
Porównanie IronPDF for Java i Qoppa Software – Java PDF Library
Pliki PDF to popularny format udostępniania dokumentów i informacji. Istnieje wiele narzędzi do odczytu, wyodrębniania i manipulowania plikami PDF. Poznaj IronPDF for Java i Qoppa PDF to dwa popularne narzędzia, które deweloperzy używają do odczytu plików PDF. Ten artykuł dostarczy krok po kroku przewodnika po konwersji HTML na PDF za pomocą IronPDF w Java do czytania i manipulowania plikami PDF efektywnie, w tym przykłady kodu.
W świecie manipulacji PDF wyróżniają się dwa popularne narzędzia: IronPDF i Qoppa PDF. Oba narzędzia mają swoje unikalne cechy i możliwości, ale jeśli chodzi o wybór najlepszego narzędzia PDF, IronPDF jest na prowadzeniu.
Zacznij korzystać z IronPDF for Java jako solidnego narzędzia PDF, które jest używane do tworzenia, odczytu i manipulacji plikami PDF. Dzięki IronPDF, programiści mogą łatwo integrować funkcjonalność PDF do swoich aplikacji bez potrzeby użycia dodatkowego oprogramowania.
Natomiast Qoppa PDF to potężne narzędzie PDF, które pozwala użytkownikom tworzyć, edytować i manipulować plikami PDF. Qoppa PDF oferuje szeroki zakres funkcji, w tym podpisy cyfrowe, wypełnianie formularzy i redakcję.
1. Instalacja IronPDF i Qoppa PDF

Dowiedz się, jak zainstalować IronPDF w Java i Qoppa PDF w Java, co jest prostym procesem, który można wykonać za pomocą menedżera pakietów NuGet. Po zainstalowaniu programiści mogą używać tych potężnych bibliotek do tworzenia, edytowania i manipulowania dokumentami PDF.
1.1. Instalacja IronPDF w Java

Aby dołączyć bibliotekę IronPDF do projektu w Java, dostępne są dwie metody:
- Dodanie IronPDF jako zależności w projekcie Java skonfigurowanym za pomocą Maven.
- Pobranie pliku JAR IronPDF i ręczne dodanie go do ścieżki klas projektu.
Obie te metody instalacji będą krótko opisane w następnej sekcji.
Opcja 1: Instalacja IronPDF jako zależności Maven wymaga dodania niezbędnych artefaktów do sekcji zależności pliku pom.xml projektu Java.
<dependency>
<groupId>com.ironsoftware</groupId>
<artifactId>ironpdf</artifactId>
<version>2023.1.1</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.32</version>
</dependency><dependency>
<groupId>com.ironsoftware</groupId>
<artifactId>ironpdf</artifactId>
<version>2023.1.1</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.32</version>
</dependency>Początkowy artefakt odnosi się do najnowszej wersji biblioteki IronPDF dla Java, podczas gdy drugi artefakt odnosi się do implementacji SLF4J. Ta zależność jest niezbędna dla silnika renderującego IronPDF, aby generować komunikaty logowania podczas swojej pracy. Programiści mogą zastąpić tę zależność innymi dostawcami logowania, takimi jak Logback i Log4J, lub całkowicie je pominąć, jeśli logowanie nie jest potrzebne.
Aby uzyskać najnowszą wersję wspomnianych bibliotek, wykonaj polecenie mvn install w terminalu w katalogu głównym projektu Java.
Opcja 2: Alternatywnie, programiści, którzy nie chcą używać Maven lub innych systemów zarządzania zależnościami, mogą ręcznie pobrać plik JAR biblioteki IronPDF (wraz z opcjonalną implementacją SLF4J) i dodać go do ścieżki klas swojego projektu.
Aby pobrać plik JAR IronPDF, uzyskaj go bezpośrednio z repozytorium Maven.
1.2. Instalacja Qoppa PDF w Java

Qoppa PDF to zewnętrzna biblioteka do pracy z plikami PDF w aplikacjach Java.
Biblioteki PDF Qoppa Java są dostępne jako artefakty i są hostowane przez Qoppa Software w repozytorium Maven. Z jedynie niewielką modyfikacją pliku POM, można łatwo zintegrować funkcje Qoppa PDF do swoich projektów i aplikacji Maven.
Szczegóły repozytorium Maven Qoppa i publikowane zależności artefaktów można zobaczyć poniżej.
