
PythonでPDFから画像を抽出する方法
この記事では、IronPDF for Pythonを使用して、Pythonコードを使いPDFファイルから画像を抽出します。
IronPDF for Python
IronPDF for Pythonは最先端で強力なライブラリであり、PythonにおけるPDFドキュメントの取り扱いに新たな次元をもたらします。 PDFタスクの包括的なソリューションとして、IronPDFはアプリケーションへの高度なPDF機能のシームレスな統合を可能にします。
IronPDFは、ゼロからPDFを作成したり、HTMLを高品質のPDFに変換したり、PDFページを結合、分割、編集するなどのアクションを通じて管理するための幅広いツールとAPIを提供します。 これらのツールはユーザーフレンドリーで効率的です。 ユーザーフレンドリーなインターフェイスと幅広いドキュメントを備えたIronPDFは、開発者に可能性を開きます。
プロフェッショナルなレポートや請求書の作成、ワークフローの自動化、ドキュメント管理のために、IronPDFはドキュメント管理と自動化の分野で貴重な資産を提供し、PythonアプリケーションでPDFの力を活用しようとする開発者にとって必須のツールです。
IronPDF for Pythonを使用してPDFから画像を抽出する方法
- PythonでPDFから画像を抽出するためにIronPDFライブラリをインストールします。
- ローカルディスクからファイルパスを使用してPDFファイルをロードするには、
PdfDocument.FromFileメソッドを使用します。 - PDFファイルから画像を抽出するには、
ExtractAllImagesメソッドを適用します。 - ループを使用して、PDFに含まれるすべての抽出された画像を反復処理します。
- 必要な画像拡張子でPDFファイルから抽出された画像を保存します。
前提条件
Pythonを使用してPDFから画像を取得する世界に入る前に、必要な前提条件をインストールしましょう。
- Python のインストール:システムにPythonインタープリターがインストールされていることを確認します。 PDFから画像を取得するプロセスにはPython 3.0以上のバージョンが必要です。 互換性のあるPythonのインストールを確認してください。
IronPDFライブラリ: IronPDFの強力な機能を活用するために、Pythonパッケージマネージャーの
pipを使用してインストールする必要があります。 コマンドラインインターフェイスを開き、次のコマンドを実行します:pip install ironpdfpip install ironpdfSHELL- 統合開発環境 (IDE): 必須ではありませんが、IDEを使用すると開発体験が大幅に向上します。 IDEはコード補完、デバッグ、よりスムーズなワークフローなどの機能を提供します。 Python開発用として非常に人気のあるIDEの一つがPyCharmです。 JetBrainsのウェブサイトからPyCharmをダウンロードしてインストールできます。
これらの前提条件が整ったら、PythonとIronPDFを使用してPDFから画像を取得するエキサイティングな世界を、ステップバイステップでガイドします。
ステップ1 新しいPythonプロジェクトの作成
以下にPyCharmで新しいPythonプロジェクトを作成する手順を示します。
- PyCharmで新しいPythonプロジェクトを開始するには、PyCharmアプリケーションを開き、トップメニューに移動します。
ファイルをクリックし、ドロップダウンメニューから新しいプロジェクトを選択します。
 PyCharm IDE
