
Como extrair texto de um PDF digitalizado em Python
Extrair texto de arquivos PDF, especialmente os digitalizados, pode ser um desafio. No entanto, esse processo pode ser simplificado com as ferramentas e técnicas certas. Este tutorial irá orientá-lo no uso do IronPDF, uma biblioteca Python, para extrair texto de um arquivo PDF digitalizado. Este artigo abordará como configurar seu ambiente, aplicar o reconhecimento óptico de caracteres (OCR) e realizar a extração de texto de forma eficaz.
1. Introdução ao IronPDF
 A biblioteca PDF do Python
A biblioteca PDF do Python
IronPDF é uma biblioteca versátil e poderosa, projetada para manipulação e processamento de PDFs no ambiente Python. Reconhecido por sua capacidade de se integrar perfeitamente com aplicativos Python, o IronPDF oferece uma gama de funcionalidades que vão além da leitura e gravação básicas de PDFs. Destaca-se pela sua capacidade de converter HTML em PDF , renderizar documentos PDF a partir de páginas web ou códigos HTML brutos e editar arquivos PDF existentes .
Além disso, seu recurso de Reconhecimento Óptico de Caracteres (OCR) é útil para extrair texto de documentos PDF digitalizados . É uma ferramenta indispensável para desenvolvedores que lidam com diversas tarefas relacionadas a PDFs. Seja para criar, modificar ou extrair dados de arquivos PDF , o IronPDF é uma solução robusta e confiável, que atende às diversas necessidades dos desenvolvedores Python em várias aplicações.
2. Pré-requisitos
Antes de abordar o processo de extração de texto de PDFs, é essencial ter alguns pré-requisitos e bibliotecas necessárias instaladas. Isso garantirá um fluxo de trabalho tranquilo e eficaz durante todo o processo.
- Ambiente Python: Certifique-se de que o Python esteja instalado em seu computador. Python é uma linguagem de programação versátil, e seu amplo suporte a bibliotecas a torna ideal para tarefas como extração de texto. Se você ainda não instalou o Python, pode baixá-lo do site oficial do Python . Certifique-se de baixar uma versão do Python compatível com seu sistema operacional.
- Instalação do SDK .NET 6.0: Como o IronPDF for Python utiliza a biblioteca IronPDF .NET , que é baseada no .NET 6.0, é crucial ter o SDK .NET 6.0 instalado em seu sistema. Este SDK fornece o ambiente de execução e as bibliotecas necessárias para que a biblioteca IronPDF funcione corretamente. Você pode baixar e instalar o SDK do .NET 6.0 no site oficial da Microsoft .NET .
- Biblioteca IronPDF for Python: IronPDF é uma biblioteca robusta para trabalhar com documentos PDF em Python. Ele não só facilita a extração de texto, como também oferece funcionalidades como criação, edição e conversão de PDFs.
- Documento PDF digitalizado: Tenha um documento PDF digitalizado pronto para extração de texto. Idealmente, este documento deve ser claro e legível, pois a qualidade do PDF digitalizado pode afetar significativamente a precisão do OCR e do texto extraído.
- Conhecimento básico de Python: Um conhecimento básico de programação em Python é benéfico. Familiaridade com conceitos como variáveis, loops e operações básicas de arquivos ajudará você a navegar pelo código e a entender o processo de extração de texto com mais eficácia.
- Um ambiente de desenvolvimento adequado: Embora não seja estritamente necessário, ter um ambiente de desenvolvimento como o Visual Studio Code , PyCharm ou até mesmo um Jupyter Notebook pode tornar sua experiência de programação mais gerenciável. Esses ambientes oferecem recursos como realce de sintaxe, preenchimento automático de código e ferramentas de depuração, que são extremamente úteis ao trabalhar com scripts Python.
Com esses pré-requisitos, você estará bem preparado para começar a extrair texto de documentos PDF digitalizados usando a biblioteca IronPDF for Python. Os passos seguintes irão guiá-lo na instalação do IronPDF, no carregamento do seu documento PDF, na aplicação do OCR, na extração do texto e na utilização dos dados extraídos para as suas necessidades específicas.
3. Guia passo a passo para extrair texto de um PDF digitalizado
Passo 1: Instale o IronPDF
Primeiro, você precisa instalar a biblioteca IronPDF for Python no seu ambiente Python. Normalmente, isso é feito usando o gerenciador de pacotes do Python, o pip. Abra a interface de linha de comando e execute o seguinte comando:
pip install ironpdf
 Instale o pacote IronPDF
Instale o pacote IronPDF
Etapa 2: Importar IronPDF
Após a instalação, importe a biblioteca IronPDF para o seu script Python. Esta etapa é crucial para acessar as funcionalidades oferecidas pelo IronPDF:
import ironpdfimport ironpdfAo importar o IronPDF, você agora pode usar suas classes e métodos em seu script.
