
Python PdfWriter (Code Example Tutorial)
IronPDF は、PDF ファイルを書き込んだり、アプリケーション内で PDF ファイルを操作したりしたい Python 開発者向けの純粋な Python PDF ファイル オブジェクト ライブラリです。 IronPDF はシンプルさと汎用性が際立っており、PDF の自動作成や PDF 生成のソフトウェア システムへの統合を必要とするタスクに最適です。
このガイドでは、純粋な Python PDF ライブラリである IronPDF を使用して、PDF ファイルまたは PDF ページ属性を作成したり、PDF ファイルを読み取る方法について説明します。 例と実用的なコード スニペットが含まれており、Python プロジェクトで IronPDF for Python の PdfWriter を使用して PDF ファイルを書き込んだり、新しい PDF ページを作成したりする方法の実践的な理解が得られます。
IronPDFの設定
インストール
IronPDFを使用するには、Pythonパッケージインデックス経由でインストールする必要があります。 ターミナルで次のコマンドを実行します。
pip install ironpdf
PDFファイルの書き込みと操作
新しいPDFを作成する
IronPDF は、新しい PDF ファイルの作成と既存の PDF の操作のプロセスを簡素化します。 シンプルな 1 ページの PDF から、ユーザー パスワードなどのさまざまな要素を含む複雑なドキュメントまで、ドキュメントを生成するためのわかりやすいインターフェイスを提供します。 この機能は、レポートの生成、請求書の作成などのタスクに不可欠です。
from ironpdf import ChromePdfRenderer, License, Logger
# Set the IronPDF license key
License.LicenseKey = "Your-License-Key"
# Enable logging for debugging purposes
Logger.EnableDebugging = True
Logger.LogFilePath = "Custom.log"
Logger.LoggingMode = Logger.LoggingModes.All
# Basic HTML content for the PDF
html = """
<html>
<head>
<title>IronPDF for Python!</title>
<link rel='stylesheet' href='assets/style.css'>
</head>
<body>
<h1>It's IronPDF World!!</h1>
<a href="https://ironpdf.com/python/"><img src='assets/logo.png' /></a>
</body>
</html>
"""
# Create a PDF renderer
renderer = ChromePdfRenderer()
# Render the HTML content as a PDF
pdf = renderer.RenderHtmlAsPdf(html)
# Save the rendered PDF to a file
pdf.SaveAs("New PDF File.pdf")from ironpdf import ChromePdfRenderer, License, Logger
# Set the IronPDF license key
License.LicenseKey = "Your-License-Key"
# Enable logging for debugging purposes
Logger.EnableDebugging = True
Logger.LogFilePath = "Custom.log"
Logger.LoggingMode = Logger.LoggingModes.All
# Basic HTML content for the PDF
html = """
<html>
<head>
<title>IronPDF for Python!</title>
<link rel='stylesheet' href='assets/style.css'>
</head>
<body>
<h1>It's IronPDF World!!</h1>
<a href="https://ironpdf.com/python/"><img src='assets/logo.png' /></a>
</body>
</html>
"""
# Create a PDF renderer
renderer = ChromePdfRenderer()
# Render the HTML content as a PDF
pdf = renderer.RenderHtmlAsPdf(html)
# Save the rendered PDF to a file
pdf.SaveAs("New PDF File.pdf") 出力ファイル
出力ファイル
PDFファイルの結合
