Biblioteka Google HTTP Client dla języka Java (jak działa dla programistów)
Biblioteka Google HTTP Client Library dla języka Java to solidna biblioteka zaprojektowana w celu uproszczenia procesu wysyłania żądań HTTP i obsługi odpowiedzi w aplikacjach Java. Jest to część silnika aplikacji Google i klienta API Google w ramach Google Apis. Ta potężna biblioteka Java, opracowana i utrzymywana przez Google, obsługuje szeroki zakres metod HTTP i płynnie integruje się z modelami danych JSON oraz XML, co czyni ją doskonałym wyborem dla programistów pragnących współpracować z usługami internetowymi. Dodatkowo przyjrzymy się bibliotece IronPDF for Java i pokażemy, jak zintegrować ją z biblioteką Google HTTP Client Library w celu generowania dokumentów PDF na podstawie danych z odpowiedzi HTTP.
Najważniejsze cechy
- Uproszczone żądania HTTP: Biblioteka eliminuje większość złożoności związanej z tworzeniem i wysyłaniem żądań HTTP, ułatwiając programistom pracę.
- Obsługa różnych metod uwierzytelniania: Obsługuje OAuth 2.0 i inne schematy uwierzytelniania, co jest niezbędne do interakcji z nowoczesnymi interfejsami API.
- Analiza JSON i XML: Biblioteka może automatycznie analizować odpowiedzi JSON i XML na obiekty Java, ograniczając ilość kodu szablonowego.
- Żądania asynchroniczne: Obsługuje żądania asynchroniczne, co może poprawić wydajność aplikacji poprzez przeniesienie operacji sieciowych do wątków działających w tle.
- Wbudowany mechanizm ponawiania prób: Biblioteka zawiera wbudowany mechanizm ponawiania prób służący do obsługi przejściowych błędów sieciowych, co może pomóc w poprawie niezawodności aplikacji.
- Stabilność i utrzymanie: Biblioteka oferuje stabilne funkcje, które nie są w fazie beta, zapewniając niezawodną wydajność w środowiskach produkcyjnych.

Konfiguracja biblioteki Google HTTP Client dla języka Java
Aby korzystać z biblioteki Google HTTP Client Library dla języka Java, należy dodać do projektu pełną bibliotekę klienta oraz niezbędne zależności. Jeśli korzystasz z Mavena, możesz dodać następujące zależności do pliku pom.xml:
<dependencies>
<dependency>
<groupId>com.google.http-client</groupId>
<artifactId>google-http-client</artifactId>
<version>1.39.2</version>
</dependency>
<dependency>
<groupId>com.google.http-client</groupId>
<artifactId>google-http-client-jackson2</artifactId>
<version>1.39.2</version>
</dependency>
</dependencies><dependencies>
<dependency>
<groupId>com.google.http-client</groupId>
<artifactId>google-http-client</artifactId>
<version>1.39.2</version>
</dependency>
<dependency>
<groupId>com.google.http-client</groupId>
<artifactId>google-http-client-jackson2</artifactId>
<version>1.39.2</version>
</dependency>
</dependencies>Podstawowe zastosowanie
Przyjrzyjmy się podstawowemu zastosowaniu biblioteki Google HTTP Client Library dla języka Java na podstawie różnych przykładów.