Passo 3: Aplique sua chave de licença
O IronPDF requer uma chave de licença para funcionar plenamente. Se você adquiriu uma licença, aplique sua chave de licença da seguinte forma:
ironpdf.License.LicenseKey = "YOUR-LICENSE-KEY-HERE"ironpdf.License.LicenseKey = "YOUR-LICENSE-KEY-HERE"Substitua "YOUR-LICENSE-KEY-HERE" pela sua chave de licença IronPDF real. Este passo é essencial para desbloquear todas as funcionalidades do IronPDF sem quaisquer limitações.
Passo 4: Carregar o arquivo PDF digitalizado
Para extrair o texto, comece carregando o documento PDF em seu script:
pdf = ironpdf.PdfDocument.FromFile("scannedpdf.pdf")pdf = ironpdf.PdfDocument.FromFile("scannedpdf.pdf")Aqui, "scannedpdf.pdf" deve ser substituído pelo caminho real do arquivo do documento PDF que você pretende processar. Este comando lê o arquivo PDF e o prepara para a extração de texto.
Etapa 5: Extrair texto do arquivo PDF
Com o PDF carregado, você pode agora extrair texto usando o método ExtractAllText() do IronPDF, conforme mostrado no código a seguir:
text = pdf.ExtractAllText()text = pdf.ExtractAllText()Esta linha de código processa todo o documento PDF e extrai seu conteúdo de texto, armazenando-o na variável text.
Etapa 6: Processar e utilizar o texto extraído
Após a extração, os dados de texto estão disponíveis na variável text. Você pode imprimir este texto no console ou processá-lo posteriormente de acordo com suas necessidades:
print(text)
# Additional code here to process or utilize the extracted textprint(text)
# Additional code here to process or utilize the extracted textEsta etapa pode envolver diversas operações, como salvar o texto extraído em um arquivo, realizar análises de dados textuais ou integrá-lo a um banco de dados ou a um aplicativo web. Aqui você pode ver o resultado do código acima.
Texto de saída
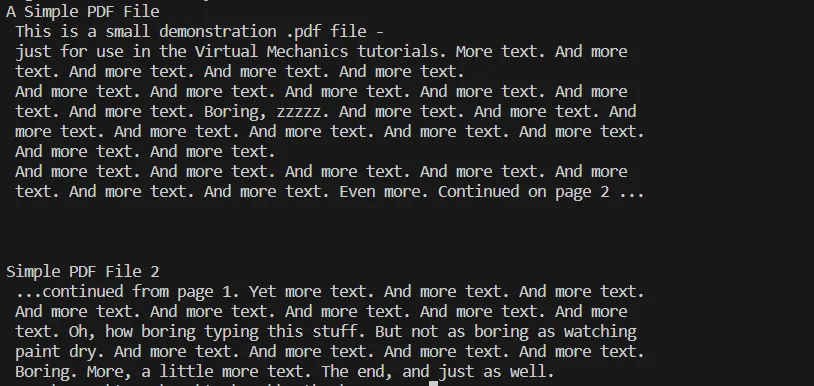 Saída do console do processo acima de extração de texto de um arquivo PDF
Saída do console do processo acima de extração de texto de um arquivo PDF
Etapa 7: Operações adicionais (opcional)
As funcionalidades do IronPDF vão além da extração de texto. Dependendo dos requisitos do seu projeto, você pode explorar recursos adicionais, como editar PDFs, converter PDFs para diferentes formatos ou até mesmo gerar PDFs a partir de HTML.
4. Técnicas Avançadas
4.1 Tratamento de Elementos Não Textuais
Os PDFs digitalizados geralmente contêm elementos não textuais, como imagens ou gráficos. Embora o OCR se concentre no texto, você pode querer lidar com esses elementos de maneira diferente. Você pode precisar de bibliotecas Python adicionais para processar ou ignorar conteúdo não textual.
4.2 Melhorando a precisão do OCR
A precisão da extração de texto pode variar dependendo da qualidade dos documentos digitalizados. Para melhorar os resultados do OCR, certifique-se de que o PDF digitalizado tenha alta qualidade e que o texto esteja o mais nítido possível.
4.3 Convertendo para outros formatos
Após extrair o texto de um PDF, você pode querer convertê-lo para outros formatos, como CSV, JSON ou XML, para processamento posterior. O IronPDF permite essas conversões, oferecendo opções flexíveis de manipulação de dados.
