
PythonでPDFからデータを抽出する方法
IronPDFと呼ばれる強力なPythonパッケージを使用して、PDFファイルからデータ、画像、ラジオボタン、リストボックスウィジェット(チェックボックスウィジェットではなく)、その他の情報を抽出できます。 この記事では、このライブラリを使用してデータを含むインタラクティブフォームをグループ化し、新しいPDFファイルやPDFフォームを生成する方法を説明します。
PDFからデータを抽出する方法(Python)
- データ処理のためのテキストを抽出するPDFファイルを入手します。
- PyCharmでプロジェクトを作成します。
- プロジェクトに必要なPythonライブラリを設定します。
- PDFドキュメント内の特定のページから情報を抽出します。
- PDFドキュメントから抽出したテキストコンテンツを印刷します。
2. IronPDF
IronPDF for Pythonライブラリは、効率的なPDFデータ処理を可能にし、多くのPDF操作を提供することでPythonプログラミングをシームレスに強化します。 その統合機能はさまざまなフレームワークに拡張され、グラフィカルユーザーインターフェースの開発能力を向上させます。
Pythonは、使いやすいグラフィカルインターフェースを迅速かつ簡単に作成できる柔軟なプログラミング言語であり、多くの開発者に選ばれています。 そのダイナミックな性質は、他のプログラミング言語とは一線を画しています。 PythonにIronPDFライブラリを導入することは、効率的なPDFデータの取り扱いや処理を可能にする簡単なプロセスです。
完全機能的なグラフィカルユーザーインターフェースを迅速かつ安全に開発するために、開発者はPyQt、wxWidgets、Kivyなどの多くの人気のあるPythonライブラリを利用できます。
さらに、IronPDFライブラリは、特に.NET Coreのコンテキストで、Pythonおよび他のいくつかのプログラミング言語をサポートするさまざまなフレームワークからの機能をシームレスに統合します。 Python IronPDFに関する詳細情報は、公式ウェブサイトをご覧ください。
IronPDF for Pythonライブラリは、特にDjango、Flask、Pyramidなどのフレームワークを使用したPythonベースのWeb開発において、Webサイトの作成と管理のプロセスを簡素化します。 Reddit、Mozilla、Spotifyなどの人気サービスは、この有用なツールに依存しています。
2.1 IronPDFの特徴
HTML、HTML5、ASPX、Razor/MVCビューなど、さまざまな形式をIronPDFを使用してPDF形式に変換できます。 さらに、IronPDFは、画像やHTMLページからPDFファイルを生成する便利な機能も提供しています。
