Comment extraire du texte d'un PDF scanné en Python
Extraire le texte des fichiers PDF, en particulier ceux scannés, peut être difficile. Cependant, ce processus peut être simplifié avec les bons outils et techniques. Ce tutoriel vous guidera dans l'utilisation d'IronPDF, une bibliothèque Python, pour extraire du texte d'un fichier PDF scanné. Cet article couvrira comment configurer votre environnement, appliquer la reconnaissance optique de caractères (OCR) et effectuer une extraction de texte efficace.
1. Introduction à IronPDF
 La bibliothèque Python PDF
La bibliothèque Python PDF
IronPDF est une bibliothèque polyvalente et puissante conçue pour la manipulation et le traitement de PDF dans l'environnement Python. Connu pour sa capacité à s'intégrer parfaitement aux applications Python, IronPDF offre une gamme de fonctionnalités qui vont au-delà de la simple lecture et écriture de PDF. Il se distingue par sa capacité à convertir du HTML en PDF, à rendre des documents PDF à partir de pages web ou de codes HTML bruts, et à modifier les fichiers PDF existants.
De plus, sa fonction de Reconnaissance Optique de Caractères (OCR) est pratique pour extraire du texte de documents PDF scannés. C'est un outil de choix pour les développeurs traitant diverses tâches liées aux PDF. Que ce soit pour créer, modifier ou extraire des données de fichiers PDF, IronPDF est une solution robuste et fiable, répondant aux divers besoins des développeurs Python dans diverses applications.
2. Prérequis
Avant de plonger dans le processus d'extraction de texte à partir de PDFs, il est essentiel d'avoir quelques prérequis et bibliothèques nécessaires en place. Cela garantira un flux de travail fluide et efficace à mesure que vous avancez.
- Environnement Python : Assurez-vous que Python est installé sur votre système informatique. Python est un langage de programmation polyvalent, et son support étendu de bibliothèques le rend idéal pour des tâches comme l'extraction de texte. Si vous n'avez pas installé Python, vous pouvez le télécharger depuis le site officiel de Python. Assurez-vous de télécharger une version de Python compatible avec votre système d'exploitation.
- Installation du SDK .NET 6.0 : Étant donné qu'IronPDF for Python utilise la bibliothèque IronPDF for .NET, qui est construite sur .NET 6.0, il est crucial d'avoir le SDK .NET 6.0 installé sur votre système. Ce SDK fournit le runtime et les bibliothèques nécessaires pour que la bibliothèque IronPDF fonctionne correctement. Vous pouvez télécharger et installer le SDK .NET 6.0 depuis le site officiel de Microsoft .NET.
- Bibliothèque IronPDF for Python : IronPDF est une bibliothèque robuste pour travailler avec des documents PDF en Python. Elle facilite non seulement l'extraction de texte mais offre également des fonctionnalités comme la création, l'édition et la conversion de PDF.
- Document PDF scanné : Ayez un document PDF scanné prêt pour l'extraction de texte. Ce document doit idéalement être clair et lisible, car la qualité du PDF scanné peut avoir un impact significatif sur la précision de l'OCR et du texte extrait.
- Compréhension de base de Python : Une compréhension de base de la programmation en Python est bénéfique. La familiarité avec des concepts tels que les variables, les boucles, et les opérations de fichiers de base vous aidera à naviguer dans le code et à comprendre le processus d'extraction de texte plus efficacement.
- Un environnement de développement adapté : Bien qu'il ne soit pas strictement nécessaire, avoir un environnement de développement comme Visual Studio Code, PyCharm ou même un Jupyter Notebook peut rendre votre expérience de codage plus gérable. Ces environnements offrent des fonctionnalités comme la coloration syntaxique, la complétion de code, et les outils de débogage qui sont extrêmement utiles lors du travail avec des scripts Python.
Avec ces prérequis, vous êtes bien préparé pour commencer à extraire du texte de documents PDF scannés en utilisant la bibliothèque IronPDF for Python. Les étapes suivantes vous guideront à travers l'installation d'IronPDF, le chargement de votre document PDF, l'application de l'OCR, l'extraction de texte, et l'utilisation des données extraites pour vos besoins spécifiques.
3. Guide étape par étape pour extraire du texte d'un PDF scanné
Étape 1 : Installez IronPDF
Tout d'abord, vous devez installer la bibliothèque Python IronPDF dans votre environnement Python. Cela se fait généralement en utilisant le Package Manager de Python, pip. Ouvrez votre interface de ligne de commande et exécutez la commande suivante :
pip install ironpdf
 Installer le package IronPDF
Installer le package IronPDF
Étape 2 : Importer IronPDF
Après l'installation, importez la bibliothèque IronPDF dans votre script Python. Cette étape est cruciale pour accéder aux fonctionnalités fournies par IronPDF :
import ironpdfimport ironpdfEn important IronPDF, vous pouvez maintenant utiliser ses classes et méthodes dans votre script.
