も適切な方法を選ぶために、リスト内の要素を見つけるさまざまな方法を見ていきますが、その前にPythonをシステムにインストールする必要があります。
Pythonのインストール
Pythonのインストールは簡単なプロセスであり、いくつかの簡単なステップで行うことができます。 ステップはオペレーティングシステムによってわずかに異なる場合があります。 ここでは、Windowsオペレーティングシステム向けの手順を提供します。
Windows
Pythonをダウンロードする:
- Pythonの公式ウェブサイトにアクセスします: Pythonダウンロード。
- "ダウンロード"タブをクリックすると、Pythonの最新バージョンのボタンが表示されます。 それをクリックします。

2.インストーラを実行します。
- インストーラーをダウンロードしたら、通常ダウンロードフォルダにある python-3.x.x.exe (xはバージョン番号を表します) という名前のファイルを見つけます。
インストーラーをダブルクリックして実行します。
- Python を設定します。
- インストールプロセス中に "Add Python to PATH" のチェックボックスを必ずオンにしてください。 これにより、コマンドラインインターフェースからPythonを簡単に実行できます。
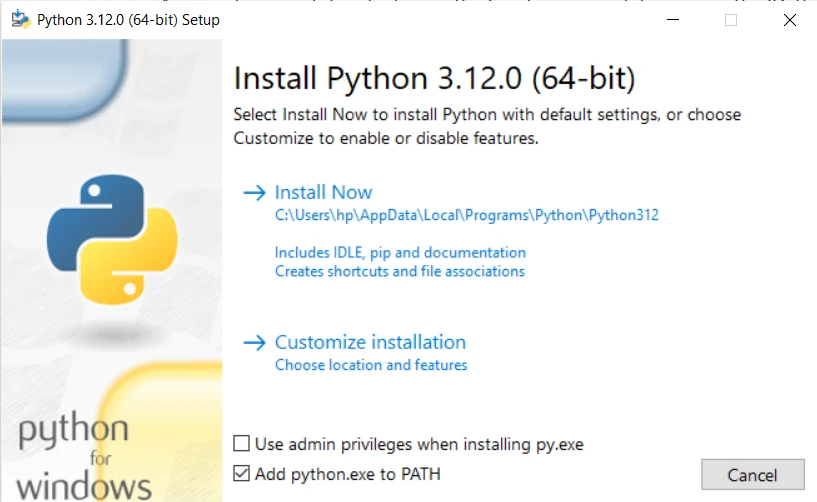
- Python を設定します。
Pythonをインストールします。
- 上記のスクリーンショットに示されているように、"Install Now" ボタンをクリックしてインストールを開始します。 インストーラーが必要なファイルをコンピュータにコピーします。
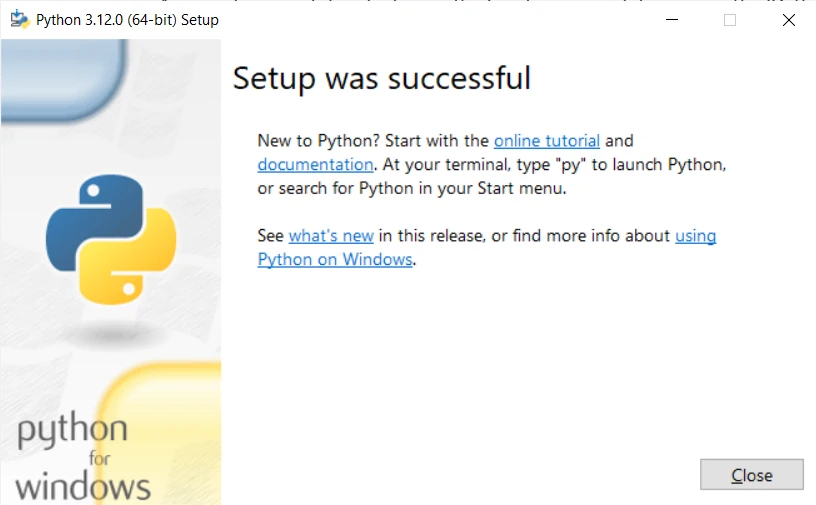
5.インストールの確認:
- コマンドプロンプトまたはPowerShellを開いて
python --versionまたはpython -Vを入力してください。 インストールされたPythonのバージョンが表示されます。
Pythonがインストールされたので、特定の要素を見つけたり、見つけた後に重複する要素を削除するため for Pythonリストメソッドを見ていきます。
Pythonのリストで見つけるメソッド
Pythonにインストールされたデフォルト for Python IDLEを開いて、コーディングを始めましょう。
1. in 演算子を使用する
リストに要素が存在するかどうかを確認する最も簡単な方法は、in 演算子を使用することです。 リスト内に要素が存在する場合、True を返し、そうでない場合は False を返します。
my_list = ["apple", "banana", "orange"]
element = "banana"
if element in my_list:
print("Element found!")
else:
print("Element not found.")my_list = ["apple", "banana", "orange"]
element = "banana"
if element in my_list:
print("Element found!")