IronPDFツールキットは、インタラクティブPDFの作成、インタラクティブフォームの記入と提出の促進、PDFファイルの効率的なマージと分割、テキストおよび画像の正確な抽出、PDFファイル内の包括的なテキスト検索、PDFを画像に変換し、フォントサイズ、境界、背景色をカスタマイズする柔軟性を提供します。 IronPDFは、PDFファイルの変換も簡単に行うことができます。
IronPDFはさらに進んで、ユーザーエージェント、プロキシ、クッキー、HTTPヘッダー、およびフォーム変数のサポートを拡張し、HTMLログインフォームの検証を強化しています。 PDF内の安全なテキストにはユーザー名とパスワードを使用してアクセスを保護します。
PDFファイルを印刷することは、文字列、ストリーム、URLなどの多くのソースから生成でき、わずか数行のコードで達成できます。
IronPDFはインタラクティブ要素を変換することにより、フラットPDFドキュメントを生成し、ドキュメントの内容が変更不可能かつ表示可能であるが編集不可能であることを保証します。
3. 設定とセットアップ
3.1 Pythonのインストールと仮想環境の作成
コンピュータにPythonプログラミング言語がインストールされていることを確認してください。 これは、Pythonライブラリがさまざまなタスクに頻繁に必要とされるため、重要です。 公式Pythonウェブサイトを訪れて、オペレーティングシステムと互換性のある最新バージョンをダウンロードしてください。 これにより、Pythonライブラリを効果的に操作するための適切なツールが手に入ります。
Pythonをインストールした後、プロジェクト用の必要なライブラリを分離するために仮想環境を構築します。いくつかのプロジェクトでは、Pythonから必要なライブラリが必要となる場合があります。 仮想環境を構築および維持することを可能にするvenvモジュールは、特に複数 for Pythonライブラリを扱う際に、変換プロジェクトにクリーンで自律的な作業環境を提供するのに役立つかもしれません。
3.2 PyCharmで新しいプロジェクトを設定
Visual Studio Code、PyCharm、Sublime Textなどの任意のテキストエディタやコーディング環境を使用してPythonコードを書く柔軟性があります。 しかし、この記事では、Pythonコードを書くためのIDEであるPyCharmを使用してPythonプロジェクトを作成します。
PyCharm IDEが起動したら、新しいプロジェクトを選択します。