5. Solução de problemas comuns
Ao trabalhar com OCR e extração de texto, você pode encontrar problemas como:
- Baixa precisão do OCR devido a digitalizações de baixa qualidade.
- Texto ausente se o OCR não reconhecer alguns caracteres.
- Erros ao carregar arquivos PDF grandes.
Para solucionar esses problemas, certifique-se de que seus arquivos PDF digitalizados estejam nítidos e com alta qualidade, considere dividir arquivos grandes em arquivos menores e verifique se sua biblioteca do IronPDF está atualizada.
Conclusão
A extração de texto de um arquivo PDF digitalizado pode ser realizada de forma simples e eficiente utilizando a biblioteca IronPDF for Python. Seguindo os passos descritos neste tutorial, você pode converter um documento digitalizado não pesquisável em um formato rico em texto que pode ser processado e analisado rapidamente. Lembre-se de manusear cada página do PDF com cuidado e aplicar o OCR para transformar seu PDF digitalizado em um arquivo PDF pesquisável. Com o texto extraído, as possibilidades de manipulação e utilização de dados são vastas, abrindo caminho para soluções inovadoras e fluxos de trabalho otimizados.
Em resumo, este artigo abordou a instalação e configuração do IronPDF, o carregamento de arquivos PDF, a aplicação da tecnologia OCR para tornar um PDF digitalizado pesquisável, o processo de extração de texto propriamente dito e o processamento de várias páginas em PDF. Também abordou técnicas avançadas e a resolução de problemas comuns. Com esse conhecimento, você pode extrair dados de texto de documentos PDF usando Python.
O IronPDF oferece um período de teste gratuito com acesso a todos os recursos, permitindo que os usuários avaliem as capacidades de manipulação de PDFs e extração de texto. Após o teste, uma licença paga começa em $999, atendendo ao uso profissional e comercial com um conjunto abrangente de recursos. O IronPDF é gratuito para desenvolvimento, permitindo que os desenvolvedores integrem e testem suas funcionalidades sem custos durante a fase de desenvolvimento do aplicativo.
Perguntas frequentes
Como configuro meu ambiente para extrair texto de PDFs digitalizados usando Python?
Para configurar seu ambiente, instale o SDK do .NET 6.0 e a biblioteca IronPDF usando o gerenciador de pacotes do Python com o pip install ironpdf . Certifique-se de ter um ambiente Python e um ambiente de desenvolvimento adequado, como o Visual Studio Code ou o PyCharm.
O que é o Reconhecimento Óptico de Caracteres (OCR) e como ele é aplicado em Python?
O Reconhecimento Óptico de Caracteres (OCR) é uma tecnologia usada para converter diferentes tipos de documentos, como documentos digitalizados em papel ou PDFs, em dados editáveis e pesquisáveis. Em Python, você pode aplicar OCR usando o IronPDF, carregando um PDF digitalizado e utilizando as funcionalidades de OCR da biblioteca para extrair o texto.
Como posso garantir a extração precisa de texto de PDFs digitalizados?
Para garantir uma extração de texto precisa, utilize PDFs digitalizados de alta qualidade, pois a precisão do OCR melhora com digitalizações mais nítidas e de melhor qualidade. Com o IronPDF, você pode aplicar o OCR para extrair o texto e processá-lo posteriormente, conforme necessário.
Quais são os passos envolvidos na extração de texto de um PDF digitalizado usando o IronPDF?
Os passos incluem instalar o IronPDF, importar a biblioteca, aplicar uma chave de licença, carregar o PDF digitalizado, aplicar o OCR e usar o método ExtractAllText() para extrair o texto.
Posso converter o texto extraído em formatos como CSV, JSON ou XML?
Sim, depois de extrair o texto de um PDF digitalizado usando o IronPDF, você pode convertê-lo em vários formatos, como CSV, JSON ou XML, para análises ou manipulação de dados posteriores.
Quais são algumas etapas comuns de solução de problemas caso a extração de texto falhe?
Se a extração de texto falhar, verifique a qualidade do PDF digitalizado. Certifique-se de que o IronPDF esteja instalado corretamente e que seu ambiente de desenvolvimento esteja configurado adequadamente. Além disso, verifique se os métodos e funcionalidades de OCR corretos estão sendo utilizados.
Existe alguma versão de avaliação disponível para o IronPDF?
Sim, o IronPDF oferece uma versão de avaliação gratuita para que os usuários testem suas funcionalidades. Após o período de avaliação, é necessária uma licença paga para obter todas as funcionalidades.
















