
Como ler PDFs digitalizados em Python
Na era da transformação digital, a indispensabilidade dos documentos PDF para o compartilhamento e a preservação de informações é inegável.
No entanto, a prevalência de PDFs digitalizados , que frequentemente contêm imagens em vez de texto pesquisável, representa um desafio significativo quando se trata de extrair dados valiosos.
É aqui que o Python surge como uma solução versátil e poderosa, consolidando-se como uma linguagem de programação essencial para automatizar diversas tarefas, sendo a extração de informações de documentos digitalizados um excelente exemplo.
A flexibilidade e os recursos robustos do Python permitem que os usuários naveguem com eficiência pelas complexidades do conteúdo digitalizado, proporcionando uma abordagem simplificada para acessar e utilizar dados de PDFs baseados em imagens.
Python é uma das linguagens de programação mais utilizadas, graças à sua funcionalidade avançada. Visite a [página Python Wikipedia](https://en.wikipedia.org/wiki/Python_(programming_language) para aprender sobre a linguagem de programação Python e seu formato estruturado.
Neste artigo, discutiremos como ler PDFs digitalizados na linguagem de programação Python com a ajuda da biblioteca IronPDF for Python.
Como ler um PDF digitalizado em Python
- Crie um novo projeto no PyCharm .
- Para ler o arquivo PDF digitalizado, instale primeiro a biblioteca IronPDF PDF.
- Importe as dependências necessárias.
- Carregue o arquivo PDF digitalizado usando o método
PdfDocument.FromFile. - Extraia todo o texto do PDF digitalizado usando o método
ExtractAllText. - Imprima todo o texto do arquivo PDF usando o método
print().
IronPDF for Python
IronPDF for Python é uma biblioteca robusta desenvolvida pela Iron Software, que permite a integração perfeita de recursos de geração e manipulação de PDFs em aplicações Python.
Essa ferramenta versátil permite que os desenvolvedores criem, modifiquem e interajam com documentos PDF sem esforço, oferecendo suporte a tarefas como geração dinâmica de relatórios, conversão de HTML para PDF e extração de conteúdo de arquivos PDF existentes.
Com uma API intuitiva, documentação completa e uma variedade de recursos, o IronPDF simplifica o processo de incorporação de funcionalidades avançadas de PDF em projetos Python, tornando-se um recurso valioso para desenvolvedores que buscam aprimorar seus aplicativos com recursos de processamento de documentos de nível profissional.
Funcionalidades do IronPDF
O IronPDF for Python vem equipado com uma série de recursos que o tornam uma ferramenta poderosa para geração de PDFs e manipulação da estrutura de arquivos de texto.
Algumas de suas principais características incluem:
- Conversão de HTML para PDF: Converta conteúdo HTML, incluindo CSS e imagens, em documentos PDF de alta qualidade, permitindo que os desenvolvedores aproveitem o conteúdo existente na web em seus processos de geração de PDF e criem arquivos PDF pesquisáveis.
- Manipulação de texto e imagem: Adicione e manipule facilmente texto, imagens e outros elementos em documentos PDF, proporcionando controle preciso sobre o layout e a aparência dos PDFs gerados.
- Fusão e divisão de documentos: combine vários documentos PDF em um único arquivo ou divida PDFs grandes em arquivos menores e mais fáceis de gerenciar, oferecendo flexibilidade na organização de documentos.
- Formulários PDF: Crie e preencha formulários PDF interativos de forma programática, facilitando a automatização de tarefas relacionadas a formulários em aplicações empresariais.
- Recursos de segurança: Implemente criptografia e proteção por senha para proteger documentos PDF, garantindo que as informações confidenciais permaneçam sigilosas e protegidas contra acesso não autorizado.
- Extração de Texto: Extraia o conteúdo de texto de documentos PDF para fins de análise ou indexação, permitindo que os desenvolvedores trabalhem com os dados textuais contidos em arquivos PDF utilizando a capacidade de reconhecimento de texto do IronPDF.
Instalando o IronPDF for Python
Antes de começarmos com o tutorial de código, vamos primeiro ver como instalar o IronPDF for Python.
Primeiro, certifique-se de que o Python esteja instalado no sistema e que você tenha uma boa IDE for Python, como o PyCharm. Além disso, o PIP deve estar instalado para instalar o IronPDF for Python.
- Primeiro, crie um novo projeto Python ou abra um já existente.
-
Abra o console, execute o seguinte comando e pressione Enter.
pip install ironpdf
- Assim, o IronPDF for Python é integrado ao seu projeto Python.