1. Wysyłanie prostego żądania GET
Poniższy kod pokazuje, jak wykonać proste żądanie GET przy użyciu biblioteki Google HTTP Client Library:
import com.google.api.client.http.HttpRequest;
import com.google.api.client.http.HttpRequestFactory;
import com.google.api.client.http.HttpResponse;
import com.google.api.client.http.javanet.NetHttpTransport;
import com.google.api.client.http.GenericUrl;
public class HttpClientExample {
public static void main(String[] args) {
try {
// Create a request factory using NetHttpTransport
HttpRequestFactory requestFactory = new NetHttpTransport().createRequestFactory();
// Define the URL for the GET request
GenericUrl url = new GenericUrl("https://jsonplaceholder.typicode.com/posts/1");
// Build the GET request
HttpRequest request = requestFactory.buildGetRequest(url);
// Execute the request and get the response
HttpResponse response = request.execute();
// Parse the response as a String and print it
System.out.println(response.parseAsString());
} catch (Exception e) {
// Print the stack trace if an exception occurs
e.printStackTrace();
}
}
}import com.google.api.client.http.HttpRequest;
import com.google.api.client.http.HttpRequestFactory;
import com.google.api.client.http.HttpResponse;
import com.google.api.client.http.javanet.NetHttpTransport;
import com.google.api.client.http.GenericUrl;
public class HttpClientExample {
public static void main(String[] args) {
try {
// Create a request factory using NetHttpTransport
HttpRequestFactory requestFactory = new NetHttpTransport().createRequestFactory();
// Define the URL for the GET request
GenericUrl url = new GenericUrl("https://jsonplaceholder.typicode.com/posts/1");
// Build the GET request
HttpRequest request = requestFactory.buildGetRequest(url);
// Execute the request and get the response
HttpResponse response = request.execute();
// Parse the response as a String and print it
System.out.println(response.parseAsString());
} catch (Exception e) {
// Print the stack trace if an exception occurs
e.printStackTrace();
}
}
}W tym przykładzie tworzymy HttpRequestFactory i używamy go do zbudowania i wykonania żądania GET do API zastępczego. Używamy tutaj bloku try-catch do obsługi wyjątków, które mogą wystąpić w przypadku niepowodzenia żądania. Następnie PRINTujemy odpowiedź na konsoli.

2. Wysyłanie żądania POST z danymi JSON
Poniższy kod pokazuje, jak wykonać żądanie POST z danymi JSON:
import com.google.api.client.http.HttpRequest;
import com.google.api.client.http.HttpRequestFactory;
import com.google.api.client.http.HttpResponse;
import com.google.api.client.http.javanet.NetHttpTransport;
import com.google.api.client.http.GenericUrl;
import com.google.api.client.http.json.JsonHttpContent;
import com.google.api.client.json.JsonFactory;
import com.google.api.client.json.jackson2.JacksonFactory;
import java.util.HashMap;
import java.util.Map;
public class HttpClientExample {
public static void main(String[] args) {
try {
// Create a request factory using NetHttpTransport
HttpRequestFactory requestFactory = new NetHttpTransport().createRequestFactory();
// Define the URL for the POST request
GenericUrl url = new GenericUrl("https://jsonplaceholder.typicode.com/posts");
// Create a map to hold JSON data
Map<String, Object> jsonMap = new HashMap<>();
jsonMap.put("title", "foo");
jsonMap.put("body", "bar");
jsonMap.put("userId", 1);
// Create a JSON content using the map
JsonFactory jsonFactory = new JacksonFactory();
JsonHttpContent content = new JsonHttpContent(jsonFactory, jsonMap);
// Build the POST request
HttpRequest request = requestFactory.buildPostRequest(url, content);
// Execute the request and get the response
HttpResponse response = request.execute();
// Parse the response as a String and print it
System.out.println(response.parseAsString());
} catch (Exception e) {
// Print the stack trace if an exception occurs
e.printStackTrace();
}
}
}import com.google.api.client.http.HttpRequest;
import com.google.api.client.http.HttpRequestFactory;
import com.google.api.client.http.HttpResponse;
import com.google.api.client.http.javanet.NetHttpTransport;
import com.google.api.client.http.GenericUrl;
import com.google.api.client.http.json.JsonHttpContent;
import com.google.api.client.json.JsonFactory;
import com.google.api.client.json.jackson2.JacksonFactory;
import java.util.HashMap;
import java.util.Map;
public class HttpClientExample {
public static void main(String[] args) {
try {
// Create a request factory using NetHttpTransport
HttpRequestFactory requestFactory = new NetHttpTransport().createRequestFactory();
// Define the URL for the POST request
GenericUrl url = new GenericUrl("https://jsonplaceholder.typicode.com/posts");
// Create a map to hold JSON data
Map<String, Object> jsonMap = new HashMap<>();
jsonMap.put("title", "foo");
jsonMap.put("body", "bar");
jsonMap.put("userId", 1);
// Create a JSON content using the map
JsonFactory jsonFactory = new JacksonFactory();
JsonHttpContent content = new JsonHttpContent(jsonFactory, jsonMap);
// Build the POST request
HttpRequest request = requestFactory.buildPostRequest(url, content);
// Execute the request and get the response
HttpResponse response = request.execute();
// Parse the response as a String and print it
System.out.println(response.parseAsString());
} catch (Exception e) {
// Print the stack trace if an exception occurs
e.printStackTrace();
}
}
}W tym przykładzie tworzymy obiekt JSON i używamy JsonHttpContent, aby wysłać go w żądaniu POST. Odpowiedź jest następnie wyświetlana w konsoli.