Ustawienia repozytorium Qoppa i lokalizacja do włączenia w pliku Maven pom.xml są następujące:
<repositories>
<repository>
<id>QoppaSoftware</id>
<name>Qoppa Software</name>
<url>http://download.qoppa.com/maven</url>
</repository>
</repositories><repositories>
<repository>
<id>QoppaSoftware</id>
<name>Qoppa Software</name>
<url>http://download.qoppa.com/maven</url>
</repository>
</repositories>Jednym z alternatywnych sposobów dla repozytorium Maven Qoppa Software jest dodanie jednego z plików JAR Qoppa jako pliku lokalnego do projektu Maven. Na przykład, jeśli chcesz dodać jPDFEditor jako lokalny JAR, zapiszesz plik w podanej ścieżce systemowej, takiej jak $project.basedir/src/main/resources/, a następnie dodasz jPDFEditor używając poniżej wymienionej zależności.
<dependencies>
<dependency>
<groupId>com.qoppa</groupId>
<artifactId>jPDFEditor</artifactId>
<version>2021R1.01</version>
<scope>system</scope>
<systemPath>${project.basedir}/src/main/resources/jPDFEditor.jar</systemPath>
</dependency>
</dependencies><dependencies>
<dependency>
<groupId>com.qoppa</groupId>
<artifactId>jPDFEditor</artifactId>
<version>2021R1.01</version>
<scope>system</scope>
<systemPath>${project.basedir}/src/main/resources/jPDFEditor.jar</systemPath>
</dependency>
</dependencies>2. Przetwarzanie PDF z IronPDF
2.1. Manipulacja PDF za pomocą IronPDF
IronPDF to potężne narzędzie, które zapewnia programistom możliwość przetwarzania i manipulowania dokumentami PDF, przy respektowaniu przepływów pracy z dokumentem. W swojej najnowszej wersji narzędzie to zapewnia użytkownikom końcowym różnorodne komponenty i funkcje wspierające ich potrzeby dotyczące odczytu i zapisu plików PDF. W tym artykule przedstawimy, jak czytać i zapisywać pliki PDF za pomocą IronPDF.
Aby rozpocząć, programiści muszą najpierw zainstalować IronPDF for Java, a następnie zaimportować niezbędne klasy i zacząć czytać pliki PDF.
2.2. Odczyt plików PDF za pomocą IronPDF