else:
print("Element not found.")2. index リストメソッドを使用する
index メソッドは、リスト内の指定された要素の最初のインデックスを返します。要素が見つからない場合、ValueError 例外が発生します。
# Example usage of index method
element = "banana"
try:
element_index = my_list.index(element)
print(f"Element found at index: {element_index}")
except ValueError:
print("リスト内に要素が見つかりませんでした。")# Example usage of index method
element = "banana"
try:
element_index = my_list.index(element)
print(f"Element found at index: {element_index}")
except ValueError:
print("リスト内に要素が見つかりませんでした。")構文: my_list.index() メソッドの構文は単純です:
my_list.index(element, start, end)my_list.index(element, start, end)*要素:リスト内で検索する要素。
- start (オプション): 検索を開始するインデックス。 指定された場合、検索はこのインデックスから開始されます。 デフォルトは0です。
- end (オプション): 検索を終了するインデックス。 指定された場合、検索はこのインデックスに達するまで (このインデックスは含まない) 行われます。 デフォルトはリストの終わりです。
基本的な使い方
list.index() メソッドの基本的な使い方を説明するために、次の例から始めましょう:
fruits = ['apple', 'banana', 'orange', 'grape', 'banana']
# Find the index of 'orange' in the list
index = fruits.index('orange')
print(f"The index of 'orange' is: {index}")fruits = ['apple', 'banana', 'orange', 'grape', 'banana']
# Find the index of 'orange' in the list
index = fruits.index('orange')
print(f"The index of 'orange' is: {index}")出力:
現在の要素 for Pythonリストインデックスを表示します:
"orange" のインデックスは: 2ValueErrors の処理
指定されたリスト要素がリストに存在しない場合、list.index() メソッドは ValueError を発生させます。 これを処理するには、try-except ブロックを使用することをお勧めします:
fruits = ['apple', 'banana', 'orange', 'grape', 'banana']
try:
index = fruits.index('watermelon')
print(f"The index of 'watermelon' is: {index}")
except ValueError:
print("リスト内に要素が見つかりませんでした。")fruits = ['apple', 'banana', 'orange', 'grape', 'banana']
try:
index = fruits.index('watermelon')
print(f"The index of 'watermelon' is: {index}")
except ValueError:
print("リスト内に要素が見つかりませんでした。")出力:
リスト内に要素が見つかりませんでした。範囲内での検索
パラメーター start と end を使うことで、検索を行うべき範囲を指定することができます。 この方法は、要素がリスト内の特定のサブセットにのみ存在することがわかっている場合に特に便利です:
numbers = [1, 2, 3, 4, 5, 2, 6, 7, 8]
# Find the index of the first occurrence of '2' after index 3
index = numbers.index(2, 3)
print(f"The index of '2' after index 3 is: {index}")numbers = [1, 2, 3, 4, 5, 2, 6, 7, 8]
# Find the index of the first occurrence of '2' after index 3
index = numbers.index(2, 3)
print(f"The index of '2' after index 3 is: {index}")出力:
インデックス3以降の '2' のインデックスは: 5複数の出現
指定された要素がリストに複数回出現する場合、list.index() メソッドはその最初の出現のインデックスを返します。 すべての出現のインデックスが必要な場合は、ループを使用してリストを反復することができます:
fruits = ['apple', 'banana', 'orange', 'grape', 'banana']
# Find all indices of 'banana' in the list
indices = [i for i, x in enumerate(fruits) if x == 'banana']
print(f"The indices of 'banana' are: {indices}")fruits = ['apple', 'banana', 'orange', 'grape', 'banana']
# Find all indices of 'banana' in the list
indices = [i for i, x in enumerate(fruits) if x == 'banana']
print(f"The indices of 'banana' are: {indices}")出力:
"banana" のインデックスは: [1, 4]3. count メソッドを使用する
count メソッドは、リスト内の指定された要素の出現回数を返します。
element_count = my_list.count(element)
print(f"Element appears {element_count} times in the list.")element_count = my_list.count(element)
print(f"Element appears {element_count} times in the list.")4. リスト内包表記を使用する
リスト内包表記は、条件に基づいてリストから要素をフィルタリングする簡潔な方法を提供します。 このメソッドは各アイテムを反復し、存在する場合は要素を返します。
filtered_list = [item for item in my_list if item == element]
print(f"Filtered list containing element: {filtered_list}")filtered_list = [item for item in my_list if item == element]
print(f"Filtered list containing element: {filtered_list}")5. any と all 関数を使用する
any 関数は、リスト内の任意の要素が与えられた条件を満たしているかどうかを確認します。 all 関数は、すべての要素が条件を満たしているかどうかを確認します。
any 関数の例
any_fruit_starts_with_a = any(item.startswith("a") for item in fruits)
print(f"Does any fruit start with 'a': {any_fruit_starts_with_a}")any_fruit_starts_with_a = any(item.startswith("a") for item in fruits)
print(f"Does any fruit start with 'a': {any_fruit_starts_with_a}")all 関数の例
all_fruits_start_with_a = all(item.startswith("a") for item in fruits)