IronPDF は、複数の PDF ファイルを 1 つに結合する作業を簡素化します。 この機能は、さまざまなレポートを集約したり、スキャンしたドキュメントをまとめたり、関連する情報を整理したりするのに役立ちます。 たとえば、複数のソースから包括的なレポートを作成するときや、一連のドキュメントを 1 つのファイルとして提示する必要があるときには、PDF ファイルを結合する必要がある場合があります。
from ironpdf import PdfDocument, License, Logger
# Set the IronPDF license key
License.LicenseKey = "Your-License-Key"
# Enable logging for debugging purposes
Logger.EnableDebugging = True
Logger.LogFilePath = "Custom.log"
Logger.LoggingMode = Logger.LoggingModes.All
# Load existing PDF documents
pdfOne = PdfDocument("Report First.pdf")
pdfTwo = PdfDocument("Report Second.pdf")
# Merge the PDFs into a single document
merged = PdfDocument.Merge(pdfOne, pdfTwo)
# Save the merged PDF
merged.SaveAs("Merged.pdf")from ironpdf import PdfDocument, License, Logger
# Set the IronPDF license key
License.LicenseKey = "Your-License-Key"
# Enable logging for debugging purposes
Logger.EnableDebugging = True
Logger.LogFilePath = "Custom.log"
Logger.LoggingMode = Logger.LoggingModes.All
# Load existing PDF documents
pdfOne = PdfDocument("Report First.pdf")
pdfTwo = PdfDocument("Report Second.pdf")
# Merge the PDFs into a single document
merged = PdfDocument.Merge(pdfOne, pdfTwo)
# Save the merged PDF
merged.SaveAs("Merged.pdf")既存の PDF ファイルを新しい PDF ファイルに結合する機能は、統合された PDF ドキュメントを AI モジュールのトレーニング用のデータセットとして使用できるデータ サイエンスなどの分野でも役立ちます。 IronPDF は、元のドキュメントの各ページの整合性とフォーマットを維持しながらこのタスクを簡単に処理し、シームレスで一貫性のある出力 PDF ファイルを生成します。
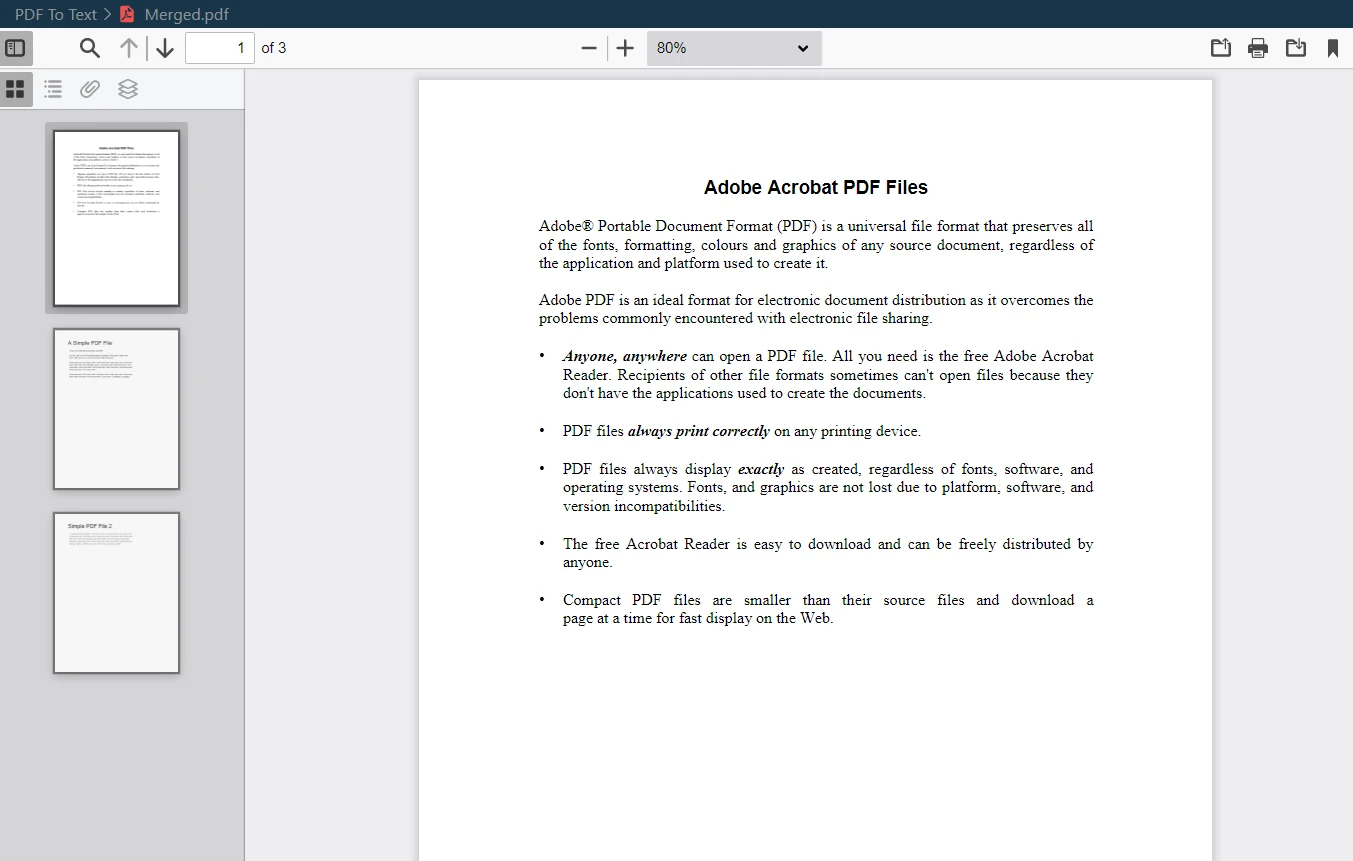 結合されたPDF出力
結合されたPDF出力
単一のPDFを分割する
逆に、IronPDF は既存の PDF ファイルを複数の新しいファイルに分割することにも優れています。 この機能は、大きな PDF ドキュメントから特定のセクションを抽出する必要がある場合や、ドキュメントをより小さく管理しやすい部分に分割する必要がある場合に便利です。
from ironpdf import PdfDocument, License, Logger
# Set the IronPDF license key
License.LicenseKey = "Your-License-Key"
# Enable logging for debugging purposes
Logger.EnableDebugging = True
Logger.LogFilePath = "Custom.log"
Logger.LoggingMode = Logger.LoggingModes.All
# Load the PDF document
pdf = PdfDocument("Report.pdf")
# Extract the first page
page1doc = pdf.CopyPage(0)
# Save the extracted page as a new PDF
page1doc.SaveAs("Split1.pdf")from ironpdf import PdfDocument, License, Logger
# Set the IronPDF license key
License.LicenseKey = "Your-License-Key"
# Enable logging for debugging purposes
Logger.EnableDebugging = True
Logger.LogFilePath = "Custom.log"
Logger.LoggingMode = Logger.LoggingModes.All
