Trouver des éléments dans des listes en Python
Les listes sont des structures de données fondamentales en Python, souvent utilisées pour stocker des collections de données ordonnées. Trouver des éléments spécifiques dans une liste est une tâche critique pour diverses tâches comme l'analyse de données, le filtrage et la manipulation.
Python est un langage de programmation polyvalent et puissant, connu pour sa simplicité et sa lisibilité. Travailler avec des listes en Python rend les choses beaucoup plus faciles que tout autre langage de programmation. Cet article explore diverses méthodes pour trouver des éléments dans une liste en Python, il vous offrira une compréhension complète des options disponibles et de leurs applications.
Comment trouver un élément dans une liste en Python
- Utilisation de l'opérateur
in - Utilisation de la méthode
index - Utilisation de la méthode
count - Utiliser des compréhensions de liste
- Utilisation des fonctions
anyetall - Utiliser des fonctions personnalisées
Importance de trouver l'élément souhaité dans une liste
Rechercher des valeurs dans les listes Python est une tâche fondamentale et fréquemment rencontrée. Comprendre et maîtriser les différentes méthodes comme in, index, count, compréhensions de liste, any, all, et fonctions personnalisées vous permet de localiser et manipuler efficacement les données au sein de vos listes, ouvrant la voie à un code clair et efficace. Pour choisir la méthode la plus appropriée en fonction de vos besoins spécifiques et de la complexité des critères de recherche, examinons les différentes façons de trouver un élément donné dans une liste, mais avant cela, Python doit être installé sur votre système.
Installation de Python
L'installation de Python est un processus simple, et elle peut être réalisée en quelques étapes simples. Les étapes peuvent varier légèrement selon votre système d'exploitation. Ici, je fournirai des instructions pour le système d'exploitation Windows.
Windows
-
Téléchargez Python :
- Visitez le site officiel de Python : Téléchargements Python.
- Cliquez sur l'onglet 'Downloads', et vous verrez un bouton pour la dernière version de Python. Cliquez dessus.

- Exécutez le programme d'installation :
- Une fois l'installateur téléchargé, localisez le fichier (généralement dans votre dossier Téléchargements) avec un nom comme python-3.x.x.exe ('x' représente le numéro de version).
- Double-cliquez sur l'installateur pour l'exécuter.
-
Configurer Python :
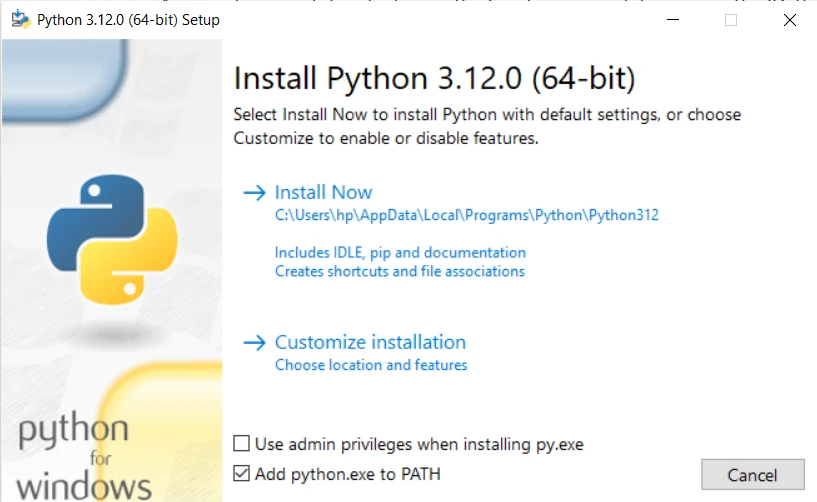
- Assurez-vous de cocher la case : 'Ajouter Python au PATH' pendant le processus d'installation. Cela facilite l'exécution de Python depuis l'interface de ligne de commande.
-
Installez Python :
- Cliquez sur le bouton 'Installer maintenant' pour démarrer l'installation comme indiqué dans la capture d'écran ci-dessus. L'installateur copiera les fichiers nécessaires sur votre ordinateur.