PyCharm IDE- 新しいプロジェクトをクリックすると、プロジェクト作成というタイトルの新しいウィンドウが表示されます。
このウィンドウで、上部の場所フィールドにプロジェクト名を入力します。環境を選択し、 仮想環境を使用している場合は、提供されたオプションから選択します。
 PyCharmで新しいPythonプロジェクトを作成
PyCharmで新しいPythonプロジェクトを作成- 環境を選択したら、作成ボタンをクリックしてPythonプロジェクトを作成します。
これでPythonプロジェクトが作成され、画像の抽出など、さまざまなタスクに使用する準備が整いました。
ステップ2 IronPDFのインストール
IronPDFをインストールするには、ターミナルまたは別のコマンドプロンプトを開き、コマンドpip install ironpdfを入力し、Enterキーを押してください。 ターミナルには以下の出力が表示されます。
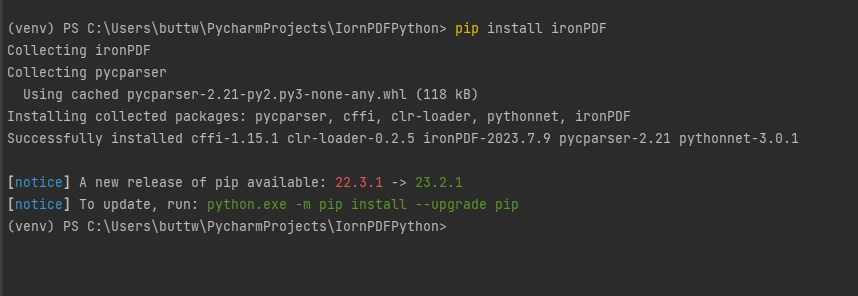 IronPDFパッケージをインストールする
IronPDFパッケージをインストールする
ステップ3 IronPDFを使用してPDFファイルから画像を抽出
IronPDFは開発者に対してPDFを操作し、埋め込まれた画像をシームレスに識別および抽出するためのツールとAPIを提供します。 分析や統合のため、IronPDFはPythonの柔軟性を活用して抽出を簡略化します。 これにより、PDFや画像ベースのアプリで作業するために不可欠です。わずか数行のコードでPDFファイルからすべての画像を抽出でき、非常にシンプルです。
次のコードでPythonプログラミング言語を使用してPDFから画像を抽出します。
from ironpdf import PdfDocument
# Open PDF file
pdf = PdfDocument.FromFile("FYP Thesis.pdf")
# Get all images found in the PDF Document
all_images = pdf.ExtractAllImages()
# Save each image to the local disk with a dynamic name
for i, image in enumerate(all_images):
image.SaveAs(f"output_image_{i}.png")from ironpdf import PdfDocument
# Open PDF file
pdf = PdfDocument.FromFile("FYP Thesis.pdf")
# Get all images found in the PDF Document
all_images = pdf.ExtractAllImages()
# Save each image to the local disk with a dynamic name
for i, image in enumerate(all_images):
image.SaveAs(f"output_image_{i}.png")このコードは最初にIronPDFライブラリをインポートし、その後、ファイルパスを使用してローカルスペースからPDFファイルをPdfDocument.FromFileメソッドでロードします。 PDFの各ページにアクセスし、Imageオブジェクトとして画像バイトを抽出します。 PDFページからのこれらの画像オブジェクトは、その後、SaveAsメソッドで保存されます。 コードは、画像インデックスと必要な画像ファイル拡張子(この例ではPNG)に基づいて動的に画像名を割り当てます。