Po zainstalowaniu IronPDF możemy użyć jego klas oraz parserów Apache Tika w naszym projekcie. Aby odczytać istniejący plik PDF w Java, możemy użyć poniższego kodu:
import com.ironsoftware.ironpdf.*;
public class ReadPDFExample {
public static void main(String[] args) {
// Load the PDF document
PdfDocument pdf = PdfDocument.fromFile(Paths.get("assets/sample.pdf"));
// Extract all the text from the document
String text = pdf.extractAllText();
// Output the extracted text
System.out.println(text);
}
}import com.ironsoftware.ironpdf.*;
public class ReadPDFExample {
public static void main(String[] args) {
// Load the PDF document
PdfDocument pdf = PdfDocument.fromFile(Paths.get("assets/sample.pdf"));
// Extract all the text from the document
String text = pdf.extractAllText();
// Output the extracted text
System.out.println(text);
}
}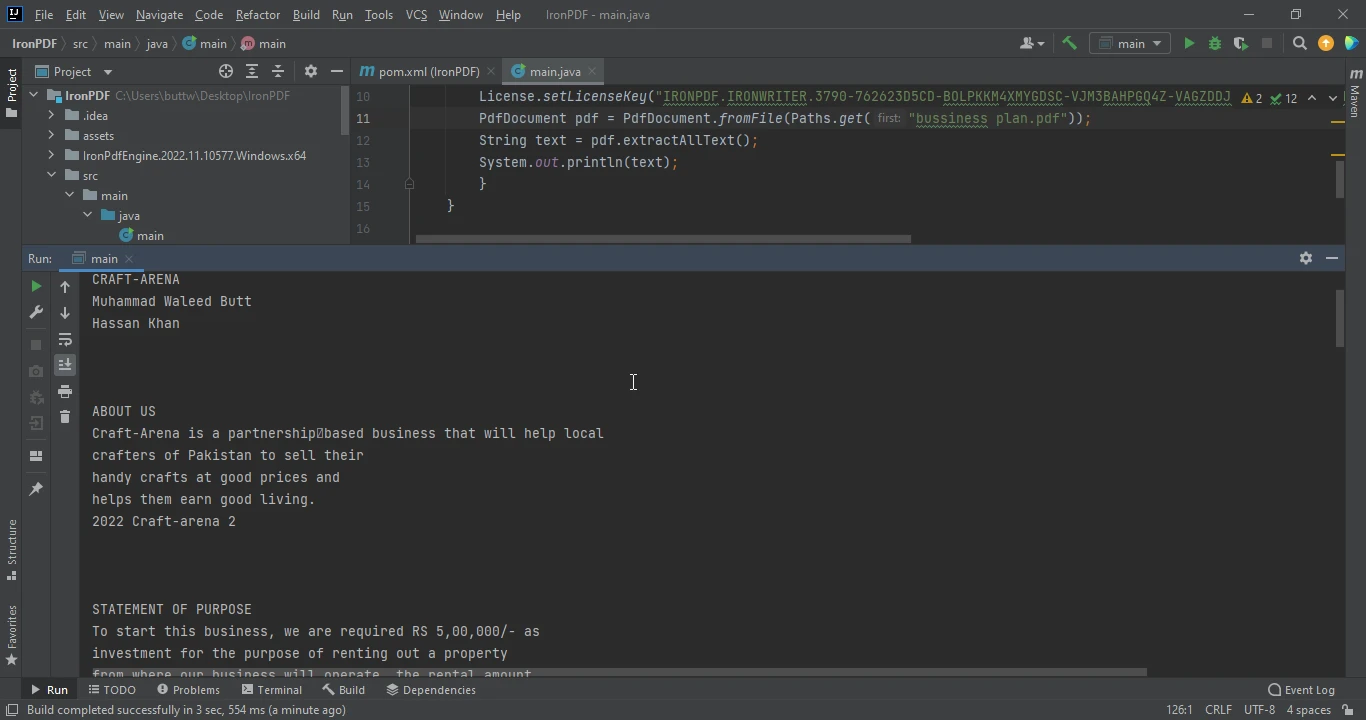
W tym kodzie PdfDocument.fromFile otwiera dokument PDF, a Paths.get pobiera ścieżkę pliku. Metoda extractAllText odczytuje cały tekst w dokumencie.
2.3. Czytanie tekstu z konkretnej strony
Aby czytać tekst z konkretnej strony, możemy użyć metody extractTextFromPage. Na przykład, aby wyodrębnić tekst z drugiej strony dokumentu PDF, możemy użyć poniższego kodu:
public class ReadSpecificPageExample {
public static void main(String[] args) {
// Load the PDF document
PdfDocument pdf = PdfDocument.fromFile(Paths.get("assets/sample.pdf"));
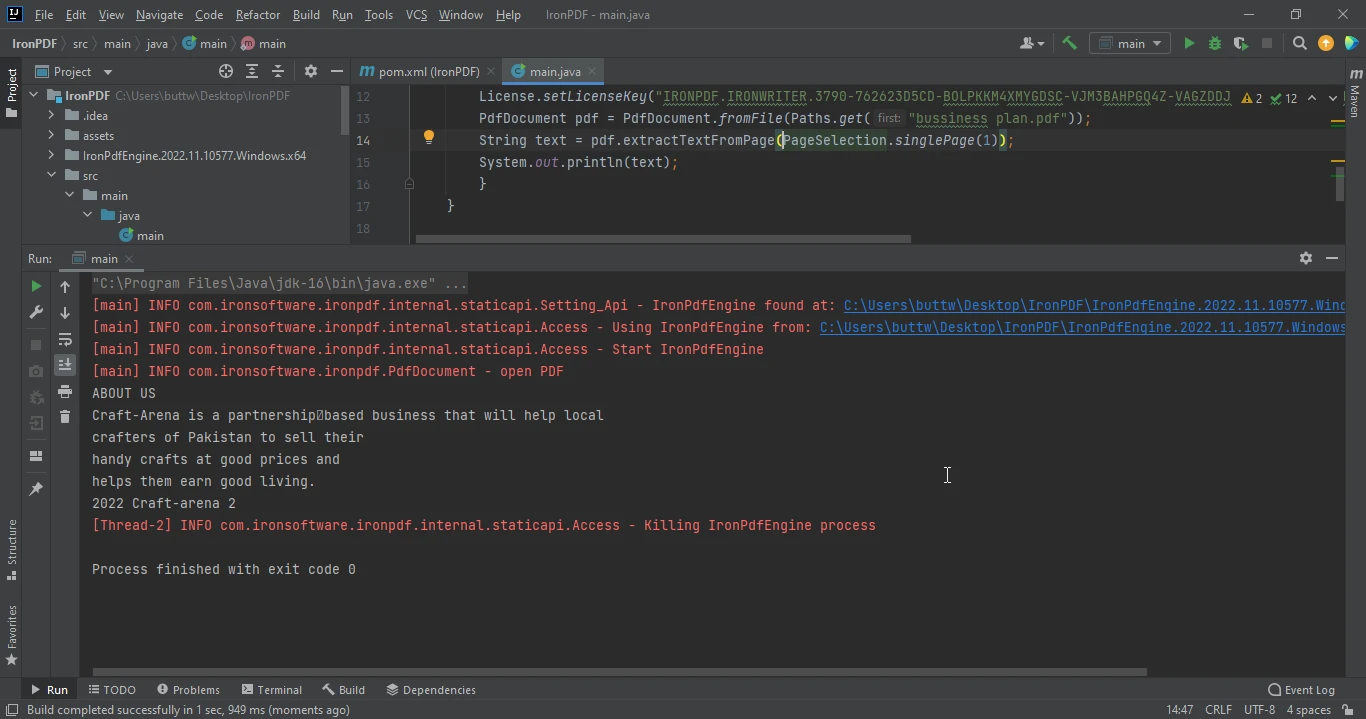
// Extract text from the second page (page index starts at 0)
String text = pdf.extractTextFromPage(PageSelection.singlePage(1));
// Output the extracted text from the specific page
System.out.println(text);
}
}public class ReadSpecificPageExample {
public static void main(String[] args) {
// Load the PDF document
PdfDocument pdf = PdfDocument.fromFile(Paths.get("assets/sample.pdf"));
// Extract text from the second page (page index starts at 0)
String text = pdf.extractTextFromPage(PageSelection.singlePage(1));
