
Jak odczytywać zeskanowane pliki PDF w języku Python
W erze transformacji cyfrowej nie da się przecenić znaczenia dokumentów PDF dla udostępniania i przechowywania informacji.
Jednak powszechne stosowanie zeskanowanych plików PDF, które często zawierają obrazy zamiast tekstu z możliwością wyszukiwania, stanowi poważne wyzwanie, jeśli chodzi o pozyskiwanie wartościowych danych.
W tym miejscu Python jawi się jako wszechstronne i potężne rozwiązanie, umacniając swoją pozycję jako język programowania z wyboru do automatyzacji różnorodnych zadań, czego doskonałym przykładem jest pozyskiwanie informacji ze skanowanych dokumentów.
Elastyczność i rozbudowane możliwości języka Python pozwalają użytkownikom sprawnie poruszać się po złożonych treściach skanowanych dokumentów, zapewniając usprawnione podejście do uzyskiwania dostępu do danych z plików PDF opartych na obrazach oraz ich wykorzystywania.
Python jest jednym z najczęściej używanych języków programowania dzięki swojej zaawansowanej funkcjonalności. Odwiedź [stronę Wikipedii poświęconą](https://en.wikipedia.org/wiki/Python_(programming_language) [Pythonowi](https://en.wikipedia.org/wiki/Python_(programming_language), aby dowiedzieć się więcej o języku programowania Python i jego strukturze.
In this article, we will discuss how to read scanned PDFs in the Python Programming Language with the help of IronPDF for the Python PDF Library.
How to read scanned PDF in Python
- Create a new project in PyCharm.
- To read the scanned PDF file first, install the IronPDF PDF Library.
- Import the required dependencies.
- Load the scanned PDF file using the
PdfDocument.FromFilemethod. - Extract all text from the scanned PDF using the
ExtractAllTextmethod. - Print all the text from the PDF file using the
print()method.
IronPDF for Python
IronPDF for Python is a robust library developed by Iron Software, enabling seamless integration of PDF generation and manipulation capabilities into Python applications.
This versatile tool empowers developers to effortlessly create, modify, and interact with PDF documents, supporting tasks such as dynamic report generation, HTML-to-PDF conversion, and content extraction from existing PDF files.
With a user-friendly API, comprehensive documentation, and a range of features, IronPDF simplifies the process of incorporating advanced PDF functionality into Python projects, making it an invaluable resource for developers looking to enhance their applications with professional-grade document processing capabilities.
Funkcje IronPDF
IronPDF for Python comes equipped with a range of features that make it a powerful tool for PDF generation and text file structure manipulation.
Niektóre z jego kluczowych funkcji to:
- HTML to PDF Conversion: Convert HTML content, including CSS and images, into high-quality PDF documents, allowing developers to leverage existing web-based content in their PDF generation processes and create searchable PDF files.
- Text and Image Manipulation: Easily add and manipulate text, images, and other elements within PDF documents, providing fine-grained control over the layout and appearance of generated PDFs.
- Document Merging and Splitting: Combine multiple PDF documents into a single file or split large PDFs into smaller, more manageable files, offering flexibility in document organization.
- PDF Forms: Create and fill interactive PDF forms programmatically, facilitating the automation of form-related tasks in business applications.
- Security Features: Implement encryption and password protection to secure PDF documents, ensuring sensitive information remains confidential and protected from unauthorized access.
- Text Extraction: Extract text content from PDF documents for analysis or indexing purposes, enabling developers to work with the textual data contained within PDF files with IronPDF's text recognition ability.
Installing IronPDF for Python
Before getting started with the code tutorial, let's first see how you can install IronPDF for Python.
First, make sure Python is installed in the system, and you have a good Python IDE like PyCharm. Also, PIP should be installed to install IronPDF for Python.
- First, create a new Python project or open an existing one.
Open the console and run the following command and press enter.
pip install ironpdfpip install ironpdfSHELL- Just like that, IronPDF for Python is integrated into your Python project.