print(f"All fruits start with 'a': {all_fruits_start_with_a}")all_fruits_start_with_a = all(item.startswith("a") for item in fruits)
print(f"All fruits start with 'a': {all_fruits_start_with_a}")6. カスタム関数を使用する
複雑な検索条件のために、希望する条件を満たすかどうかを確認するためにカスタム関数を定義することができます。
def is_even(number):
return number % 2 == 0
numbers = [1, 2, 3, 4, 5, 6, 7, 8]
filtered_list = list(filter(is_even, numbers))
print(f"Filtered list containing even numbers: {filtered_list}")def is_even(number):
return number % 2 == 0
numbers = [1, 2, 3, 4, 5, 6, 7, 8]
filtered_list = list(filter(is_even, numbers))
print(f"Filtered list containing even numbers: {filtered_list}")IronPDF for Pythonを使用したPythonリストでの検索の活用
IronPDF は、Iron Softwareによって開発された、さまざまなプログラミング環境でPDFファイルを簡単かつ柔軟に操作するように設計された強力な.NETライブラリです。 Iron Suiteの一部として、IronPDFは開発者に強力なツールを提供し、PDF文書からコンテンツを簡単に作成、編集、および抽出することを可能にします。 その包括的な機能と互換性により、IronPDFはPDF関連のタスクを簡素化し、PDFファイルをプログラムで扱うための多用途なソリューションを提供します。

開発者はPythonのリストを簡単に使用してIronPDF文書を操作できます。 これらのリストは、PDFから抽出された情報を整理し、管理するのに役立ち、テキストの処理、テーブルの操作、新しいPDFコンテンツの作成などのタスクを容易にします。
IronPDFから抽出したテキストを使ってPythonリスト操作を組み込みましょう。 次のコードは、抽出されたコンテンツ内に特定のテキストを見つけるために in 演算子を使用し、それぞれのキーワードの出現回数を数える方法を示しています。 リスト内包表記の方法を使って、キーワードを含む完全な文を見つけることもできます:
from ironpdf import *
# Load existing PDF document
pdf = PdfDocument.FromFile("content.pdf")
# Extract text from PDF document
all_text = pdf.ExtractAllText()
# Define a list of keywords to search for in the extracted text
keywords_to_find = ["important", "information", "example"]
# Check if any of the keywords are present in the extracted text
for keyword in keywords_to_find:
if keyword in all_text:
print(f"Found '{keyword}' in the PDF content.")
else:
print(f"'{keyword}' not found in the PDF content.")
# Count the occurrences of each keyword in the extracted text
keyword_counts = {keyword: all_text.count(keyword) for keyword in keywords_to_find}
print("Keyword Counts:", keyword_counts)
# Use list comprehensions to create a filtered list of sentences containing a specific keyword
sentences_with_keyword = [sentence.strip() for sentence in all_text.split('.') if any(keyword in sentence for keyword in keywords_to_find)]
print("Sentences with Keyword:", sentences_with_keyword)
# Extract text from a specific page in the document
page_2_text = pdf.ExtractTextFromPage(1)from ironpdf import *
# Load existing PDF document
pdf = PdfDocument.FromFile("content.pdf")
# Extract text from PDF document
all_text = pdf.ExtractAllText()
# Define a list of keywords to search for in the extracted text
keywords_to_find = ["important", "information", "example"]
# Check if any of the keywords are present in the extracted text
for keyword in keywords_to_find:
if keyword in all_text:
print(f"Found '{keyword}' in the PDF content.")
else:
print(f"'{keyword}' not found in the PDF content.")
# Count the occurrences of each keyword in the extracted text
keyword_counts = {keyword: all_text.count(keyword) for keyword in keywords_to_find}
print("Keyword Counts:", keyword_counts)
# Use list comprehensions to create a filtered list of sentences containing a specific keyword
sentences_with_keyword = [sentence.strip() for sentence in all_text.split('.') if any(keyword in sentence for keyword in keywords_to_find)]
print("Sentences with Keyword:", sentences_with_keyword)
# Extract text from a specific page in the document
page_2_text = pdf.ExtractTextFromPage(1)結論
結論として、データ分析や操作のようなタスクにおいて、Pythonのリスト内で要素を効率的に見つけることの重要性は、構造化データから特定の詳細を見つける際に非常に大きいです。 Pythonは、in 演算子を使うこと、index メソッド、count メソッド、リスト内包表記、any 関数および all 関数を使用するなど、リスト中の要素を見つけるための様々な方法を提供します。 各メソッドまたは関数は、リスト内の特定の項目を見つけるために使用できます。 これらのテクニックをマスターすることで、コードの読みやすさと効率が向上し、Pythonで多様なプログラミングチャレンジを克服するための力を与えます。
上記の例は、IronPDFとシームレスに統合されたさまざまなPythonリストの方法をテキスト抽出および分析プロセスを強化するためにどう活用することができるかを示しています。 これにより、開発者は読み取り可能なPDF文書から指定されたテキストを抽出するためのより多くのオプションが得られます。
IronPDFは開発目的には無料ですが、商業目的の利用にはライセンスが必要です。 無料試用版を提供しており、こちらからダウンロードできます。