// Output the extracted text from the specific page
System.out.println(text);
}
}IronPDF dostarcza inne metody w klasie PageSelection, które można wykorzystać do wyodrębnienia tekstu z różnych stron, takich jak firstPage, lastPage, pageRange, i allPages.
WYNIK
2.4. URL do PDF
Możemy również użyć IronPDF do konwersji strony internetowej na PDF, a następnie wyodrębnić z niej tekst. Poniższy kod generuje PDF z URL i wyodrębnia cały tekst ze strony internetowej:
public class UrlToPdfExample {
public static void main(String[] args) {
// Render the website as a PDF
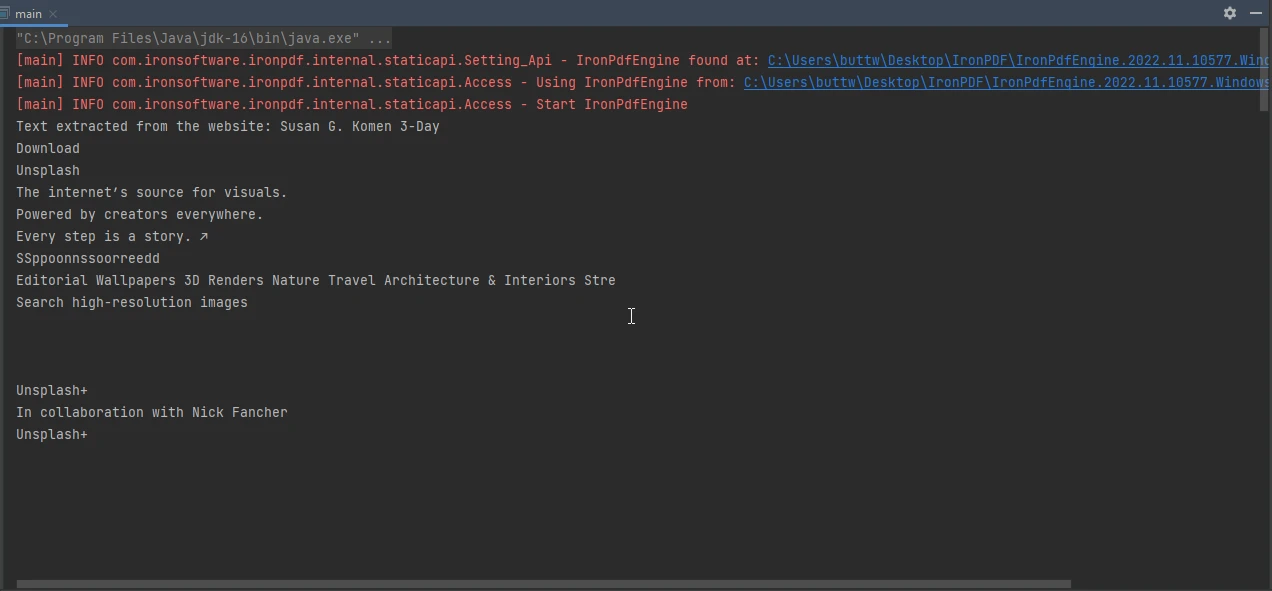
PdfDocument pdf = PdfDocument.renderUrlAsPdf("https://unsplash.com/");
// Extract all text from the generated PDF
String text = pdf.extractAllText();
// Output the extracted text
System.out.println("Text extracted from the website: " + text);
}
}public class UrlToPdfExample {
public static void main(String[] args) {
// Render the website as a PDF
PdfDocument pdf = PdfDocument.renderUrlAsPdf("https://unsplash.com/");
// Extract all text from the generated PDF
String text = pdf.extractAllText();
// Output the extracted text
System.out.println("Text extracted from the website: " + text);
}
}
2.5. Wyodrębnianie obrazów z PDF
Dodatkowo, IronPDF można używać do wyodrębniania obrazów z plików PDF. Poniższy kod demonstruje proces wyodrębniania obrazów:
import com.ironsoftware.ironpdf.License;
import com.ironsoftware.ironpdf.PdfDocument;
import java.awt.image.BufferedImage;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
import java.util.List;
import javax.imageio.ImageIO;
public class ExtractImagesExample {
public static void main(String[] args) throws IOException {
// Set the IronPDF license key
License.setLicenseKey("YOUR LICENSE KEY HERE");
// Load the PDF document
PdfDocument pdf = PdfDocument.fromFile(Paths.get("assets/sample.pdf"));
try {
// Extract all images from the PDF document
List<BufferedImage> images = pdf.extractAllImages();