# Load the PDF document
pdf = PdfDocument("Report.pdf")
# Extract the first page
page1doc = pdf.CopyPage(0)
# Save the extracted page as a new PDF
page1doc.SaveAs("Split1.pdf")たとえば、大きなレポートから特定の PDF ページを分離したり、本の異なる章から個別のドキュメントを作成したりする必要がある場合があります。 IronPDF を使用すると、必要な複数のページを選択して新しい PDF ファイルに変換できるため、必要に応じて PDF コンテンツを操作および管理できます。
 PDF出力の分割
PDF出力の分割
セキュリティ機能の実装
機密情報や秘密情報を扱う場合、PDF ドキュメントのセキュリティ保護は最優先事項になります。 IronPDF は、ユーザー パスワードの保護や暗号化などの強力なセキュリティ機能を提供することで、このニーズに対応します。 これにより、PDF ファイルは安全に保たれ、許可されたユーザーのみがアクセスできるようになります。
from ironpdf import PdfDocument, License, Logger
# Set the IronPDF license key
License.LicenseKey = "Your-License-Key"
# Enable logging for debugging purposes
Logger.EnableDebugging = True
Logger.LogFilePath = "Custom.log"
Logger.LoggingMode = Logger.LoggingModes.All
# Load the PDF document
pdf = PdfDocument("Report.pdf")
# Adjust security settings to make the PDF read-only and set permissions
pdf.SecuritySettings.RemovePasswordsAndEncryption()
pdf.SecuritySettings.MakePdfDocumentReadOnly("secret-key")
pdf.SecuritySettings.AllowUserAnnotations = False
pdf.SecuritySettings.AllowUserCopyPasteContent = False
pdf.SecuritySettings.AllowUserFormData = False
pdf.SecuritySettings.AllowUserPrinting = PdfPrintSecurity.FullPrintRights
# Set the document encryption passwords
pdf.SecuritySettings.OwnerPassword = "top-secret" # password to edit the PDF
pdf.SecuritySettings.UserPassword = "sharable" # password to open the PDF
# Save the secured PDF
pdf.SaveAs("secured.pdf")from ironpdf import PdfDocument, License, Logger
# Set the IronPDF license key
License.LicenseKey = "Your-License-Key"
# Enable logging for debugging purposes
Logger.EnableDebugging = True
Logger.LogFilePath = "Custom.log"
Logger.LoggingMode = Logger.LoggingModes.All
# Load the PDF document
pdf = PdfDocument("Report.pdf")
# Adjust security settings to make the PDF read-only and set permissions
pdf.SecuritySettings.RemovePasswordsAndEncryption()
pdf.SecuritySettings.MakePdfDocumentReadOnly("secret-key")
pdf.SecuritySettings.AllowUserAnnotations = False
pdf.SecuritySettings.AllowUserCopyPasteContent = False
pdf.SecuritySettings.AllowUserFormData = False
pdf.SecuritySettings.AllowUserPrinting = PdfPrintSecurity.FullPrintRights
# Set the document encryption passwords
pdf.SecuritySettings.OwnerPassword = "top-secret" # password to edit the PDF