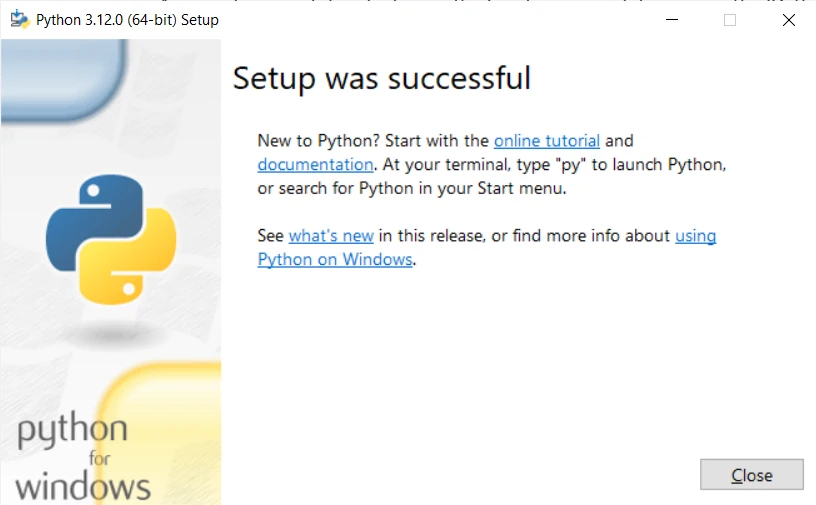
- Vérifier l'installation :
- Ouvrez l'invite de commandes ou PowerShell et tapez
python --versionoupython -V. Vous devriez voir la version de Python installée.
- Ouvrez l'invite de commandes ou PowerShell et tapez
Python est installé, passons donc aux méthodes de liste Python pour trouver un certain élément ou même supprimer des éléments en double après les avoir trouvés.
Méthodes pour rechercher dans une liste Python
Ouvrez l'IDLE Python par défaut installé avec Python et commencez à coder.
1. Utilisation de l'opérateur in
La manière la plus simple de vérifier si un élément existe dans une liste est d'utiliser l'opérateur in. Il renvoie True si l'élément à l'intérieur de la liste existe et False sinon.
my_list = ["apple", "banana", "orange"]
element = "banana"
if element in my_list:
print("Element found!")
else:
print("Element not found.")my_list = ["apple", "banana", "orange"]
element = "banana"
if element in my_list:
print("Element found!")
else:
print("Element not found.")2. Utilisation de la méthode de liste index
La méthode index renvoie le premier index de l'élément spécifié dans la liste. Si l'élément est introuvable, elle lève une exception ValueError.
# Example usage of index method
element = "banana"
try:
element_index = my_list.index(element)
print(f"Element found at index: {element_index}")
except ValueError:
print("Élément non trouvé dans la liste.")# Example usage of index method
element = "banana"
try:
element_index = my_list.index(element)
print(f"Element found at index: {element_index}")
except ValueError:
print("Élément non trouvé dans la liste.")Syntaxe : La syntaxe de la méthode my_list.index() est simple :
my_list.index(element, start, end)my_list.index(element, start, end)- élément : L'élément à rechercher dans la liste.
- début (optionnel) : L'index de départ pour la recherche. Si fourni, la recherche commence à cet index. La valeur par défaut est 0.
- fin (optionnel) : L'index de fin pour la recherche. Si fourni, la recherche se fait jusqu'à, mais non inclus, cet index. La valeur par défaut est la fin de la liste.