このアプローチは、PyMuPDFやPillowなどの他 for Pythonライブラリを使用するよりも簡単で、同じタスクである画像ファイルの抽出と保存にはより多くのコードが必要です。
ステップ4 PDFファイルから画像を保存
画像はPDFファイルのすべてのページから抽出され、PNG形式で保存されます。 出力形式は、ファイル拡張子を調整することで、希望する画像ファイル形式に変更する柔軟性があります。
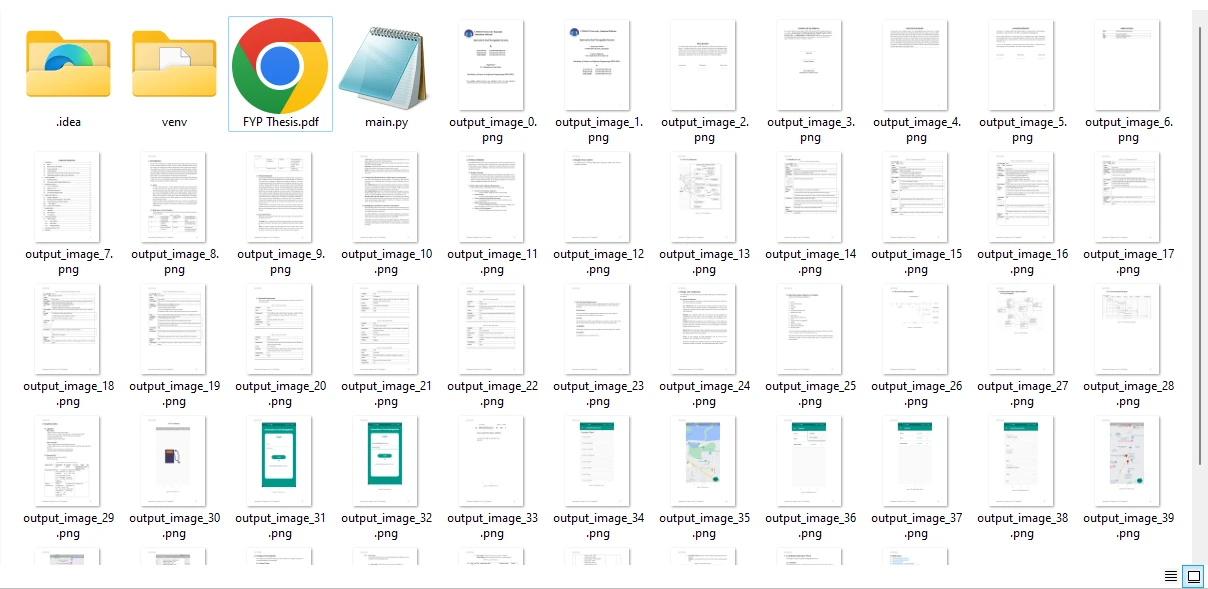 サンプルPDFファイルから抽出された画像
サンプルPDFファイルから抽出された画像
結論
Pythonと強力なIronPDFを組み合わせることで、PDFファイルから画像を取得するための多用途で効率的な解決策を提供します。 Pythonの柔軟性とIronPDFの機能を活用し、開発者はPDFドキュメントをシームレスに操作し、その中の画像バイトを見つけ、希望の画像拡張子でこれらの画像を保存できます。 プロセスは、PDFから画像を取得することを含み、生成された画像リストは、必要に応じてさらに処理および操作できます。 Pythonを使用してPDFから画像を取得する技術をマスターすることで、開発者はワークフローを強化し、ドキュメント管理を自動化し、画像ベースのアプリケーションの幅広いエクスプロレーションを行うことができ、デジタル時代において価値のあるスキルとなります。
PDFファイルから画像を抽出するためのその他の機能については、次の例をご覧ください。 PDFファイルのコンテンツを画像に変換するなどの他の操作を探ることができます。 完全なチュートリアルはこのhow-to Python記事にあります。
よくある質問
Pythonを使用してPDFから画像を抽出するにはどうすればよいですか?
IronPDF for Pythonを使用して、PdfDocument.FromFileメソッドでPDFを読み込み、ExtractAllImagesメソッドで画像を抽出できます。
Pythonを使用してPDFから抽出された画像を保存する手順は何ですか?
抽出された画像を保存するには、画像を反復処理し、SaveAsメソッドを使用して各画像をPNGなどの指定されたファイル拡張子で保存します。
PythonでPDFからの画像抽出にIronPDFを選ぶ理由は何ですか?
IronPDFはPyMuPDFやPillowのような他のライブラリと比較して画像抽出プロセスを簡素化し、同様の結果を得るために必要なコード量を減らします。
PDFを扱うためにPythonでIronPDFを使用するための要件は何ですか?
Python 3.0以降が必要で、pipを介してIronPDFライブラリをインストールします。また、PyCharmのようなIDEを使用すると開発に役立ちます。
Python用のIronPDFをどのようにインストールしますか?
IronPDFはpipパッケージマネージャーを使用してインストールできます。コマンドラインインターフェースでpip install ironpdfコマンドを実行してください。
IronPDFはPythonでのPDFドキュメント管理の自動化に使用できますか?
はい、IronPDFは画像の抽出やPDFコンテンツの変換などのドキュメント管理タスクの自動化を可能にし、ワークフローの効率を向上させます。
IronPDFが抽出された画像の保存に対応している画像フォーマットは何ですか?
抽出された画像はSaveAsメソッドで指定されたファイル拡張子によりPNGなどのフォーマットで保存できます。
IronPDFはPythonでの画像ベースのアプリケーション開発に適していますか?
IronPDFは画像ベースのアプリケーション開発に最適です。強力な機能で画像を抽出・管理できます。
