pdf.SecuritySettings.UserPassword = "sharable" # password to open the PDF
# Save the secured PDF
pdf.SaveAs("secured.pdf")ユーザー パスワードを実装することで、PDF ドキュメントを表示または編集できるユーザーを制御できます。 暗号化オプションによりセキュリティがさらに強化され、不正アクセスからデータが保護されるため、IronPDF は PDF 形式で機密情報を管理するための信頼できる選択肢となります。
PDFからテキストを抽出する
IronPDF のもう 1 つの重要な機能は、PDF ドキュメントからテキストを抽出できることです。 この機能は、データの取得、コンテンツの分析、さらには既存の PDF のテキスト コンテンツを新しいドキュメントに再利用する場合に特に役立ちます。
from ironpdf import PdfDocument, License, Logger
# Set the IronPDF license key
License.LicenseKey = "Your-License-Key"
# Enable logging for debugging purposes
Logger.EnableDebugging = True
Logger.LogFilePath = "Custom.log"
Logger.LoggingMode = Logger.LoggingModes.All
# Load the PDF document
pdf = PdfDocument("Report.pdf")
# Extract all text from the PDF document
allText = pdf.ExtractAllText()
# Extract text from a specific page in the document
specificPage = pdf.ExtractTextFromPage(3)from ironpdf import PdfDocument, License, Logger
# Set the IronPDF license key
License.LicenseKey = "Your-License-Key"
# Enable logging for debugging purposes
Logger.EnableDebugging = True
Logger.LogFilePath = "Custom.log"
Logger.LoggingMode = Logger.LoggingModes.All
# Load the PDF document
pdf = PdfDocument("Report.pdf")
# Extract all text from the PDF document
allText = pdf.ExtractAllText()
# Extract text from a specific page in the document
specificPage = pdf.ExtractTextFromPage(3)分析のためにデータを抽出する場合、大きなドキュメント内で特定の情報を検索する場合、または PDF からテキスト ファイルにコンテンツを移行してさらに処理する場合、IronPDF を使用すると簡単かつ効率的に作業できます。 ライブラリにより、抽出されたテキストは元の書式と構造を維持し、特定のニーズに合わせてすぐに使用できるようになります。
ドキュメント情報の管理
PDF の効率的な管理は、そのコンテンツだけにとどまりません。 IronPDF を使用すると、作成者名、ドキュメントのタイトル、作成日などのドキュメントのメタデータとプロパティを効果的に管理できます。 この機能は、特にドキュメントの由来とメタデータが重要な環境では、PDF ドキュメントを整理およびカタログ化するために不可欠です。
from ironpdf import PdfDocument, License, Logger
from datetime import datetime
# Set the IronPDF license key
License.LicenseKey = "Your-License-Key"
# Enable logging for debugging purposes
Logger.EnableDebugging = True
Logger.LogFilePath = "Custom.log"
Logger.LoggingMode = Logger.LoggingModes.All
# Load an existing PDF or create a new one
pdf = PdfDocument("Report.pdf")
# Edit file metadata
pdf.MetaData.Author = "Satoshi Nakamoto"
pdf.MetaData.Keywords = "SEO, Friendly"
pdf.MetaData.ModifiedDate = datetime.now()
# Save the PDF with updated metadata
pdf.SaveAs("MetaData Updated.pdf")from ironpdf import PdfDocument, License, Logger