Utilisation de base
Commençons par l'exemple suivant pour illustrer l'utilisation de base de la méthode list.index() :
fruits = ['apple', 'banana', 'orange', 'grape', 'banana']
# Find the index of 'orange' in the list
index = fruits.index('orange')
print(f"The index of 'orange' is: {index}")fruits = ['apple', 'banana', 'orange', 'grape', 'banana']
# Find the index of 'orange' in the list
index = fruits.index('orange')
print(f"The index of 'orange' is: {index}")Sortie :
Affiche l'index de la liste Python de l'élément actuel :
L'index de 'orange' est : 2Traitement des ValueError
Il est important de noter que si l'élément de liste spécifié n'est pas présent dans la liste, la méthode list.index() génère une exception ValueError. Pour gérer cela, il est recommandé d'utiliser un bloc try-except :
fruits = ['apple', 'banana', 'orange', 'grape', 'banana']
try:
index = fruits.index('watermelon')
print(f"The index of 'watermelon' is: {index}")
except ValueError:
print("Élément non trouvé dans la liste.")fruits = ['apple', 'banana', 'orange', 'grape', 'banana']
try:
index = fruits.index('watermelon')
print(f"The index of 'watermelon' is: {index}")
except ValueError:
print("Élément non trouvé dans la liste.")Sortie :
Élément non trouvé dans la liste.Recherche dans une plage
Les paramètres début et fin vous permettent de spécifier une plage dans laquelle la recherche doit être effectuée. Cela est particulièrement utile lorsque vous savez que l'élément n'existe que dans un certain sous-ensemble de la liste :
numbers = [1, 2, 3, 4, 5, 2, 6, 7, 8]
# Find the index of the first occurrence of '2' after index 3
index = numbers.index(2, 3)
print(f"The index of '2' after index 3 is: {index}")numbers = [1, 2, 3, 4, 5, 2, 6, 7, 8]
# Find the index of the first occurrence of '2' after index 3
index = numbers.index(2, 3)
print(f"The index of '2' after index 3 is: {index}")Sortie :
L'index de '2' après l'index 3 est : 5Occurrences multiples
Si l'élément spécifié apparaît plusieurs fois dans la liste, la méthode list.index() renvoie l'index de sa première occurrence. Si vous avez besoin des indices de toutes les occurrences, vous pouvez utiliser une boucle pour itérer à travers la liste :
fruits = ['apple', 'banana', 'orange', 'grape', 'banana']
# Find all indices of 'banana' in the list
indices = [i for i, x in enumerate(fruits) if x == 'banana']
print(f"The indices of 'banana' are: {indices}")fruits = ['apple', 'banana', 'orange', 'grape', 'banana']
# Find all indices of 'banana' in the list
indices = [i for i, x in enumerate(fruits) if x == 'banana']
print(f"The indices of 'banana' are: {indices}")Sortie :
Les indices de 'banana' sont : [1, 4]3. Utilisation de la méthode count
La méthode count renvoie le nombre d'occurrences de l'élément spécifié dans la liste.
element_count = my_list.count(element)
print(f"Element appears {element_count} times in the list.")element_count = my_list.count(element)
print(f"Element appears {element_count} times in the list.")4. Utiliser des compréhensions de liste
La compréhension de liste offre un moyen concis de filtrer les éléments d'une liste en fonction d'une condition. La méthode itère à travers chaque élément et retourne l'élément s'il est présent.
filtered_list = [item for item in my_list if item == element]
print(f"Filtered list containing element: {filtered_list}")filtered_list = [item for item in my_list if item == element]
print(f"Filtered list containing element: {filtered_list}")5. Utilisation des fonctions any et all
La fonction any vérifie si un élément quelconque de la liste satisfait une condition donnée. La fonction all vérifie si tous les éléments satisfont la condition.
Exemple de la fonction any
any_fruit_starts_with_a = any(item.startswith("a") for item in fruits)
print(f"Does any fruit start with 'a': {any_fruit_starts_with_a}")any_fruit_starts_with_a = any(item.startswith("a") for item in fruits)
print(f"Does any fruit start with 'a': {any_fruit_starts_with_a}")Exemple de la fonction all
all_fruits_start_with_a = all(item.startswith("a") for item in fruits)
print(f"All fruits start with 'a': {all_fruits_start_with_a}")all_fruits_start_with_a = all(item.startswith("a") for item in fruits)
print(f"All fruits start with 'a': {all_fruits_start_with_a}")6. Utiliser des fonctions personnalisées
Pour des critères de recherche complexes, vous pouvez définir votre propre fonction pour retourner une valeur afin de vérifier si un élément répond aux conditions souhaitées.
def is_even(number):
return number % 2 == 0
numbers = [1, 2, 3, 4, 5, 6, 7, 8]
filtered_list = list(filter(is_even, numbers))
print(f"Filtered list containing even numbers: {filtered_list}")def is_even(number):
return number % 2 == 0
numbers = [1, 2, 3, 4, 5, 6, 7, 8]
filtered_list = list(filter(is_even, numbers))
print(f"Filtered list containing even numbers: {filtered_list}")Utiliser la recherche dans une liste Python avec IronPDF
IronPDF est une robuste bibliothèque .NET par Iron Software, conçue pour une manipulation facile et flexible des fichiers PDF dans divers environnements de programmation. Dans le cadre de la Iron Suite, IronPDF fournit aux développeurs des outils puissants pour créer, éditer et extraire du contenu des documents PDF de manière transparente. Avec ses fonctionnalités complètes et sa compatibilité, IronPDF simplifie les tâches liées aux PDF, offrant une solution polyvalente pour gérer les fichiers PDF de manière programmatique.