Étape 3 : Appliquer votre clé de licence
IronPDF nécessite une clé de licence pour une fonctionnalité complète. Si vous avez acheté une licence, appliquez votre clé de licence comme suit :
ironpdf.License.LicenseKey = "YOUR-LICENSE-KEY-HERE"ironpdf.License.LicenseKey = "YOUR-LICENSE-KEY-HERE"Remplacez "YOUR-LICENSE-KEY-HERE" par votre clé de licence IronPDF réelle. Cette étape est essentielle pour débloquer toutes les fonctionnalités d'IronPDF sans aucune limitation.
Étape 4 : Charger le fichier PDF scanné
Pour extraire du texte, commencez par charger le document PDF dans votre script :
pdf = ironpdf.PdfDocument.FromFile("scannedpdf.pdf")pdf = ironpdf.PdfDocument.FromFile("scannedpdf.pdf")Ici, "scannedpdf.pdf" doit être remplacé par le chemin d'accès réel du document PDF que vous souhaitez traiter. Cette commande lit le fichier PDF et le prépare pour l'extraction de texte.
Étape 5 : Extraire le texte du fichier PDF
Une fois le PDF chargé, vous pouvez maintenant extraire du texte à l'aide de la méthode ExtractAllText() d'IronPDF, comme indiqué dans le code suivant :
text = pdf.ExtractAllText()text = pdf.ExtractAllText()Cette ligne de code traite l'intégralité du document PDF et extrait son contenu textuel, le stockant dans la variable text.
Étape 6 : Traiter et utiliser le texte extrait
Après extraction, les données textuelles sont disponibles dans la variable text. Vous pouvez imprimer ce texte dans la console ou le traiter davantage selon vos besoins :
print(text)
# Additional code here to process or utilize the extracted textprint(text)
# Additional code here to process or utilize the extracted textCette étape peut impliquer diverses opérations telles que sauvegarder le texte extrait dans un fichier, réaliser une analyse des données textuelles, ou l'intégrer dans une base de données ou une application web. Ici, vous pouvez voir la sortie du code ci-dessus.
Texte de SORTIE
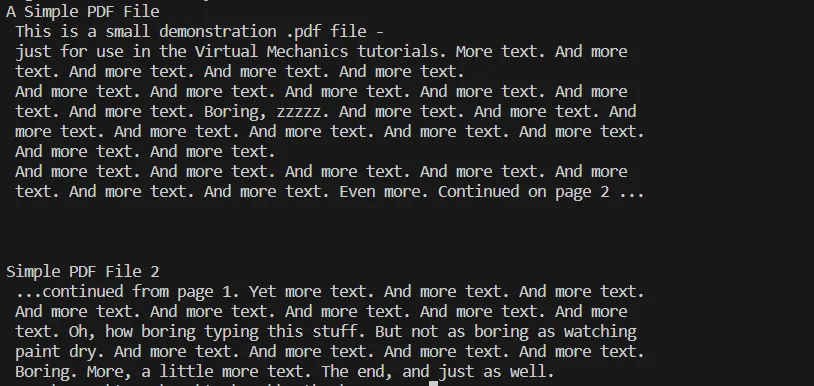 Sortie console du processus ci-dessus d'extraction de texte du fichier PDF
Sortie console du processus ci-dessus d'extraction de texte du fichier PDF
Étape 7 : Opérations supplémentaires (optionnel)
Les capacités d'IronPDF vont au-delà de l'extraction de texte. Selon les exigences de votre projet, vous pouvez explorer des fonctionnalités supplémentaires telles que l'édition des PDF, la conversion des PDF en différents formats, ou même la génération de PDFs à partir de HTML.
4. Techniques avancées
4.1 Gestion des éléments non textuels
Les PDF scannés contiennent souvent des éléments non textuels comme des images ou des graphiques. Alors que l'OCR se concentre sur le texte, vous pouvez vouloir traiter ces éléments différemment. Vous pourriez avoir besoin de bibliothèques Python supplémentaires pour traiter ou ignorer le contenu non textuel.
4.2 Amélioration de la précision de l'OCR
La précision de l'extraction de texte peut varier en fonction de la qualité des documents scannés. Pour améliorer les résultats de l'OCR, assurez-vous que votre PDF scanné est de haute qualité et que le texte est aussi clair que possible.
4.3 Conversion en d'autres formats
Après avoir extrait le texte du PDF, vous pouvez vouloir le convertir dans d'autres formats comme CSV, JSON, ou XML pour un traitement ultérieur. IronPDF permet de telles conversions, vous offrant des options de gestion des données flexibles.