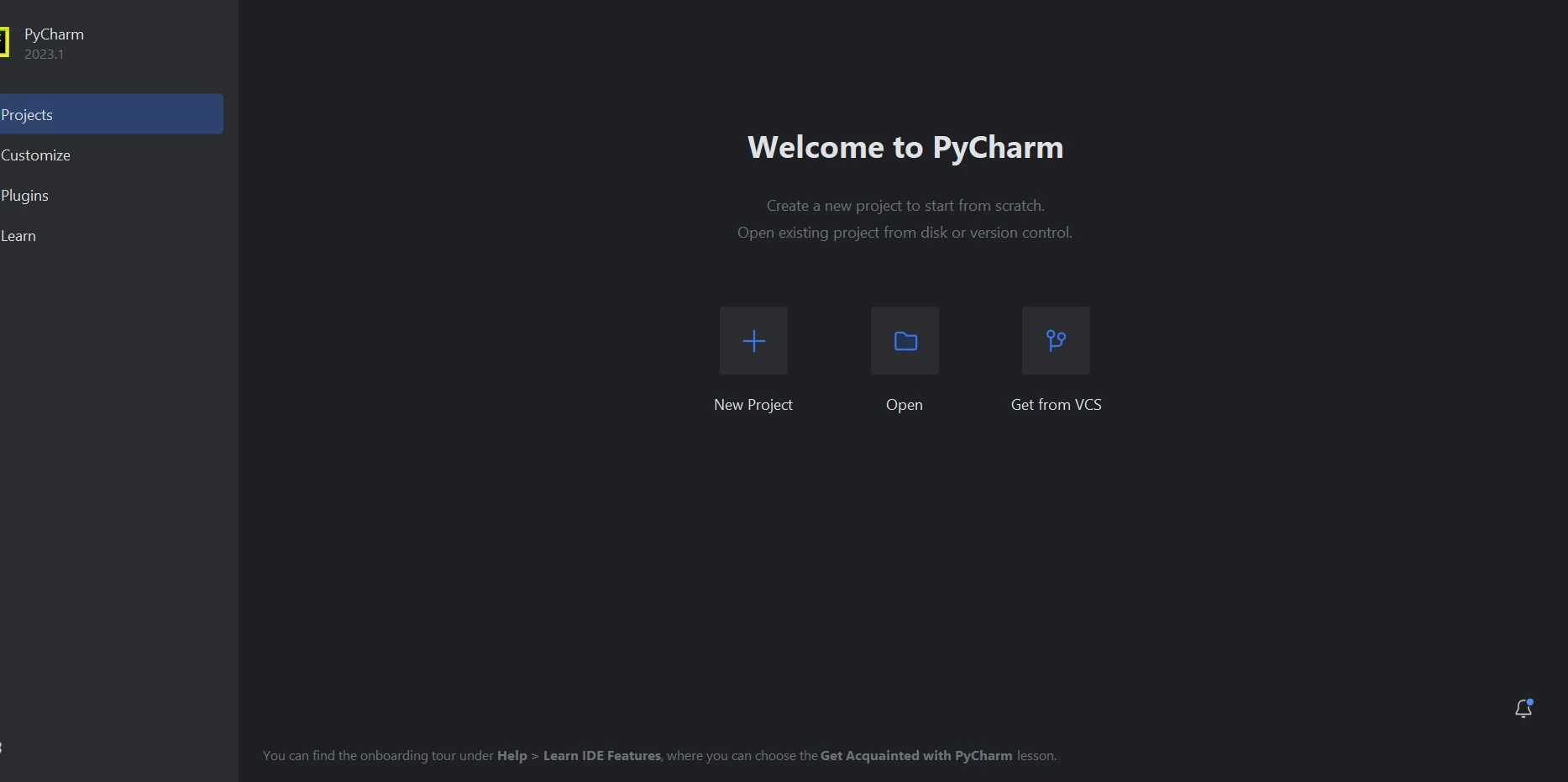 PyCharm IDEで新しいPythonプロジェクトを作成
PyCharm IDEで新しいPythonプロジェクトを作成
新しいプロジェクトを選択すると、プロジェクトの環境と場所を指定するための新しいウィンドウが表示されます。 下記の画像がより明確になるかもしれません。
プロジェクトの場所と環境の詳細を設定し、作成をクリックすると、PyCharmのインターフェースに入ります。 ここで、プロジェクトの構造とコードファイルが表示されます。 これはプロジェクトを管理し、開発するための作業スペースです。 このガイドで使用されているバージョンはPython 3.9です。
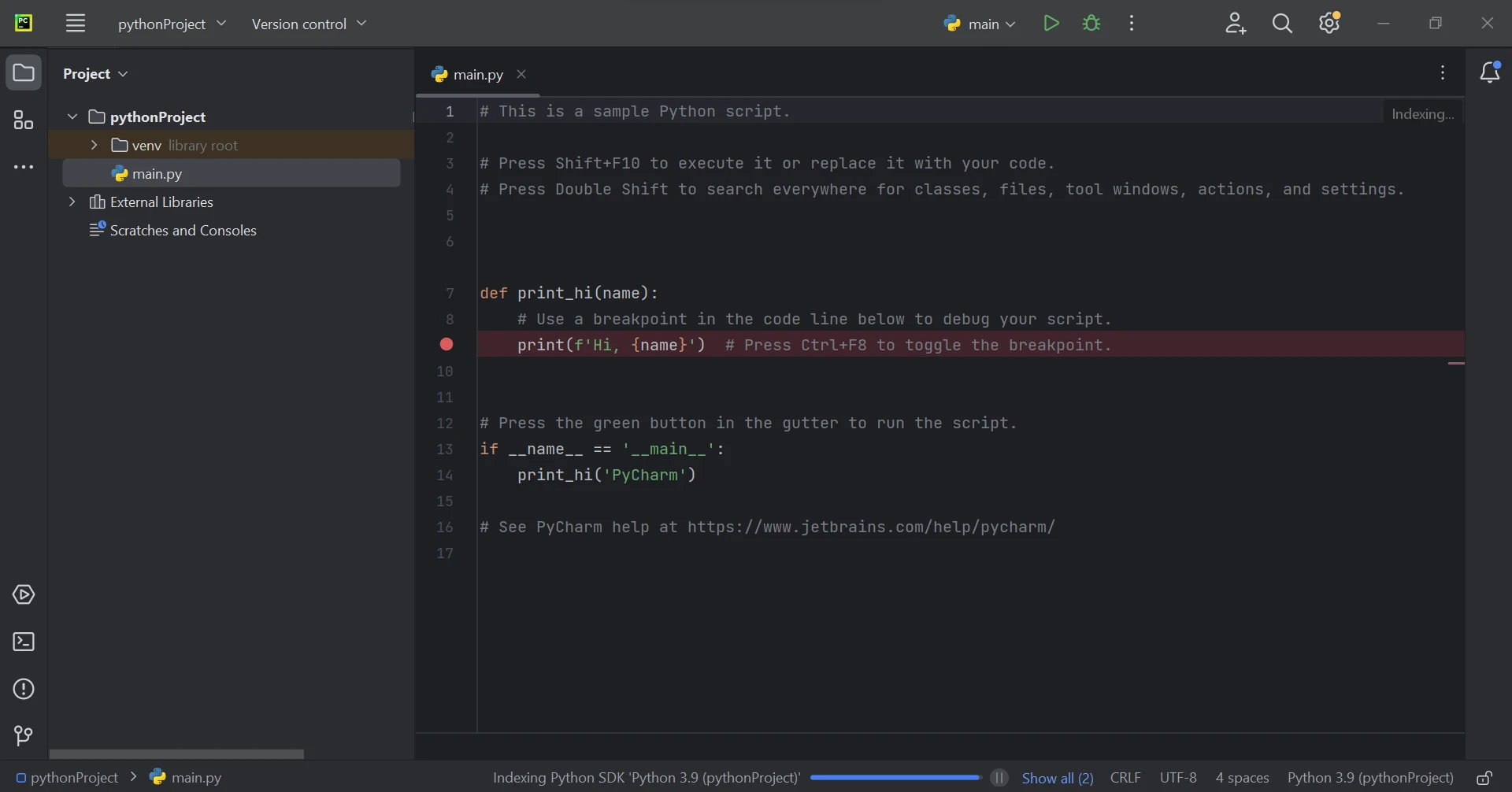 メイン for Pythonファイル
メイン for Pythonファイル
3.3 IronPDFのライブラリ要件
PythonライブラリIronPDFは通常、.NET 6.0とインターフェースを持ちます。したがって、Python用IronPDFを効果的に利用するには、コンピュータに.NET 6.0ランタイムが装備されている必要があります。
LinuxやMacユーザーの場合、こ for Pythonモジュールを使用する前に.NETをインストールする必要があるかもしれません。 必要なランタイム環境の取得に関するガイダンスについては、このMicrosoftのダウンロードページをご覧ください。
3.4 IronPDFライブラリのインストール
PDFファイルの作成、編集、開くなどを含む"ironpdf"パッケージをインストールする必要があります。 PyCharmでこれを行うには、ターミナルウィンドウを開いて次のコマンドを入力します。
pip install ironpdf
以下のスクリーンショットを参照してironpdfパッケージをインストールしてください。
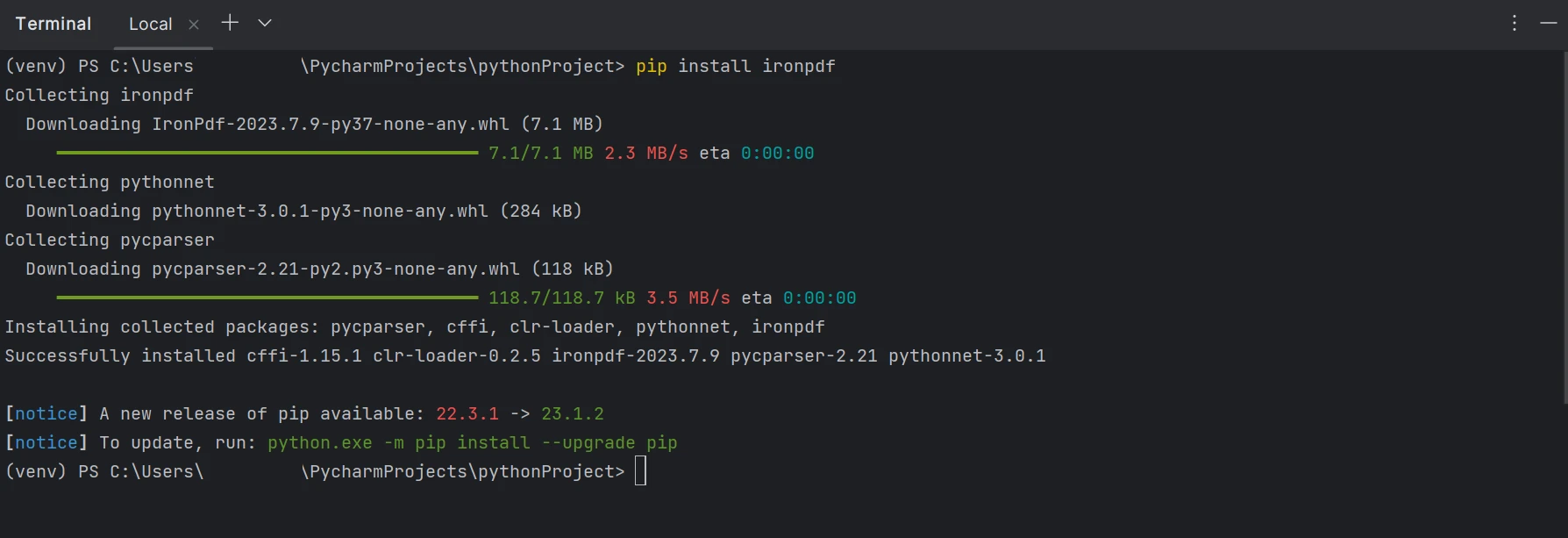 IronPDFのインストール
IronPDFのインストール
4. PDFファイルからテキストを抽出
IronPDF for Pythonライブラリは、PDFページをPDFページオブジェクトに効果的に変換し、PDFファイルからテキストコンテンツを抽出するプロセスを簡素化します。
4.1 PDFファイルから全テキストデータを抽出
この例では、IronPDFを使用して既存のPDFからテキストを抽出するプロセスが示されています。 このケースでは、以下のPDFドキュメントがこのデモンストレーションのために使用されます。
最初の方法は、PDFファイルからすべてのテキストを抽出することに焦点を当てています。以下のコードを書いて、入力PDFで完全なデータ抽出を簡単に行います。