Les développeurs peuvent facilement travailler avec les documents IronPDF en utilisant des listes Python. Ces listes aident à organiser et gérer les informations extraites des PDF, rendant les tâches telles que la gestion du texte, le travail avec les tableaux, et la création de nouveau contenu PDF un jeu d'enfant.
Intégrons une opération de liste Python avec du texte extrait d'IronPDF. Le code suivant montre comment utiliser l'opérateur in pour trouver un texte spécifique dans le contenu extrait, puis compter le nombre d'occurrences de chaque mot-clé. Nous pouvons également utiliser la méthode de compréhension de liste pour trouver des phrases complètes qui contiennent les mots-clés :
from ironpdf import *
# Load existing PDF document
pdf = PdfDocument.FromFile("content.pdf")
# Extract text from PDF document
all_text = pdf.ExtractAllText()
# Define a list of keywords to search for in the extracted text
keywords_to_find = ["important", "information", "example"]
# Check if any of the keywords are present in the extracted text
for keyword in keywords_to_find:
if keyword in all_text:
print(f"Found '{keyword}' in the PDF content.")
else:
print(f"'{keyword}' not found in the PDF content.")
# Count the occurrences of each keyword in the extracted text
keyword_counts = {keyword: all_text.count(keyword) for keyword in keywords_to_find}
print("Keyword Counts:", keyword_counts)
# Use list comprehensions to create a filtered list of sentences containing a specific keyword
sentences_with_keyword = [sentence.strip() for sentence in all_text.split('.') if any(keyword in sentence for keyword in keywords_to_find)]
print("Sentences with Keyword:", sentences_with_keyword)
# Extract text from a specific page in the document
page_2_text = pdf.ExtractTextFromPage(1)from ironpdf import *
# Load existing PDF document
pdf = PdfDocument.FromFile("content.pdf")
# Extract text from PDF document
all_text = pdf.ExtractAllText()
# Define a list of keywords to search for in the extracted text
keywords_to_find = ["important", "information", "example"]
# Check if any of the keywords are present in the extracted text
for keyword in keywords_to_find:
if keyword in all_text:
print(f"Found '{keyword}' in the PDF content.")
else:
print(f"'{keyword}' not found in the PDF content.")
# Count the occurrences of each keyword in the extracted text
keyword_counts = {keyword: all_text.count(keyword) for keyword in keywords_to_find}
print("Keyword Counts:", keyword_counts)
# Use list comprehensions to create a filtered list of sentences containing a specific keyword
sentences_with_keyword = [sentence.strip() for sentence in all_text.split('.') if any(keyword in sentence for keyword in keywords_to_find)]
print("Sentences with Keyword:", sentences_with_keyword)
# Extract text from a specific page in the document
page_2_text = pdf.ExtractTextFromPage(1)Conclusion
En conclusion, l'importance de trouver efficacement des éléments dans les listes Python pour des tâches comme l'analyse et la manipulation de données est immense lorsqu'il s'agit de trouver certains détails spécifiques à partir de données structurées. Python présente diverses méthodes pour trouver des éléments dans des listes, telles que l'utilisation de l'opérateur in, de la méthode index, de la méthode count, des compréhensions de listes et des fonctions any et all. Chaque méthode ou fonction peut être utilisée pour trouver un élément particulier dans des listes. Dans l'ensemble, maîtriser ces techniques améliore la lisibilité et l'efficacité du code, donnant aux développeurs les moyens de relever divers défis de programmation en Python.
Les exemples ci-dessus montrent comment les différentes méthodes de liste Python peuvent être intégrées de manière transparente avec IronPDF pour améliorer les processus d'extraction et d'analyse de texte. Cela donne aux développeurs plus d'options pour extraire le texte spécifié du document PDF lisible.
IronPDF est gratuit à des fins de développement mais doit être licencié pour une utilisation commerciale. Il offre un essai gratuit et peut être téléchargé depuis ici.