// Output number of images extracted
System.out.println("Number of images extracted from the website: " + images.size());
// Save each extracted image to a file
int i = 0;
for (BufferedImage image : images) {
ImageIO.write(image, "PNG", Files.newOutputStream(Path.of("assets/extracted_" + ++i + ".png")));
}
} catch (Exception exception) {
System.out.println("Failed to extract images from the website");
exception.printStackTrace();
}
}
}import com.ironsoftware.ironpdf.License;
import com.ironsoftware.ironpdf.PdfDocument;
import java.awt.image.BufferedImage;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
import java.util.List;
import javax.imageio.ImageIO;
public class ExtractImagesExample {
public static void main(String[] args) throws IOException {
// Set the IronPDF license key
License.setLicenseKey("YOUR LICENSE KEY HERE");
// Load the PDF document
PdfDocument pdf = PdfDocument.fromFile(Paths.get("assets/sample.pdf"));
try {
// Extract all images from the PDF document
List<BufferedImage> images = pdf.extractAllImages();
// Output number of images extracted
System.out.println("Number of images extracted from the website: " + images.size());
// Save each extracted image to a file
int i = 0;
for (BufferedImage image : images) {
ImageIO.write(image, "PNG", Files.newOutputStream(Path.of("assets/extracted_" + ++i + ".png")));
}
} catch (Exception exception) {
System.out.println("Failed to extract images from the website");
exception.printStackTrace();
}
}
}
3. Manipulacja plikami PDF za pomocą Qoppa PDF
Qoppa PDF to popularne narzędzie do przetwarzania PDF, które oferuje użytkownikom potężny zestaw komponentów do pracy z plikami PDF. W tym artykule zbadamy, jak czytać i zapisywać pliki PDF za pomocą Qoppa PDF w Java.
Aby rozpocząć, programiści muszą najpierw pobrać plik JAR Qoppa PDF i dodać go do ścieżki klas swojego projektu. Po dodaniu pliku JAR programiści mogą zaimportować niezbędne klasy i zacząć czytać pliki PDF.