5. Résolution des problèmes courants
Lors du travail avec l'OCR et l'extraction de texte, vous pouvez rencontrer des problèmes tels que :
- Précision de l'OCR médiocre due à des scans de mauvaise qualité.
- Texte manquant si l'OCR ne parvient pas à reconnaître certains caractères.
- Erreurs lors du chargement de fichiers PDF volumineux.
Pour résoudre ces problèmes, assurez-vous que vos fichiers PDF scannés sont clairs et de haute qualité, envisagez de diviser les fichiers volumineux en plus petits, et vérifiez que votre bibliothèque IronPDF est à jour.
Conclusion
Extraire du texte d'un fichier PDF numérisé peut être accompli sans effort en utilisant la bibliothèque Python IronPDF. En suivant les étapes décrites dans ce tutoriel, vous pouvez convertir un document scanné non-recherchable en un format riche en texte qui peut être rapidement traité et analysé. N'oubliez pas de manipuler chaque page PDF avec précaution et d'appliquer l'OCR pour transformer votre PDF scanné en un fichier PDF recherché. Avec le texte extrait, les possibilités de manipulation et d'utilisation des données sont vastes, ouvrant la voie à des solutions innovantes et à des flux de travail rationalisés.
En résumé, cet article a couvert l'installation et la configuration d'IronPDF, le chargement des fichiers PDF, l'application de la technologie OCR pour rendre un PDF scanné recherché, le processus réel d'extraction de texte, et la gestion de plusieurs pages PDF. Il a également abordé des techniques avancées et la résolution des problèmes courants. Avec ces connaissances, extrayez des données textuelles de PDF en Python.
IronPDF offre un essai gratuit pour un accès complet aux fonctionnalités, permettant aux utilisateurs d'évaluer les capacités de manipulation de PDF et d'extraction de texte. Après la période d'essai, une licence payante est disponible à partir de $999, adaptée à un usage Professional et commercial avec un ensemble complet de fonctionnalités. IronPDF est gratuit pour le développement, permettant aux développeurs d'intégrer et de tester ses fonctionnalités sans coût pendant la phase de développement d'application.
Questions Fréquemment Posées
Comment configurer mon environnement pour extraire du texte à partir de PDF scannés en utilisant Python?
Pour configurer votre environnement, installez le SDK .NET 6.0 et la bibliothèque IronPDF en utilisant le Package Manager de Python avec pip install ironpdf. Assurez-vous d'avoir un environnement Python et un environnement de développement adapté comme Visual Studio Code ou PyCharm.
Qu'est-ce que la reconnaissance optique de caractères (OCR) et comment est-elle appliquée en Python?
La reconnaissance optique de caractères (OCR) est une technologie utilisée pour convertir différents types de documents, tels que des documents papier scannés ou des PDFs, en données modifiables et recherchables. En Python, vous pouvez appliquer l'OCR en using IronPDF en chargeant un PDF scanné et en utilisant les fonctionnalités OCR de la bibliothèque pour extraire le texte.
Comment puis-je assurer une extraction précise du texte depuis des PDF scannés?
Pour assurer une extraction précise du texte, utilisez des PDF scannés de haute qualité, car la précision de l'OCR s'améliore avec des scans plus clairs et de meilleure qualité. Avec IronPDF, vous pouvez appliquer l'OCR pour extraire le texte et le traiter plus avant si nécessaire.
Quelles sont les étapes impliquées dans l'extraction de texte à partir d'un PDF scanné en using IronPDF?
Les étapes incluent l'installation de IronPDF, l'importation de la bibliothèque, l'application d'une clé de licence, le chargement de votre PDF scanné, l'application de l'OCR, et l'utilisation de la méthode ExtractAllText() pour extraire le texte.
Puis-je convertir le texte extrait en formats comme CSV, JSON ou XML?
Oui, une fois le texte extrait d'un PDF scanné en using IronPDF, vous pouvez le convertir en divers formats tels que CSV, JSON ou XML pour une analyse plus poussée ou une manipulation des données.
Quelles sont les étapes de dépannage courantes si l'extraction de texte échoue?
Si l'extraction de texte échoue, vérifiez la qualité du PDF scanné. Assurez-vous que IronPDF est correctement installé et que votre environnement de développement est correctement configuré. Vérifiez aussi que les méthodes et les fonctionnalités OCR correctes sont utilisées.
Y a-t-il une version d'essai disponible pour IronPDF?
Oui, IronPDF offre une version d'essai gratuite pour permettre aux utilisateurs de tester ses capacités. Une licence payante est requise pour bénéficier de toutes les fonctionnalités après la période d'essai.