from ironpdf import *
# Load a PDF document from a file
pdf = PdfDocument.FromFile("sampleData.pdf")
# Extract all text from the PDF document
all_text = pdf.ExtractAllText()from ironpdf import *
# Load a PDF document from a file
pdf = PdfDocument.FromFile("sampleData.pdf")
# Extract all text from the PDF document
all_text = pdf.ExtractAllText()上記のコードで示されているように、FromFileメソッドは重要な役割を果たします。 PDFファイルを既存の場所から読み込み、PdfDocumentオブジェクトに変換します。 このオブジェクトを使うことで、PDFページ内のテキストコンテンツや画像にアクセスできます。 指定されたPDFファイルからすべてのテキストを抽出するには、ExtractAllTextというメソッドを使用します。 抽出されたテキストは文字列として保存され、さらに処理のために準備されます。
4.2 ページごとのテキスト抽出
以下は、PDFファイルの各ページからテキストを明示的に抽出する第2のアプローチのコードです。
from ironpdf import *
# Load a PDF document from a file
pdf = PdfDocument.FromFile("sampleData.pdf")
# Iterate over each page and extract text
for xpage in range(pdf.PageCount):
# Extract text from the current page
print(pdf.ExtractTextFromPage(xpage))from ironpdf import *
# Load a PDF document from a file
pdf = PdfDocument.FromFile("sampleData.pdf")
# Iterate over each page and extract text
for xpage in range(pdf.PageCount):