3.1. Odczyt plików PDF za pomocą Qoppa PDF
Odczyt plików PDF za pomocą Qoppa PDF w Java można zrealizować przy użyciu poniższego przykładowego kodu:
import com.qoppa.pdf.PDFImages;
import java.awt.Color;
import java.awt.Graphics2D;
import java.awt.image.BufferedImage;
import java.awt.Font;
import java.io.File;
import javax.imageio.ImageIO;
public class ReadPdfWithQoppa {
public static void main(String[] args) {
try {
// Load the document
PDFImages pdfDoc = new PDFImages("input.pdf", null);
// Loop through pages
for (int count = 0; count < pdfDoc.getPageCount(); ++count) {
// Get an image of the PDF page at a resolution of 150 DPI
BufferedImage pageImage = pdfDoc.getPageImage(count, 150);
// Create a Graphics 2D from the page image
Graphics2D g2d = pageImage.createGraphics();
// Modify BufferedImage using drawing functions available in Graphics2D
// Here is an example on how to add a watermark
g2d.setFont(new Font("sansserif", Font.PLAIN, 200));
g2d.rotate(Math.toRadians(45));
g2d.setColor(new Color(128, 128, 128, 128));
g2d.drawString("Watermark", 300, g2d.getFontMetrics().getMaxDescent());
// Save the image as a JPEG
File outputFile = new File("output_" + count + ".jpg");
ImageIO.write(pageImage, "JPEG", outputFile);
System.out.println("Page " + count + " processed.");
}
} catch (Exception e) {
e.printStackTrace();
}
}
}import com.qoppa.pdf.PDFImages;
import java.awt.Color;
import java.awt.Graphics2D;
import java.awt.image.BufferedImage;
import java.awt.Font;
import java.io.File;
import javax.imageio.ImageIO;
public class ReadPdfWithQoppa {
public static void main(String[] args) {
try {
// Load the document
PDFImages pdfDoc = new PDFImages("input.pdf", null);
// Loop through pages
for (int count = 0; count < pdfDoc.getPageCount(); ++count) {
// Get an image of the PDF page at a resolution of 150 DPI
BufferedImage pageImage = pdfDoc.getPageImage(count, 150);
// Create a Graphics 2D from the page image
Graphics2D g2d = pageImage.createGraphics();
// Modify BufferedImage using drawing functions available in Graphics2D
// Here is an example on how to add a watermark
g2d.setFont(new Font("sansserif", Font.PLAIN, 200));
g2d.rotate(Math.toRadians(45));
g2d.setColor(new Color(128, 128, 128, 128));
g2d.drawString("Watermark", 300, g2d.getFontMetrics().getMaxDescent());
// Save the image as a JPEG
File outputFile = new File("output_" + count + ".jpg");
ImageIO.write(pageImage, "JPEG", outputFile);
System.out.println("Page " + count + " processed.");
}
} catch (Exception e) {
e.printStackTrace();
}
}
}3.2. Zapis plików PDF za pomocą Qoppa PDF
Zapis plików PDF za pomocą Qoppa PDF w Java można wykonać przy użyciu ich API:
/*
* This sample Java program uses jPDFWriter
* to create a new PDF file, add a page to it
* and draw an image and text on the page.
*/
package jPDFWriterSamples;
import java.awt.Color;
import java.awt.image.BufferedImage;
import java.awt.print.PageFormat;
import java.awt.print.Paper;
import java.io.File;
import javax.imageio.ImageIO;
import com.qoppa.pdfWriter.PDFDocument;
import com.qoppa.pdfWriter.PDFGraphics;
import com.qoppa.pdfWriter.PDFPage;
public class CreatePDFWithTextAndImage {
public static void main(String [] args) {
try {
// Create a new PDF document
PDFDocument pdfDoc = new PDFDocument();
// Create a PageFormat of standard letter size with no margins
Paper paper = new Paper();
paper.setSize(8.5 * 72, 11 * 72);
paper.setImageableArea(0, 0, 8.5 * 72, 11 * 72);
PageFormat pf = new PageFormat();
pf.setPaper(paper);
// Create a new page and add it to the PDF
PDFPage page = pdfDoc.createPage(pf);
pdfDoc.addPage(page);
// Get graphics from the page to draw content
PDFGraphics g2d = (PDFGraphics) page.createGraphics();
// Read an image (could be png, jpg, etc.)
BufferedImage image = ImageIO.read(new File("C:\\photo.jpg"));
// Draw the image on the page
g2d.drawImage(image, 0, 0, null);
// Set the font and color for the text
g2d.setFont(PDFGraphics.HELVETICA.deriveFont(24f));
g2d.setColor(Color.BLUE);
// Draw text on the graphics object of the page
g2d.drawString("NEW TEXT", 200, 30);
// Save the document to a file
pdfDoc.saveDocument("C:\\output.pdf");
System.out.println("PDF created successfully.");
} catch (Throwable t) {
System.out.println("Error creating PDF.");
t.printStackTrace();
}
}
}/*
* This sample Java program uses jPDFWriter
* to create a new PDF file, add a page to it
* and draw an image and text on the page.
*/
package jPDFWriterSamples;
import java.awt.Color;
import java.awt.image.BufferedImage;
import java.awt.print.PageFormat;
import java.awt.print.Paper;
import java.io.File;
import javax.imageio.ImageIO;
import com.qoppa.pdfWriter.PDFDocument;
import com.qoppa.pdfWriter.PDFGraphics;
import com.qoppa.pdfWriter.PDFPage;
public class CreatePDFWithTextAndImage {
public static void main(String [] args) {
try {
// Create a new PDF document
PDFDocument pdfDoc = new PDFDocument();
// Create a PageFormat of standard letter size with no margins
Paper paper = new Paper();
paper.setSize(8.5 * 72, 11 * 72);
paper.setImageableArea(0, 0, 8.5 * 72, 11 * 72);
PageFormat pf = new PageFormat();
pf.setPaper(paper);
// Create a new page and add it to the PDF
PDFPage page = pdfDoc.createPage(pf);
pdfDoc.addPage(page);
// Get graphics from the page to draw content
PDFGraphics g2d = (PDFGraphics) page.createGraphics();
// Read an image (could be png, jpg, etc.)