Wprowadzenie do IronPDF for Java
IronPDF to potężna biblioteka dla programistów Java, która upraszcza tworzenie, edycję i zarządzanie dokumentami PDF. Oferuje szeroki zakres funkcji, w tym konwersję HTML do PDF, edycję istniejących plików PDF oraz wyodrębnianie tekstu i obrazów z plików PDF.
Najważniejsze cechy IronPDF
- Konwersja HTML do PDF: Konwertuj treści HTML do formatu PDF z zachowaniem wysokiej jakości.
- Manipulowanie istniejącymi plikami PDF: Łączenie, dzielenie i modyfikowanie istniejących dokumentów PDF.
- Wyodrębnianie tekstu i obrazów: Wyodrębnianie tekstu i obrazów z dokumentów PDF w celu dalszego przetwarzania.
- Znaki wodne i adnotacje: Dodawaj znaki wodne, adnotacje i inne ulepszenia do plików PDF.
- Funkcje bezpieczeństwa: Dodaj hasła i uprawnienia, aby zabezpieczyć dokumenty PDF.
Konfiguracja IronPDF for Java
Aby używać IronPDF w projekcie Java, należy dołączyć bibliotekę IronPDF. Plik JAR można pobrać ze strony internetowej IronPDF lub użyć narzędzia do kompilacji, takiego jak Maven, aby dołączyć go do swojego projektu. Użytkownicy korzystający z Maven powinni dodać następujący kod do pliku pom.xml:
<dependency>
<groupId>com.ironsoftware</groupId>
<artifactId>ironpdf</artifactId>
<version>2023.12.1</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-simple</artifactId>
<version>2.0.3</version>
</dependency>
<dependency>
<groupId>com.ironsoftware</groupId>
<artifactId>ironpdf</artifactId>
<version>2023.12.1</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-simple</artifactId>
<version>2.0.3</version>
</dependency>Korzystanie z biblioteki Google HTTP Client Library z IronPDF
W tej sekcji pokażemy, jak używać biblioteki Google HTTP Client Library do pobierania treści HTML z serwisu internetowego, a następnie używać IronPDF do konwersji tej treści HTML na dokument PDF.
Przykład: Pobieranie kodu HTML i konwersja do formatu PDF
import com.google.api.client.http.HttpRequest;
import com.google.api.client.http.HttpRequestFactory;
import com.google.api.client.http.HttpResponse;
import com.google.api.client.http.javanet.NetHttpTransport;
import com.google.api.client.http.GenericUrl;
import com.ironsoftware.ironpdf.PdfDocument;
public class HtmlToPdfExample {
public static void main(String[] args) {
try {
// Fetch HTML content using Google HTTP Client Library
HttpRequestFactory requestFactory = new NetHttpTransport().createRequestFactory();
GenericUrl url = new GenericUrl("https://jsonplaceholder.typicode.com/posts/1");