Reading Scanned PDF Files Using IronPDF For Python
In this section, we will see how you can extract text from scanned PDF files using IronPDF.
from ironpdf import * # Import everything from ironpdf
# Set the license key for IronPDF
License.LicenseKey = "Your License Key"
# Load the scanned PDF document
pdf = PdfDocument.FromFile("C:/Users/buttw/INV_2023_00008.pdf")
# Extract all text from the PDF document
all_text = pdf.ExtractAllText()
# Print the extracted text
print(all_text)from ironpdf import * # Import everything from ironpdf
# Set the license key for IronPDF
License.LicenseKey = "Your License Key"
# Load the scanned PDF document
pdf = PdfDocument.FromFile("C:/Users/buttw/INV_2023_00008.pdf")
# Extract all text from the PDF document
all_text = pdf.ExtractAllText()
# Print the extracted text
print(all_text)The above code example extracts text from scanned PDF files. Below is the breakdown of the above code:
Import the IronPDF Module:
from ironpdf import *from ironpdf import *PYTHONThis line imports the necessary modules and classes from the IronPDF library. The asterisk (
*) indicates that all classes and functions from the module should be imported.Set the License Key:
License.LicenseKey = "Your License Key"License.LicenseKey = "Your License Key"PYTHONThis line sets the license key for IronPDF. You need to replace
"Your License Key"with the actual license key you obtained from Iron Software.The license key is necessary for using IronPDF and is typically provided when you purchase the product.
Load a Scanned PDF Document:
pdf = PdfDocument.FromFile("C:/Users/buttw/INV_2023_00008.pdf")pdf = PdfDocument.FromFile("C:/Users/buttw/INV_2023_00008.pdf")PYTHONThis line loads a scanned PDF document located at the specified file path (
"C:/Users/buttw/INV_2023_00008.pdf"). ThePdfDocument.FromFilemethod is used to create aPdfDocumentobject from the given file.Extract Text from PDF Document:
all_text = pdf.ExtractAllText()all_text = pdf.ExtractAllText()PYTHONThis line extracts all text content from the loaded PDF document using the ExtractAllText method from all the pages. The extracted text is then stored in the
all_textvariable.Print Extracted Text:
print(all_text)print(all_text)PYTHONFinally, this line prints the extracted text to the console. The
all_textvariable contains the text content of the scanned PDF document.
Plik wejściowy PDF
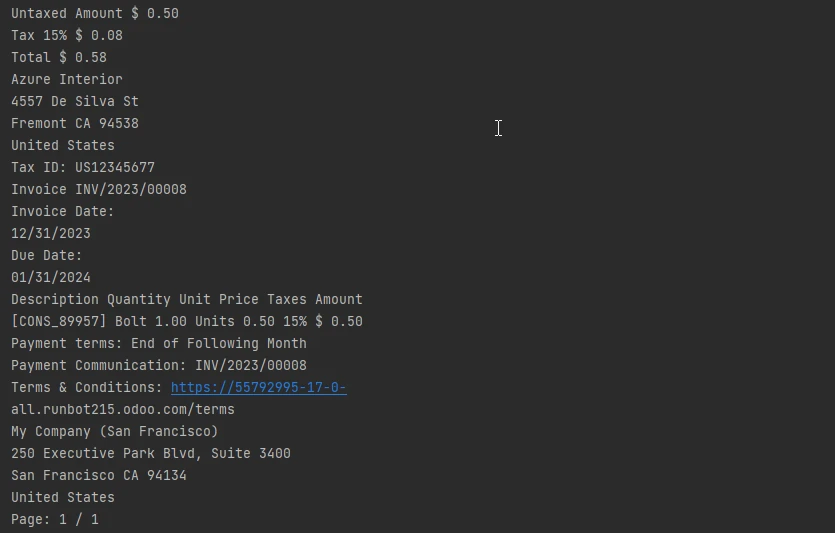
Output text
Wnioski
In the realm of digital document processing, the Python programming language emerges as a versatile solution for overcoming the challenges posed by scanned PDFs containing images instead of searchable text.