BufferedImage image = ImageIO.read(new File("C:\\photo.jpg"));
// Draw the image on the page
g2d.drawImage(image, 0, 0, null);
// Set the font and color for the text
g2d.setFont(PDFGraphics.HELVETICA.deriveFont(24f));
g2d.setColor(Color.BLUE);
// Draw text on the graphics object of the page
g2d.drawString("NEW TEXT", 200, 30);
// Save the document to a file
pdfDoc.saveDocument("C:\\output.pdf");
System.out.println("PDF created successfully.");
} catch (Throwable t) {
System.out.println("Error creating PDF.");
t.printStackTrace();
}
}
}4. Dlaczego wybrać IronPDF zamiast Qoppa PDF
Chociaż oba narzędzia są użyteczne, IronPDF ma przewagę pod względem łatwości użycia i funkcjonalności. Oto niektóre powody, dla których IronPDF jest najlepszym wyborem do manipulacji plikami PDF:
4.1. Prostota
Jedną z głównych zalet IronPDF jest jego prostota. IronPDF posiada prostą w użyciu API, która jest łatwa do zastosowania nawet dla początkujących. Programiści mogą z łatwością tworzyć i modyfikować dokumenty PDF przy użyciu zaledwie kilku linii kodu. W przeciwieństwie do tego, Qoppa PDF posiada bardziej skomplikowaną API, która może odstraszać nowych użytkowników.
4.2. Zgodność
IronPDF jest kompatybilny z szerokim zakresem platform i frameworków, w tym Java, .NET, ASP.NET, i .NET Core. IronPDF również obsługuje szereg formatów plików, takich jak HTML, CSS i SVG. To sprawia, że jest łatwy do zintegrowania z istniejącymi aplikacjami.
W przeciwieństwie do tego, Qoppa PDF ma ograniczoną kompatybilność z innymi platformami niż Java. Może to stanowić problem dla deweloperów pracujących z innymi językami programowania.
4.3. Wydajność
IronPDF jest zaprojektowany tak, aby był szybki i wydajny, nawet podczas pracy z dużymi dokumentami PDF. IronPDF używa zoptymalizowanych algorytmów, aby zapewnić szybkie i płynne przetwarzanie PDF. Jest to szczególnie ważne dla aplikacji, które muszą obsługiwać dużą liczbę plików PDF.
Wydajność IronPDF jest imponująca, nawet podczas pracy z dużymi plikami PDF. Jest to zasługa zoptymalizowanych algorytmów i efektywnego zarządzania pamięcią IronPDF.
5. Cennik i licencjonowanie
Jeśli chodzi o cennik i licencjonowanie, IronPDF i Qoppa PDF mają różne podejścia. W tym artykule porównamy cennik i licencjonowanie obu narzędzi i preferencję damy IronPDF.
5.1. Cennik i licencjonowanie IronPDF
IronPDF oferuje prosty i przejrzysty model cenowy oparty na liczbie deweloperów korzystających z narzędzia. Możesz kupić licencję dla jednego dewelopera, zespołu deweloperów lub przedsiębiorstwa z nieograniczoną liczbą deweloperów.
Z zakupem licencji, możesz używać IronPDF w dowolnej liczbie projektów, a także otrzymasz bezpłatne aktualizacje i wsparcie techniczne przez rok. Po pierwszym roku możesz zdecydować się na odnowienie licencji po obniżonej cenie.
5.2. Cennik i licencjonowanie Qoppa PDF
Qoppa PDF oferuje różnorodne opcje licencjonowania, w tym licencje wieczyste, roczne i subskrypcyjne.
Pod względem cennika i licencjonowania, IronPDF oferuje prostsze i bardziej przejrzyste podejście. Cena jest ustalona na podstawie liczby deweloperów korzystających z narzędzia, i nie ma żadnych ukrytych opłat ani dodatkowych kosztów.

6. Podsumowanie
Podsumowując, IronPDF to najlepszy wybór dla manipulacji plikami PDF. Prostota, zgodność i wydajność IronPDF sprawiają, że jest to potężne narzędzie dla deweloperów, którzy potrzebują pracy z dokumentami PDF. Choć Qoppa PDF ma swoje unikalne cechy, IronPDF oferuje lepszy całościowy pakiet do manipulacji PDF. IronPDF zapewnia obszerne dokumentacje i wsparcie, co ułatwia deweloperom naukę i używanie narzędzia. IronPDF jest również wysoce kompatybilny z szerokim zakresem platform i frameworków, co czyni go wszechstronnym narzędziem dla deweloperów.