# Extract text from the current page
print(pdf.ExtractTextFromPage(xpage))このサンプルコードは最初にPDFファイル全体をロードし、pdfと呼ばれます。 PDFファイルの各特定のページが順次処理されることを確実にするために、pdfオブジェクト内のページ番号またはページインデックスを使用して各ページにアクセスします。 最初にこれを行うには、入力PDFに存在するページの総数がPageCountメソッドを使用して決定されます。
このページ数を使って、ExtractTextFromPage関数が呼び出されます。 抽出されたテキストは文字列変数に保存されるか、ユーザースクリーンに表示することができます。 したがって、この方法では、各PDFページからのテキストの整理された抽出が可能になります。 これらの方法は、PDFタスクのために設計されたPythonライブラリであるIronPDFから、PDFファイルからのテキスト抽出を簡単かつ完全に行う能力を際立たせています。 このアクセスのしやすさは、多くの実用的なアプリケーションを持ち、さまざまな分野でのPDFの有用性を向上させます。
5. 結論
IronPDFライブラリは、潜在的なリスクを軽減し、データの安全性を確保するための強力なセキュリティ対策を組み込んでいます。 特定の制限なしに、すべての広く使用されているブラウザ上で効果的に動作します。 IronPDFは、最小限 for PythonコードでPDFドキュメントを効率的に生成および解析する力を開発者に与えます。 開発者のさまざまなニーズに応えるために、IronPDFライブラリは無料の開発者ライセンスと購入可能な補足的な開発ライセンスを含む一連のライセンスオプションを提供しています。
Lite パッケージは$799の費用で、永続ライセンスを提供します。 さらに30日間の返金保証、1年間のソフトウェア保守、更新を受けるチャンスがあります。 購入後、追加の料金は発生しません。 このライセンスは、プロダクション、ステージング、および開発に使用できます。 IronPDFはまた、時間および共有の制限がある無料ライセンスも提供しています。 30日間ウォーターマークなしで試すことができます。 IronPDFの試用版の費用と取得方法については、IronPDFのライセンスページをご覧ください。
よくある質問
Pythonを使用してPDFファイルからデータを抽出するにはどうしたらよいですか?
IronPDFを使用してPythonでPDFファイルからデータを抽出できます。PdfDocument.FromFile()メソッドを使用してPDFを読み込み、ExtractAllText()またはExtractTextFromPage()メソッドを使用してテキストデータを取得します。
PythonプロジェクトにIronPDFをセットアップする手順は何ですか?