Leitura de arquivos PDF digitalizados usando IronPDF for Python
Nesta seção, veremos como você pode extrair texto de arquivos PDF digitalizados usando o IronPDF.
from ironpdf import * # Import everything from ironpdf
# Set the license key for IronPDF
License.LicenseKey = "Your License Key"
# Load the scanned PDF document
pdf = PdfDocument.FromFile("C:/Users/buttw/INV_2023_00008.pdf")
# Extract all text from the PDF document
all_text = pdf.ExtractAllText()
# Print the extracted text
print(all_text)from ironpdf import * # Import everything from ironpdf
# Set the license key for IronPDF
License.LicenseKey = "Your License Key"
# Load the scanned PDF document
pdf = PdfDocument.FromFile("C:/Users/buttw/INV_2023_00008.pdf")
# Extract all text from the PDF document
all_text = pdf.ExtractAllText()
# Print the extracted text
print(all_text)O exemplo de código acima extrai texto de arquivos PDF digitalizados. Segue abaixo a análise do código acima:
-
Importe o módulo IronPDF :
from ironpdf import *from ironpdf import *PYTHONEsta linha importa os módulos e classes necessários da biblioteca IronPDF . O asterisco (
*) indica que todas as classes e funções do módulo devem ser importadas. -
Defina a chave de licença:
License.LicenseKey = "Your License Key"License.LicenseKey = "Your License Key"PYTHONEsta linha define a chave de licença para o IronPDF. Você precisa substituir
"Your License Key"pela chave de licença real que obteve da Iron Software.A chave de licença é necessária para usar o IronPDF e geralmente é fornecida quando você compra o produto.
-
Carregar um documento PDF digitalizado:
pdf = PdfDocument.FromFile("C:/Users/buttw/INV_2023_00008.pdf")pdf = PdfDocument.FromFile("C:/Users/buttw/INV_2023_00008.pdf")PYTHONEsta linha carrega um documento PDF digitalizado localizado no caminho de arquivo especificado (
"C:/Users/buttw/INV_2023_00008.pdf"). O métodoPdfDocument.FromFileé usado para criar um objetoPdfDocumenta partir do arquivo fornecido. -
Extrair texto de um documento PDF:
all_text = pdf.ExtractAllText()all_text = pdf.ExtractAllText()PYTHONEsta linha extrai todo o conteúdo de texto do documento PDF carregado, utilizando o método ExtractAllText de todas as páginas. O texto extraído é então armazenado na variável
all_text. -
Imprimir o texto extraído:
print(all_text)print(all_text)PYTHONPor fim, esta linha imprime o texto extraído no console. A variável
all_textcontém o conteúdo de texto do documento PDF digitalizado.
Entrada PDF
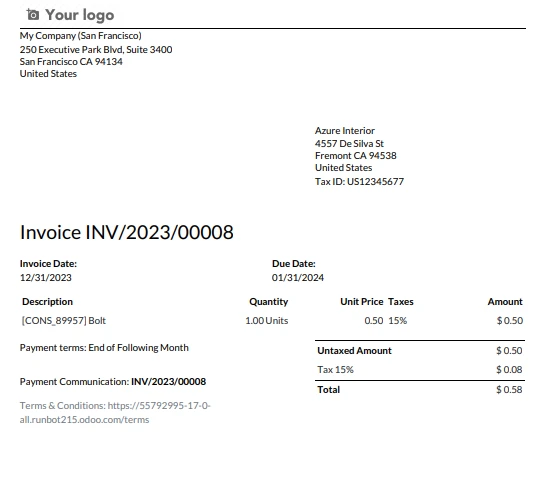
Texto de saída
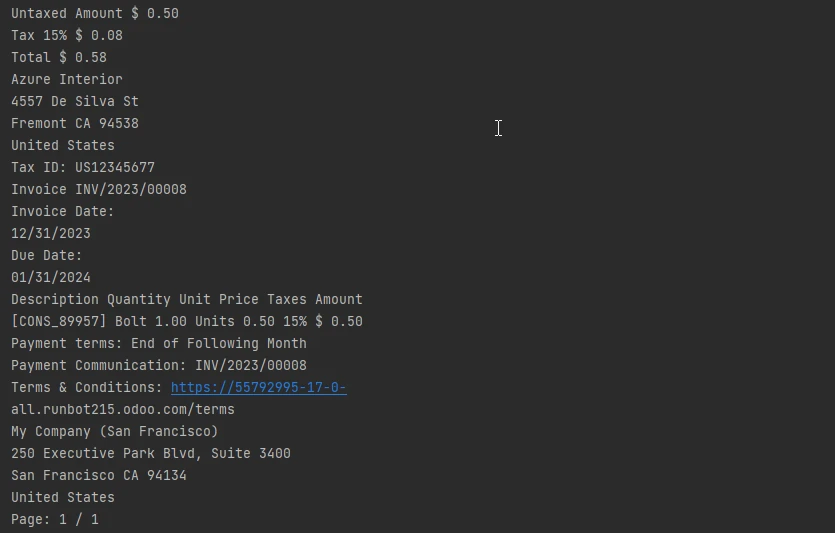
Conclusão
No âmbito do processamento de documentos digitais, a linguagem de programação Python surge como uma solução versátil para superar os desafios apresentados por PDFs digitalizados que contêm imagens em vez de texto pesquisável.