Z drugiej strony, Qoppa PDF jest zaprojektowany z myślą o elastyczności i łatwości użycia, oferujący szeroki zakres opcji dostosowywania, które pozwalają programistom dostosować bibliotekę do swoich specyficznych potrzeb. Jego zaawansowane funkcje, takie jak obsługa PDF 3D, OCR i rozpoznawanie pól formularzy, czynią go wszechstronnym narzędziem do pracy z złożonymi dokumentami PDF.
Jeśli szukasz niezawodnego i wydajnego narzędzia do manipulacji PDF, IronPDF to właściwy wybór.
Pakiety IronPDF oferują konkurencyjne licencje i wsparcie bez żadnych kosztów bieżących. IronPDF wspiera także wiele platform w jednej cenie!
Jeśli nie jesteś jeszcze klientem IronPDF, możesz uzyskać bezpłatną wersję próbną IronPDF, aby wypróbować wszystkie dostępne funkcje. Jeśli kupisz pełną Iron Suite, możesz dostać wszystkie pięć produktów w cenie dwóch. Aby uzyskać więcej szczegółów dotyczących licencjonowania IronPDF, proszę skorzystać z szczegółowego przeglądu pakietu, aby zobaczyć pełne informacje o pakiecie.
Qoppa PDF jest zarejestrowanym znakiem towarowym swojego właściciela. Ta strona nie jest powiązana z, popierana ani sponsorowana przez Qoppa PDF. Wszystkie nazwy produktów, logo i marki są własnością ich odpowiednich właścicieli. Porównania mają charakter wyłącznie informacyjny i odzwierciedlają informacje dostępne publicznie w momencie pisania.)}]
Często Zadawane Pytania
Jakie są główne różnice między IronPDF a Qoppa PDF?
IronPDF znany jest ze swojej prostoty i kompatybilności z wieloma platformami, takimi jak Java, .NET i ASP.NET, podczas gdy Qoppa PDF jest zorientowany głównie na Javę. IronPDF oferuje również proste API i jest zoptymalizowany pod kątem szybkości, efektywnie obsługując duże dokumenty PDF.
Jak przekonwertować HTML na PDF w Javie?
Możesz użyć IronPDF do konwersji HTML na PDF w Javie, korzystając z metod przeznaczonych do konwersji HTML na PDF. IronPDF udostępnia przewodniki krok po kroku oraz przykładowy kod, aby ułatwić ten proces.
Czy mogę wyodrębnić tekst i obrazy z plików PDF za pomocą IronPDF?
Tak, IronPDF umożliwia wyodrębnianie zarówno tekstu, jak i obrazów z plików PDF. Oferuje funkcje pozwalające na skuteczne wyodrębnianie tekstu oraz narzędzia do wyodrębniania obrazów i zapisywania ich osobno.
Czy IronPDF można łatwo zintegrować z projektami Java?
Tak, IronPDF można łatwo zintegrować z projektami Java, dodając go jako zależność Maven lub ręcznie włączając plik JAR do ścieżki klasy projektu.
Jakie modele cenowe są dostępne dla IronPDF?
IronPDF oferuje przejrzysty i elastyczny model cenowy oparty na liczbie programistów. Dostępne są licencje dla pojedynczych programistów, zespołów lub przedsiębiorstw, bez ukrytych kosztów.
Czy IronPDF oferuje jakieś zaawansowane funkcje związane z plikami PDF?
Chociaż IronPDF wyróżnia się prostotą i wydajnością, oferuje również funkcje konwersji HTML do PDF, wyodrębniania tekstu i obsługi obrazów. Nie skupia się jednak na zaawansowanych funkcjach, takich jak pliki PDF 3D i OCR, które oferuje Qoppa.
Czy mogę wypróbować IronPDF przed zakupem?
Tak, IronPDF oferuje bezpłatną wersję próbną, która pozwala użytkownikom zapoznać się z jego funkcjami. Ta wersja próbna pomaga programistom ocenić produkt przed podjęciem decyzji o zakupie.
Dlaczego programiści mieliby wybrać IronPDF zamiast Qoppa PDF?
Programiści mogą wybrać IronPDF zamiast Qoppa PDF ze względu na łatwość obsługi, kompatybilność międzyplatformową, wydajność i proste API. IronPDF oferuje również konkurencyjne ceny i solidne wsparcie techniczne, co czyni go atrakcyjną opcją dla wielu programistów.
