PythonプロジェクトにIronPDFをセットアップするには、まずPythonをインストールして仮想環境を設定します。その後、コマンドpip install ironpdfを使用してIronPDFライブラリをインストールします。システムに.NET 6.0ランタイムがインストールされていることを確認してください。
PythonでHTMLコンテンツをPDFに変換できますか?
はい、IronPDFを使用するとPythonでHTMLコンテンツをPDFに変換できます。RenderUrlAsPdf()またはRenderHtmlAsPdf()メソッドを使用して、ウェブページやHTML文字列をPDFドキュメントに変換できます。
IronPDFはPDFフォームの作成と管理をサポートしていますか?
IronPDFはインタラクティブなPDFフォームの作成と管理をサポートしています。フォームをプログラム上で記入し、送信することでPDFドキュメントのインタラクティブ性を向上させることができます。
IronPDFをPythonのWebフレームワークと統合するにはどうすればよいですか?
IronPDFはDjangoやFlaskといった人気のあるPythonのWebフレームワークと統合できます。この統合により、ウェブアプリケーションから動的にPDFを生成でき、Web開発の能力を向上させます。
IronPDFはPythonでのPDF操作のためにどのような機能を提供していますか?
IronPDFは、テキストおよび画像の抽出、PDFの分割と結合、HTMLや画像のPDFへの変換、インタラクティブフォームのサポートなどの機能を提供します。また、PDFのカスタマイズやセキュリティ管理も可能です。
IronPDFを使用するためのライセンスオプションはどのようなものがありますか?
IronPDFは、無料の開発者ライセンスや、さまざまな開発・展開のニーズに応じた有料ライセンスを提供しています。
PythonでIronPDFを使用してPDFから画像を抽出することは可能ですか?
はい、必要に応じて保存または操作するために、PDFページ内の画像データにアクセスすることで、IronPDFを使用してPDFから画像を抽出できます。
Python環境でIronPDFを実行するためのシステム要件は何ですか?
PythonでIronPDFを実行するには、システムに.NET 6.0ランタイムをインストールする必要があります。この要件はLinuxおよびMacOSユーザーにとって特に重要です。
Pythonで生成されたPDFへの安全なアクセスをどのように保証できますか?
IronPDFを使用すると、PDFにパスワードプロテクションや暗号化などのセキュリティ対策を実装し、機密情報を保護しつつ安全にアクセスできるようにします。
