HttpRequest request = requestFactory.buildGetRequest(url);
HttpResponse response = request.execute();
String htmlContent = response.parseAsString();
// Convert HTML content to PDF using IronPDF
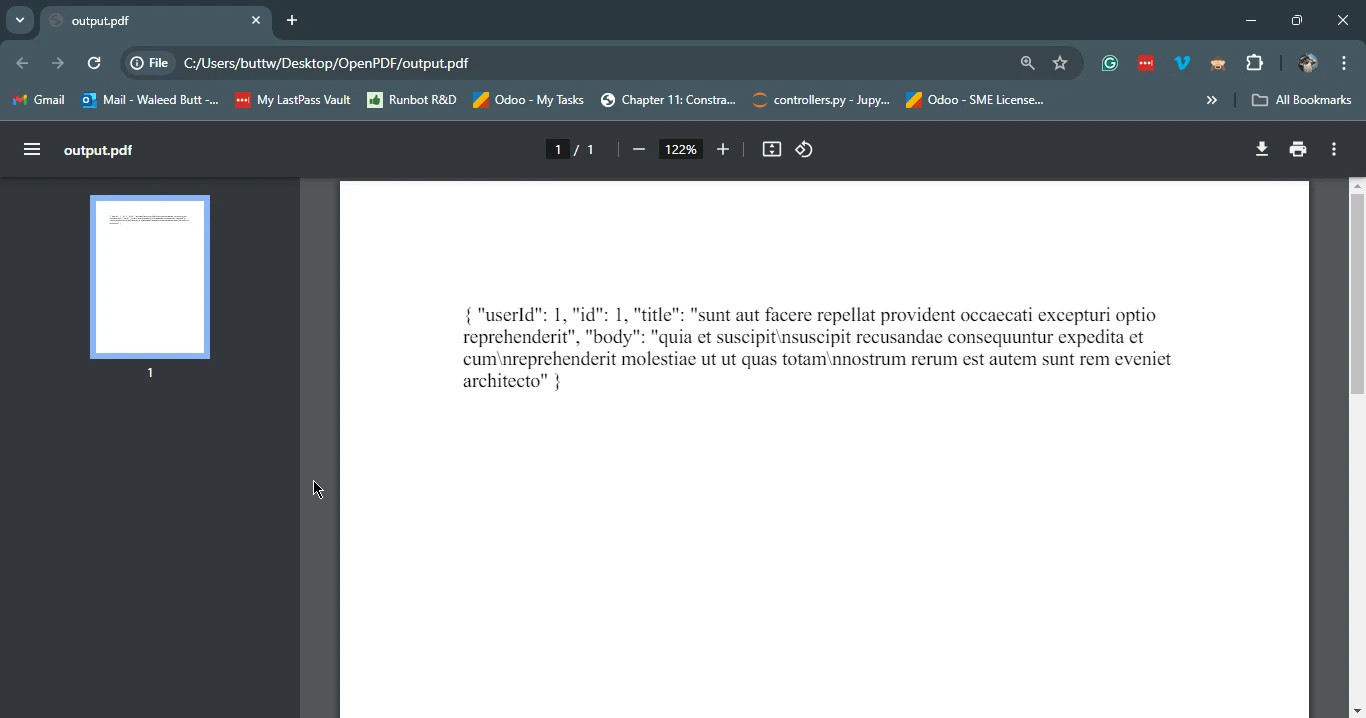
PdfDocument pdf = PdfDocument.renderHtmlAsPdf(htmlContent);
pdf.saveAs("output.pdf");
System.out.println("PDF created successfully!");
} catch (Exception e) {
// Print the stack trace if an exception occurs
e.printStackTrace();
}
}
}import com.google.api.client.http.HttpRequest;
import com.google.api.client.http.HttpRequestFactory;
import com.google.api.client.http.HttpResponse;
import com.google.api.client.http.javanet.NetHttpTransport;
import com.google.api.client.http.GenericUrl;
import com.ironsoftware.ironpdf.PdfDocument;
public class HtmlToPdfExample {
public static void main(String[] args) {
try {
// Fetch HTML content using Google HTTP Client Library
HttpRequestFactory requestFactory = new NetHttpTransport().createRequestFactory();
GenericUrl url = new GenericUrl("https://jsonplaceholder.typicode.com/posts/1");
HttpRequest request = requestFactory.buildGetRequest(url);
HttpResponse response = request.execute();
String htmlContent = response.parseAsString();
// Convert HTML content to PDF using IronPDF
PdfDocument pdf = PdfDocument.renderHtmlAsPdf(htmlContent);
pdf.saveAs("output.pdf");
System.out.println("PDF created successfully!");
} catch (Exception e) {
// Print the stack trace if an exception occurs
e.printStackTrace();
}
}
}W tym przykładzie najpierw pobieramy zawartość HTML z API zastępczego przy użyciu biblioteki Google HTTP Client Library. Następnie używamy IronPDF do konwersji pobranej treści HTML na dokument PDF i zapisujemy go jako output.pdf.
Wnioski
Biblioteka Google HTTP Client Library dla języka Java to potężne narzędzie do interakcji z usługami internetowymi, oferujące uproszczone żądania HTTP, obsługę różnych metod uwierzytelniania, płynną integrację z parsowaniem JSON i XML oraz kompatybilność z różnymi środowiskami Java. W połączeniu z IronPDF programiści mogą z łatwością pobierać treści HTML z serwisów internetowych i konwertować je na dokumenty PDF, co zapewnia pełną bibliotekę do różnych zastosowań, od generowania raportów po tworzenie treści do pobrania dla aplikacji internetowych. Korzystając z tych dwóch bibliotek, programiści Java mogą znacznie zwiększyć możliwości swoich aplikacji, jednocześnie zmniejszając złożoność kodu.
Proszę zapoznać się z poniższym linkiem.