The synergy between Python's flexibility and IronPDF for Python's robust capabilities provides a compelling avenue for developers to seamlessly integrate PDF generation, manipulation, and extraction functionalities into their projects.
IronPDF, developed by Iron Software, proves instrumental in this regard, offering features like converting PDF files from various document types, HTML to PDF page conversion, text and image manipulation, and OCR-based text extraction from scanned PDFs.
The showcased code example demonstrates the straightforward implementation of IronPDF to read text from a scanned PDF page, showcasing the potential for efficient data extraction and enhancing document processing capabilities in Python applications.
As the demand for sophisticated PDF handling continues to rise, IronPDF for Python stands as a valuable tool empowering developers to navigate the intricacies of scanned content with ease.
IronPDF for Python offers a trial license, which is a great opportunity for developers to get to know the features of IronPDF.
The complete tutorial on extracting text from scanned PDFs can be found here.
Często Zadawane Pytania
Jak odczytać tekst ze zeskanowanego pliku PDF w języku Python?
Aby odczytać tekst ze zeskanowanego pliku PDF w języku Python, można skorzystać z funkcji OCR biblioteki IronPDF. Najpierw należy zainstalować IronPDF za pomocą polecenia pip install ironpdf. Następnie należy załadować plik PDF za pomocą metody PdfDocument.FromFile i wyodrębnić tekst za pomocą metody ExtractAllText.
Jakie wyzwania stawia skanowane pliki PDF przy ekstrakcji tekstu?
Zeskanowane pliki PDF często przechowują treść jako obrazy, a nie tekst, który można przeszukiwać, co wymaga specjalistycznych narzędzi, takich jak OCR firmy IronPDF, do wyodrębniania i konwertowania tekstu do formatu, który można łatwo przetwarzać.
W jaki sposób IronPDF ułatwia manipulowanie plikami PDF w języku Python?
IronPDF oferuje Suite narzędzi do obróbki plików PDF, w tym wyodrębnianie tekstu, konwersję HTML do PDF, łączenie i dzielenie dokumentów oraz pracę z interaktywnymi formularzami PDF, zwiększając możliwości aplikacji Python w zakresie obsługi dokumentów.
Co jest potrzebne do skonfigurowania IronPDF w środowisku Python?
Aby skonfigurować IronPDF w Pythonie, upewnij się, że Python i PIP są zainstalowane w Twoim systemie. Następnie uruchom pip install ironpdf, aby zainstalować bibliotekę, co pozwoli Ci na rozpoczęcie pracy z plikami PDF w Twoich projektach w Pythonie.
Czy IronPDF może konwertować treści HTML na pliki PDF w języku Python?
Tak, IronPDF może konwertować treści HTML, w tym CSS i obrazy, na wysokiej jakości dokumenty PDF, co czyni go wszechstronnym narzędziem dla programistów potrzebujących generować pliki PDF z treści internetowych.
Czy istnieje możliwość wypróbowania IronPDF przed zakupem?
IronPDF oferuje Licencję Trial, która pozwala programistom zapoznać się z pełnym zakresem funkcji, w tym OCR i edycją plików PDF, przed podjęciem decyzji o zakupie.
Dlaczego Python jest dobrym wyborem do przetwarzania zeskanowanych plików PDF?
Python jest preferowanym językiem do przetwarzania zeskanowanych plików PDF ze względu na swoją elastyczność oraz dostępność solidnych bibliotek, takich jak IronPDF, które upraszczają zadania, takie jak wyodrębnianie tekstu i manipulowanie plikami PDF.
Jakie są kluczowe funkcje IronPDF for Python?
Kluczowe funkcje IronPDF for Python obejmują OCR dla zeskanowanych plików PDF, konwersję HTML do PDF, łączenie i dzielenie dokumentów, manipulowanie tekstem i obrazami oraz obsługę interaktywnych formularzy, oferując kompleksowe rozwiązania do przetwarzania plików PDF.
