A sinergia entre a flexibilidade do Python e os recursos robustos do IronPDF for Python oferece uma via atraente para que os desenvolvedores integrem, de forma transparente, funcionalidades de geração, manipulação e extração de PDFs em seus projetos.
O IronPDF , desenvolvido pela Iron Software, mostra-se fundamental nesse sentido, oferecendo recursos como conversão de arquivos PDF de vários tipos de documentos, conversão de páginas HTML para PDF, manipulação de texto e imagem e extração de texto baseada em OCR de PDFs digitalizados.
O exemplo de código apresentado demonstra a implementação direta do IronPDF para ler texto de uma página PDF digitalizada, evidenciando o potencial para extração eficiente de dados e aprimoramento dos recursos de processamento de documentos em aplicações Python.
Com a crescente demanda por manipulação sofisticada de PDFs, o IronPDF for Python se destaca como uma ferramenta valiosa, permitindo que desenvolvedores naveguem com facilidade pelas complexidades do conteúdo digitalizado.
O IronPDF for Python oferece uma licença de avaliação , o que é uma ótima oportunidade para os desenvolvedores conhecerem os recursos do IronPDF.
O tutorial completo sobre como extrair texto de PDFs digitalizados pode ser encontrado aqui .
Perguntas frequentes
Como posso ler o texto de um PDF digitalizado em Python?
Para ler texto de um PDF digitalizado em Python, você pode usar os recursos de OCR do IronPDF. Primeiro, instale o IronPDF com pip install ironpdf . Em seguida, carregue seu PDF usando PdfDocument.FromFile e extraia o texto com o método ExtractAllText .
Quais são os desafios que os PDFs digitalizados apresentam para a extração de texto?
Os PDFs digitalizados geralmente armazenam conteúdo como imagens, e não como texto pesquisável, exigindo ferramentas especializadas como o OCR do IronPDF para extrair e converter o texto em um formato gerenciável.
Como o IronPDF facilita a manipulação de PDFs em Python?
O IronPDF oferece um conjunto de ferramentas para manipulação de PDFs, incluindo extração de texto, conversão de HTML para PDF, fusão e divisão de documentos, além de trabalho com formulários PDF interativos, aprimorando os recursos de manipulação de documentos de aplicativos Python.
O que é necessário para configurar o IronPDF em um ambiente Python?
Para configurar o IronPDF em Python, certifique-se de que o Python e o PIP estejam instalados em seu sistema. Em seguida, execute pip install ironpdf para instalar a biblioteca, permitindo que você comece a manipular PDFs em seus projetos Python.
É possível usar o IronPDF para converter conteúdo HTML em PDFs em Python?
Sim, o IronPDF pode converter conteúdo HTML, incluindo CSS e imagens, em documentos PDF de alta qualidade, tornando-se uma ferramenta versátil para desenvolvedores que precisam gerar PDFs a partir de conteúdo da web.
Existe alguma forma de experimentar o IronPDF antes de comprar?
O IronPDF oferece uma licença de avaliação, que permite aos desenvolvedores explorar toda a sua gama de recursos, incluindo OCR e manipulação de PDF, antes de decidirem pela compra.
Por que o Python é uma boa escolha para processar PDFs digitalizados?
Python é uma linguagem preferida para processar PDFs digitalizados devido à sua flexibilidade e à disponibilidade de bibliotecas robustas como o IronPDF, que simplifica tarefas como extração de texto e manipulação de PDFs.
Quais são algumas das principais funcionalidades do IronPDF for Python?
Os principais recursos do IronPDF for Python incluem OCR para PDFs digitalizados, conversão de HTML para PDF, fusão e divisão de documentos, manipulação de texto e imagem e tratamento de formulários interativos, oferecendo soluções abrangentes para processamento de PDFs.
