from datetime import datetime
# Set the IronPDF license key
License.LicenseKey = "Your-License-Key"
# Enable logging for debugging purposes
Logger.EnableDebugging = True
Logger.LogFilePath = "Custom.log"
Logger.LoggingMode = Logger.LoggingModes.All
# Load an existing PDF or create a new one
pdf = PdfDocument("Report.pdf")
# Edit file metadata
pdf.MetaData.Author = "Satoshi Nakamoto"
pdf.MetaData.Keywords = "SEO, Friendly"
pdf.MetaData.ModifiedDate = datetime.now()
# Save the PDF with updated metadata
pdf.SaveAs("MetaData Updated.pdf")たとえば、学術機関や企業の環境では、文書の作成日と作成者を追跡できることは、記録の保存や文書の検索に不可欠です。 IronPDF を使用すると、この情報の管理が容易になり、Python アプリケーション内でドキュメント情報を効率的に処理および更新できるようになります。
結論
 ライセンス
ライセンス
このチュートリアルでは、PDF 操作のために Python で IronPDF を使用する基本について説明しました。 新しい PDF ファイルの作成から既存の PDF ファイルの結合、セキュリティ機能の追加まで、IronPDF はあらゆる Python 開発者にとって多目的なツールです。
IronPDF for Python には次の機能も備わっています。
- HTMLまたはURLを使用して最初から新しいPDFファイルを作成します
- 既存のPDFファイルの編集
- PDFページを回転する
- PDFファイルからテキスト、メタデータ、画像を抽出します
- パスワードと制限でPDFファイルを保護する
- PDFの分割と結合
IronPDF for Python では、ユーザーがその機能を試すことができる無料トライアルを提供しています。 トライアルを超えて継続して使用するには、ライセンスは$799から開始します。 この価格設定により、開発者はプロジェクトで IronPDF のあらゆる機能を活用できます。
よくある質問
PythonでPDFファイルを作成する方法は?
IronPDFのCreatePdfメソッドを使って新しいPDFファイルを生成できます。PythonでカスタムPDFを一から作成可能です。
Python用のIronPDFをインストールする手順は?
Python用のIronPDFをインストールするには、Pythonパッケージインデックスを使用し、以下のコマンドを実行します:pip install ironpdf。
Pythonを使用して複数のPDFを1つにマージする方法は?
IronPDFは複数のPDFファイルをマージするための機能を提供しています。複数のPDFを1つのドキュメントに結合するためにMergePdfFilesメソッドを使用できます。
IronPDFでPDFを別々のページに分割できますか?
はい、IronPDFはSplitPdf機能を提供しており、PDFを個々のページやセクションに分割し、各部分のために個別のファイルを作成することができます。
IronPDFがPDFに対してサポートするセキュリティ機能は何ですか?
IronPDFは、あなたのPDFファイルが安全で、権限のあるユーザーのみがアクセスできるようにするために、パスワード保護と暗号化を含むいくつかのセキュリティ機能をサポートしています。
PythonでPDFドキュメントからテキストを抽出する方法は?
IronPDFを使用すると、ExtractTextメソッドを使用してPDFドキュメントから簡単にテキストを抽出でき、データ取得や分析に役立ちます。
IronPDFが提供する主なPDF操作機能は何ですか?
IronPDFはPDFの作成、マージ、分割、セキュリティ対策の適用、テキストの抽出、著者名や作成日などの文書メタデータの管理を可能にします。
IronPDFの無料トライアルはありますか、どうすればアクセスできますか?
はい、IronPDFは無料トライアルを提供しています。トライアル期間中にその機能を探索することができますし、トライアル終了後の継続使用のためのライセンスも購入可能です。
PythonプロジェクトでのIronPDFの実用的な使用例は何ですか?
IronPDFは、さまざまなPythonプロジェクトでレポートの生成、請求書の作成、ドキュメントの保護、およびPDFメタデータの管理に理想的です。
IronPDFを使用してPDFメタデータを管理する方法は?
IronPDFは、文書の組織とカタログ化に重要な著者名、文書タイトル、作成日を含むPDFメタデータの管理を可能にします。
















